
Accessing remote data in SQL Server – whether from other SQL Server instances, PostgreSQL, Oracle, flat files, or APIs – requires careful architecture to avoid the latency and reliability problems that plague cross-server queries. The three primary methods are linked servers (with OPENQUERY for optimal performance over four-part naming), SSIS packages (for scheduled batch loads), and OPENROWSET (for ad hoc access without a persistent linked server). Key optimization principles: pull only the data you need by pushing filters to the remote server, land remote data into local temp tables before joining to local data, validate data quality before processing, and build error handling and retry logic for network failures. This guide covers each method with working examples and performance comparisons.
Introduction
Data rarely resides in one place. Oftentimes, there is a need to collect data from many different data sources and combine them locally into meaningful reports, analytics, or tables. The process for accessing, collecting, validating, and using data from remote data sources requires the same level of design and architectural considerations as building data structures for a software application.
In this article, methods of accessing remote data will be introduced with the goal of presenting best practices and ways to optimize load processes. This will lead into a discussion of performance and how to avoid the latency often associated with loading data from remote locations.
What are Remote Data Sources?
It seems like a trivial question, but identifying the many places that data can be gathered from is important towards collecting data from them in efficient and meaningful ways. For the sake of this article, a remote data source will be any data that resides on a different server, instance, or location than the target database.
For help with identifying and solving index scan problems, click here.
Databases on the same SQL Server that can be referenced without a linked server or remote alias are not considered remote, whereas the following are examples of remote data sources:
- SQL Servers configured on other instances in the same cluster or on the same server.
- SQL Servers on remote hardware/platforms.
- Other flavors of database servers, such as PostgreSQL, MySQL, Oracle, Redshift, etc.
- Data from flat files, Excel, CSV, or other data from non-database sources.
- Data from application APIs.
- Data from cloud-hosted software platforms.
Getting started
Because a data source is remote, we may or may not have any control over the data and schema stored there. Part of the data discovery process is to understand the remote data source and its contents. Some questions worth asking before diving in are:
- Do I control this data source, or is it owned and maintained by others?
- If owned by someone else, then who owns it, and how do I contact them?
- How familiar am I with the database technology?
- If not familiar, can I get by without fully understanding it? If not, who or what training can help?
- How familiar am I with the database schema?
- If not very familiar, who is the subject-matter expert for it?
- How often do these data sources change or get upgraded/modified?
- How can changes be tracked in a meaningful fashion?
- Does the remote data source experience outages or maintenance windows?
- What are the details?
- Are there limitations on connections, queries, or resource usage?
- What are the limitations?
- How reliable is the data? Does it require validation prior to usage?
Many questions here revolve around the causes of trouble that often plague the usage of remote data sources. Understanding what can go wrong and which people or resources are available to help can make a huge difference in meaningfully using this data.
Building processes that are resilient will go a long way towards making their maintenance simpler and less of a burden on your valuable time.
Example #1: A remote SQL Server
The simplest example to demo is a remote SQL Server. To do this, a linked server will be created between a SQL Server 2019 instance and a separate SQL Server 2016 instance:
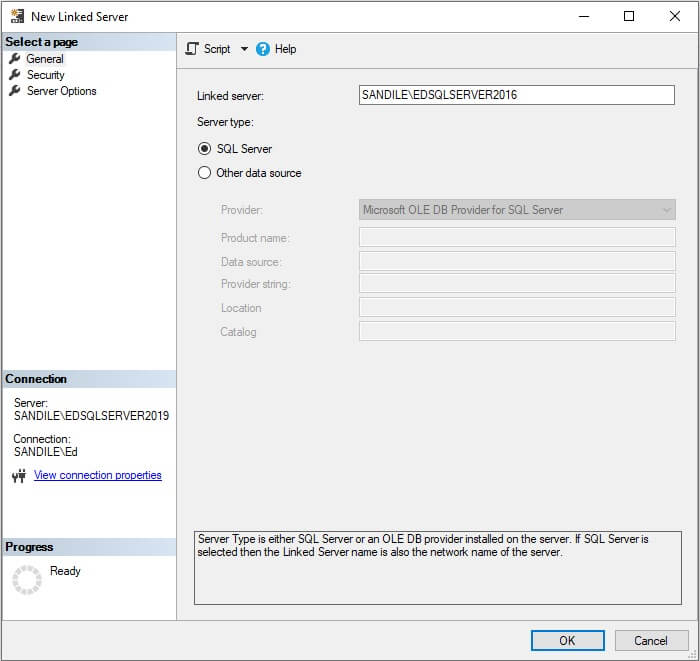
On the first screen, the server and instance name are supplied. Since the port is the default of 1433, it does not need to be supplied. Choosing SQL Server as the server type greatly reduces the amount of work needed here. As a bonus, linked servers can be created to earlier or later versions of SQL Server if needed.
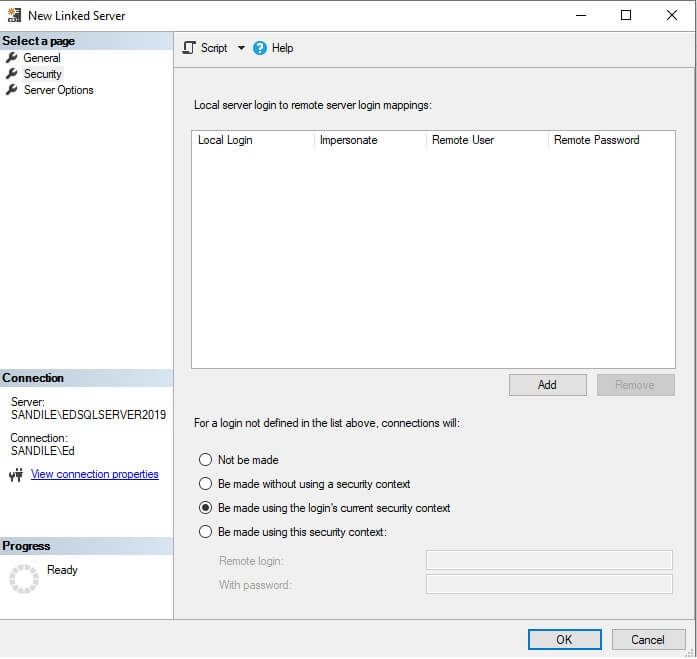
Security is being configured to pass authentication credentials from the calling TSQL into the linked server. This means that if the login that is used to run a data collection process is different than the login testing it, permissions may need to be granted to the login to be used to ensure it can access the server and databases targeted by the linked server.
A variety of additional options are available as well:
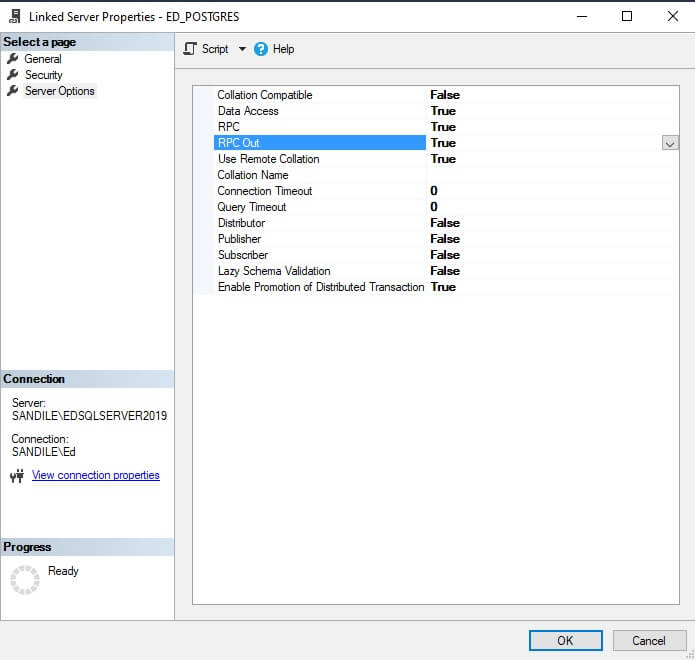
Most of these can be left as-is, but the settings RPC and RPC Out may need to be adjusted to allow for remote procedure calls to or from the server. RPC allows remote procedure calls from the remote server, whereas RPC Out allows remote procedure calls to the remote server.
These options can be set at any time now or modified after the linked server is created if changes are needed.
Once created, the linked server can be accessed as if it were a table:
|
1 2 3 4 5 6 7 8 |
SELECT ProductID, Name, Color, Size, Weight FROM [SANDILE\EDSQLSERVER2016].AdventureWorks2014.Production.Product WHERE ProductID = 317 |
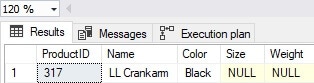
This returns results as if we were on the target server:
Similarly, we can join tables together and return results for a more complex query, if needed:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT Product.ProductID, Product.Name, Product.Color, PRODUCT_SIZE.Name AS product_size_name, PRODUCT_WEIGHT.Name AS product_weight_name FROM [SANDILE\EDSQLSERVER2016].AdventureWorks2014.Production.Product INNER JOIN [SANDILE\EDSQLSERVER2016].AdventureWorks2014.Production.UnitMeasure PRODUCT_SIZE ON PRODUCT_SIZE.UnitMeasureCode = Product.SizeUnitMeasureCode INNER JOIN [SANDILE\EDSQLSERVER2016].AdventureWorks2014.Production.UnitMeasure PRODUCT_WEIGHT ON PRODUCT_WEIGHT.UnitMeasureCode = Product.WeightUnitMeasureCode WHERE ProductID = 917; |
As before, the results are what is expected from the query:

So far, this seems easy, but the time for easy ends here. Why? Because the query that was just demonstrated may or may not perform the way that a query with joins on indexed columns would be expected to perform.
When objects are joined together via a linked server, SQL Server attempts to find an efficient way to either execute it remotely or retrieve data to the local server for processing. A quick look at the execution plan and IO statistics provides little knowledge on the query’s performance:

The execution plan indicates that the query was executed remotely, which is ideal for a query being executed via linked servers. The downside to this execution plan is that no indication is given as to what the plan actually was, making optimization challenging, if needed.
![]()
The output of STATISTICS IO is not useful as the IO occurred on a remote machine and is not captured here. The result is an empty output from STATISTICS IO.
The limited information provided by SQL Server leads into a legitimate challenge where the performance of remote queries can be abysmal, and no one will know unless a complaint is made about the latency of a report, load process, or server performance problems. Since being proactive with regards to performance is far better than being reactive, the remainder of this article will focus on ways to write remote queries that are resilient towards performance problems.
Read also: The default trace for auditing
Remote servers are black boxes to SQL Server!
The key to writing efficient remote queries is to view each remote object as a black box to SQL Server. The local server does not have complete knowledge of the remote objects and will make an educated guess as to whether it can or should be executed remotely and then do so. It is challenging to confirm whether the query executed optimally or not as many of our optimization tools do not return sufficient data about IO, execution plan operators, and more.
The only way to review the performance of a given query would be to log into the remote server and check it there. For example, logging into the remote server from the previous example allows the plan cache to be searched, like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT databases.name, dm_exec_sql_text.text AS TSQL_Text, dm_exec_query_stats.creation_time, dm_exec_query_stats.execution_count, dm_exec_query_stats.total_worker_time AS total_cpu_time, dm_exec_query_stats.total_elapsed_time, dm_exec_query_stats.total_logical_reads, dm_exec_query_stats.total_physical_reads, dm_exec_query_plan.query_plan FROM sys.dm_exec_query_stats CROSS APPLY sys.dm_exec_sql_text(dm_exec_query_stats.plan_handle) CROSS APPLY sys.dm_exec_query_plan(dm_exec_query_stats.plan_handle) INNER JOIN sys.databases ON dm_exec_sql_text.dbid = databases.database_id WHERE dm_exec_sql_text.text LIKE '%UnitMeasure%'; |
The results provide some metrics, including execution count, duration, execution plan, IO, and the actual query text that was executed:

The following is the SQL text for the query that was previously executed:
|
1 2 3 4 5 6 7 8 |
SELECT "Col1031","Col1032","Col1034","Tbl1004"."Name" "Col1026","Col1029" FROM "AdventureWorks2014"."Production"."UnitMeasure" "Tbl1004", (SELECT "Col1031","Col1032","Col1034","Col1035","Col1036","Tbl1006"."UnitMeasureCode" "Col1028","Tbl1006"."Name" "Col1029","Col1037","Col1033","Col1038" FROM "AdventureWorks2014"."Production"."UnitMeasure" "Tbl1006", (SELECT "Tbl1002"."ProductID" "Col1031","Tbl1002"."Name" "Col1032","Tbl1002"."Color" "Col1034","Tbl1002"."SizeUnitMeasureCode" "Col1035", "Tbl1002"."WeightUnitMeasureCode" "Col1036","Tbl1002"."Weight" "Col1037","Tbl1002"."ProductNumber" "Col1033","Tbl1002"."rowguid" "Col1038" FROM "AdventureWorks2014"."Production"."Product" "Tbl1002" WHERE "Tbl1002"."ProductID"=(917)) Qry1039 WHERE "Col1036"="Tbl1006"."UnitMeasureCode") Qry1040 WHERE "Tbl1004"."UnitMeasureCode"="Col1035" |
That is a mess! Looking closer, it can be determined that the query is essentially the one previously executed, and it performed well, as can be confirmed by viewing the execution plan:
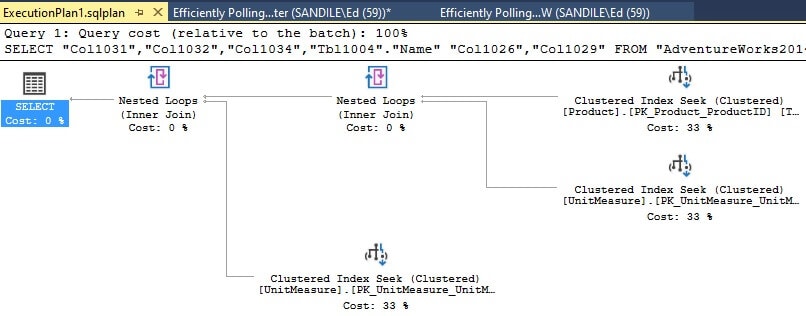
It took some extra effort to get this information. Because the remote server may not always be available for querying and digging up details, this approach becomes cumbersome. Something better is needed, especially as queries get larger and more complex.
Optimizing remote data loads using OPENQUERY
Since optimizing remote queries is challenging, writing efficient TSQL becomes more important than ever. Prevention is, by far, the best performance problem solution.
The first step towards accomplishing this will be to use OPENQUERY to manage remote DML queries (that is: not schema or server changes). The syntax of the previous example when converted to use OPENQUERY will look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT ProductID, Name, Color, product_size_name, product_weight_name FROM OPENQUERY([SANDILE\EDSQLSERVER2016], ' SELECT Product.ProductID, Product.Name, Product.Color, PRODUCT_SIZE.Name AS product_size_name, PRODUCT_WEIGHT.Name AS product_weight_name FROM AdventureWorks2014.Production.Product INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_SIZE ON PRODUCT_SIZE.UnitMeasureCode = Product.SizeUnitMeasureCode INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_WEIGHT ON PRODUCT_WEIGHT.UnitMeasureCode = Product.WeightUnitMeasureCode WHERE ProductID = 917;'); |
The syntax of OPENQUERY consists of the remote server name and the query to execute, formatted as a string. The results are returned the same as they were before, and the execution plan has changed slightly:
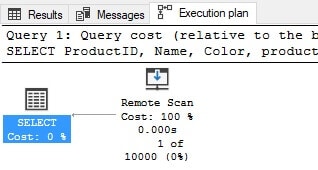
This plan indicates that the contents of the OPENQUERY script are executed as-is, and the results are scanned in their entirety. This syntax emphasizes that the script passed into OPENQUERY truly is a black box script that will remotely execute as-is, as though it had been executed locally on the remote server.
One upshot of this is that the remote execution plan and query look exactly like what was executed above. When the query text is viewed in the cache of the target server, the following is returned:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT Product.ProductID, Product.Name, Product.Color, PRODUCT_SIZE.Name AS product_size_name, PRODUCT_WEIGHT.Name AS product_weight_name FROM AdventureWorks2014.Production.Product INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_SIZE ON PRODUCT_SIZE.UnitMeasureCode = Product.SizeUnitMeasureCode INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_WEIGHT ON PRODUCT_WEIGHT.UnitMeasureCode = Product.WeightUnitMeasureCode WHERE ProductID = 917; |
In addition, the execution plan is the same as it was before. This helps confirm that the query is being executed exactly as it is written on the source server and is not being rewritten on-the-fly. In addition, the contents of OPENQUERY cannot be executed locally on the source server, which helps prevent the potential for excessive data transfer from target to source.
Because the OPENQUERY TSQL string appears in SQL Server Management Studio as a string (aka a giant blob of red), it becomes important to write queries within the string just like a standard query. This is a similar practice to when dynamic SQL is being written.
It is possible to issue INSERT, DELETE, and UPDATE operations using OPENQUERY as well. This can be a useful way to craft highly-performant write operations against a remote database. Since this is not the goal of this article, though, the demonstration of syntax can be left to Microsoft. The following link provides the basic structure of INSERT, UPDATE, and DELETE operations when utilized as part of an OPENQUERY statement:
https://docs.microsoft.com/en-us/sql/t-sql/functions/openquery-transact-sql?view=sql-server-ver15
Optimizing remote data loads using EXEC…AT
Not all remote operations can be efficiently modelled using OPENQUERY. The most common examples of this are schema changes or server/database configuration changes. For these operations, EXEC…AT is a convenient syntax that provides similar functionality to OPENQUERY but can be used under different circumstances.
For example, if there was a need to set AUTO_UPDATE_STATISTICS_ASYNC on a target database, it could be accomplished like this:
|
1 |
EXEC ('ALTER DATABASE AdventureWorks2014 SET AUTO_UPDATE_STATISTICS_ASYNC ON') AT [SANDILE\EDSQLSERVER2016]; |
The setting change can be confirmed by connecting to the target server and viewing the database settings:
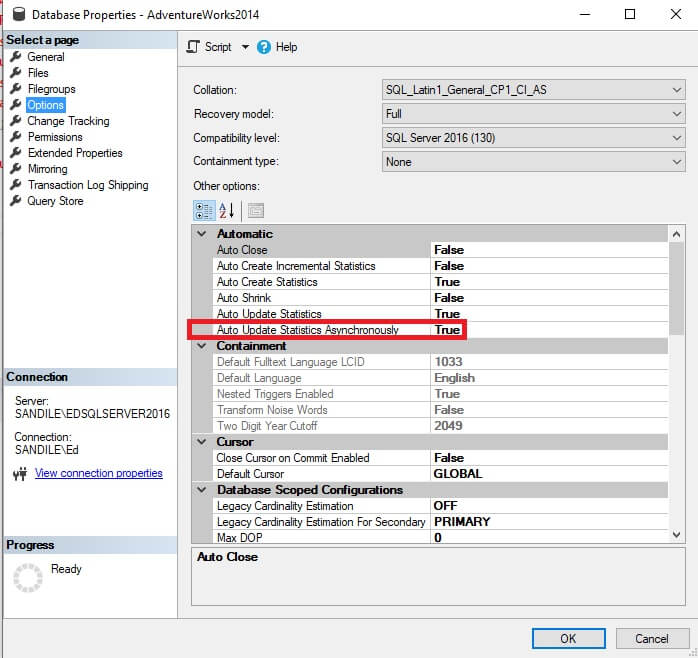
As long as permissions allow, this syntax can be used to issue commands on the target server as if they were being executed locally there. This can prove useful when using a Central Management Server, or when looking to update many remote databases or servers from a central location.
Using dynamic SQL to improve remote filtering
The challenge with the syntaxes for OPENQUERY and EXEC…AT is that there is no way to easily concatenate strings as part of the query string. For example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @ProductID INT = 917; SELECT ProductID, Name, Color, product_size_name, product_weight_name FROM OPENQUERY([SANDILE\EDSQLSERVER2016], ' SELECT Product.ProductID, Product.Name, Product.Color, PRODUCT_SIZE.Name AS product_size_name, PRODUCT_WEIGHT.Name AS product_weight_name FROM AdventureWorks2014.Production.Product INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_SIZE ON PRODUCT_SIZE.UnitMeasureCode = Product.SizeUnitMeasureCode INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_WEIGHT ON PRODUCT_WEIGHT.UnitMeasureCode = Product.WeightUnitMeasureCode WHERE ProductID = ''' + @ProductID + ''';'); |
This query will not pass a syntax check as SQL Server cannot resolve the local variable cannot be spliced into the string as-is. The resulting error is:

SQL Server expects a single string, and that string must be deterministic. As such, the following syntax also will not pass a syntax check:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @openquery_script VARCHAR(MAX) = ' SELECT Product.ProductID, Product.Name, Product.Color, PRODUCT_SIZE.Name AS product_size_name, PRODUCT_WEIGHT.Name AS product_weight_name FROM AdventureWorks2014.Production.Product INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_SIZE ON PRODUCT_SIZE.UnitMeasureCode = Product.SizeUnitMeasureCode INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_WEIGHT ON PRODUCT_WEIGHT.UnitMeasureCode = Product.WeightUnitMeasureCode WHERE ProductID = 917;'; SELECT ProductID, Name, Color, product_size_name, product_weight_name FROM OPENQUERY([SANDILE\EDSQLSERVER2016], @openquery_script); |
The error returned is similar to the previous one:

If there is a need to dynamically add filters or other details into a remote query, the optimal way to do so is with dynamic SQL. For example, if the previous example had an ID that was determined at runtime, then it can be spliced into the query string like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
DECLARE @sql_command NVARCHAR(MAX) DECLARE @ProductID INT = 917; SELECT @sql_command = ' SELECT ProductID, Name, Color, product_size_name, product_weight_name FROM OPENQUERY([SANDILE\EDSQLSERVER2016], '' SELECT Product.ProductID, Product.Name, Product.Color, PRODUCT_SIZE.Name AS product_size_name, PRODUCT_WEIGHT.Name AS product_weight_name FROM AdventureWorks2014.Production.Product INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_SIZE ON PRODUCT_SIZE.UnitMeasureCode = Product.SizeUnitMeasureCode INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_WEIGHT ON PRODUCT_WEIGHT.UnitMeasureCode = Product.WeightUnitMeasureCode WHERE ProductID = ''''' + CAST(@ProductID AS VARCHAR(MAX)) + ''''';'');'; EXEC sp_executesql @sql_command; |
This query is not in any way pretty, but the end result is a clean query that is executed at the remote server. Because dynamic SQL is wrapped around the OPENQUERY string, it is necessary to escape apostrophes with extra care to ensure that the resulting script is syntactically and logically correct.
Note that a parameter was not passed into sp_executesql for @ProductID. This is due to the fact that parameters cannot be passed into OPENQUERY. The only way to fully parameterize this query would be to push the filter up to the local server. This would force the entire remote table to be read, which nullifies this optimization effort.
Using PRINT or SELECT to view the dynamic SQL string (@sql_command in this example) is a good way to confirm that the syntax looks as expected. The PRINT output from above is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT ProductID, Name, Color, product_size_name, product_weight_name FROM OPENQUERY([SANDILE\EDSQLSERVER2016], ' SELECT Product.ProductID, Product.Name, Product.Color, PRODUCT_SIZE.Name AS product_size_name, PRODUCT_WEIGHT.Name AS product_weight_name FROM AdventureWorks2014.Production.Product INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_SIZE ON PRODUCT_SIZE.UnitMeasureCode = Product.SizeUnitMeasureCode INNER JOIN AdventureWorks2014.Production.UnitMeasure PRODUCT_WEIGHT ON PRODUCT_WEIGHT.UnitMeasureCode = Product.WeightUnitMeasureCod WHERE ProductID = ''917'';'); |
Since the output is stripped of colors in the PRINT window, it can be pasted into another SSMS window so that it is easier to troubleshoot.
The primary benefits of this approach are flexibility and performance. Dynamic SQL allows a query to be customized as much as is needed, even when the details of those changes are not known until runtime.
Because the resulting query is to the remote server for execution in a single operation, there is little opportunity for SQL Server to perform joins poorly, rewrite the query in a suboptimal fashion, or choose an exceptionally poor execution plan. The performance experienced will be the same performance expected when running the query directly on the remote server.
Dynamic SQL is an excellent way to take complete control of remote queries and improve performance. The downside of this approach is readability. To balance these needs, always consider alternative approaches first if they can deliver all needed features to a remote data access project.
Avoid joining remote tables together in queries when possible without OPENQUERY as the opportunity for performance challenges will increase with the complexity of the query. The resulting performance problems may be difficult to isolate and resolve without already being aware of the limitations of straight-up querying against linked servers.
Read also: Creating CSV files using BCP and stored procedures
Example #2: A remote PostgreSQL server
A linked server may be created to any data source that is either pre-defined in SQL Server or that can be encapsulated in an ODBC data source. This allows data to be written or read from non-SQL Server databases. The list of possible data sources that can be queried is vast, and most common database systems can be accessed by this method.
For this demonstration, a PostgreSQL database has been set up on my local server with a movie rental database. This sample data contains information about movies, actors, genres, prices, rental terms, and more.
To access this database, an ODBC data source needs to be configured that can connect to the server and communicate between it and whatever program accesses it (in this case, SQL Server). This requires downloading and installing an ODBC driver that supports Postgres. For this demo, the 64-bit Windows driver will be downloaded from the PostgreSQL home page: https://odbc.postgresql.org/
Once the driver is installed, an ODBC connection must be set up via the ODBC Data Source Administrator menu:
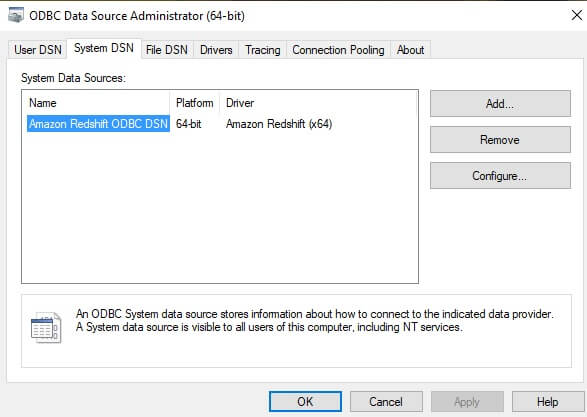
From the System DSN tab, select “Add…” and scroll down to the appropriate driver. In this example, the PostgreSQL Unicode(x64) driver will be used.
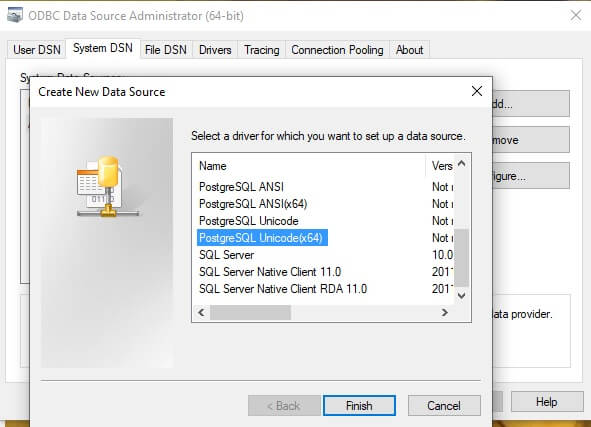
Finally, the data source is configured to connect to my local Postgres server:
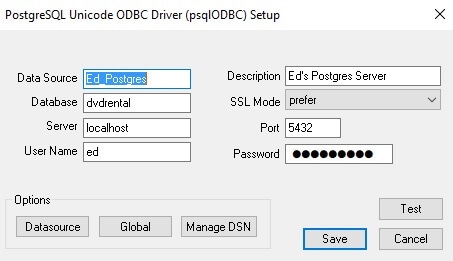
With the ODBC data source created, a linked server can now be created in SQL Server to connect via the data source to Postgres and access its data:
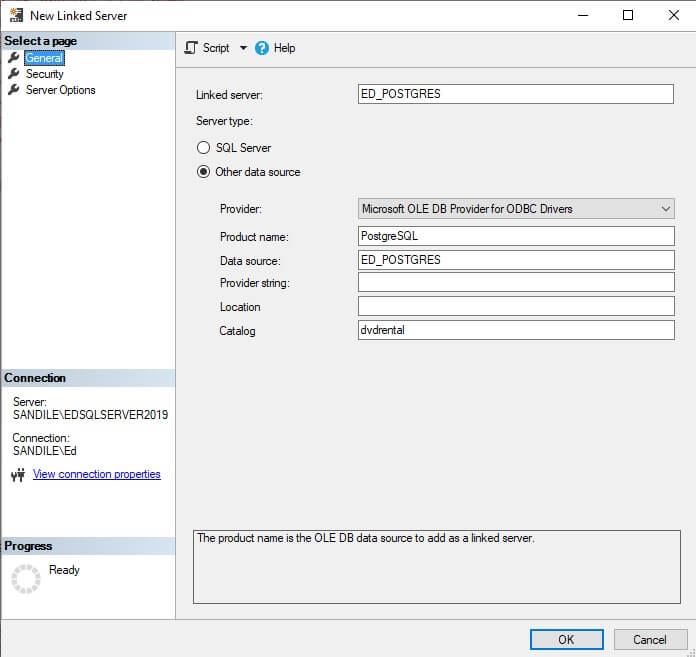
The security configuration for this server has a specific login configured, so that login is used here:
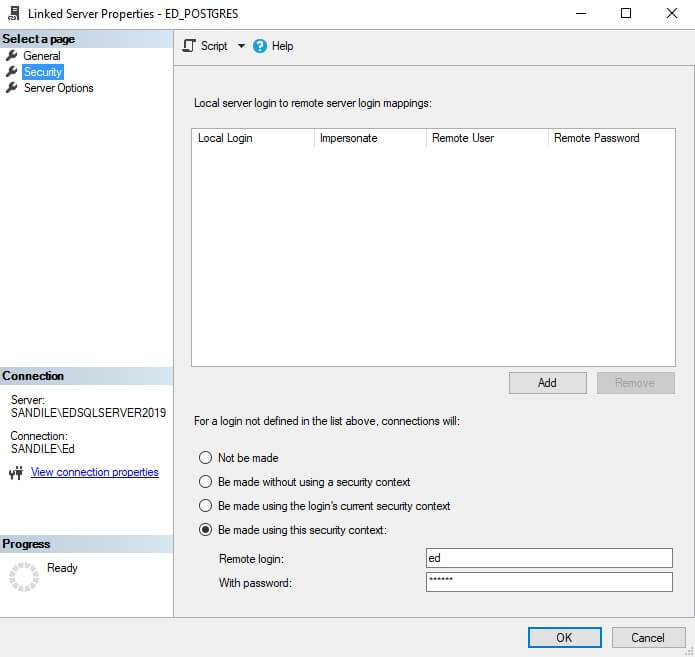
Now, to test a simple query against the server:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM OPENQUERY([ED_POSTGRES], 'SELECT first_name || '' '' || last_name AS full_name, actor_id FROM public.actor;') WHERE actor_id IN (17, 23); |
Note that all query syntax within OPENQUERY will obey the syntax rules of the target database system. In this example, anything sent via OPENQUERY to Postgres needs to obey the syntax rules of Postgres. Similarly, Postgres features or functions can be taken advantage of that do not exist in SQL Server. Anything outside of the OPENQUERY string must be written in TSQL for SQL Server. This convention allows for some mixing of database server features that can prove beneficial when one system has a feature that the other does not.
The results of this query are as if it were run locally on the Postgres server:
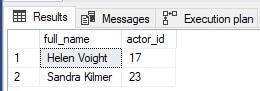
I made an intentional performance goof here: By placing the filter outside of the OPENQUERY script, Postgres is forced to scan the entire table and return all of that data before SQL Server can filter it.
Since the contents of OPENQUERY are a black box to SQL Server, they are executed as-is, regardless of what TSQL appears outside of it. This can be confirmed by viewing the execution plan in SQL Server:
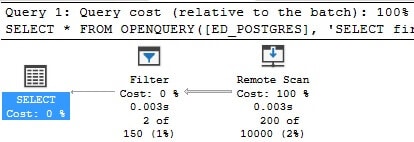
Note that the remote data source is scanned and then filtered afterwards. Had the remote table been large, then this query would have performed poorly in many ways:
- It would have taken a long time to execute
- The Postgres server would experience high IO and memory usage as it retrieves the entire contents of the table.
- The network between the servers (if they are remote) would need to transfer all of that data.
- SQL Server would be forced to receive and temporarily store all of that data first, prior to filtering it, consuming even more storage and memory.
A poorly performing remote query is doubly bad for systems and users as the data needs to be read and managed by two systems instead of one, in addition to whatever network connection exists between them.
To resolve this, the IDs need to either be embedded into the OPENQUERY script or dynamic SQL used to insert them as-needed. The following is a valid solution, if hard-coding filters is acceptable:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM OPENQUERY([ED_POSTGRES], 'SELECT first_name || '' '' || last_name AS full_name, actor_id FROM public.actor WHERE actor_id IN (17, 23);'); |
Note that when executed, the execution plan no longer has the extra filter operator:
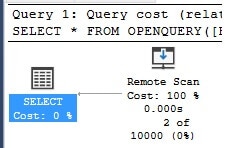
This indicates that the WHERE clause was executed as part of the query that was issued in Postgres, and not after-the-fact in SQL Server. An alternate way to manage this would be dynamic SQL, like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DECLARE @sql_command NVARCHAR(MAX) DECLARE @actor_id_string VARCHAR(MAX) = '17, 23'; SELECT @sql_command = ' SELECT * FROM OPENQUERY([ED_POSTGRES], '' SELECT first_name || '''' '''' || last_name AS full_name, actor_id FROM public.actor WHERE actor_id IN (' + @actor_id_string + ');'');'; PRINT @sql_command; EXEC sp_executesql @sql_command; |
The resulting TSQL that is printed prior to the dynamic SQL execution looks like this::
|
1 2 3 4 5 6 7 8 |
SELECT * FROM OPENQUERY([ED_POSTGRES], ' SELECT first_name || '' '' || last_name AS full_name, actor_id FROM public.actor WHERE actor_id IN (17, 23);'); |
The variable @actor_id_string is used to hold a list of IDs that are passed into the query and subsequently into Postgres as the query filter.
Effective remote query patterns
The key to efficient remote querying is to ensure that as much grouping, filtering, joining, and data simplification as possible occurs remotely. The more data that is dragged back to SQL Server, the more computing resources will be needed to move and crunch the extra data and the longer a query will take to complete.
The following are some best practices that can help improve processes that require data to be loaded from remote locations:
- Ensure that filters are included within the remote query. Dynamic SQL is an efficient way to accomplish this when variables cannot be hard-coded into the query.
- Consider splitting a large query into smaller parts. If data needs to be filtered on multiple levels, then instead of writing a large monster query, break it into a set of remote queries that use the results from each other to filter its own results.
- If significant data manipulation is needed, the results of the remote query can be placed into a temporary table. This allows the remote connection to be closed and the resulting data be managed locally in SQL Server. This also helps prevent remote queries from becoming too large or complex.
- If a data retrieval process takes too long, consider having the remote server manage the data crunching internally. Once complete, the remote server can drop the results into a table. When the data is needed, SQL Server can pull data from the results table, rather than issuing an expensive query on-the-fly to the remote server.
In general, there are no shortcuts to querying remote systems efficiently. Doing so requires an efficient remote query AND a local query that receives and processes that data efficiently. If either is poorly written, then the result could be an unacceptably slow query and/or poor performance on the source server, target server, or both.
Conclusion
As organizations grow and expand, the need will arise to merge together data from many data sources, some local and others remote. Some of these data sources may be SQL Server, whereas others will be a wide variety of database systems, some familiar, others less so.
By considering the structure of data that is to be pulled remotely, a developer or administrator can determine the ideal ways to filter, crunch, and return that data. Filtering as early as possible in the data retrieval process will result in less data needing to be sent from system to system, speeding up queries and reducing resource consumption.
Once filtered, the remainder of the challenge becomes manipulating and storing results. By considering the best practices in this article, a variety of options become available when optimizing a remote data retrieval process becomes a challenge. While the options listed here are by no means exhaustive, they present a wide variety of data processing methods that allow for creativity in moving data around. Ultimately it is this creativity that will provide a solution to a difficult problem and improve performance and processes when similar challenges arise in the future.
Fast, reliable and consistent SQL Server development…
FAQs: How to efficiently poll remote data sources in SQL Server
1. What is the difference between OPENQUERY and four-part naming in SQL Server?
Four-part naming (LinkedServer.Database.Schema.Table) sends the query to the local SQL Server engine, which then requests data from the remote server – often pulling entire tables before filtering locally. OPENQUERY sends the query text directly to the remote server for execution, so filtering happens remotely and only the result set travels across the network. For large remote tables, OPENQUERY can be dramatically faster because it minimizes data transfer.
2. How do you optimize linked server queries in SQL Server?
Use OPENQUERY instead of four-part naming to push filtering to the remote server. Pull remote data into a local temporary table first, then join to local tables – this avoids the optimizer making poor cardinality estimates on remote data. Minimize the columns and rows you retrieve. Set appropriate RPC and RPC Out options on the linked server configuration. For large recurring loads, consider SSIS packages instead of linked server queries for better parallelism and error handling.
3. When should you use SSIS instead of linked servers?
Use SSIS for scheduled, recurring data loads from remote sources – especially when you need parallel data flows, transformations, error handling, and logging. Use linked servers for ad hoc queries and real-time lookups where you need immediate results. SSIS handles large-volume batch operations more efficiently than linked servers because it manages memory buffers, threading, and error rows natively.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments