



This article demonstrates how to read data from SQL Server and write it to Apache Parquet files – and vice versa – using Python, pandas, and pyarrow. No native Parquet import/export feature in SQL Server is required: Python acts as the bridge, connecting to SQL Server via SQLAlchemy and pyodbc, reading query results into a pandas DataFrame, and writing the DataFrame to Parquet format using pyarrow. The same Python project also covers reading an existing Parquet file back into SQL Server. Before diving in, the article briefly covers how Parquet’s columnar storage relates to SQL Server’s own columnstore index format – context that makes the format’s design choices immediately intuitive for SQL Server practitioners.
When analytic data is stored directly in SQL Server, a clustered columnstore index is an ideal place for that data to reside. It is column-based, highly compressed, and supports a wide variety of optimizations for both reads and writes.
When analytic data is stored in files, such as for use in Azure Data Factory, Synapse, or Fabric, the Parquet file format will often be used. There are many similarities between these two columnstore formats and the methods they use to improve read/write speeds and storage space.
When writing data from SQL Server to files, though, uncompressed formats such as CSV are often used. While files can be written quickly, the lack of compression can be wasteful and slow as data and file sizes become large.
This article dives into the Apache Parquet file format, how it works, and how it can be used to export and import data directly to SQL Server, even when a data platform that supports Parquet files natively is unavailable to assist.
In the second part of this article, customizations and more advanced options will be highlighted, showing the flexibility of Python as a tool to solve analytic data movement challenges.
Background: Columnstore Indexes in SQL Server
Before diving into this article, there is value in briefly reviewing how columnstore indexes work. If in need of a refresher, check out my series on columnstore indexes here: https://www.red-gate.com/simple-talk/databases/sql-server/t-sql-programming-sql-server/hands-on-with-columnstore-indexes-part-1-architecture/
Background: Apache Parquet File Format
The Parquet file format is a columnar data file format that can be compressed using a variety of different algorithms. It is an open format, meaning that its underlying technology is not owned by any company or organization. This makes it portable and allows data to be stored and managed across different platforms without the typical vendor-lock-in challenges that many data formats pose.
While the Parquet file format can benefit a wide variety of data, it is most effective at storing analytic data. Because data intended for analytics tends to contain repetitive, easy-to-compress values within each individual column, a column-wise format is ideal for its storage. Most conventional file formats, such as CSV, XML, and JSON are all row-based. In these formats, values for all data elements with each row are stored consecutively. This is similar to how a clustered rowstore index stores data in SQL Server: Each column in sequence for each row in the table, one row after another until the end of the table.
The similarities between a columnstore index and a parquet file are no coincidence. Each is built to solve the same exact problem, but in different environments. The challenges of storing large amounts of analytic data in a relational database are quite different from those faced in file formats, and this article will bring them together as a way to improve the movement and storage of data to and from SQL Server.
How is a Parquet File Stored?
The Apache Parquet format can be summarized by this image:
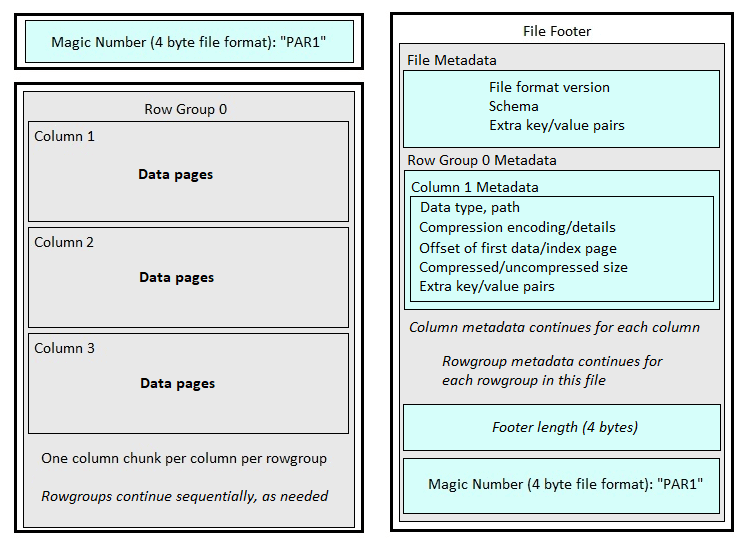
The key elements to note here are:
- Row Groups
- Column Chunks
- File Metadata
- Row Group Metadata
Row groups are similar to those found in columnstore indexes. Their purpose is to break up a large data set into manageable groupings. Whereas Columnstore indexes limit rowgroup size to 220 rows, the size of Row groups in the parquet format is more variable and can be configured. As is often the case with storage-level configurations, there is value in accepting the default settings until use-cases and performance dictate otherwise.
For more information on the Parquet file format, configuration settings, and other details, check out the definitive source: File Format | Parquet (apache.org)
Column chunks are akin to segments in a columnstore index. Each column chunk stores data for a single column within a single row group. The column chunk may be split into any number of data pages, which then store that data sequentially. Like with row groups, data page size can be configured if there is a need to do so.
Each column chunk represents the minimum amount of data that can be read at a time from a parquet file. Compression is applied at the data page level, though. Therefore, it is possible for a single column to have different compression details, even within the same column chunk, via different data pages.
Minimal High-level file metadata is stored in the file footer of each parquet file, allowing tools to quickly identify in general what is stored in the file.
Metadata for each row group is stored in file footer, as well. This includes details of data types, compression, size, and more.
The key to metadata in parquet files is that it allows tools to quickly determine what is stored in the file without reading and analyzing all of the data first. Therefore, queries that need to access many rows of data can do so without reading every one of those rows. This is quite like the function of metadata in columnstore indexes, allowing for functionality similar to segment elimination as unneeded columns and data ranges can automatically be ignored when reading parquet files.
There are many additional optimizations available for parquet files. Some are open-source parts of the file format, whereas others are proprietary add-ons by software vendors. If you see references to V-Order Optimization, Z-Order Optimization, or Liquid Clustering, then recognize that they are performance optimizations intended to:
- Improve compression by tweaking data order.
- Improve performance for specific filters.
- Behave like indexes, where needed, to add critical query/analytics support.
A more detailed discussion of the parquet file format is out-of-scope for this article, as would be a review of Delta Tables/Delta Lake. No further knowledge is needed to understand the code in this article, and in fact, I’ve probably already over-shared quite a bit.
The Lego-Based Approach
Azure SQL Database added both Parquet and delta file support to OPENROWSET, though this functionality is currently in private preview. Azure SQL Managed Instance has this support currently available, as well (without the private preview limitation). If you have access to either of these options, then reading Parquet files into SQL Server can be accomplished using a relatively streamlined and familiar approach. Due to the limited scope and access to these features, we will not delve into them as part of this article.
To otherwise read and write parquet files from SQL Server requires a set of different processes to be pieced together. I like to refer to this as a “Lego-Based Approach”, with each process being a different Lego brick.
For this project, the components that will be used include:
- SQL Server
- SQL Server Agent
- Python
- Including some free widely available libraries
- Anaconda
There are many ways to accomplish the goals of this project, including other programming languages, task-scheduling agents, data platforms, and more. Feel free to customize the approach to meet the needs/limitations of your data platform and software development environments.
Why Python?
Python is the Swiss-army-knife of tools in the best possible way and is the glue that brings everything in this project together. It is extremely versatile, with a seemingly endless supply of well-maintained libraries, ensuring that further customization is not difficult or impossible.
A huge bonus: Most platforms support Python. Whether your code is in Azure, AWS, on-premises, or elsewhere, Python is a readily available tool that will continue to serve us well for many years to come.
Lastly, learning and using Python is not too challenging. Even for someone with little coding experience, the vast tutorials and example code that are available make it easy to solve problems and understand how scripts work.
If you are a PowerShell enthusiast, then the answer to your next question is: “Yes”. Parquet files can be written and read using PowerShell, and if you are fluent in PowerShell scripting, then the task to replicate the contents of this article there will not be any more challenging that what is presented here.
Installing/Configuring the Tools
To avoid 30 long/boring pages on configuration and install settings, I will include links here to official documentation and instructions on how to set up each tool needed for this project. If you already have any/all installed, then feel free to skim/skip those steps.
Some of these instructions will be second nature to a database engineer/administrator, while others are likely to be easier for a developer. This project dives into a bit of both worlds!
Download and install the Anaconda distribution for Windows:
https://www.anaconda.com/download/success
Create an Environment in Anaconda Navigator for testing our Python scripts:
https://docs.anaconda.com/navigator/tutorials/manage-environments
Install the following Python libraries (and dependencies) from the packages list:
For more details:
https://docs.anaconda.com/anacondaorg/user-guide/packages/installing-packages/
Create a 64-bit ODBC local data source for the SQL Server:
Create a SQL Auth login to SQL for use by this project.:
Create database users/access for the SQL Auth login created above:
If using Visual Studio Code to create/modify python files, then it can be downloaded for free here (or in the appropriate app store):
https://code.visualstudio.com/download
The Python Parquet Project
Python is the language of choice here and will be used as the glue to bind together SQL Server and file system. The general logic that will be followed here will be:
- Import libraries
- Define SQL Server connection properties & file system properties
- Write a SQL Query for the data that is to be written to the file system.
- Connect to SQL Server and read the query data
- Write the data to a parquet file.
Each step will be explored in detail so there is no confusion. This will also allow for easy customization, making scripts like this more extensible. I’m using Visual Studio Code to edit the python file, but you are welcome to use whatever code/text editor you are most comfortable with.
Import Libraries
This is the shortest and simplest task. The following libraries are used in this project:
- Pandas: For reading data from SQL Server into a data frame.
- Pyarrow: To read data from the data frame.
- Pyarrow.csv: Support for writing to the CSV format (for demo purposes).
- Pyarrow.parquet: Support for writing to the parquet format.
- Pyarrow.dataset: Used to demo writing a data set to a partitioned file.
- Sqlalchemy: Used to create the SQL Server connection.
The following python code will import the libraries listed above. Libraries may be omitted that are for demo purposes and you decide to not use going forward:
|
1 2 3 4 5 6 |
import pandas; import pyarrow; import pyarrow.parquet; import pyarrow.csv; import pyarrow.dataset; import sqlalchemy; |
If any errors are encountered that indicate a library cannot be found, be sure that it is installed and available to python for use in this project.
SQL Server Connection & File System Properties
To connect to SQL Server, the server details need to be defined. The following variables will be used to store these details:
|
1 2 3 4 5 |
SERVER = '(local)'; DATABASE = 'AdventureWorks2022'; USERNAME = 'PythonTesting'; PASSWORD = 'TestPythonNow17!'; DRIVER = 'SQL+Server'; |
To keep things simple, I am using my local SQL Server for demo purposes. The login credentials are provided explicitly here, as well. If you decide to use code like this in a production environment, be sure to stash passwords somewhere secure to reduce the potential for unauthorized data access.
(You can download the AdventureWorks sample database here and a copy of SQL Server here) if you don’t already have them available where you can work through the examples)
That handles where the data is coming from. A file path must also be defined where files will be written to:
|
1 |
FILEPATH = 'C:/Users/epollack/Dropbox/SQL/Articles/Exporting Data Into Parquet Files in SQL Server/'; |
For this demo, I’m writing directly to Dropbox (because some HA at home is a good thing!) In a production environment, this is more likely to be a path to a shared drive or cloud service, such as Azure Blob Storage or Amazon s3.
Create a SQL Query
For this demo, a data set will be created with some sales analytics:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SQL_QUERY = """ SELECT ROW_NUMBER() OVER (ORDER BY SUM(SalesOrderHeader.SubTotal) DESC) AS OverallRank, SalesOrderHeader.CustomerID, SUM(SalesOrderHeader.SubTotal) AS SalesTotal, AVG(SalesOrderHeader.SubTotal) AS AvgSaleAmount, MIN(SalesOrderHeader.SubTotal) AS MinSaleAmount, MAX(SalesOrderHeader.SubTotal) AS MaxSaleAmount, COUNT(*) AS CustomerOrderCount FROM Sales.SalesOrderHeader GROUP BY SalesOrderHeader.CustomerID ORDER BY SUM(SalesOrderHeader.SubTotal) DESC """; |
Nothing fancy here. The goal is to be able to quickly and efficiently demo process. Experimenting with different or larger data sets requires only altering the query defined above.
Connect to SQL Server and Read Data
This task is made easy by leaning on some of the libraries that were imported earlier in this article:
|
1 2 3 4 |
engine = sqlalchemy.create_engine('mssql+pyodbc://{}/{}?driver={}'.format(SERVER, DATABASE, DRIVER)); dataframe = pandas.read_sql_query(SQL_QUERY, engine); table = pyarrow.Table.from_pandas(dataframe); |
The first line defines the connect string using variables declared earlier. If changes are needed, adjust the variables or make new ones to splice into here. Doing so is far more scalable than manually hacking the connection string whenever an adjustment has to be made.
A data frame is used to store the data in-memory, prior to writing it to a file. From there, the data is staged in a table, which is the ideal format for outputting the data to a file of any format. Note that there is no formatting of data occurring as it is read. Ideally, data should be manipulated as little as possible here as it is very easy to accidentally introduce bugs into data types. For example:
- Accidentally rounding a decimal to the wrong place.
- Truncating a string or number.
- Storing a data or bit as a less obvious data type
- Adjusting formatting unintentionally
Ideally an analytics or business application should format data, rather than data engineers knee-deep in code 😊
From here, code can be crafted to export the data stored in that Pyarrow table into whatever file format we wish, Before doing so, let’s quickly review how we will run this project.
Running the Project
From Anaconda Navigator, the project begins in an environment I named ParquetTesting, which was set up according to the instructions from earlier in this article:
Clicking the play icon on the environment and choose the “Open Terminal” option, which will open a command prompt:
Nothing exciting to see here, yet. Before starting, be sure to change to the directory where the Python script resides. In this example, the following command is executed:
|
1 |
Cd C:\Users\epollack\Dropbox\SQL\Articles\Exporting Data Into Parquet Files in SQL Server |
We are ready to go! The following code can be added to the Python script, which will export the data in the Pyarrow table to a CSV file called customer_totals.csv:
|
1 |
pyarrow.csv.write_csv(table, FILEPATH + 'customer_totals.csv',<br> write_options=pyarrow.csv.WriteOptions(include_header=True)); |
All files are being maintained in the same directory where the Python script was created. Any paths can be customized if needed relatively easily.
After saving, the Python file can be executed from the Anaconda terminal with the following command:
|
1 |
python "C:\Users\epollack\Dropbox\SQL\Articles\Exporting Data Into Parquet Files in SQL Server\ParquetTesting.py" |
The result is a new file in the working directory:
Opening the file shows a sample of the expected CSV output: 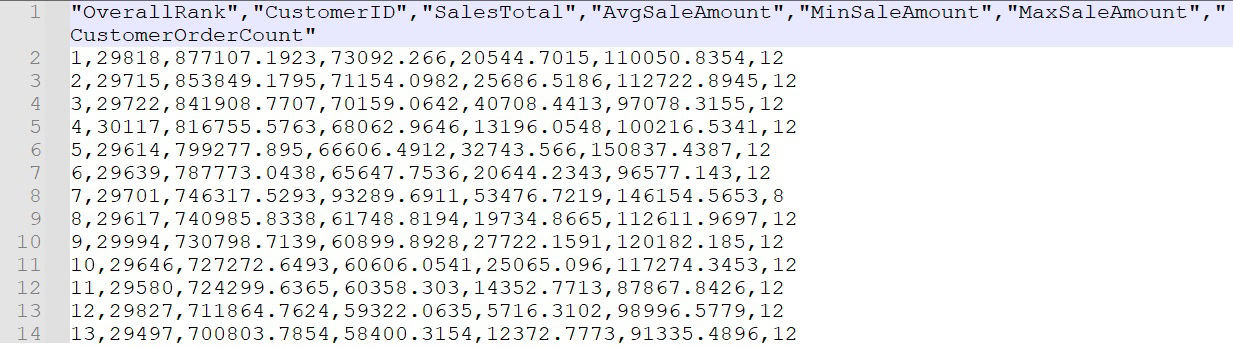
Note that the header column names were explicitly included via the Python script and can be removed by instead setting the property: include_header=false. The file size for the CSV is 787KB, which will soon be relevant to our discussion of compression.
The file creation code can be adjusted to instead use the parquet library from Pyarrow:
|
1 |
pyarrow.parquet.write_table(table, FILEPATH + 'customer_totals.parquet', compression=None); |
For this first parquet test, no compression will be used. The result is a 552KB parquet file:
The file size decreased to 552KB! While no specific compression algorithm was applied, the columnstore nature of the parquet file format allows for files to generally be smaller, even with no additional efforts applied to further shrinking it.
Parquet supports a variety of compression algorithms. We can test a handful of them here using the following code:
|
1 2 3 4 5 6 |
pyarrow.parquet.write_table(table, FILEPATH + 'customer_totals_lz4.parquet', compression="lz4"); pyarrow.parquet.write_table(table, FILEPATH + 'customer_totals_snappy.parquet', compression="snappy"); pyarrow.parquet.write_table(table, FILEPATH + 'customer_totals_gzip.parquet', compression="gzip"); |
When executed, three new files will be created:

Each is smaller than the previous examples, with the resulting compression ratios being dependent on the data and the algorithm used. For this data set, the gzip algorithm provided the largest compression ratio, shrinking the file to less than 50% of the initial parquet file size. Experimentation can be used to determine the ideal compression algorithm, or a default can be chosen based on availability, comfort, or organizational standards.
The key takeaway at this point in the experiment is that the gzip compressed parquet file is about 30% of the size of the original CSV file, highlighting the immense storage savings provided here. Those savings will compound when files need to be copied, backed up, or stored/read in other systems.
Conclusion
The beauty of Python is that it is highly customizable. Libraries exist for so many tasks and more are being created/improved every day. This article provided a glimpse of how data can be exported from SQL Server into the Parquet file format using Python and some freely available libraries.
The data source could be Postgres, MySQL, or something else. Similarly, file formats, names, and the processes for ingesting these files are wholly customizable.
Your imagination is the limit in terms of how processes like this can be built, customized, and implemented.
We dove into the Parquet file format for this article as there is no out-of-the-box way to accomplish the tasks that were tackled here. Despite no native one-tool process, solutions can be built, customized, and implemented to accomplish what we wanted to.
This is the first of two articles that investigate the use of Python to create, manage, move, and read Parquet files to and from SQL Server. The second article will introduce additional options, including how to adjust Parquet file format attributes and file properties.
FAQs: Reading and writing parquet files in SQL Server
1. Can SQL Server read Parquet files natively?
SQL Server does not support Parquet files natively in on-premises versions. Azure SQL Database and Azure SQL Managed Instance have added OPENROWSET support for Parquet files in Azure Blob Storage, though this was in preview at the time of writing. For on-premises SQL Server, the most practical approach is to use Python (with pandas and pyarrow) or Azure Data Factory as intermediary tools to read Parquet data and load it into SQL Server tables.
2. What is Apache Parquet and why is it used with SQL Server?
Apache Parquet is an open-source columnar storage format designed for efficient analytical workloads. It stores data column-by-column (rather than row-by-row), enabling fast reads of specific columns across large datasets, and achieves high compression ratios for analytical data. It is the standard interchange format for data pipelines involving cloud storage, Spark, and Azure Synapse. SQL Server practitioners encounter Parquet when integrating SQL Server with modern data lake or analytical pipeline architectures.
3. How do I read a SQL Server table into a Parquet file using Python?
Connect to SQL Server using sqlalchemy and pyodbc (via create_engine with a connection string). Execute a SELECT query and load the result into a pandas DataFrame using pd.read_sql(). Write the DataFrame to a Parquet file using df.to_parquet(‘output.parquet’, engine=’pyarrow’). The pyarrow library handles the columnar serialisation. Ensure the pandas and pyarrow packages are installed in your Python environment, along with the ODBC Driver for SQL Server.
4. What Python libraries do I need to work with SQL Server and Parquet?
The core libraries are: pandas (for reading SQL query results into DataFrames and writing/reading Parquet), pyarrow or fastparquet (for the Parquet engine), sqlalchemy (for the database connection abstraction), and pyodbc (for the SQL Server ODBC driver interface). Install via pip: pip install pandas pyarrow sqlalchemy pyodbc. For Anaconda environments, use conda install pandas pyarrow sqlalchemy and pip install pyodbc separately.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved



Load comments