
In this article, I will try to describe how you can implement SQL Server In-Memory OLTP, that is how you can migrate a disk-based table into a memory-optimized as well as how to rewrite the data processing logic using a natively-compiled stored procedure. I will use a simple example in order to make this as easy as possible.
Before analyzing the sample workload to be optimized using In-Memory OLTP, let’s refresh our memory on the two key features of SQL Server In-Memory Optimization which are: (i) Memory-Optimized Tables, and (ii) Natively-Compiled Stored Procedures. These two new features enable the user to load data directly into memory and process them very fast.
Memory-optimized tables
Memory Optimized tables store their data into memory using multiple versions of each row’s data. Therefore, you do not need to worry about locks and latches because a ‘non-blocking multi-version optimistic concurrency control’ approach is followed which eliminates both locks and latches. By saving the time that is normally lost by locks and latches, a database process can be much faster than the traditional ‘disk-based’ processing.
Memory-optimized tables can be ‘durable’ and ‘non-durable’. The contents of a durable memory-optimized table is also stored on disk, thus ensuring access to your data via the transaction logs in the unfortunate event of a server crash or failover. The data of a non-durable memory-optimized table is only stored into memory. To this end, if a server crashes or a failover takes place, then this data will be lost. The decision to use either durable or non-durable memory-optimized tables is a responsibility of the SQL Server user and usually has to do with each specific workload type. For example, if you have a large Data Warehouse staging table that processes millions of records and passes the results to another table, then in such case you could use a non-durable memory-optimized table. In the case where you need to process a table and the data will stay in that table, then you should use a durable memory-optimized table.
Natively-compiled stored procedures
Natively-compiled stored procedures are stored procedures that are compiled to native code when they are defined. This is in contrast to the ‘traditional’ stored procedures that are compiled when they are interpreted, that is during their first run. This characteristic of natively-compiled stored procedures offers significant performance advantage when compared to the traditional stored procedures as invoking a natively-compiled stored procedure is just a DLL call.
Last but not least, natively-compiled stored procedures can only access memory-optimized tables.
The Workload
The example in this article features a fictitious multinational company whose Management decided to give a special salary raise to all of its high-performing employees based on a specific formula. The formula is:
For all employees with a performance score that is equal to or higher than 9, then increase their basic salary by 5%.
The IT Department is requested to implement Management’s decision. This will be done with the use of an UPDATE SQL statement. The company has 1M employees. The disk-based ‘Employees’ table’s design is provided in the below figure:
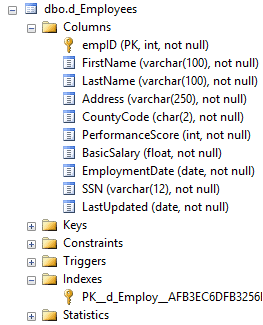
Figure 2.1: Employees Table Design
For this article’s example, the sample data was generated using Redgate’s SQL Data Generator.
Sample Database
The sample database can be created using the DDL script provided in the below listing:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE DATABASE InMemOLTPTest; GO ALTER DATABASE InMemOLTPTest ADD FILEGROUP [InMemOLTPTest_mod] CONTAINS MEMORY_OPTIMIZED_DATA; GO --Note: In the place of 'c:\tmpData\InMemOLTPTest_Dir' you can use any directory ALTER DATABASE InMemOLTPTest ADD FILE (NAME = [InMemOLTPTest_dir], FILENAME= 'c:\tmpData\InMemOLTPTest_Dir') TO FILEGROUP InMemOLTPTest_mod; GO |
Listing 3.1: Creating Sample DB with its Memory-Optimized Filegroup.
Disk-Based Solution Design
The disk-based design (mode) uses the traditional disk-based tables. This is the ‘Employees’ table whose design was illustrated in Figure 2.1. This listing provides the DDL for this table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE InMemOLTPTest; GO --Disk-Based Table Definition CREATE TABLE [dbo].[d_Employees] ( [empID] [INT] NOT NULL PRIMARY KEY , [FirstName] [VARCHAR](100) NOT NULL , [LastName] [VARCHAR](100) NOT NULL , [Address] [VARCHAR](250) NOT NULL , [CountyCode] [CHAR](2) NOT NULL , [PerformanceScore] [INT] NOT NULL , [BasicSalary] [FLOAT] NOT NULL , [EmploymentDate] [DATE] NOT NULL , [SSN] [VARCHAR](12) NOT NULL , [LastUpdated] [DATE] NOT NULL ); GO |
Listing 4.1: Disk-Based Employees Table Definition.
After several tests and execution plans, it was clear that the best option was to have just a clustered index for the above table’s key column (’empID’). This was because the cost for maintaining another index added for the column ‘PerformanceScore’ would be higher than any processing performance benefit, given this example’s workload.
Listing 4.2 provides the UPDATE statement for the disk-based solution:
|
1 2 3 4 5 |
UPDATE dbo.d_Employees SET BasicSalary = BasicSalary + ( BasicSalary * 0.05 ) , LastUpdated = GETDATE() WHERE PerformanceScore >= 9; GO |
Listing 4.2: Processing Logic for Disk-Based Design.
Memory-Optimized Solution Design
For the memory-optimized design we just need to migrate the disk-based table to a memory-optimized table. The UPDATE statement will be similar to the disk-based mode because In-Memory OLTP is seamlessly integrated into SQL Server’s Database Engine and does not require any other special syntax beyond some keywords that enable In-Memory Optimization and set specific options, i.e. BUCKET_COUNT, durability, etc.
The listing below provides the memory-optimized version of the Employees table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
--Memory-Optimized Table Definition CREATE TABLE [dbo].[m_Employees] ( [empID] [INT] NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH ( BUCKET_COUNT = 1500000 ), [FirstName] [VARCHAR](100) NOT NULL , [LastName] [VARCHAR](100) NOT NULL , [Address] [VARCHAR](250) NOT NULL , [CountyCode] [CHAR](2) NOT NULL , [PerformanceScore] [INT] NOT NULL INDEX IX_PS NONCLUSTERED, [BasicSalary] [FLOAT] NOT NULL , [EmploymentDate] [DATE] NOT NULL , [SSN] [VARCHAR](12) NOT NULL , [LastUpdated] [DATE] NOT NULL ) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA); GO |
Listing 5.1.: Memory-Optimized Employees Table Definition.
As you can see, the only difference from the disk-based table’s definition is that we set a NONCLUSTERED HASH index for the key column (’empID’), another NONCLUSTERED index for the ‘PerformanceScore’ column, as well as we enabled In-Memory Optimization by setting the MEMORY_OPTIMIZED option to ON along with specifying the durability option for the table.
By setting durability to ‘SCHEMA_AND_DATA’ it means that the table is durable and the data will be always available, even in the case of a server crash or failover. Another thing you need to note is the BUCKET_COUNT setting. The recommended value for BUCKET_COUNT is to be between 1.5 and 2 times the estimated number of unique values (1M employees in this example) for the indexed column, so in this case we set 1.5M as the BUCKET_COUNT value.
Now that the memory-optimized table is defined, the next step is to define the processing logic. This is the UPDATE SQL statement for the table. As you can see from the below listing, the syntax is identical to the disk-based mode, of course in this case it is the memory-optimized table that is being used.
|
1 2 3 4 5 |
UPDATE dbo.m_Employees SET BasicSalary = BasicSalary + ( BasicSalary * 0.05 ) , LastUpdated = GETDATE() WHERE PerformanceScore >= 9; GO |
Listing 5.2: Processing Logic for Memory-Optimized Design.
Memory-Optimized with Natively-Compiled Stored Procedure Solution Design
As before, we will use a memory-optimized table but in this case it will be processed by a natively-compiled stored procedure.
Listing 6.1 provides the definition for the memory-optimized table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
--Memory-Optimized Table Definition for Natively-Compiled SP CREATE TABLE [dbo].[n_Employees] ( [empID] [INT] NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH ( BUCKET_COUNT = 1500000 ) , [FirstName] [VARCHAR](100) NOT NULL , [LastName] [VARCHAR](100) NOT NULL , [Address] [VARCHAR](250) NOT NULL , [CountyCode] [CHAR](2) NOT NULL , [PerformanceScore] [INT] NOT NULL INDEX IX_PS NONCLUSTERED , [BasicSalary] [FLOAT] NOT NULL , [EmploymentDate] [DATE] NOT NULL , [SSN] [VARCHAR](12) NOT NULL , [LastUpdated] [DATE] NOT NULL ) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA); GO |
Listing 6.1: Memory-Optimized Employees Table Definition for Natively-Compiled SP.
You will have noticed that the definition of the above table is the same like the one used in the memory-optimized design.
The below listing provides the natively-compiled stored procedure’s definition.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
--Natively-Compiled SP Definition CREATE PROCEDURE [dbo].[spUpdateCustomers] WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER AS BEGIN ATOMIC WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english' ) UPDATE dbo.n_Employees SET BasicSalary = BasicSalary + ( BasicSalary * 0.05 ) , LastUpdated = GETDATE() WHERE PerformanceScore >= 9; END; GO |
Listing 6.2: Processing Logic for Memory-Optimized with Natively-Compiled SP Design.
By examining the definition of the natively-compiled stored procedure, you can see that the UPDATE statement is exactly the same as with the disk-based and memory-optimized modes. As mentioned above, natively-compiled stored procedures can only process memory-optimized objects.
Some other points to note about natively-compiled stored procedures are:
- The WITH NATIVE_COMPILATION clause is used in their definition.
- The SCHMABINDING clause is required because it bounds the stored procedure to the schema of the objects it references.
- The BEGIN_ATOMIC clause is required because the stored procedure must consist of exactly one block along with the Transaction Isolation Level.
By examining the definition of the natively-compiled stored procedure, we can see that all the above must be used in order to successfully define the stored procedure.
Execution and Performance Statistics
Before running the three modes/processes, note that the purpose of this run to compare the pure execution times for the above three modes (disk-based, memory-optimized and memory-optimized with natively-compiled stored procedure). To this end, before running each process, ‘CHECKPOINT’ and ‘DBCC DROPCLEANBUFFERS’ are executed in order to allow testing each mode of execution with a cold buffer cache without having to restart SQL Server. Therefore, if you are going to test this, please do not run it on a Production Server.
The execution script is provided in Listing 7.1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
SET STATISTICS TIME OFF; SET NOCOUNT ON; --Clean Buffers CHECKPOINT; GO DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; GO --Time-keeping variables DECLARE @StartTimeDiskBased DATETIME2,@EndTimeDiskBased DATETIME2; --Execute Disk-Based Mode SET @StartTimeDiskBased=SYSDATETIME(); UPDATE dbo.d_Employees SET BasicSalary=BasicSalary+(BasicSalary*0.05), LastUpdated=getdate() WHERE PerformanceScore>=9; SET @EndTimeDiskBased=SYSDATETIME(); PRINT 'Disk-Based Execution Time: ' + CAST (datediff(ms,@StartTimeDiskBased,@EndTimeDiskBased) AS VARCHAR(10)) + 'ms' --Clean Buffers CHECKPOINT; GO DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; GO --Time-keeping variables DECLARE @StartTimeMemOpt DATETIME2,@EndTimeMemOpt DATETIME2; --Execute Memory-Optimized Mode SET @StartTimeMemOpt=SYSDATETIME(); UPDATE dbo.m_Employees SET BasicSalary=BasicSalary+(BasicSalary*0.05), LastUpdated=getdate() WHERE PerformanceScore>=9; SET @EndTimeMemOpt=SYSDATETIME(); PRINT 'Mem-Opt Execution Time: ' + CAST (datediff(ms,@StartTimeMemOpt,@EndTimeMemOpt) AS VARCHAR(10)) + 'ms' --Clean Buffers CHECKPOINT; GO DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS; GO --Time-keeping variables DECLARE @StartTimeNativelyCompiledSP DATETIME2,@EndTimeNativelyCompiledSP DATETIME2; --Execute Memory-Optimized with Natively-Compiled Stored Procedure Mode SET @StartTimeNativelyCompiledSP=SYSDATETIME(); EXEC dbo.spUpdateCustomers; SET @EndTimeNativelyCompiledSP=SYSDATETIME(); PRINT 'Natively-Compiled SP Execution Time: ' + CAST (datediff(ms,@StartTimeNativelyCompiledSP,@EndTimeNativelyCompiledSP) AS VARCHAR(10)) + 'ms' |
Listing 7.1: Execution Script for All Modes.
The output of the execution script is presented in the below figure:
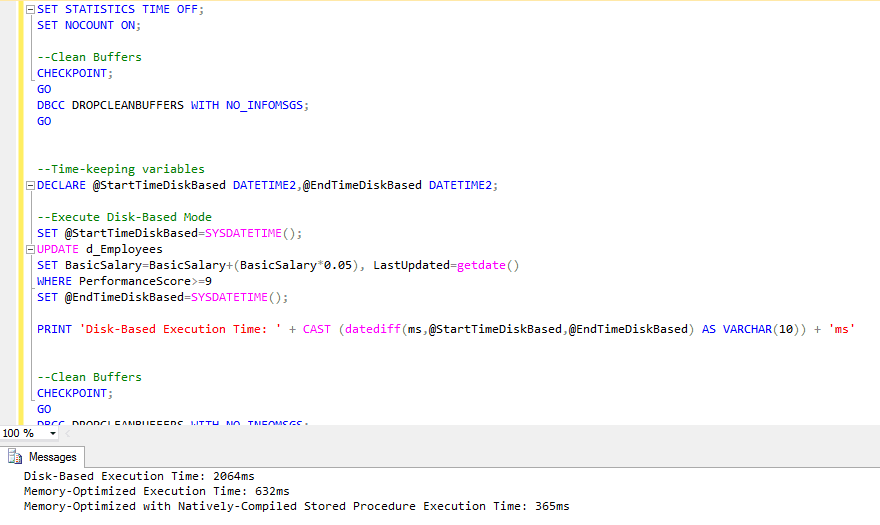
Figure 7.1: SSMS Output for Execution Script (all modes).
Table 7.1 summarizes the execution times and calculates the speedups of the two memory-optimized modes over the disk-based mode which serves as the baseline.
| Modes of Execution / Metrics | Disk-Based | Memory-Optimized | Memory-Optimized with Natively-Compiled SP |
|---|---|---|---|
| Execution Time (ms) | 2064 | 632 | 365 |
| Speedup (x) | 1.00 | 3.27 | 5.65 |
Table 7.1: Execution Times and Speedups.
As shown in the above table, disk-based mode took 2064 ms to complete, memory-optimized 632 ms, and memory-optimized with natively-compiled stored procedure took only 365 ms to complete and that is the winner.
In terms of speedup, memory-optimized mode executed 3.27 times faster over the disk-based mode and memory-optimized with natively-compiled stored procedure mode executed 5.65 times faster.
All the above are illustrated in the graphs provided in figures 7.2 and 7.3.
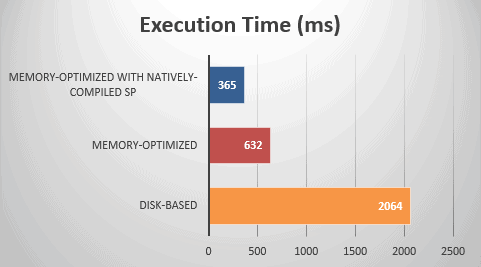
Figure 7.2: Execution Times.
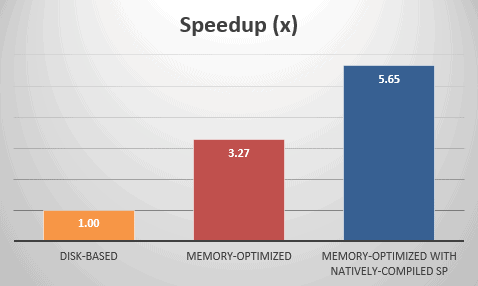
Figure 7.3: Speedups.
Conclusions
In this article we used a step-by-step example to show how it is possible to migrate a disk-based workload to the respective memory-optimized design. We also saw how it is possible to process memory-optimized tables via either direct T-SQL scripts or natively-compiled stored procedures.
Furthermore, we ran the three execution modes of the sample workload (disk-based, memory-optimized, and memory-optimized with natively-compiled stored procedure) and compared the execution times and speedups along with examining the performance improvements.
For our workload, we witnessed a speedup of 3.27x for the memory-optimized mode compared to the disk-based mode, and a speedup of 5.65x for the memory-optimized with natively-compiled stored procedure mode.
The purpose of this article was to use a simple example to show how SQL Server’s In-Memory OLTP technology can be used in order to optimize a specific workload. The execution results verified the performance improvement and are just indicative. For different workload types and volumes you might get much higher speedups. For example, in one of my recent publications (‘In-Memory OLTP Simulator: The Experiment’ (PDF link)) for another sample workload of 5M records, while using memory-optimized tables and natively-compiled stored procedures, I have witnessed a speedup of 26x over disk-based tables.
Lastly, in large Production environments you might encounter complex disk-based designs that may need comprehensive analysis prior to migrating them to In-Memory OLTP. The important thing is that the technology is here, and it is available for all of us to test it and see its real power against our ‘personal’ workloads. SQL Server 2016 includes many improvements for In-Memory OLTP and this technology is something which is constantly evolving. It is recommended to thoroughly test it in order to realize its true potential when it comes to performance optimization of heavy database operations.
References:
- MSDN Library Article: In-Memory OLTP (In-Memory Optimization)
- Microsoft Whitepaper: In-Memory OLTP – Common Workload Patterns and Migration Considerations
- Microsoft Whitepaper: SQL Server In-Memory OLTP Internals Overview
- Microsoft Whitepaper: SQL Server 2016 In-Memory OLTP
See also:
- Introducing SQL Server In-Memory OLTP
- Assessing the SQL Server In-Memory OLTP Performance Benefits
- In-Memory OLTP Simulator: The Experiment (PDF link)
- The Promise – and the Pitfalls – of In-Memory OLTP
- Hekaton in 1000 Words
- Exploring In-memory OLTP Engine (Hekaton) in SQL Server 2014 CTP1
- SQL Server Internals: In-Memory OLTP
- In-Memory Optimization in SQL Server: Will my Workload Execute Faster?
- Redgate’s SQL Data Generator
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments