
Modifying Contiguous Time Periods
This article explains how to modify contiguous time periods that were described in Joe Celko’s article ‘Contiguous Time Periods in SQL‘. Joe describes the table itself that he calls the ‘Kuznetsov History Table’. He explains how it is used to store contiguous time intervals with constraint to ensure that the date periods really are contiguous, The editor suggested that I give a brief description of how to modify the data in the History table as this may not be entirely obvious.
When trusted constraints enforce data integrity, the data is guaranteed to be valid at the end of any statement, even if it is not committed. When we modify contiguous time periods, in order to get from one valid state to another we may need to insert a row and update another one, or we may need to delete a row and update another one. This is one of those cases when MERGE really shines – it allows us to get from one valid state to another in one statement, inserting, updating, and deleting rows as needed.
Prerequisites.
All we need is an empty table, as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
CREATE TABLE dbo.Responsibilities ( TaskId INT NOT NULL , PersonInCharge VARCHAR(50) NOT NULL , StartedAt DATETIME NOT NULL , FinishedAt DATETIME NOT NULL , PreviousFinishedAt DATETIME NULL , CONSTRAINT PK_Responsibilities_TaskId_FinishedAt PRIMARY KEY ( TaskId, FinishedAt ) , CONSTRAINT UNQ_Responsibilities_TaskId_PreviousFinishedAt UNIQUE ( TaskId, PreviousFinishedAt ) , CONSTRAINT FK_Responsibilities_TaskId_PreviousFinishedAt FOREIGN KEY ( TaskId, PreviousFinishedAt ) REFERENCES dbo.Responsibilities ( TaskId, FinishedAt ) , CONSTRAINT CHK_Responsibilities_PreviousFinishedAt_NotAfter_StartedAt CHECK ( PreviousFinishedAt <= StartedAt ) , CONSTRAINT CHK_Responsibilities_StartedAt_Before_FinishedAt CHECK ( StartedAt < FinishedAt ) ) ; |
Some Easy Modifications.
It is easy to begin a new series of time periods
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
INSERT INTO dbo.Responsibilities ( TaskId , PersonInCharge , StartedAt , FinishedAt , PreviousFinishedAt ) VALUES ( 1 , 'Joe' , '20101002' , '20101023' , NULL ), ( 1 , 'Andrew' , '20101023' , '20101103' , '20101023' ) ; |
It is just as easy to continue adding periods to the end of the series.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
INSERT INTO dbo.Responsibilities ( TaskId , PersonInCharge , StartedAt , FinishedAt , PreviousFinishedAt ) SELECT 1 AS TaskId , 'Alex' AS PersonInCharge , '20101120' AS StartedAt , '20101125' AS FinishedAt , '20101103' AS PreviousFinishedAt UNION ALL SELECT 1 AS TaskId , 'Andrew' AS PersonInCharge , '20101126' AS StartedAt , '20101127' AS FinishedAt , '20101125' AS PreviousFinishedAt |
Deleting one or more rows from the end is just as easy, and we shall skip the example. As we have seen, it is easy to perform typical, the most common operations against history of periods.
However, some other operations are less easy and need more explanations. Now that we have enough test data, let us move on to more complex examples. Here is the test data at this moment:

Adding periods to the beginning.
Each series of periods has exactly one first period – this is enforced by the following constraint: UNQ_Responsibilities_TaskId_PreviousFinishedAt.
As a result, when we are inserting one or more periods to the beginning of the series, we have to update the period that used to be the first before, as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
MERGE dbo.Responsibilities AS Target USING ( SELECT 1 AS TaskId , 'Alex' AS PersonInCharge , '20090301' AS StartedAt , '20090306' AS FinishedAt , NULL AS PreviousFinishedAt UNION ALL SELECT 1 AS TaskId , 'Joe' AS PersonInCharge , '20101002' AS StartedAt , '20101023' AS FinishedAt , '20090306' AS PreviousFinishedAt ) AS source ( TaskId, PersonInCharge, StartedAt, FinishedAt, PreviousFinishedAt ) ON ( Target.TaskId = source.TaskId AND Target.StartedAt = source.StartedAt ) WHEN MATCHED THEN UPDATE SET PersonInCharge = source.PersonInCharge , StartedAt = source.StartedAt , FinishedAt = source.FinishedAt , PreviousFinishedAt = source.PreviousFinishedAt WHEN NOT MATCHED THEN INSERT ( TaskId , PersonInCharge , StartedAt , FinishedAt , PreviousFinishedAt ) VALUES ( source.TaskId , source.PersonInCharge , source.StartedAt , source.FinishedAt , source.PreviousFinishedAt ); |
Now we will verify that our test data looks as expected, with a new row at the beginning, and PreviousFinishedAt column is modified to point to the new row for the row that used to be the first before this modification:

We are also going to discuss some other scenarios, such as adding/deleting periods in the middle of the series. In all these cases we shall be using MERGE, and the DML looks quite similar, so let us wrap it up in a stored procedure.
Creating a stored procedure
The following code implements this merging functionality with a stored procedure that uses a table valued parameter, as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
CREATE TYPE ResponsibilitiesChangesList AS TABLE ( TaskId INT NOT NULL , PersonInCharge VARCHAR(50) NOT NULL , StartedAt DATETIME NOT NULL , FinishedAt DATETIME NOT NULL , PreviousFinishedAt DATETIME NULL, DeleteThisRow CHAR(1) ) ; GO CREATE PROCEDURE dbo.MergeResponsibilities @changes ResponsibilitiesChangesList READONLY AS BEGIN ; SET NOCOUNT ON ; MERGE dbo.Responsibilities AS Target USING ( SELECT TaskId , PersonInCharge , StartedAt , FinishedAt , PreviousFinishedAt , DeleteThisRow FROM @changes AS c ) AS source ( TaskId, PersonInCharge, StartedAt, FinishedAt, PreviousFinishedAt, DeleteThisRow ) ON ( Target.TaskId = source.TaskId AND Target.StartedAt = source.StartedAt ) WHEN MATCHED AND DeleteThisRow = 'Y' THEN DELETE WHEN MATCHED THEN UPDATE SET PersonInCharge = source.PersonInCharge , StartedAt = source.StartedAt , FinishedAt = source.FinishedAt , PreviousFinishedAt = source.PreviousFinishedAt WHEN NOT MATCHED THEN INSERT ( TaskId , PersonInCharge , StartedAt , FinishedAt , PreviousFinishedAt ) VALUES ( source.TaskId , source.PersonInCharge , source.StartedAt , source.FinishedAt , source.PreviousFinishedAt ) ; END ; |
Let us use this stored procedure.
Filling a gap in the middle of the series
The following code fills the gap on November 25th.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
DECLARE @changes ResponsibilitiesChangesList ; INSERT INTO @changes ( TaskId , PersonInCharge , StartedAt , FinishedAt , PreviousFinishedAt , DeleteThisRow ) SELECT 1 AS TaskId , 'Michelle' AS PersonInCharge , '20101125' AS StartedAt , '20101126' AS FinishedAt , '20101125' AS PreviousFinishedAt , 'N' AS DeleteThisRow UNION ALL SELECT 1 AS TaskId , 'Andrew' AS PersonInCharge , '20101126' AS StartedAt , '20101127' AS FinishedAt , '20101126' AS PreviousFinishedAt , 'N' AS DeleteThisRow ; EXEC dbo.MergeResponsibilities @changes = @changes ; |
Here is the data after this modification, with a period added in the middle fo the series:
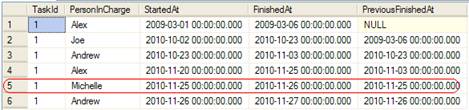
Deleting a period in the middle of the series
The following code deletes the period added in the previous example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
DECLARE @changes ResponsibilitiesChangesList ; INSERT INTO @changes ( TaskId , PersonInCharge , StartedAt , FinishedAt , PreviousFinishedAt , DeleteThisRow ) SELECT 1 AS TaskId , 'Michelle' AS PersonInCharge , '20101125' AS StartedAt , '20101126' AS FinishedAt , '20101125' AS PreviousFinishedAt, 'Y' AS DeleteThisRow UNION ALL SELECT 1 AS TaskId , 'Andrew' AS PersonInCharge , '20101126' AS StartedAt , '20101127' AS FinishedAt , '20101125' AS PreviousFinishedAt, 'N' AS DeleteThisRow ; EXEC dbo.MergeResponsibilities @changes = @changes ; |
Here is the data after this modification:

Inserting two periods in the middle, and adjusting an exaisting period to make room for them.
This is the last and most complex example involving our stored procedure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
DECLARE @changes ResponsibilitiesChangesList ; INSERT INTO @changes ( TaskId , PersonInCharge , StartedAt , FinishedAt , PreviousFinishedAt , DeleteThisRow ) SELECT 1 AS TaskId , 'Alex' AS PersonInCharge , '20101120' AS StartedAt , '20101122' AS FinishedAt , '20101103' AS PreviousFinishedAt, 'N' AS DeleteThisRow UNION ALL SELECT 1 AS TaskId , 'Michelle' AS PersonInCharge , '20101122' AS StartedAt , '20101123' AS FinishedAt , '20101122' AS PreviousFinishedAt, 'N' AS DeleteThisRow UNION ALL SELECT 1 AS TaskId , 'Alex' AS PersonInCharge , '20101123' AS StartedAt , '20101125' AS FinishedAt , '20101123' AS PreviousFinishedAt, 'N' AS DeleteThisRow EXEC dbo.MergeResponsibilities @changes = @changes ; |
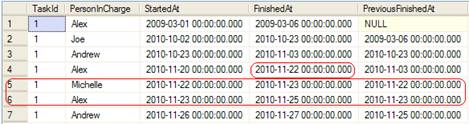
Here is the data after running this script, with modifications in red rectangles:
Getting by on SQL Server 2005, without MERGE
We do not have MERGE on SQL Server 2005, so we have to use more complex ways to modify, such as delete and reinsert the whole series, or use more than one command to implement the change. The following operations are available:
- Inserting periods at the end
- Deleting periods at the end
- Updating periods from one valid state to another
For example, to delete the first period, we have to use an update to move it to the end, and then delete it, as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
SET XACT_ABORT ON ; BEGIN TRAN ; UPDATE dbo.Responsibilities SET FinishedAt = CASE WHEN StartedAt = '20090301' THEN '20990909' ELSE FinishedAt END , StartedAt = CASE WHEN StartedAt = '20090301' THEN '20990908' ELSE StartedAt END , PreviousFinishedAt = CASE WHEN StartedAt = '20090301' THEN '20101127' ELSE NULL END WHERE TaskId = 1 AND StartedAt IN ( '20090301', '20101002' ) ; SELECT * FROM dbo.Responsibilities DELETE FROM dbo.Responsibilities WHERE TaskId = 1 AND StartedAt = '20990908' ; SELECT * FROM dbo.Responsibilities ; ROLLBACK ; |
Selects were added to the script so that we can see the intermediate and final state of the data. In the intermediate state, the first row is moved to the end, and the second one is updated to become the first:
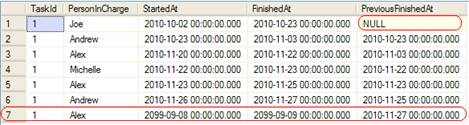
In the final state, the row is gone:
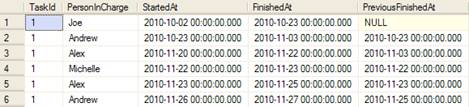
We shall not re-implement all the previously discussed examples – that is left as an advanced exercise.
Good luck!
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments