
The true measure of a soldier’s worth is not the thousands of hours of drills they’ve completed, or their success in simulated war games. They’re remembered (or forgotten) for their instinct and bravery in the heat of battle, for the split second decisions they make which have a profound and enduring impact on the lives of many.
Be it a Purple Heart or a Victoria Cross, the crowning achievement of a soldier’s career is the moment in which the intersection of preparation and opportunity presents them with a platform upon which to prove their worth. They’re trained and paid for this moment, yet few will ever have the opportunity to respond to it.
In the context of Database Administration, the true measure of a DBA’s worth is not the number of training courses they’ve attended, or qualifications they’ve earned, or books they’ve written; it’s their response to an unexpected crisis, the speed and efficiency with which they recover their organization’s data and return them to normal operating conditions.
The best DBAs know they’re paid to be the guardians of their organization’s most crucial asset: data. They value its importance to the extent that they consider and simulate various failure scenarios in order to hone their response to them. Like a soldier on the battle field, optimism plays no part in their plans. They expect failure, and they know exactly what to do when it happens.
A Disaster Recovery (DR) plan is an essential element in any DBA’s toolkit. In this the first of the Seven Habits of the Highly Effective DBA, let’s take an inside look at the breadth and depth of an effective DR plan.
1. What could possibly go wrong?
Your next disaster will be unanticipated. It’s a motto I like to use when devising my DR plans. By necessity, DBAs need to take a pessimistic approach to their DR plan, in order to ensure that they consider as many as possible of the vast number of things that can (and do) go wrong.

When dealing with complex and fluid situations such as disaster recovery planning, half of the battle is in defining the parameters. Military leaders often refer to this as reducing the unknown unknowns, in other words, minimizing the number of things we don’t know we don’t know.
As a DBA, reducing the unknown unknowns means coming up with a list of possible disasters. A good starting point is to categorize disasters into one of the following four categories:
Human Errors; This category covers all of the unanticipated human failures that happen from time to time. I once worked with a DBA who used the diagramming tool in Enterprise Manager to create a basic model of a production database. He dropped a table from the database thinking his action would only remove it from the diagram. Other classics are DELETE commands run against a table without a WHERE clause, and shutting down a server instead of logging off.
Hardware Faults; As hardware prices fall, it is becoming more common for organizations to build redundancy into their server designs. RAID storage, dual power supplies, ECC RAM and clustered servers all combine to reduce the chances of a hardware fault bringing down a system. However rare such events may be today, we cannot ignore the possibility of their occurrence, and they need to be considered when developing our DR plans.
Environmental Disasters; Most people’s initial definition of disaster includes events in this category. While bushfires, flooding and landslides happen, they’re very rare compared to the other categories presented here. That said, the DBA must at least imagine the wholesale destruction of the database infrastructure that could result, and plan an appropriate response.
Security Breach; An often overlooked area in terms of disaster recovery, these types of disasters relate to situations in which unauthorized access to data constitutes a disaster. Be it company secrets, credit card numbers, payroll data or classified documents, unintended access to this information requires a swift and coordinated response to limit the damage.
Once we have a list of things we know could go wrong, we can go about designing a response to each of them. But before doing so, we need to consider the Service Level Agreements under which we operate.
2. What about Service Level Agreements?
Service Level Agreements (SLAs) define the service level that we agree to provide, typically in terms of factors such as the maximum transaction response time, the maximum numbers of hours of downtime per year, and the maximum amount of data loss that’s considered acceptable.
An important prerequisite to DR planning is to define and agree on a SLA with the business (the people that pay our salary). SLAs set the framework within which we can design an appropriate recovery response to each disaster we consider. For example, an SLA that stipulates zero downtime and data loss obviously requires a far more extensive and expensive infrastructure than that which would be required by a more-typical SLA, which allowed a set amount of downtime and data loss.
Designing database infrastructure and a DR plan in the absence of a SLA is a common mistake and frequently leads to overly expensive solutions and service level disappointment from the business, during an actual disaster. A DBA should never assume what service levels the business expects and the business should never expect that zero data loss and zero downtime comes cheap. Calibrating the infrastructure investment to service level expectations is an important task, and one that requires both parties to engage in clear communication on the various options, and their associated service levels and costs. A great catalyst for this discussion is the SLA
SLA Option Papers
When negotiating service level agreements with the business, it’s very easy for the conversation to turn into a circular argument around costs, options and requirements. For example, asking a business how much downtime and data loss is acceptable will typically result in the answers “none” and “none”, with the usual DBA response to this request being “how much do you want to spend”. It’s difficult for a business to answer this question without understanding what the options are, how much each of them will cost, and their relative strengths and weaknesses. When presented clearly, such as shown in the example in figure 1 for backup/restore, option papers enable the business to clearly see what they will get for their money, and helps to really sharpen the debate on what the real priorities are.

Figure 1; A simplified option paper comparing the costs, benefits and limitations of 3 backup/restore options.

A classic SLA metric is uptime target percentage, and is usually expressed using the number of nines in the target. For example, an uptime of 99 % or “2 nines” represents about 3.5 days of downtime per year. In contrast, an uptime of 99.999 % or “5 nines” represents about 5 minutes per year! A “5 nines” solution is exponentially more expensive than a “2 nines” solution, with a single downtime incident typically causing a target failure in a “5 nines” environment. A business needs to weigh up the benefits of a large infrastructure investment, required for a 5 nines solution, compared with the benefits of spending that money elsewhere, for example, on staff training. If a few days of downtime per year (spread over the whole year) is acceptable, then it does not make sense to throw money at expensive infrastructure when the investment in other areas will yield a better overall outcome.
So, once we’ve recognized that a) things go wrong and b) we need to talk to the business on aligning infrastructure investment with their service level expectations, the next step is to address the nuts and bolts of SQL Server High Availability and Disaster Recovery.
3. SQL Server High Availability Disaster Recovery
The terms High Availability and Disaster Recovery are often used interchangeably to talk about the same thing. I think there’s an important yet subtle difference:
- Disaster Recovery addresses what needs to be done when unexpected downtime has occurred.
- High Availability addresses what we need to do, as DBAs, to avoid down time.
The latter is a very broad statement, and deliberately so. While there are “big ticket” items such as failover clustering and database mirroring, there are a whole lot of smaller yet equally important things that also contribute and detract from the goal of a highly-available database. For example:
- Not installing a service pack may lead to a security vulnerability
- Inadequate physical security may enable someone to remove/unplug the server
- A lack of training may lead to simple, yet costly human errors
All of these mistakes, regardless of the presence of clustering and/or mirroring, will impact on the uptime target. High availability is therefore as much a state of mind as it is a SQL Server feature or option.
The scope of this article does not allow for a detailed discussion on each of the items that impact on High Availability. What I’d like to do instead is to compare and contrast the most commonly-used SQL Server High Availability techniques, beginning with Failover Clustering.
3.1 Failover Clustering
There are numerous components within a server that can fail, from power supplies to motherboards, CPU and memory. Some of these components can be designed redundantly by use, for example, of dual power supplies and ECC RAM, to prevent a failure from causing the server as a whole to fail. However, there are some faults that will cause a server wide failure, and for those situations, Failover Clustering provides many benefits:
- All databases on the failed server move to an alternate server in a single action
- SQL Server agent jobs, system configuration, maintenance plans logs also automatically move to an alternate server
- Application connection strings do not need to be aware of the alternate failover server(s); the clustering logic automatically handles the connection redirection
Failover clustering is flexible in terms of the number of possible configurations that are supported i.e. the number of passive servers in the cluster compared to the number of active servers. If clustering is configured incorrectly, a single server may end up taking the load of a number of active and failed servers, and so performance may be poor after failover.
The other major consideration for clustering is that, unlike some other High Availability solutions, the disk containing the database files is shared among the cluster nodes, and therefore acts as a single point of failure (notwithstanding RAID support), a shortcoming addressed by both Database Mirroring and Log Shipping.
3.2 Database Mirroring
Unlike clustering, servers in a database mirroring solution can be, and often are, physically separate, both geographically and in terms of their hardware configuration. There is no requirement for the servers to share a storage system, meaning that mirroring pairs are often setup across large geographical distances in order to provide protection from catastrophic events (think 9/11).
Database mirroring pairs can be maintained in either a synchronous manner, in which case transactions will not commit on the principal database until written to the mirror’s transaction log, or asynchronously, for faster mirroring performance (but a higher risk of data loss).
Depending on the connection technique, applications can be configured to automatically reconnect to the database mirror on failure of the principal, although this is more complex than failover clustering, and requires usage of the SQL Server Native Client (SNAC).
Each database is individually mirrored, meaning that a server containing lots of databases requires a much larger administrative effort when compared to failover clustering. Further, the SQL Agent jobs, logs and server configuration settings are not automatically moved with the database.
Introduced in SQL Server 2005, one of the big advantages of Database Mirroring is the real time (or near real time) delivery of transactions from the principal database to the mirror database. This was a big leap forward when compared to the closest available technology in SQL Server 2000, Log Shipping, leading some to question the need for this older technology moving forward. As we’ll soon see, Log Shipping remains an important tool in the box.
Consider a situation in which someone accidentally deletes every row in a table. In a mirroring solution, that change is automatically (or very soon after) made to the mirrored database and therefore provides no easy rollback option. In addition to a number of other advantages, Transaction log shipping addresses this situation nicely.
3.3 Log Shipping
Transaction log shipping works by periodically restoring the transaction log backups from a primary database to one or more secondary databases initially created from a full backup of the primary. The secondary database(s) remains in the NORECOVERY/STANDBY state, enabling it to restore transaction logs from the primary. This process, in effect, turns the secondary database into a mirror of the primary, with a configurable transaction latency (15 minutes, by default).
Transaction log shipping, whilst sometimes considered an older and slower version of mirroring, provides a number of unique advantages. Firstly, by default, log shipping ships transaction logs from the primary database to the secondary (mirror) database(s) every 15 minutes. In our earlier example of the accidental deletion of all the rows in a table, those 15 minutes affords us an opportunity to intervene in the automatic transaction log restore to the secondary database(s), therefore avoiding the replication of the unintended deletion. For example, we could;
- Disable the SQL Agent jobs created by log shipping that automatically backup, copy & restore transaction logs from the primary to secondary databases,
- Disconnect client connections from the Primary database,
- Take a new transaction log backup on the primary database,
- Manually copy and restore transaction logs to the secondary database using the STOPAT command to restore up to the point of the unintended delete command,
- Restore the secondary database WITH RECOVERY making it usable as a replacement for the primary database,
- Reconnect clients to the new database
Log shipping also provides a number of other advantages when compared to mirroring; there can be multiple destination/copy databases from a single source database, and the destination database can be created in a manner that enables it to be used for read-only reporting in between log restore operations, an option not available in mirroring (unless using database snapshots).
On the downside, log shipping does not offer automatic failover and client redirection, and transaction latency is typically much slower.
So, which is the best High Availability option?
3.4 Options Compared
What should be obvious by now is that each of the three options (Clustering, Mirroring and Log Shipping) provides unique strengths and weaknesses. For this reason, many sites choose to combine two or more of these technologies in order to maximize the strength of the overall solution. A common configuration is to use clustering within a primary data centre for local failure protection, and then mirror (or log ship) critical databases off site for added protection.
Figure 2 (reproduced with permission from SQL Server 2008 Administration in Action, Manning Publications) compares and contrasts the attributes of these three options.
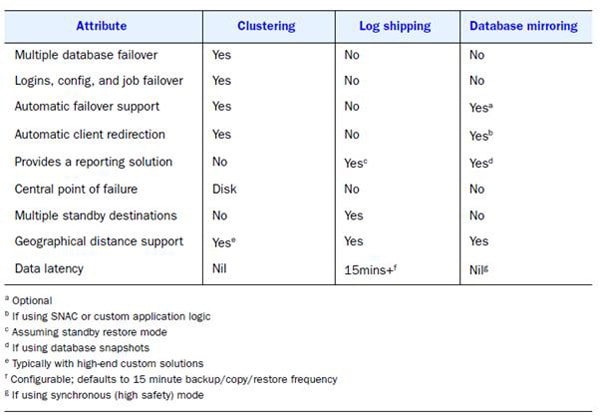
Figure 2; High Availability options compared. Reproduced with permission, SQL Server 2008 Administration in Action, Manning Publications, 2009
3.5 Other Components of a HA Solution
There is much more to an effective High Availability solution than just SQL Server features or options. Further, there are many other ways in which DBAs can improve availability, some of which include:
- Backups; Don’t underestimate the importance of a sound backup strategy. We’ll be covering this more in the upcoming articles in this series
- Replication; Considered more of a data distribution technology than a High Availability solution; it is frequently used for the latter purpose nonetheless
- SQL Azure; The cloud is here! SQL Azure Data Sync enables an on-premises database to be synced up (and down) to/from the cloud, providing an alternate failover point in the event of disaster
No strategy is foolproof, and the best-laid plan can sometimes look spectacularly inadequate in retrospect. In that context, we need to be constantly validating our plans, a task best achieved through the DBA Fire Drill.
4. Fire Drills
Earlier in the article, we discussed the important difference between High Availability and Disaster Recovery. We noted that High Availability is concerned with keeping systems up and avoiding downtime, and Disaster Recovery is about what to do when an unexpected event occurs which leads to downtime.
One of the crucial (and often overlooked) aspects of any Disaster Recovery plan is the importance of simulating various disasters in order to determine the effectiveness of the High Availability systems put in place. Such exercises, or Fire Drills as I like to call them, provide a number of benefits; firstly, the ability to measure/adjust the High Availability system’s effectiveness in preventing downtime, and secondly, as a means of fine tuning the Disaster Recovery plan should downtime result.
Depending on the failure, the Disaster Recovery plan will of course vary, but in all cases, there are a number of common inclusions:
- Clearly documented restore scenarios including the location of restore/verification scripts
- Decision escalation points. Some decisions are irreversible, and following the correct chain-of-command during an actual disaster is crucial in avoiding any rash decisions that may lead to permanent data loss
- Contact phone numbers (including after hours numbers) for application support staff, senior DBAs, and business representatives
- Follow up post mortem that examines what went wrong, the success/failure of the Disaster Recovery plan & High Availability design, and what steps can be taken in the future to avoid the same outage scenario
One of the common excuses given for not simulating disasters is the cost and time involved. While these are legitimate concerns, failure to run these simulations can lead to confusion, long outages and potentially irreversible mistakes under the pressure of real disaster.
One of the more successful approaches to disaster simulation is to conduct random fire drills during which DBAs are tasked with recovering from a random disaster, simulated in a test environment, at an unannounced time.
This technique is highly effective in training the DBA how to respond quickly, with the appropriate actions, during a real disaster. It is invaluable for newly-hired DBAs, enabling them to very quickly come up to speed with all the specific processes required for disaster recovery, but also livens up the day, and adds a competitive spark to the DBA team as a whole. DBAs often compete to see who can recover a system the fastest with the least amount of data loss!
Summary
In this article, we covered arguably the most important aspect of being a DBA; being prepared for an unexpected disaster. Despite its importance, a lot of DBAs ignore this element of their job, and those that do can only hope that luck runs their way.
In the next article, we’ll concentrate on a fundamental DBA task; storage design and validation.
Figure 2 in this article is taken from SQL Server 2008 Administration in Action by Rod Colledge and reproduced with permission from the publisher, Manning Publications. Save 35% on the print or eBook edition of SQL Server 2008 Administration in Action. Enter ‘redgate35’ in the Promotional Code box when you check out at manning.com
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments