
This article extends the classic one-dimensional interval-packing problem to two dimensions, using a student-scheduling scenario where each record spans both a date range and a class-period range. The challenge was posed to Itzik Ben-Gan by Paul Wilcox and the article presents both the task and Ben-Gan’s solution in full T-SQL.
The solution applies the Unpack/Pack technique – converting intervals into their constituent unit points, grouping those points with a gaps-and-islands approach, and converting the groups back into packed intervals – iteratively across both dimensions.
Expected readers: advanced T-SQL developers, those familiar with Ben-Gan’s earlier packing-intervals work, and anyone who has hit this problem in scheduling, resource allocation, or calendar-overlap workloads.
What is the packing intervals task in SQL Server?
Packing intervals is a classic SQL task that involves packing groups of intersecting intervals to their respective continuous intervals. In mathematics, an interval is the subset of all values of a given type, e.g., integer numbers, between some low value and some high value. In databases, intervals can manifest as date and time intervals representing things like sessions, prescription periods, hospitalization periods, schedules, or numeric intervals representing things like ranges of mile posts on a road, temperature ranges, and so on.
An example for an interval packing task is packing intervals representing sessions for billing purposes. If you conduct a web search of the term packing intervals SQL, you’ll find scores of articles on the subject, including my own.
I’ve dealt with many interval packing tasks in the past and used different techniques to handle those. But they all had something in common that kept the complexity level at bay—they were all what you can think of as one-dimensional interval packing tasks. That is, each input represented one interval. One-dimensional intervals can be depicted spatially as segments on a line, and the packing task can be illustrated as identifying the delimiters of the groups of intersecting segments.
During a T-SQL class, while discussing packing challenges, Paul Wilcox from Johns Hopkins inquired whether I dealt with two-dimensional packing tasks, and if I had any references to resources for addressing those. He pointed to a forum post he submitted a few years earlier with a problem that came about due to a scheduling issue he came across when working at a previous school district. I remember Paul trying to use hand gestures representing two dimensional polygons to illustrate the idea. Up to that point it didn’t even occur to me that two-dimensional packing problems even existed, so obviously I had nothing to give him at the time. I promised to look at it after class, though, and address it next morning.
I sometimes refer to solutions or techniques as being elegant. What was interesting about this problem is that the challenge itself was very elegant and compelling. Moreover, I could tell that Paul was very experienced and bright, so if after years since he first stumbled into this task, he was still looking for additional solutions, it had to be a very interesting one.
In this article I present Paul’s two-dimensional packing challenge and my solution. Some of the illustrations I use are like Paul’s own depictions of the logical steps that are involved in the solution.
As a practice tool, I recommend that you attempt to solve the challenge yourself before looking at Paul’s and my solutions. I recommend reading Paul’s post to understand the task, but will also provide full details of the challenge here.
Note: the code for this article can be downloaded here.
The Two-Dimensional Interval Packing Challenge
The task at hand involves student class schedules stored in a table called Schedule, which you create and populate using the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SET NOCOUNT ON; USE tempdb; DROP TABLE IF EXISTS dbo.Schedule; CREATE TABLE dbo.Schedule ( id INT NOT NULL CONSTRAINT PK_Schedule PRIMARY KEY, student CHAR(3) NOT NULL, fromdate INT NOT NULL, todate INT NOT NULL, fromperiod INT NOT NULL, toperiod INT NOT NULL ); INSERT INTO dbo.Schedule(id, student, fromdate, todate, fromperiod, toperiod) VALUES (1, 'Amy', 1, 7, 7, 9), (2, 'Amy', 3, 9, 5, 8), (3, 'Amy', 10, 12, 1, 3), (4, 'Ted', 1, 5, 11, 14), (5, 'Ted', 7, 11, 13, 16); |
Each row has the student in question, a begin date (fromdate) and end date (todate), and a period start time (fromperiod) and period end time (toperiod). Note that the sample data uses integers instead of date and time values for simplicity.
To help understand the current data, it can be convenient to depict it graphically. This can be achieved with the following spatial query, forming a rectangle from each row:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT student, GEOMETRY::STGeomFromText('GEOMETRYCOLLECTION(' + STRING_AGG(CONCAT('POLYGON((',fromdate,' ',fromperiod, ',', fromdate,' ',toperiod + 1, ',', todate + 1,' ',toperiod + 1,',', todate + 1,' ',fromperiod,',', fromdate,' ',fromperiod , '))'), ',') + ')', 0) AS shape FROM dbo.Schedule GROUP BY student; |
Figure 1 has the graphical output of this query as can be seen in the SSMS Spatial results tab.
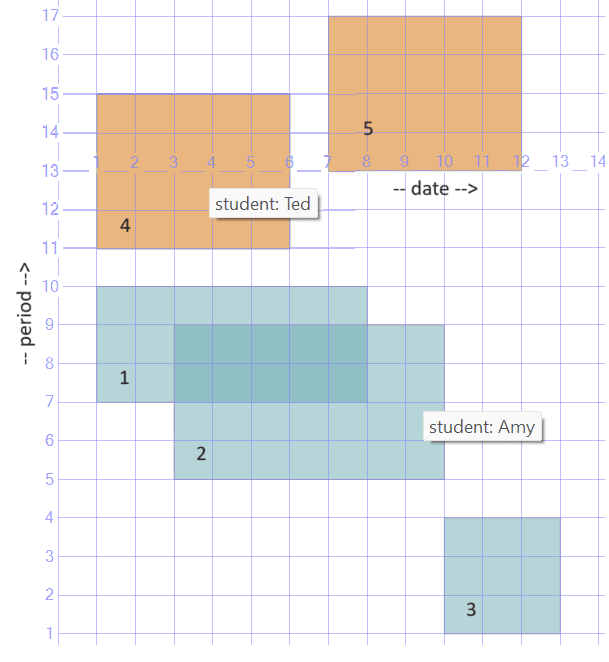
Figure 1: Unnormalized Schedule Depicted Graphically
The X axis represents the date ranges, and the Y axis represents the period ranges.
Notice that a student may have overlapping schedules, as is the case with Amy’s schedules 1 and 2. You can think of the current data as representing an unnormalized form of the schedule.
Sometimes you need to query the data to identify a schedule that contains a certain date and period. For example, the following query looks for Amy’s schedule that contains date 4 and period 8:
|
1 2 3 4 5 |
SELECT id, student, fromdate, todate, fromperiod, toperiod FROM dbo.Schedule WHERE student = 'Amy' AND 4 BETWEEN fromdate AND todate AND 8 BETWEEN fromperiod AND toperiod; |
This query generates the following output, showing multiple matches:
|
1 2 3 4 |
id student fromdate todate fromperiod toperiod ----------- ------- ----------- ----------- ----------- -------- 1 Amy 1 7 7 9 2 Amy 3 9 5 8 |
Multiple matches for a single (date, period) point are only possible due to the unnormalized nature of the schedule. The challenge is to create a normalized state of the schedule, with distinct, nonoverlapping date range and period range combinations. Assuming such a normalized state is stored in a table, you then have a guarantee for no more than one matching row per input (date, period) point.
The tricky part is that there may be multiple arrangements that can achieve this goal. For the sake of this challenge, you just need to pick one that produces a deterministic result. For example, form a result row for each consecutive range of dates with the same period range. Figure 2 has a graphical depiction of the desired normalized schedule.
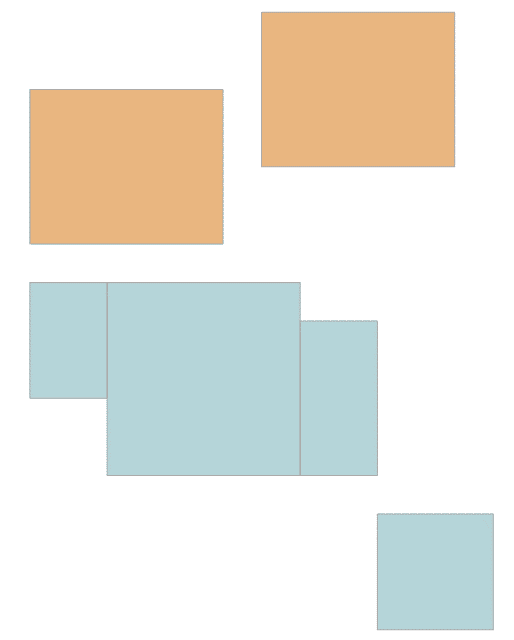
Figure 2: Desired Normalized Schedule
Informally, you’re forming the smallest number of rectangles possible using only vertical cuts. Obviously, you could go for a strategy that uses horizontal cuts. Or even something more sophisticated that uses a combination of vertical and horizontal cuts. Anyway, assuming the vertical-cuts approach, following is the desired output of your solution:
|
1 2 3 4 5 6 7 8 |
student fromdate todate fromperiod toperiod ------- ----------- ----------- ----------- ----------- Amy 1 2 7 9 Amy 3 7 5 9 Amy 8 9 5 8 Amy 10 12 1 3 Ted 1 5 11 14 Ted 7 11 13 16 |
Told you it’s a formidable challenge. Now, to work!
Unpack/Pack Solution for One Dimensional Packing
My approach to solving the two-dimensional packing problem is to rely on a classic technique for handling one-dimensional packing, which you can think of as the Unpack/Pack technique, in multiple steps of the solution. So first, let me describe the Unpack/Pack technique for one-dimensional packing.
Suppose that in our Schedule table you only had period ranges and needed to normalize them. This is of course a completely contrived example, but I’m using it for convenience since we already have sample data available to work with. Here’s a query showing just the periods:
|
1 2 3 |
SELECT id, student, fromperiod, toperiod FROM dbo.Schedule ORDER BY student, fromperiod, toperiod; |
This query generates the following output:
|
1 2 3 4 5 6 7 |
id student fromperiod toperiod ----------- ------- ----------- ----------- 3 Amy 1 3 2 Amy 5 8 1 Amy 7 9 4 Ted 11 14 5 Ted 13 16 |
Suppose that the task was to pack intersecting periods per student. Here’s the desired output of the solution with the packed periods:
|
1 2 3 4 5 |
student fromperiod toperiod ------- ----------- ----------- Amy 1 3 Amy 5 9 Ted 11 16 |
As mentioned earlier, there are many solutions out there for packing intervals. The Unpack/Pack solution involves the following steps:
- Unpack each interval to the individual values that constitute the set.
- Compute a group identifier using a classic islands technique.
- Group the data by the group identifier to form the packed intervals.
Let’s start with Step 1. You’re supposed to unpack each interval to the individual values that constitute the interval set. Recall that an interval is the set of all values between the low and high values representing the interval delimiters. For example, given that our sample data uses an integer type for the period delimiters, Amy’s interval with fromperiod 5 and toperiod 8 should be unpacked to the set {5, 6, 7, 8}.
If you’re using Azure SQL or SQL Server 2022 or above, you can achieve this with the GENERATE_SERIES function, like so:
|
1 2 3 4 |
SELECT S.id, S.student, P.value AS p FROM dbo.Schedule AS S CROSS APPLY GENERATE_SERIES(S.fromperiod, S.toperiod) AS P ORDER BY S.student, p, S.id; |
This query generates the following output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
id student p ----------- ------- ----------- 3 Amy 1 3 Amy 2 3 Amy 3 2 Amy 5 2 Amy 6 1 Amy 7 2 Amy 7 1 Amy 8 2 Amy 8 1 Amy 9 4 Ted 11 4 Ted 12 4 Ted 13 5 Ted 13 4 Ted 14 5 Ted 14 5 Ted 15 5 Ted 16 |
If you don’t have access to the GENERATE_SERIES function, you can either create your own, or use a numbers table.
Step 2 involves computing a unique group identifier per packed interval. Observe that each packed interval contains a consecutive range of unpacked p values, possibly with duplicates. As an example, see Amy’s range between 5 and 9: {5, 6, 7, 7, 8, 8, 9}. The group identifier can be computed as the p value, minus the dense rank value (because there may be duplicates) based on p value ordering, within the student partition. Here’s the query that achieves this, showing also the dense rank values separately for clarity:
|
1 2 3 4 5 6 7 8 |
SELECT S.id, S.student, P.value AS p, DENSE_RANK() OVER(PARTITION BY S.student ORDER BY P.value) AS drk, P.value - DENSE_RANK() OVER(PARTITION BY S.student ORDER BY P.value) AS grp_p FROM dbo.Schedule AS S CROSS APPLY GENERATE_SERIES(S.fromperiod, S.toperiod) AS P ORDER BY S.student, p, S.id; |
This query generates the following output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
id student p drk grp_p ----------- ------- ------ --------- -------- 3 Amy 1 1 0 3 Amy 2 2 0 3 Amy 3 3 0 2 Amy 5 4 1 2 Amy 6 5 1 1 Amy 7 6 1 2 Amy 7 6 1 1 Amy 8 7 1 2 Amy 8 7 1 1 Amy 9 8 1 4 Ted 11 1 10 4 Ted 12 2 10 4 Ted 13 3 10 5 Ted 13 3 10 4 Ted 14 4 10 5 Ted 14 4 10 5 Ted 15 5 10 5 Ted 16 6 10 |
You get a group identifier (grp_p) that is the same per packed interval group and unique per group.
Step 3 then groups the unpacked data by the student and the group identifier, and computes the packed interval delimiters with the MIN(p) an MAX(p) aggregates, like so:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
WITH C AS ( SELECT S.id, S.student, P.value AS p, DENSE_RANK() OVER(PARTITION BY S.student ORDER BY P.value) AS drk, P.value - DENSE_RANK() OVER(PARTITION BY S.student ORDER BY P.value) AS grp_p FROM dbo.Schedule AS S CROSS APPLY GENERATE_SERIES(S.fromperiod, S.toperiod) AS P ) SELECT student, MIN(p) AS fromperiod, MAX(p) AS toperiod FROM C GROUP BY student, grp_p ORDER BY student, fromperiod; |
This query generates the following desired output:
|
1 2 3 4 5 |
student fromperiod toperiod ------- ----------- ----------- Amy 1 3 Amy 5 9 Ted 11 16 |
This technique is obviously not very optimal when the sets representing the intervals can contain large numbers of members. But it works quite well for small sets and is essential for handling the two-dimensional packing challenge.
Solution for Two-Dimensional Packing
Armed with the Unpack/Pack technique, you are ready to tackle the two-dimensional packing task. The trick is to realize that you can use it multiple times in the solution—once per dimension.
In Step 1, you unpack the two-dimensional date range, period range values to the individual date (d), period (p) values. It’s probably easiest to think of this step in graphical terms, as pixelating (thanks Paul for the terminology!) the rectangles representing each student class schedule from Figure 1 shown earlier. Here’s the code to achieve this step:
|
1 2 3 4 5 |
SELECT S.id, S.student, D.value AS d, P.value AS p FROM dbo.Schedule AS S CROSS APPLY GENERATE_SERIES(S.fromdate, S.todate) AS D CROSS APPLY GENERATE_SERIES(S.fromperiod, S.toperiod) AS P ORDER BY S.student, d, p, S.id; |
This query generates the following output:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
id student d p ----------- ------- ----------- ----------- 1 Amy 1 7 1 Amy 1 8 1 Amy 1 9 1 Amy 2 7 1 Amy 2 8 1 Amy 2 9 2 Amy 3 5 2 Amy 3 6 1 Amy 3 7 2 Amy 3 7 1 Amy 3 8 2 Amy 3 8 1 Amy 3 9 2 Amy 4 5 2 Amy 4 6 1 Amy 4 7 2 Amy 4 7 1 Amy 4 8 2 Amy 4 8 1 Amy 4 9 2 Amy 5 5 2 Amy 5 6 1 Amy 5 7 2 Amy 5 7 1 Amy 5 8 2 Amy 5 8 1 Amy 5 9 2 Amy 6 5 2 Amy 6 6 1 Amy 6 7 2 Amy 6 7 1 Amy 6 8 2 Amy 6 8 1 Amy 6 9 2 Amy 7 5 2 Amy 7 6 1 Amy 7 7 2 Amy 7 7 1 Amy 7 8 2 Amy 7 8 1 Amy 7 9 2 Amy 8 5 2 Amy 8 6 2 Amy 8 7 2 Amy 8 8 2 Amy 9 5 2 Amy 9 6 2 Amy 9 7 2 Amy 9 8 3 Amy 10 1 3 Amy 10 2 3 Amy 10 3 3 Amy 11 1 3 Amy 11 2 3 Amy 11 3 3 Amy 12 1 3 Amy 12 2 3 Amy 12 3 ... |
You can use the following helper query to depict Step 1’s result graphically:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
WITH Pixels AS ( SELECT S.id, S.student, D.value AS d, P.value AS p FROM dbo.Schedule AS S CROSS APPLY GENERATE_SERIES(S.fromdate, S.todate) AS D CROSS APPLY GENERATE_SERIES(S.fromperiod, S.toperiod) AS P ) SELECT student, GEOMETRY::STGeomFromText('GEOMETRYCOLLECTION(' + STRING_AGG(CONCAT('POLYGON((', d , ' ', p , ',', d , ' ', p + 1, ',', d + 1, ' ', p + 1, ',', d + 1, ' ', p , ',', d , ' ', p , '))'), ',') + ')', 0) AS shape FROM Pixels GROUP BY student; |
Figure 3 has the graphical result from the Spatial results tab in SSMS.

Figure 3: Pixelated Schedule
Now you need to decide on the normalization strategy that you want to use. Assuming you decide to use what I referred to earlier as the vertical cuts approach, you can proceed to Step 2. To apply vertical cuts, you pack period ranges per student and date. This is achieved by assigning the group identifier grp_p to each distinct range of consecutive p values per student and d group. Here’s the code that achieves this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
WITH PixelsAndPeriodGroupIDs AS ( SELECT S.id, S.student, D.value AS d, P.value AS p, P.value - DENSE_RANK() OVER(PARTITION BY S.student, D.value ORDER BY P.value) AS grp_p FROM dbo.Schedule AS S CROSS APPLY GENERATE_SERIES(S.fromdate, S.todate) AS D CROSS APPLY GENERATE_SERIES(S.fromperiod, S.toperiod) AS P ) SELECT student, d, MIN(p) AS fromperiod, MAX(p) AS toperiod FROM PixelsAndPeriodGroupIDs GROUP BY student, d, grp_p ORDER BY student, d, grp_p; |
Here’s the output of the inner query defining the CTE PixelsAndPeriodGroupIDs, showing the computed grp_p value per pixel, if you will:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
id student d p grp_p ----------- ------- ----------- ----------- -------------------- 1 Amy 1 7 6 1 Amy 1 8 6 1 Amy 1 9 6 1 Amy 2 7 6 1 Amy 2 8 6 1 Amy 2 9 6 2 Amy 3 5 4 2 Amy 3 6 4 2 Amy 3 7 4 1 Amy 3 7 4 1 Amy 3 8 4 2 Amy 3 8 4 1 Amy 3 9 4 2 Amy 4 5 4 2 Amy 4 6 4 2 Amy 4 7 4 1 Amy 4 7 4 1 Amy 4 8 4 2 Amy 4 8 4 1 Amy 4 9 4 2 Amy 5 5 4 2 Amy 5 6 4 2 Amy 5 7 4 1 Amy 5 7 4 1 Amy 5 8 4 2 Amy 5 8 4 1 Amy 5 9 4 2 Amy 6 5 4 2 Amy 6 6 4 2 Amy 6 7 4 1 Amy 6 7 4 1 Amy 6 8 4 2 Amy 6 8 4 1 Amy 6 9 4 2 Amy 7 5 4 2 Amy 7 6 4 2 Amy 7 7 4 1 Amy 7 7 4 1 Amy 7 8 4 2 Amy 7 8 4 1 Amy 7 9 4 2 Amy 8 5 4 2 Amy 8 6 4 2 Amy 8 7 4 2 Amy 8 8 4 2 Amy 9 5 4 2 Amy 9 6 4 2 Amy 9 7 4 2 Amy 9 8 4 3 Amy 10 1 0 3 Amy 10 2 0 3 Amy 10 3 0 3 Amy 11 1 0 3 Amy 11 2 0 3 Amy 11 3 0 3 Amy 12 1 0 3 Amy 12 2 0 3 Amy 12 3 0 … |
And here’s the output of outer query, showing the packed period ranges after grouping:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
student d fromperiod toperiod ------- ----------- ----------- ----------- Amy 1 7 9 Amy 2 7 9 Amy 3 5 9 Amy 4 5 9 Amy 5 5 9 Amy 6 5 9 Amy 7 5 9 Amy 8 5 8 Amy 9 5 8 Amy 10 1 3 Amy 11 1 3 Amy 12 1 3 Ted 1 11 14 Ted 2 11 14 Ted 3 11 14 Ted 4 11 14 Ted 5 11 14 Ted 7 13 16 Ted 8 13 16 Ted 9 13 16 Ted 10 13 16 Ted 11 13 16 |
What’s important to note here is that you created packed period ranges per student and date. This is convenient to depict graphically using the following spatial query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
WITH PixelsAndPeriodGroupIDs AS ( SELECT S.id, S.student, D.value AS d, P.value AS p, P.value - DENSE_RANK() OVER(PARTITION BY S.student, D.value ORDER BY P.value) AS grp_p FROM dbo.Schedule AS S CROSS APPLY GENERATE_SERIES(S.fromdate, S.todate) AS D CROSS APPLY GENERATE_SERIES(S.fromperiod, S.toperiod) AS P ), DailyPeriodRanges AS ( SELECT student, d, MIN(p) AS fromperiod, MAX(p) AS toperiod FROM PixelsAndPeriodGroupIDs GROUP BY student, d, grp_p ) SELECT student, GEOMETRY::STGeomFromText('GEOMETRYCOLLECTION(' + STRING_AGG(CONCAT('POLYGON((',d,' ',fromperiod , ',', d,' ',toperiod + 1,',', d + 1,' ',toperiod + 1, ',', d + 1,' ',fromperiod ,',', d,' ',fromperiod,'))'),',') + ')', 0) AS shape FROM DailyPeriodRanges GROUP BY student; |
The output from the Spatial results tab in SSMS shown in Figure 4.
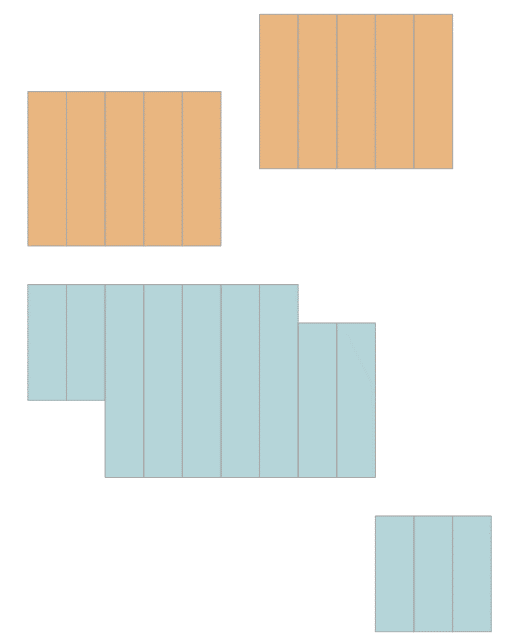
Figure 4: Daily Period Ranges
What you achieved here is sort of daily binning (again, thanks Paul for the terminology) of the packed period ranges. What’s left then in Step 3, is to pack consecutive date ranges per student and period range. Here’s the code to achieve this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
WITH PixelsAndPeriodGroupIDs AS ( SELECT S.id, S.student, D.value AS d, P.value AS p, P.value - DENSE_RANK() OVER(PARTITION BY S.student, D.value ORDER BY P.value) AS grp_p FROM dbo.Schedule AS S CROSS APPLY GENERATE_SERIES(S.fromdate, S.todate) AS D CROSS APPLY GENERATE_SERIES(S.fromperiod, S.toperiod) AS P ), PeriodRangesAndDateGroupIDs AS ( SELECT student, d, MIN(p) AS fromperiod, MAX(p) AS toperiod, D - DENSE_RANK() OVER(PARTITION BY student, MIN(p), MAX(p) ORDER BY d) as grp_d FROM PixelsAndPeriodGroupIDs GROUP BY student, d, grp_p ) SELECT student, MIN(d) AS fromdate, MAX(d) AS todate, fromperiod, toperiod FROM PeriodRangesAndDateGroupIDs GROUP BY student, fromperiod, toperiod, grp_d ORDER BY student, fromdate, fromperiod; |
The main trick here is that in the second CTE (PeriodRangesAndDateGroupIDs), where you apply the classic islands technique a second time, when computing the dense rank value, you partition it by the student and the period range (student, MIN(p), MAX(p)), and order it by d.
Here’s the output of the second CTE’s inner query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
student d fromperiod toperiod grp_d ------- ----------- ----------- ----------- ---------- Amy 10 1 3 9 Amy 11 1 3 9 Amy 12 1 3 9 Amy 8 5 8 7 Amy 9 5 8 7 Amy 3 5 9 2 Amy 4 5 9 2 Amy 5 5 9 2 Amy 6 5 9 2 Amy 7 5 9 2 Amy 1 7 9 0 Amy 2 7 9 0 Ted 1 11 14 0 Ted 2 11 14 0 Ted 3 11 14 0 Ted 4 11 14 0 Ted 5 11 14 0 Ted 7 13 16 6 Ted 8 13 16 6 Ted 9 13 16 6 Ted 10 13 16 6 Ted 11 13 16 6 |
And here’s the output of the outer query, showing the final desired result with the normalized schedule:
|
1 2 3 4 5 6 7 8 |
student fromdate todate fromperiod toperiod ------- ----------- ----------- ----------- ----------- Amy 1 2 7 9 Amy 3 7 5 9 Amy 8 9 5 8 Amy 10 12 1 3 Ted 1 5 11 14 Ted 7 11 13 16 |
If you wish to illustrate the result graphically, you can use the following helper spatial query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
WITH PixelsAndPeriodGroupIDs AS ( SELECT S.id, S.student, D.value AS d, P.value AS p, P.value - DENSE_RANK() OVER(PARTITION BY S.student, D.value ORDER BY P.value) AS grp_p FROM dbo.Schedule AS S CROSS APPLY GENERATE_SERIES(S.fromdate, S.todate) AS D CROSS APPLY GENERATE_SERIES(S.fromperiod, S.toperiod) AS P ), PeriodRangesAndDateGroupIDs AS ( SELECT student, d, MIN(p) AS fromperiod, MAX(p) AS toperiod, d - DENSE_RANK() OVER(PARTITION BY student, MIN(p), MAX(p) ORDER BY d) as grp_d FROM PixelsAndPeriodGroupIDs GROUP BY student, d, grp_p ), NormalizedSchedule AS ( SELECT student, MIN(d) AS fromdate, MAX(d) AS todate, fromperiod, toperiod FROM PeriodRangesAndDateGroupIDs GROUP BY student, fromperiod, toperiod, grp_d ) SELECT student, GEOMETRY::STGeomFromText('GEOMETRYCOLLECTION(' + STRING_AGG(CONCAT('POLYGON((',fromdate,' ',fromperiod,',', fromdate,' ',toperiod+1,',', todate + 1,' ',toperiod+1,',', todate + 1,' ',fromperiod,',', fromdate , ' ', fromperiod , '))'), ',') + ')', 0) AS shape FROM NormalizedSchedule GROUP BY student; |
The output in the Spatial results tab in SSMS is the same as what I’ve shown earlier in Figure 2 as the graphical depiction of the desired result.
Conclusion
Thanks again to Paul Wilcox for introducing the two-dimensional packing challenge. It’s a beautiful puzzler and I enjoyed very much working on it. I hope that’s the case for you too.
You saw how important it is to develop a toolbox of fundamental techniques, such as the classic islands technique, and based on it, the Unpack/Pack technique. Those were essential for solving this more complex challenge. You also saw how useful it can be to think of some tasks in graphical terms, and even utilize T-SQL spatial tools for this purpose.
Happy querying!
FAQs
1. What is the interval packing problem in SQL?
Interval packing is the task of consolidating groups of overlapping or adjacent intervals into their continuous equivalents. Given a set of intervals (e.g., sessions 9-11, 10-12, 14-16), packing produces the minimum set of non-overlapping intervals that cover the same points (9-12, 14-16). It’s common in scheduling, resource allocation, billing consolidation, and time-series analysis. The one-dimensional version has established T-SQL solutions; the two-dimensional extension – where intervals span two axes such as date-and-period – is less commonly documented.
2. What is the Unpack/Pack technique in SQL Server?
Unpack/Pack is a set-based interval-packing technique where you: (1) Unpack – convert each interval into a row per discrete unit point it covers (so interval 5-8 becomes rows for 5, 6, 7, 8); (2) apply a gaps-and-islands analysis to group consecutive points into islands; (3) Pack – convert each island back into an interval by taking its MIN and MAX. The technique is purely set-based (no cursors) and scales well on modern SQL Server. The article demonstrates applying it iteratively across two dimensions by repeating the process along the second axis after packing the first.
3. How do you pack intervals across two dimensions in SQL Server?
Apply the Unpack/Pack technique to one dimension first, then apply it again to the result in the second dimension. For student scheduling with date and period axes: first unpack each schedule record into per-day-per-period rows, pack those into contiguous date runs per period per student, then unpack those by period and pack into contiguous period runs. The result is the minimum set of two-dimensional rectangles that cover the original input. The key insight is that two-dimensional packing reduces to two sequential one-dimensional packings if the ordering is chosen correctly.
4. Can I solve interval packing without using cursors?
Yes. All efficient interval-packing solutions in SQL Server are fully set-based – no cursors needed. The Unpack/Pack approach, LAG-based consecutive-row comparisons, and row-number difference techniques (borrowed from gaps-and-islands analysis) all operate on the input set as a whole. Cursor-based solutions exist but are much slower and should not be used in production. For large datasets (millions of rows), index the sort column used in the packing step and ensure statistics are current – the SQL Server query optimiser handles the rest.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments