
Editor’s note: This article was written against SQL Server 2017 CTP 2.1. SQL Server 2019 and later versions have added significant graph improvements including SHORTEST_PATH, edge constraints, and merge DML. For current coverage, see our 5-part SQL Server Graph Databases series starting with Part 1: Introduction.
SQL Server 2017 introduced graph database support through node tables (CREATE TABLE…AS NODE) and edge tables (CREATE TABLE…AS EDGE), with the MATCH clause for traversing relationships. This article builds a forum example comparing the relational and graph approaches side by side, evaluating both the strengths (simpler relationship queries, natural many-to-many modeling) and the limitations (no edge constraints, no DML support for MERGE, limited tooling) of the initial implementation.
Introduction
SQL Server 2017 will be bringing us support for some of the functionality of graph databases. Graph databases are unlike relational databases in that they represent data as nodes, edges and properties within a ‘graph’, which is an abstract data type representing relationships or connections as a set of vertices nodes, points and edges, like a tangled fish-net. They allow us to represent and traverse relationships between entities in easier ways than is possible with the traditional relational database.
Graph objects are built to represent complex relationships. A hierarchy is a special case of a graph and is useful to record such things as relationship between forum posts and their replies, likes in forum posts, and friendship between people. Hierarchies have a root node (forum post and replies, for example), but many graphs don’t have a root node (people friendship, for example).
In this article, we’ll be building a forum example using the new graph model. I will also compare the complexity of the queries between the graph and a relational model and calling your attention for what’s still missing in this first version. Yes, it’s a Beta technology in its early stages.
Demonstration Environment
I’m using SQL Server 2017 CTP 2.1 which you can download here: https://www.microsoft.com/en-us/sql-server/sql-server-2017
I’m also using SSMS v. 17.0 which you can download here: https://docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
Creating the models
This is the Entity-relationship model I will use for comparison:
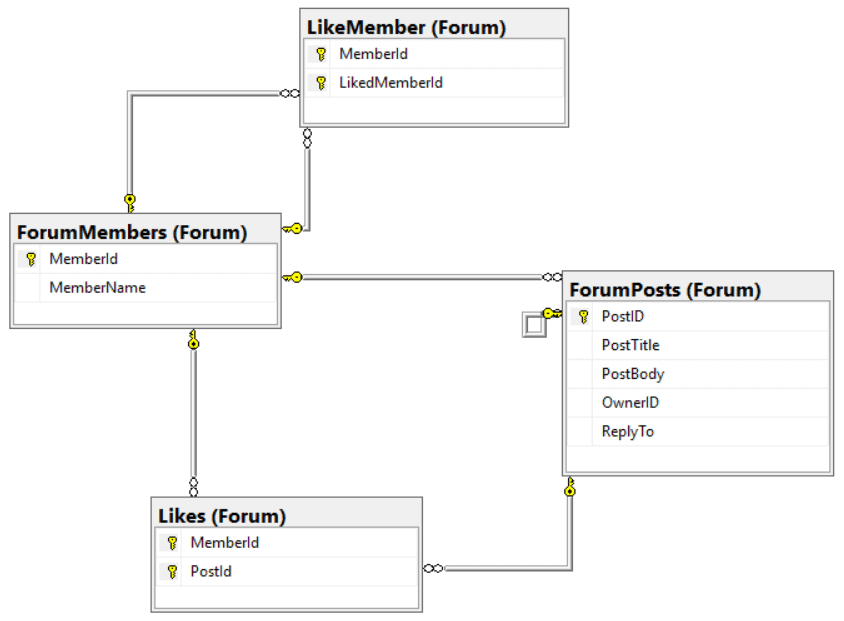
If you would like to follow along and try out some comparisons, you can create this entity-relational model with the script below, or you can go directly to the graph model. However, you need to create the new database, ‘GraphExample’, using SSMS.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
create database GraphExample go -- Trying an entire graph model use GraphExample go create schema Forum go create table Forum.ForumMembers (MemberId int not null primary key Identity(1,1), MemberName varchar(100)) go create table Forum.ForumPosts ([PostID] int not null primary key, PostTitle varchar(100), PostBody varchar(100), OwnerID int, ReplyTo int) go Create table Forum.Likes (MemberId int, PostId int) go create table Forum.LikeMember (MemberId int, LikedMemberId int) go INSERT Forum.ForumMembers values('Mike'),('Carl'),('Paul'),('Christy'),('Jennifer'),('Charlie') go INSERT INTO [Forum].[ForumPosts] ( [PostID] ,[PostTitle] ,[PostBody],OwnerID, ReplyTo ) VALUES (4,'Geography','Im Christy from USA',4,null), (1,'Intro','Hi There This is Carl',2,null) INSERT INTO [Forum].[ForumPosts] ( [PostID] ,[PostTitle] ,[PostBody],OwnerID, ReplyTo ) VALUES (8,'Intro','nice to see all here!',1,1), (7,'Intro','I''m Mike from Argentina',1,1), (6,'Re:Geography','I''m Mike from Argentina',1,4), (5,'Re:Geography','I''m Jennifer from Brazil',5,4), (3,'Re: Intro','Hey Paul This is Christy',4,2), (2,'Intro','Hello I''m Paul',3,1) go INSERT Forum.Likes VALUES (1,4), (2,7), (2,8), (2,2), (4,5), (4,6), (1,2), (3,7), (3,8), (5,4) go Insert Forum.LikeMember VALUES (2,1), (2,3), (4,1), (4,5) |
The Graph Model
The planning of a graph model is quite different than the relational model. Tables in a graph model can be Edges or Nodes, we need to decide which tables will be edges and which tables will be nodes.
This image illustrates our graph model:
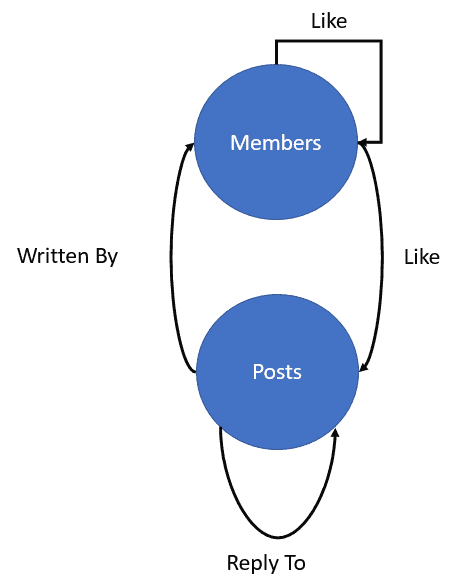
The decision between nodes and edges in our model is simple: All the entities in a logical model will be nodes, while all the relations in the logical model will be edges. In our model, we have ‘Posts’ and ‘Members’ as entities, ‘Reply To’, ‘Like’ and ‘Written By’ as relations.
Read also: SQL Server Graph Databases series
Architectural Notes
Nodes and Edges are nothing more than tables with some special fields. There’s no restriction that forbids us to create regular relationships between these tables, turning the model into a mix of relational and graph model.
For example, the relationship ‘Written By’ between ‘Posts’ and ‘Members’ is a simple one-to-many relationship. Instead of using an edge table, we could express it with a regular relation between these tables, creating a mixed model.
When we create a node entity, the entity receives a calculated field named ‘$node_id’. We could use this field as a primary key, SQL Server allows calculated fields to be the primary key of a table: However this field is a JSON field, which is not a good option for primary key for many reasons. For this reason, our nodes have to maintain two keys: The business key, an integer, and the ‘$node_id’ key, an auto-generated JSON key that also contains an integer.
This will be the script for our node entities:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Use GraphExample go CREATE TABLE [dbo].[ForumMembers]( [MemberID] [int] IDENTITY(1,1) NOT NULL, [MemberName] [varchar](100) NULL ) AS NODE GO CREATE TABLE [dbo].[ForumPosts]( [PostID] [int] NULL, [PostTitle] [varchar](100) NULL, [PostBody] [varchar](1000) NULL ) AS NODE |
Architectural Notes
After creating the objects, you can then examine the objects in Object Explorer. You may notice a new folder called ‘Graph’ inside the ‘Tables’ folder. All graph objects will be inside this folder.
You may also notice the name of the auto-generated fields. Although we can reference these fields with their short-name, for example, $node_id, the real name of the field includes a GUID. This short name is a pseudo-column and we can use it in our queries.
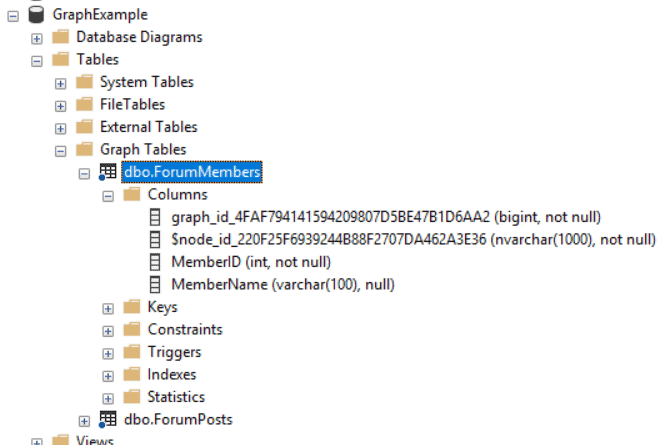
It is simple to insert the values into the node tables: We just ignore the pseudo-column ($node_id) and write simple INSERT statements. These will be our INSERTs:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
INSERT ForumMembers values ('Mike'),('Carl'),('Paul'),('Christy'),('Jennifer'),('Charlie') INSERT INTO [dbo].[ForumPosts] ( [PostID] ,[PostTitle] ,[PostBody] ) VALUES (8,'Intro','nice to see all here!'), (7,'Intro','I''m Mike from Argentina'), (6,'Re:Geography','I''m Mike from Argentina'), (5,'Re:Geography','I''m Jennifer from Brazil'), (4,'Geography','Im Christy from USA'), (3,'Re: Intro','Hey Paul This is Christy'), (1,'Intro','Hi There This is Carl') (2,'Intro','Hello I''m Paul') |
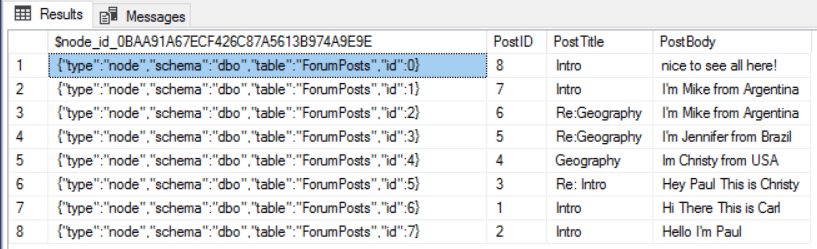
You will see the result of SELECTing the records from the ForumPosts table in the image below. You may notice the field $node_id, a JSON field including the type of the entity and an integer id that is automatically generated.
Creating the Edge tables
The edge tables are very simple to create. Edge tables can have properties that would be regular fields in the table, however that’s not part of our example. This will be the script to create our edge tables:
|
1 2 3 4 5 6 7 8 |
Create table dbo.[Written_By] as EDGE CREATE TABLE [dbo].[Likes] AS EDGE CREATE TABLE [dbo].[Reply_To] AS EDGE |
Each edge table has three pseudo-columns that we need to deal with:
- $edge_id: The id of the edge record
- $from_id: One of the nodes in the edge record
- $to_id: The other node in the edge record
Noticing this definition, you may be asking: “Oh, ‘One of the nodes’ is quite vague, isn’t it?”. Yes, sure! That’s an important point: We need to define, in a logical way, what the $to_id and $from_id fields for each edge will mean. You may also be noticing that the name of the edge tables already defines the $to_id and $from_id sides. This is a logical choice of the sides and a good use of the names to make things easier for us.
These will be our logical definitions:
Written_By:
$from_id will be the post
$to_id will be the member
Likes:
$from_id will be who likes
$to_id will be who/what is liked
Reply_To:
$from_id will be the reply to the main post
$to_id will be the main post
There is no technical restriction about these choices, but we need to keep them when inserting new records, never mixing the meaning of each side of the relation.
Read also: Closure tables as alternative hierarchy approach
Architectural Notes
Besides the three pseudo-columns, all edge tables have some more fields, all of them are hidden fields.
We can see the hidden definition in the field properties and these hidden fields will not appear in query results.
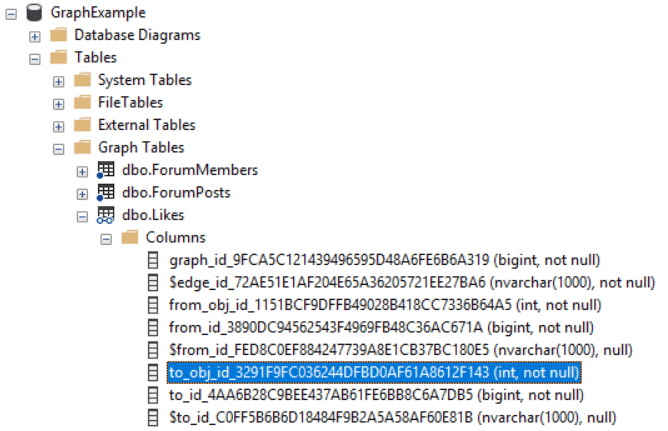

Inserting Edge records
The insert statement for the edge tables needs to fill both sides of the edge, $From_id and $To_id. These fields need to be filled with the $node_id value of the record of each side.
For example, to relate a member with a forum post, the ‘Written_By’ record will have the $node_id value of the post in the $From_id field and the $node_id value of the member in the $To_id field.
These will be the inserts:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
Insert into Written_By ($to_id,$from_id) values ( (select $node_id from dbo.ForumMembers where MemberId= 1 ), (select $node_id from dbo.ForumPosts where PostID=8 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=1 ), (select $node_id from dbo.ForumPosts where PostID=7 ) ), ( (select $node_id from dbo.ForumMembers where MemberId= 1 ), (select $node_id from dbo.ForumPosts where PostID= 6) ), ( (select $node_id from dbo.ForumMembers where MemberId=5 ), (select $node_id from dbo.ForumPosts where PostID=5 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=4 ), (select $node_id from dbo.ForumPosts where PostID=4 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=3 ), (select $node_id from dbo.ForumPosts where PostID=3 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=3 ), (select $node_id from dbo.ForumPosts where PostID=1 ) ), ( (select $node_id from dbo.ForumMembers where MemberId=3 ), (select $node_id from dbo.ForumPosts where PostID=2 ) ) |
Architectural Notes
It’s complex to build INSERTs like these, isn’t it? We will want to use an object framework with support for graph objects in the database. Today entity framework hasn’t got this feature, but we can expect to see something new about this in a while, either as a new feature for entity framework or as a new object model to map graph objects.
Let’s insert the replies records:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
INSERT Reply_To ($to_id,$from_id) VALUES ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4), (SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 6)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 1), (SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 1), (SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 1), (SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4), (SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 5)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2), |
(SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 3))
Finally, a let’s insert a lot of likes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
INSERT Likes ($to_id,$from_id) VALUES ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 5), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 6), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 2), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 3)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 3)), ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 5)) |
The ‘Likes’ edge illustrates the capabilities of the edge feature rather well. We just inserted several relations between members and posts, but we now decide that in the application a member can also like another member. No problem, we can use the same edge to relate one member to another. In the relational model we need two tables for this, in the graph model, only a single edge.
Let’s insert more likes, now between members of the forum:
|
1 2 3 4 5 6 7 8 9 10 |
INSERT Likes ($to_id,$from_id) VALUES ((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)), ((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 3), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 2)), ((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 1), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)), ((SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 5), (SELECT $node_id FROM dbo.ForumMembers WHERE MemberID = 4)) |
The Good: Building queries over the Graph Model
T-SQL brings some new syntax elements into use to query graph tables. We have a special statement to relate nodes and edges in a SELECT.
Let’s do a walkthrough to build a query that retrieves all the posts and their replies:
- We will retrieve two posts in each record, the post and the reply, so we will need two references to the ‘ForumPosts’ table in the FROM clause of the select. Let’s do it with some meaningful aliases:
1FROM dbo.ForumPosts ReplyPost, dbo.ForumPosts RepliedPostAlthough we can, of course, use any alias we choose, it is best to use meaningful aliases when working with graph objects.
- We need the relation between the posts, the relation is the table ‘Reply_to’.
1FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost - In the WHERE clause, we need to relate all the tables. We can do this with the new MATCH clause:
1FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost<br>WHERE MATCH(ReplyPost-(Reply_to)->RepliedPost)The syntax is interesting: A single “-” (dash) means a relation with the $From_id field of the edge, and a dash and greather-than (->) means a relation with the $To_id field of the edge
- Knowing which alias has the reply and which alias has the replied post, we can build the field list of the query.
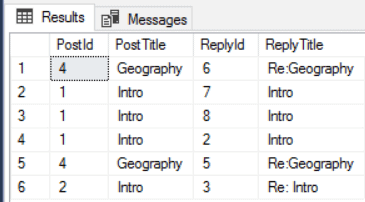
1-- Posts and their replies<br> select RepliedPost.PostId,RepliedPost.PostTitle,<br> ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle<br> From dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost<br> Where Match(ReplyPost-(Reply_to)->RepliedPost)The same query in the relational model would be like this:
1select RepliedPost.PostId,RepliedPost.PostTitle,<br> ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle<br> from Forum.ForumPosts ReplyPost, Forum.ForumPosts RepliedPost<br> where ReplyPost.PostId=RepliedPost.ReplyToThese queries are very similar, although it’s possible to argue that the MATCH syntax is easier to understand
- We can already execute this query. The result will be like the image below:
- Let’s include the name of the member who wrote the replied post. We need to include the ‘ForumMembers’ node and the ‘Written_By’ edge in the FROM clause. The new FROM clause will be like this:
1FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost, dbo.ForumMembers RepliedMember, Written_By RepliedWritten_By - Include the relation inside the MATCH clause:
1WHERE MATCH(ReplyPost-(Reply_to)->RepliedPost-(RepliedWritten_by)->RepliedMember) - Include the member name of the replied post in the field list of the SELECT. The final query will be this:
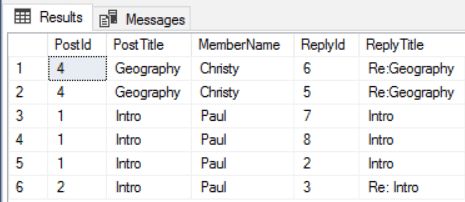
1-- Posts and members and their replies<br> SELECT RepliedPost.PostId,RepliedPost.PostTitle,RepliedMember.MemberName,<br> ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle<br> FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost, <br> dbo.ForumMembers RepliedMember, Written_By RepliedWritten_By<br> WHERE MATCH(ReplyPost-(Reply_to)->RepliedPost-(RepliedWritten_by)->RepliedMember)The same query against the relational model:
1SELECT RepliedPost.PostId,RepliedPost.PostTitle,<br> ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle, <br> RepliedMember.MemberName<br> FROM Forum.ForumPosts ReplyPost, Forum.ForumPosts RepliedPost, <br> Forum.ForumMembers RepliedMember<br> WHERE ReplyPost.PostId=RepliedPost.ReplyTo<br> and RepliedPost.OwnerId=RepliedMember.MemberIdThe image below shows the result:
- We still need to include the member name of the reply post. Again, we need to include the ‘ForumMembers’ and the ‘Written_By’ tables in the FROM clause:
1From dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost,<br>dbo.ForumMembers RepliedMember, Written_By RepliedWritten_By,<br>dbo.ForumMembers ReplyMember, Written_By ReplyWritten_By - The next step is correcting the MATCH clause. ‘ReplyMember’ needs to be related to ‘ReplyPost’, however, how to do this relation without breaking the others? Let’s do in a different direction:
1WHERE MATCH(ReplyMember<-(ReplyWritten_By)-ReplyPost-(Reply_to)->RepliedPost-(RepliedWritten_by)->RepliedMember)Notice the <- symbol. It’s in opposite direction than ->, however it’s the same meaning: a relation between $to_id of the edge table with the node table.
- Finally, let’s include the name of the member who wrote the reply in the field list and execute the query:
1-- Posts and members and their replies and members<br> SELECT RepliedPost.PostId, RepliedPost.PostTitle,RepliedMember.MemberName,<br> ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle,<br> ReplyMember.MemberName [ReplyMemberName]<br> FROM dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost, <br> dbo.ForumMembers RepliedMember, Written_By RepliedWritten_By, <br> dbo.ForumMembers ReplyMember, Written_By ReplyWritten_By<br> WHERE MATCH(ReplyMember<-(ReplyWritten_By)-ReplyPost-(Reply_to)->RepliedPost-(RepliedWritten_by)->RepliedMember)The result is the following:
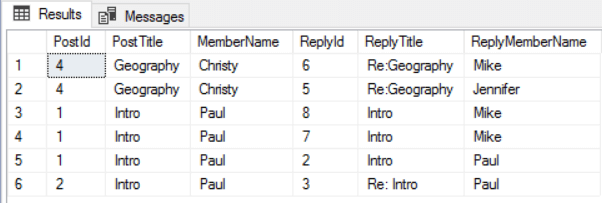
The same query against the relational model:
1SELECT RepliedPost.PostId,RepliedPost.PostTitle, <br> RepliedMember.MemberName, ReplyPost.PostId as ReplyId, <br> ReplyPost.PostTitle as ReplyTitle, ReplyMember.MemberName<br> FROM Forum.ForumPosts ReplyPost, Forum.ForumPosts RepliedPost, <br> Forum.ForumMembers RepliedMember, Forum.ForumMembers ReplyMember<br> WHERE ReplyPost.PostId=RepliedPost.ReplyTo<br> and RepliedPost.OwnerId=RepliedMember.MemberId<br> and ReplyPost.OwnerId=ReplyMember.MemberIdAt this point you may be noticing that according to the increasing of the number of relations the WHERE clause in the relational model will be much harder to read than the MATCH clause in the graph model.
Let’s see some more interesting and useful queries against the graph model.
Count of Replies of each Post
|
1 2 3 4 5 6 7 |
-- Count of replies of each post SELECT distinct RepliedPost.PostID,RepliedPost.PostTitle, RepliedPost.PostBody, count(ReplyPost.PostID) over(partition by RepliedPost.PostID) as TotalReplies FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost WHERE MATCH(ReplyPost-(Reply_To)->RepliedPost) |
In this one we have the count of replies in each post, however only in a single level, not in a tree of replies.
List of Root Posts
We can get all the root posts without the MATCH syntax:
|
1 2 3 4 |
-- All the root posts SELECT Post1.PostId,Post1.PostTitle FROM dbo.ForumPosts Post1 WHERE $node_id not in (select $from_id from dbo.Reply_To) |
The MATCH syntax only allows us to relate three or more entities (two nodes and one relation). When we want to relate only two of them, we can do a regular join or sub-query, as the above.
Including a Level field in the result
It can be useful to include a ‘Level’ field to expose the structure as a tree. We have a syntax for this in T-SQL: The recursive CTE (Common Table Expression).
However, there is a catch: We can’t use the MATCH syntax over a derived table, in this case the CTE. We can, if needed, use the MATCH syntax in the CTE, but we can’t reference the CTE in it. This is a limitation.
We can, however, use the recursive CTE syntax without be MATCH syntax, using regular relations. The result will be this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
-- All replies with tree level with root as ( select $node_id as node_id,RootPosts.PostId, RootPosts.PostTitle, 1 as Level, 0 as ReplyTo from dbo.ForumPosts RootPosts where $node_id not in (select $from_id from dbo.reply_to) union all select $node_id,ReplyPost.PostId, ReplyPost.PostTitle, Level+1 as [Level], root.PostId as ReplyTo from dbo.ForumPosts ReplyPost, reply_to, root where ReplyPost.$node_id=reply_to.$from_id and root.node_id=reply_to.$to_id ) select PostId,PostTitle, Level, ReplyTo from root |
Retrieve all replies of a single post
Using the recursive CTE syntax, we can retrieve all the replies of a single post in a tree style. If we try to retrieve all replies of post 1 using a regular syntax we won’t retrieve the post 3 and we should, because post 3 is a reply to post 2, which is a reply to post 1.
We can only retrieve post 3 when querying the replies of post 1 using the recursive CTE syntax.
This will be the query to retrieve all replies of a single post:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- All replies of a single post with root as ( select $node_id as node_id,RootPosts.PostId,RootPosts.PostTitle, 1 as Level, 0 as ReplyTo from dbo.ForumPosts RootPosts where PostId=1 union all select $node_id,ReplyPost.PostId, ReplyPost.PostTitle, Level+1 as [Level],root.PostId as ReplyTo from dbo.ForumPosts ReplyPost, reply_to, root where ReplyPost.$node_id=reply_to.$from_id and root.node_id=reply_to.$to_id ) select PostId,PostTitle, Level, ReplyTo from root |
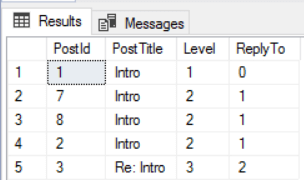
We can also do it in reverse, in order to retrieve all parent posts of a single post in a tree structure. For this we need to do the relations inside the CTE to retrieve the posts and at the outside do some OUTER JOINs to retrieve the parent of each post. It needs to be an OUTER JOIN because the main post has no parent. It also needs to be in the outside of the CTE because the recursive part of the CTE doesn’t support OUTER JOINs.
This brings another point to our attention: There isn’t an OUTER in the MATCH syntax.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
-- All the parents of a single post, with reference to their parents with root as ( select LeafPost.$node_id as node_id,LeafPost.PostId, LeafPost.PostTitle from dbo.ForumPosts LeafPost where LeafPost.PostId=3 -- Single post union all select RepliedPost.$node_id as node_id,RepliedPost.PostId, RepliedPost.PostTitle from dbo.ForumPosts RepliedPost, Reply_to, root where root.node_id=Reply_to.$from_id and Reply_to.$to_id=RepliedPost.$node_id ) select root.PostId,root.PostTitle, RepliedPost.PostId ParentPostId from root left join reply_to on root.node_id=reply_to.$from_id left join dbo.ForumPosts RepliedPost on reply_to.$to_id=RepliedPost.$node_id |
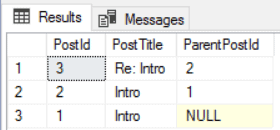
Recovering the posts of a single user
Recovering the information of a single user, instead of a post, is easier because there isn’t a tree in this situation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- All Post replied by Peter SELECT distinct RepliedPost.PostID,RepliedPost.PostTitle, RepliedPost.PostBody FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost, dbo.ForumMembers Members,Written_By WHERE MATCH(Members<-(Written_By)-ReplyPost-(Reply_To)->RepliedPost) and Members.MemberName='Peter' -- All replies made by Peter SELECT ReplyPost.PostID,ReplyPost.PostTitle,ReplyPost.PostBody, RepliedPost.PostId ReplyTo FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost, dbo.ForumMembers Members,Written_By WHERE MATCH(Members<-(Written_By)-ReplyPost-(Reply_To)->RepliedPost) and Members.MemberName='Peter' |
You may notice the only difference between the queries above is the field list and the use of DISTINCT. The DISTINCT is needed because Peter can reply the same post more than once.
Retrieving the Likes from the model
The queries to retrieve the ‘Likes’ are interesting: The ‘Likes’ edge has relations between members and between members and posts. Each of these selects brings only one of these kinds of relation and ignores the other.
|
1 2 3 4 5 6 7 8 9 10 |
-- All posts that have likes and who liked them SELECT Post.PostID,Post.PostTitle,Member.MemberName FROM dbo.ForumPosts Post, Likes, dbo.ForumMembers Member WHERE MATCH(Member-(Likes)->Post) -- All members that have likes and who liked them SELECT Member.MemberId,Member.MemberName LikeMember, LikedMember.MemberName LikedMemberName FROM dbo.ForumMembers Member, Likes, dbo.ForumMembers LikedMember WHERE MATCH(Member-(Likes)->LikedMember) |
It is also easy to aggregate the information to get the total of likes of each post or each member.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- Total likes of each Post select Post.PostId,Post.PostTitle, count(*) totalLikes from dbo.ForumPosts Post,Likes, dbo.ForumMembers Members where Match(Members-(Likes)->Post) group by PostId,PostTitle -- Total likes of each Member select LikedMembers.MemberId,LikedMembers.MemberName, count(*) totalLikes from dbo.ForumMembers Members,Likes, dbo.ForumMembers LikedMembers where Match(Members-(Likes)->LikedMembers) group by LikedMembers.MemberId, LikedMembers.MemberName |
Members who liked and replied to the same post
We can build even some more interesting queries. For example, who are the members who liked and replied to a post?
This is the query:
|
1 2 3 4 5 6 7 |
-- Members who liked and replied on same post SELECT Member.MemberName,Member.Memberid, LikedPost.PostId,LikedPost.PostTitle, ReplyPost.PostTitle ReplyTitle FROM dbo.ForumPosts LikedPost, Reply_To, dbo.ForumPosts ReplyPost, Likes, dbo.ForumMembers Member, Written_By WHERE MATCH(Member-(Likes)->LikedPost<-(Reply_To)-ReplyPost-(Written_By)->Member) |
You may notice the use of the node ‘Member’ two times in the same MATCH expression. This creates a kind of a filter: The member who liked the ‘LikedPost’ needs to be the same member who wrote the ‘ReplyPost’.
This one, over the relational model, would be like this:
|
1 2 3 4 5 6 |
select Likes.MemberId,Members.MemberName from Forum.Likes Likes, Forum.ForumPosts Posts, Forum.ForumMembers Members where Likes.MemberId=Posts.OwnerId and Posts.ReplyTo=Likes.PostId and Members.MemberId=Likes.MemberId |
It seems for me more difficult to build and read over the relational model.
Members who replied to multiple posts
|
1 2 3 4 5 6 7 |
SELECT Members.MemberId, Members.MemberName, Count(distinct RepliedPost.PostId) as Total FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost, Written_By,dbo.ForumMembers Members WHERE MATCH(Members<-(Written_By)-ReplyPost-(Reply_To)->RepliedPost) GROUP BY MemberId, Members.MemberName Having Count(RepliedPost.PostId) >1 |
Members who replied multiple times to the same post:
|
1 2 3 4 5 6 7 |
SELECT Members.MemberId, Members.MemberName, RepliedPost.PostId RepliedId,count(*) as TotalReplies FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost, Written_By,dbo.ForumMembers Members WHERE MATCH(Members<-(Written_By)-ReplyPost-(Reply_To)->RepliedPost) GROUP BY MemberId,MemberName,RepliedPost.PostId Having count(*) >1 |
The only differences between the two above are the field list and aggregation.
Missing features for queries
You probably don’t like the requirement to use recursive CTE to retrieve a tree of nodes. That’s because a feature called transitive closure, usually present in graph databases, isn’t available in this first version.
The ability to find any type of node connected to a single node, for example, all replies and likes of a post, is called polymorphism and isn’t available in this version. We can use UNION to solve this for small sets of node types.
Some graph-specific functions, such as the ability to find the ‘shortest path’ between two forum members, isn’t available in this version.
The Bad: Edge records validation
As well as all the missing features, with a lot of room for improvement, I found problems with the validation of the relations inserted in the model. You may have noticed that it’s too easy to create an edge table. That’s because we don’t need to identify the possible relations of that edge.
This creates some validation problems. For example, the ‘Reply_To’ edge: A forum message can be a reply to another single forum message, however, I shouldn’t be able to insert the same forum message as a reply of two others.
The model doesn’t validate this. We shouldn’t be able to execute the insert below because the message ‘3’ is already a reply to message ‘2’. However, the insert will work:
|
1 2 3 |
Insert Reply_to Values ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 3), (SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4)) |
After trying the insert, delete the inserted record:
|
1 2 3 4 5 6 |
delete reply_to from reply_to, dbo.forumposts replypost, dbo.forumposts repliedpost where MATCH(replypost-(reply_to)->repliedpost) and replypost.postid=3 and repliedpost.postid=4 |
How can we solve this problem?
The graph calculated field doesn’t support constraints. The only solution for this problem is the creation of triggers over our edge tables. In this example, we will need a trigger for INSERT and UPDATE.
The following trigger will solve the problem:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
create trigger chkReplies on dbo.Reply_to for insert,update as begin if exists( select 1 from inserted where (SELECT count(*) FROM dbo.ForumPosts ReplyPost, Reply_To, dbo.ForumPosts RepliedPost WHERE MATCH(ReplyPost-(Reply_To)->RepliedPost) and ReplyPost.$node_id=inserted.$from_id) >1 ) begin raiserror('One message can only be reply to another single message',13,1) rollback transaction end end |
Try the INSERT again and this time you will the error message:
|
1 2 3 |
Insert Reply_to Values ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 3), (SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 4)) |

Deleting Parent records with Children
This is another interesting problem. The relation isn’t enforced, so we can delete parent records even when they have children. You can try this:
|
1 2 3 4 5 6 7 8 |
Begin Transaction -- This delete works, unfortunately. Delete dbo.forumposts where postid=1 -- Posts and their replies select RepliedPost.PostId,RepliedPost.PostTitle, ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle From dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost Where Match(ReplyPost-(Reply_to)->RepliedPost) |
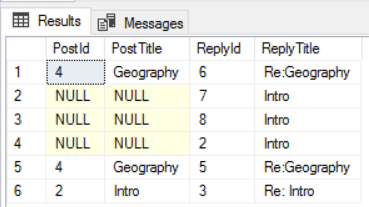
You will notice that the result in the SELECT will have several NULL values because of the deleted record. We can’t even insert the record again, because the relation is done by the $node_id value, which is auto-generated.
Undo the change with a rollback:
|
1 |
Rollback transaction |
We can’t solve this with a simple relationship, such as foreign key constraint, first because the graph pseudo-columns don’t support constraints and also because this would be an impossible solution for and edge such as ‘Likes’, which accepts multiple types of nodes.
Again, the solution is a trigger:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
create trigger chkNotOrphanReply on dbo.ForumPosts for delete as if exists(select 1 from deleted where (SELECT count(*) FROM Reply_To WHERE $to_id=deleted.$node_id) >0 ) begin raiserror('This message can''t be deleted because it has replies',13,1) rollback transaction end |
After creating the trigger, execute this block of code again and you will see the error message:
|
1 2 3 4 5 6 7 8 9 10 |
Begin Transaction -- This delete works, unfortunatelly. Delete dbo.forumposts where postid=1 -- Posts and their replies select RepliedPost.PostId,RepliedPost.PostTitle, ReplyPost.PostId as ReplyId, ReplyPost.PostTitle as ReplyTitle From dbo.ForumPosts ReplyPost, dbo.Reply_to, dbo.ForumPosts RepliedPost Where Match(ReplyPost-(Reply_to)->RepliedPost) |

One Forum post shouldn’t like another forum post
The ‘Likes’ edge is much more flexible, however has also its problems. We shouldn’t be able to insert a like between two forum posts, but the model will accept it. The following insert will work:
|
1 2 3 4 |
--This insert should not be accepted, but it is INSERT Likes ($to_id,$from_id) VALUES ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8), (SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7)) |
After trying the insert above, delete the inserted record and any like between posts:
|
1 2 3 4 5 |
-- Deleting delete likes from likes, dbo.forumposts post1, dbo.forumposts post2 where MATCH(Post1-(likes)->Post2) |
Again, the solution will be a trigger. However, this time we need to check the type of record inserted in the relation. We can use the function JSON_VALUE to extract this information. The JSON_VALUE function can extract information from any JSON field, including the calculated graph fields.
For example, the following SELECT will extract the type of each record inserted in the $from_id field part of the like:
|
1 2 3 |
select json_value($from_id, '$.schema') as [schema], json_value($from_id, '$.table') as [table] from likes |
We can use this function in a trigger for insert/update. The trigger will be this:
|
1 2 3 4 5 6 7 8 9 10 |
Create trigger chkLikeType on Likes for Insert,Update as if exists (select 1 from inserted where json_value($from_id, '$.schema')<>'dbo' or json_value($from_id, '$.table')<>'ForumMembers') begin raiserror('Only forum members can like a post or another member',13,1) rollback transaction end |
After creating the trigger, you can try the insert again, it will not be accepted:
|
1 2 3 4 |
--This insert should not be accepted, but it is INSERT Likes ($to_id,$from_id) VALUES ((SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 8), (SELECT $node_id FROM dbo.ForumPosts WHERE PostID = 7)) |

Missing Validation Features
All these problems should be solved with some kind of validation syntax on the creation of edge nodes. We should be able to constrain the types of entities that are allowed in the edge node and whether we will allow more than one record with the same entity.
This syntax would avoid the need for triggers. The support for a range of constraints would make the system much more robust.
Conclusion
It’s a first version, SQL Graph in SQL Server 2017 is very promising, even though there are a lot of missing features at this stage. There is plenty to do before this becomes usable and robust, but there is enough so far to be hopeful that Microsoft can deliver a fully-functional graph database within SQL Server
- At the moment, there is little or any information about how soon we can expect to see the tools that a development is likely to need. We need an object model with support for this, Entity Framework doesn’t support these kind of database objects and I’m not sure if the best option really is to join relational and graph models in the same object model.
- We need a tool to design this model. Besides the needed support for validation in the syntax of edge nodes, a tool to design this, such as database diagram is for relational models, will be very useful.
After reading this article, probably would like to check:
- The documentation and architecture of this model. This link will be useful
- More examples. This link will be useful, it’s a bigger sample and the only link I found talking also about the performance of the graph model
- More references and other links. This summary of several references will be useful link.
Fast, reliable and consistent SQL Server development…
FAQs: Graph databases in SQL Server
1. What are the pros and cons of SQL Server graph databases?
Pros: MATCH clause simplifies complex relationship queries, natural modeling for social networks and recommendations, integrates with existing SQL Server tools and T-SQL. Cons (as of 2017, many addressed in later versions): no edge constraints (added in 2019), no MERGE for graph DML, limited visualization tooling, MATCH requires explicit hop counts. SQL Server 2019+ addressed several of these with SHORTEST_PATH, edge constraints, and derived table support in MATCH.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments