
You don’t you think thirteen is a good number? Well, here in Brazil we’ve a famous soccer player and coach called Mario Zagalo who really likes it. This obviously has nothing at all to do with Query Optimizer, so let’s get started with the good stuff.
When we are talking about query plans and optimization, there are some things that you really should know. The SQL Query Optimizer employs many techniques to create a optimal execution plan, and today I’ll present some terminology and features used.
1 – Selectivity
We can define selectivity as:
The degree to which one value can be differentiated within a wider group of similar values.
For instance, when Mario Zagalo was a coach of Brazilian soccer team, one of his hardest jobs was select the players for each match. Brazil is a huge country and, as you probably know, we have a lot of very good players. So, the selectivity of good players in Brazil is very low, because there are a lot of them. If I ask to you to select just players who would make good attackers, you would probably return to me with a lot of guys, and returning with many players lowers the selectivity.
In database terms, suppose we have a table called Internationally_Renown_Players with a column called Country. If we write:
|
1 |
SELECT * FROM Internationally_Renown_Players WHERE Country= 'Brazil' |
… then we can say that this query is not very selective, because many rows will be returned (Update: Sadly, this didn’t help us in the 2010 World Cup). However, if we write:
|
1 |
SELECT * FROM Internationally_Renown_Players WHERE Location = 'Tuvalu' |
… then this query will be very selective, because it will return very few rows (I know if they have a soccer team, but they have yet to really make a name for themselves.)
Another good (and broader interest) example would be to have a table called Customers, with columns for Gender and, say, Passport_Number. The selectivity of the Gender column is very low because we can’t do much filtering with just the F or M values, and so many rows will be returned by any query using it. by contrast, a query filtering with the Passport_Number column will always return just one row, and so the selectivity of that column is very high.
Why You Should Know This
The Query Optimizer use Selectivity information to create the execution plans, and can decide on an optimal execution plan based on the selectivity of a given column. It is also clearly good practice is create your indexes on the columns with a highest selectivity level. That means it is better to create a index on a Name column than a Gender column. It is also better create a composite index in a order to make use of the most selective column first, and thus increase the chances that the SQL Server will actually use that index.
2. Density
The term “density” comes from physics, and is calculated by the dividing the mass of a substance by the volume it occupies, as represented mathematically below.
![]()
Where D = Density, M = Mass and V = Volume.
The explanation can be stretched, as is the case with “Geographic Density” (something we’ve become used to hearing and understanding); For example, the geographic density of Brazil is calculated by dividing the number of habitants (or the ‘mass’) by the size of the geographic area (the ‘volume’, which is 187,000,000 people divided by 8,514,215.3 km2, which gives us 21.96 habitants per km2. In SQL Server, we can interpret this as:
The more dense a column is, more rows that column returns for a given query.
Take note that is exactly the opposite of selectivity, for which a higher value means less rows. To calculate the density of a column, you can run the following query:
|
1 |
SELECT (1.0 / COUNT(DISTINCT <ColumnName>)) FROM <TableName> |
… The larger a number that query returns, the more ‘dense’ your column is, and the more duplications it contains. With this number, the QO can determine two important facts about the frequency of data of a column, and to explain this better, let’s create an example table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE Test(Col1 INT) GO DECLARE @i INT SET @I = 0 WHILE @i < 5000 BEGIN INSERT INTO Test VALUES(@i) INSERT INTO Test VALUES(@i) INSERT INTO Test VALUES(@i) INSERT INTO Test VALUES(@i) INSERT INTO Test VALUES(@i) SET @i = @i + 1 END GO CREATE STATISTICS Stat ON Test(Col1) GO |
As you can see, we have a table with 25,000 rows, and each value is duplicated across five rows; so the density is calculated as 1.0 / 5000 = 0.0002. The first question we can answer that that information is: “How many unique values do we have in the column ‘Col1’?” Just using the density information we can make the following, 1.0 / 0.0002 = 5000. The second question is: “What is the average number of duplication per value in the ‘Col1’ column?” Using the density information we can calculate: 0.0002 * 25000 = 5 (Which is exactly the average of duplicated values in this case).
Why You Should Know This
Using the table created above, let’s see where the SQL Server uses that information in practice. Take the following query:
|
1 2 3 4 5 |
DECLARE @I INT SET @I = 999999 SELECT * FROM Test WHERE Col1 = @I |
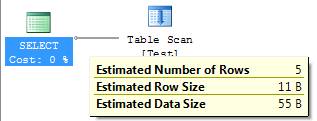
The SQL Server will use the information about the average density to estimate how many rows will be returned (in this case, 5 rows). We will see more about why the SQL uses the density information in the section 7.
Another example:
|
1 2 |
SELECT COUNT(*) FROM Test GROUP BY Col1 |

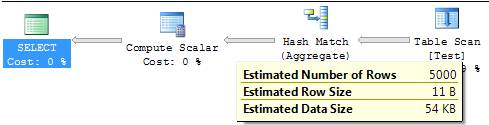
In the first step, the Table Scan operator estimates that 25000 rows will be returned, and then after the Hash Mach Operator applies the Group By, only 5000 rows will be returned. In that case, SQL Server uses the information about how many unique rows are in the column.
The density information used to give the QO an impression of how many duplicated rows exist in a column, which allows it to chose the optimal operator or join algorithm in an execution plan. In certain cases, the QO also uses density information to guess how many rows will be returned by a query – look at section 5 for more details.
3. Cardinality
This is used to measure the number of rows which satisfy one condition. For instance, imagine one table with 500 rows, and a query with “WHERE NAME = ‘Joao'” – the Optimizer goes to the statistics and reads from the histogram that ‘Joao’ represents 5% of the table, so the cardinality is (5% x 500) = 25. In the execution plan, we can think of the cardinality as the “estimated number of rows” displayed in the tool tips of each operator. I probably don’t need to spell it out, but a bad estimation of cardinality can easily result in an inefficient plan.
Why you should know that
In my opinion, the cardinality of a column is one of the most important pieces of information to the creation of an efficient execution plan. To create an execution plan, we really need to know (or at least be able to make a decent estimate about) how many rows will be returned to each operator. For example, a join query which returns a lot of rows would be better processed with a hash join; But if the QO doesn’t know about the cardinality, it can mistakenly chose to use a Loop Join or, even worst, chose to order the key columns to make use of a merge join!
4. SARG
SARGs (Search Arguments) are the conditions of your query; The value you include in WHERE = “…” is the value passed to the search. With that information, the Optimizer will estimate how many rows will be returned and what is the best way(plan) to read this data. In the other words, based on the SARG, the QO analyses the selectivity, density and cardinality to get the best possible execution plan.
Why you should know that
Queries with good SARGs are used to filter returned data, as when less data is selected, fewer pages will need to be read, and that will manifest itself as a huge performance gain.
Interlude
Many SQL Server books and Query Processor references uses these four core terms described above (Selectivity, Density, Cardinality and SARG) to explain the behavior of a query plan, so hopefully this knowledge will make things a little clearer for you in the future.
5. Foldable Expressions
Early on in the optimization phase, the QO tries to change your query to evaluate an expression, and then change that expression to a constant. A constant is a literal value like such as ‘1’, ‘Peter’, ‘10.50’, ‘20090101’, etc. This method is known as Constant Folding.
A simple example of Constant Folding is the expression “<column> = 1+1″; early in the optimization process, the QO would change that expression to “<column> = 2“, and then use the value ‘2’ as a SARG. Another interesting example is that the QO would change “<column> = REPLACE(‘123xxx’, ‘xxx’, ‘456’)” to simply “<column> = ‘123456’”.
Why You Should Know This
It is good to know where the QO can do this, because that can make our queries a little easier to write. It is also worth bearing in mind that an exception is made for large object types. If the output type of the folding process is a large object type (text, image, nvarchar(max), varchar(max), or varbinary(max)), then SQL Server does not fold the expression.
6. Non-foldable Expressions
An expression is considered non-foldable when the SQL Server cannot evaluate the expression, which causes a bad estimation of cardinality and a bad execution plan. We will see some examples in the next section (7) of when the use of some expressions blocks the use of statistics for a column.
Why You Should Know This
Well basically, you should know to avoid the use of these constructions in your query, as they’ll just make life more difficult. To avoid this, instead of using, say ABS(-1000), you could use (-1000 * -1), or pass the expression to a variable and then use that variable in your query, as in:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM Tab1 WHERE Col1 < ABS(-78150) -- Use a variable with the recompile clause, to force the QO read the value of @Var DECLARE @Var INT SET @Var = ABS(-1000) SELECT * FROM CONVE002 WHERE ID_Pessoa < @Var OPTION(RECOMPILE)) |
7. What Happens When the Query Optimizer Can’t Estimate the Cardinality of a SARG?
The cardinality, density and selectivity of a value or a column are the heart of the matter, and the QO will always try to use these pieces of information to get an execution plan. When possible during the optimization stage, the QO tries to simplify your search arguments into constants. We’ve already covered this section 5, and we know that:
- In the optimization stage, the QO changes “WHERE Value = 1 + 1” to “WHERE Value = 2”, and with that 2 calculated, it tries to read the statistics to get the information necessary to generate a good execution plan.
- The QO changes “WHERE <column> = REPLACE(‘123XXX’, ‘XXX’, ‘456’)” to “WHERE <column> = ‘123456’”.
However, the QO sometimes can’t identify (read sniff) the value of a search argument for any of a variety of reasons. I’ll demonstrate a few:
- Pay attention to when a constant uses a function, because some functions prevent the QO’s estimations. The functions listed below are used by the Query Optimizer to change your constants to a literal, and if you are using a different function you should run a test to be sure about what the QO is going to do:
Lower, Upper, RTrim, Datediff, Dateadd, Datepart, Substring, Charindex, Len, SUser_SName, IsNull, GetDate, GetUTCDate, Replace, Left, Right;
Some examples of what I mean:- “WHERE <column> = ABS(-1000)” – to make this SARG able to be used into the Optimizer, you could change this command to “WHERE <column> = -1000 * -1”. Using * -1 instead of the ABS function.
- “WHERE <column> = ROUND(123.4545, 2)”: Results in a bad estimation of the cardinality.
- “WHERE <column> = LEN(88888888)”: Results in a good estimation of the cardinality.
- When you are using local variables, for instance:
123DECLARE @I INTSELECT * FROM <TABLE>WHERE <COLUMN> = @I
- When you are using scalar-valued user-defined functions.
12SELECT * FROM <TABLE>WHERE <COLUMN> = dbo.fn_FormatText('Text')
- When you are using a SubQuery; for instance, “WHERE <column> = (select <column> from <table>)” will prevent an estimation because the value of the subquery is not known at the optimization stage.
When the optimizer can’t identify the cardinality of a value, it uses a feature called Magic Density (I love this name), which is more commonly known by the name “Guess”. In other words, it’ll try to predict how many rows will be returned, and to do that, it uses the density of one column or a hard-coded percent (which I’ll come to in a moment). Let’s take a look at some examples of how it does this ‘magic’ in SQL Server 2005:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- For "=", uses COUNT(*) * column Density, translating COUNT(*) * (1.0 / (COUNT (DISTINCT <column>))) SELECT * FROM <TABLE> WHERE <COLUMN> = @I -- For "BETWEEN", uses 9%, translating (COUNT(*) * 9.0) / 100 SELECT * FROM <TABLE> WHERE <COLUMN> BETWEEN @I AND @X -- For ">, >=, < and <=", uses 30%, translating (COUNT(*) * 30.0) / 100 SELECT * FROM <TABLE> WHERE <COLUMN> ">, >=, < and <=" @I |
Note : If there are no statistics for a column and the equality operator is used, that means the SQL can’t know the density of the column, so it uses a 10 percent fixed value.
Why You Should Know This
This knowledge is important because with it you can avoid these mistakes and help the QO to create a optimal execution plan. As I said, estimation of cardinality is the heart of the matter, so always keep eye on that.
8. Contradiction Detections
Contradiction Detection is an optimization that recognizes when a query is written in such a way that it will never return any rows at all. When the QO identifies such a query, it rewrites it to remove whichever part contained the contradiction. Here you can see a quick example of such a contradiction:
|
1 2 3 4 5 |
SELECT * FROM Tab1 WHERE Tab1_Col1 BETWEEN 10 AND 0 OPTION(RECOMPILE) |
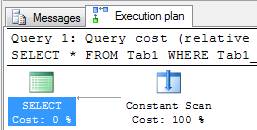
Looking at the plan, you’ll see it does not access the table Tab1, but instead that the plan uses a Constant Scan operator. It’s worth noticing that I use the RECOMPILE hint to force SQL Server not to use parameterization, because that can prevent the contradiction from being detected, and hence the optimization from taking place.
Why You Should Know This
This optimization is very interesting because it can neatly avoid the use of large amount of resources. Identifying the contradiction means less wasted CPU time, less memory used, fewer locks and so on. In section 10 we’ll will see another interesting detection of contradictions.
9. Foreign Keys
The Query Optimizer is smart enough to identify when a query is accessing a table that doesn’t need to be accessed. For instance, if I have a Customers table and an Orders table, a Foreign Key from Orders to Customers tells me that every Order has a Customer. So, if I have a query doing a join with the Customers and Orders tables, it might be that I don’t need to read all the columns of a table. This code shows that behavior:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
IF OBJECT_ID('Tab2') IS NOT NULL BEGIN DROP TABLE Tab2 END IF OBJECT_ID('Tab1') IS NOT NULL BEGIN DROP TABLE Tab1 END GO CREATE TABLE Tab1 (Tab1_Col1 Integer NOT NULL PRIMARY KEY, Tab1_Col2 CHAR(200)) CREATE TABLE Tab2 (Tab2_Col1 Integer NOT NULL PRIMARY KEY, Tab1_Col1 Integer NOT NULL, Tab2_Col2 CHAR(200)) ALTER TABLE Tab2 ADD CONSTRAINT fk FOREIGN KEY (Tab1_Col1) REFERENCES Tab1(Tab1_Col1) GO -- Fine, the execution plan won't use Tab1 SELECT Tab2.* FROM Tab2 INNER JOIN Tab1 ON Tab1.Tab1_Col1 = Tab2.Tab1_Col1 |
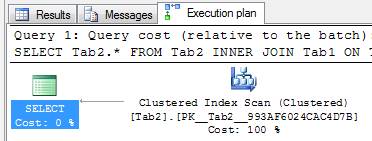
As we can see, the QO create a execution plan that access just the Tab2 table, because I have a foreign key (FK) that assures the all rows on Tab2 are linked to a valid row into Tab1. Be aware that the foreign key must be Trusted. You can have a nontrusted foreign key, but in that case the QO will read both tables. You can check if an FK is trusted by reading the sys.foreign_keys table, in which the is_not_trusted column will tell us if an FK is trusted or not.
This is undoubtedly a very cool feature, but in my opinion there are actually many ways it could be improved. For instance, the QO will only use this behavior if you have a single-column foreign key; if you have a multi-column foreign key, it will read both tables. I’ve send an email to my mentor and great friend Conor Cunningham discussing some points which, in my opinion, could be enhanced; he blogs about it, so that is a mandatory extended read if you want to know more.
Why You Should Know This
I would like to make two important points. The first is a warning; when you write your queries, be sure to include all columns in the join, even when you are using a key column in the WHERE clause.
Last month I was working in a performance problem, and I found a query that was not using an index properly, ad so I naturally decided to investigate what was happening. The problem was that the QO was not using the index because the developer had not specified all the columns of the multi-column foreign key in one join. Take a look in my blog here and here to see the example (the originally posts are in Portuguese, but I think Google translation did a good job here). You can also Look at the Conor’s blog to see another example.
The second point is about views; we rarely see this type of syntax (example above, in the Foreign Key section), where we select just the columns of one table, but as you can see, you can have a view which accesses both tables. When you write code using that view, you don’t need to use all the columns, just a column from one table, so in that case this feature will be well-sed.
10. Check Constraints
Check Constraints are used by the QO to identify contradictions. For example, if you have a trusted check constraint, and one query using the columns which belong to that check constraint, the QO can use the constraint to quickly validate the expression. Let’s take a look at an example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
IF OBJECT_ID('Tab1') IS NOT NULL BEGIN DROP TABLE Tab1 END GO CREATE TABLE Tab1 (Col1 Integer NOT NULL PRIMARY KEY, Status CHAR(1)) ALTER TABLE Tab1 ADD CONSTRAINT ck CHECK(Status = 'S' OR Status = 'N') GO SELECT * FROM Tab1 WHERE Status = 'X' OPTION(RECOMPILE) |
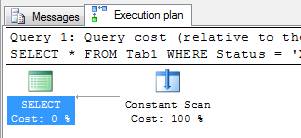
The QO knows that it’s impossible for a row to exist with an ‘X’ value in the status column, so it creates a plan which doesn’t access the table at all.
Why You Should Know This
If you don’t have them already, be sure to create your check constraints and make them trusted. Just like with the foreign keys, the QO will only use that information if the constraints are trusted, and you can look that information up in sys.check_constraints. Another interesting point concerns parameterization; Notice that I used the RECOMPILE hint to force SQL Server to not use parameterization because, as before, that can avoid the detection of the contradiction in the first place.
11. Non-Updating Updates
Now this is a very interesting topic – Don’t you ever ask yourself what happens when you update a column with the same value as already exists? As we know, when a column belongs to an index, we need to keep that data updated on the clustered index and all non-clustered indexes that uses the column. Well, this is exactly where the Non-Updating Updates optimizations come into play.
Since SQL Server 2005, the QO has had an optimization that verifies if the value in a non-clustered index has changed before updating it. Why is that so important? Because non-clustered indexes are very expensive and their cost increases exponentially depending on how many non-clustered index reference a given column.
Generally speaking, updates to a column which belongs to a non-clustered index are performed in several steps. For instance, first use the cluster index to locate the value which needs to be updated. Second, update that value in the clustered index. Third, locate the value in the non-clustered index. Fourth, update the non-clustered index (a process which will be split to a delete action and an insert one) with the new value. Let’s go see some examples:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
IF OBJECT_ID('Tab1') IS NOT NULL BEGIN DROP TABLE Tab1 END GO CREATE TABLE Tab1 (Tab1_Col1 Integer NOT NULL PRIMARY KEY, Tab1_Col2 CHAR(200)) CREATE INDEX ix_Test ON Tab1(Tab1_Col2) INSERT INTO Tab1 (Tab1_Col1, Tab1_Col2) VALUES(1,'') SELECT OBJECT_NAME(a.OBJECT_ID) Tabela, b.name, leaf_insert_count, leaf_delete_count, leaf_update_count FROM sys.dm_db_index_operational_stats(DB_ID(), OBJECT_ID('Tab1'), 2, NULL) AS a INNER JOIN sys.indexes b ON a.OBJECT_ID = b.OBJECT_ID AND a.index_id = b.index_id |

The select on the dmv sys.dm_db_index_operational_stats show us the number of inserts that occur on the ix_Test index. Now let’s make an update on the Tab1_Col2 column, which has a non-clustered (NC) index.
|
1 2 3 4 5 6 |
UPDATE Tab1 SET Tab1_Col2 = 'ABC' SELECT OBJECT_NAME(a.OBJECT_ID) Tabela, b.name, leaf_insert_count, leaf_delete_count, leaf_update_count FROM sys.dm_db_index_operational_stats(DB_ID(), OBJECT_ID('Tab1'), 2, NULL) AS a INNER JOIN sys.indexes b ON a.OBJECT_ID = b.OBJECT_ID AND a.index_id = b.index_id |

Now we have 2 values inserted on the NC index – next, let’s make an update using the same ‘ABC’ value.
|
1 2 3 4 5 6 7 |
UPDATE Tab1 SET Tab1_Col2 = 'ABC' SELECT OBJECT_NAME(a.OBJECT_ID) Tabela, b.name, leaf_insert_count, leaf_delete_count, leaf_update_count FROM sys.dm_db_index_operational_stats(DB_ID(), OBJECT_ID('Tab1'), 2, NULL) AS a INNER JOIN sys.indexes b ON a.OBJECT_ID = b.OBJECT_ID AND a.index_id = b.index_id |

You can run the update as many times as you want; The QO is smart enough to identify the value ‘ABC’ is the same as what is stored in the non-clustered index, so it detects the unchanged value and avoids the update.
Why You Should Know This
The ‘SQL Server 2008 Internals‘ book by Kalen Delaney has an interesting point regarding this optimization. Many programming databases have a common paradigm of how to make updates, and if I write an update dynamically using just the rows which are changed, I will have one query plan for each updated column.
To fix that inefficiency, we can write one query using all columns, and pass the column values as parameters (which is the usual way), so the same plan will be reused. But if we write one update using all the columns of a table, even the columns which have not changed, we can end up with a problem when it comes to updating all the non-clustered indexes with a value which has not changed. So this features is very interesting from the point of view of avoiding gross inefficiency.
12. RowModCtr
There is a column in the sysindexes table where we can see how many changes have been made to a column or a table since the last statistics update. In SQL Server 2005, when an INSERT, DELETE or UPDATE occurs in a column which belongs to a set of statistic, SQL Server updates this value (RowModCtr) in the sysindexes table. In SQL Server 2000, this column is updated when events occurs on a table level, not a column level. In both cases, when the statistics are updated, the RowModCtr column is updated to zero.
Why You Should Know This
If you want to have more control over when UPDATE STATISTICS occurs, you can use this column to see how many changes occur in your table, or column, and with that information in hand you can decide whether to update a statistic or not. For example, using this column, you can create a maintenance job to keep the statistics updated because, if a statistic is outdated, the QO can decide to update it during the creation of an execution plan , which causes a small (and avoidable) delay.
13. When is the Auto-Update to Statistics Triggered?
Every time a column which belongs to a statistic get a sufficient quantity of modifications, the SQL Server starts ‘Auto-Update Statistics’ to keep the data current. This works in this manner:
- If the cardinality of a table is less than six and the table is in the tempdb database, auto update after every six modifications to the table.
- If the cardinality of a table is greater than 6, but less than or equal to 500, update statistics every 500 modifications.
- If the cardinality of a table is greater than 500, update statistics when (500 + 20 percent of the table) changes have occurred.
- For table variables, a cardinality change does not trigger an auto-update of the statistics.
Question: what can I do to know when an auto update has started?
There are many ways; Here are a few:
- If the column rowmodctr was zero, that means an auto update statistics just run, or the table is empty.
- In Profiler you can select the SP:StmtCompleted and SP:StmtStarting columns, and if an auto update statistics is triggered you will see code which looks like:
12345SELECT StatMan([SC0])FROM (SELECT TOP 100 PERCENT <COLUMN> AS [SC0]FROM [dbo].<TABLE> WITH (READUNCOMMITTED)ORDER BY [SC0] ) AS _MS_UPDSTATS_TBL
- You can enable the 205 trace flag, and then SQL Server will write that information into the error log.
- The 8721 trace flag will write that information into the error log, too.
Why You Should Know This
The information about when and why the auto update statistics is triggered is all about SQL Server internals, and that knowledge can make your maintenance jobs more accurate. Sometimes the auto update can take a huge amount of time in the creation of the execution plan, so some problems can be avoided and fixed by analyzing this point.
I appreciate any and all feedback, and I really hope you’ve enjoyed reading this. But that’s not all folks; do you wanna know more? I’ve put together a long, juicy list of many of my preferred articles and posts, so have a good read if you want to know more about the Query Optimizer.
- The Query Optimizer and Contradiction Detection
- Conor vs. FOREIGN KEY join elimination
- Use Function Results
- Non updating updates
- Optimized Non-clustered Index Maintenance
- Troubleshooting Poor Query Performance: Constant Folding and Expression Evaluation During
Cardinality - Estimation
- Troubleshooting Poor Query Performance: Cardinality Estimation
- Statistical maintenance functionality (autostats) in SQL Server
- INF: Search Arguments That Determine Distribution Page Usage
- Statistics Used by the Query Optimizer in Microsoft SQL Server 2000
- Statistics Used by the Query Optimizer in Microsoft SQL Server 2005
- Batch Compilation, Recompilation, and Plan Caching Issues in SQL Server 2005
- Use Parameters or Literals for Query Inputs
- I Smell a Parameter!
- How to update statistics for large databases
- How It Works: Statistics Sampling for BLOB data
- Index Statistics
- Support WebCast: Effective Indexing and Statistics with SQL 2000
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments