
I don’t think I’ve ever had a great impression of Azure SQL Database as a place for production applications. In its early days, it was missing several important features (like data compression). While that hole has been plugged, there are still other limitations and differences you should be aware of, like T-SQL differences, lack of SQL Server Agent, and some observability gaps. There are several other differences, and while this platform comparison puts Azure SQL Database and Azure SQL Managed Instance side-by-side, the list can help you understand what’s different between PaaS offerings and the on-premises product. Many of the limitations make sense, but you still need to understand them if you’re moving an existing application (even with migration tools to help).
Whether or not it’s a cloud offering that makes sense for you, Azure SQL Database is often the staging ground for new features that will eventually make it to all flavors of SQL Server. For example, it was where I could first test GENERATE_SERIES, GREATEST and LEAST, and changes to STRING_SPLIT. Following that trend, earlier this year, Microsoft announced this magical-sounding feature, “optimized locking.”
What is it?
In a sentence: Instead of locking individual rows and pages for the life of the transaction, a single lock is held at the transaction level, and row and lock pages are taken and released as needed.
This is made possible by previous investments in Accelerated Database Recovery and its persistent version store. A modification can evaluate the predicate against the latest committed version, bypassing the need for a lock until it is ready to update (this is called lock after qualification, or LAQ). There’s a lot more to it than that, and I’m not going to dive deep today, but the result is simple: long-running transactions will lead to fewer lock escalations and will do a lot less standing in the way of the rest of your workload. Locks held for shorter periods of time will naturally help reduce blocking, update conflicts, and deadlocks. And with fewer locks being held at any given time, this will help improve concurrency and reduce overall lock memory.
Prerequisites
The prerequisites are pretty easy:
- You need to be in Azure SQL Database.
- Accelerated Database Recovery needs to be enabled; this is on by default.
- Read Committed Snapshot Isolation (RCSI) is not required, but it’s recommended, and also on by default. While you can turn it off, you shouldn’t.
Other than that, you’ll just get this benefit by default. To verify that your Azure SQL Database supports optimized locking, you should see 1 in all three columns of the output for this query:
|
1 2 3 4 5 6 7 8 |
SELECT OptimizedLocking = DATABASEPROPERTYEX (name, 'IsOptimizedLockingOn'), RCSI = is_read_committed_snapshot_on, ADR = is_accelerated_database_recovery_on FROM sys.databases WHERE name = DB_NAME(); |
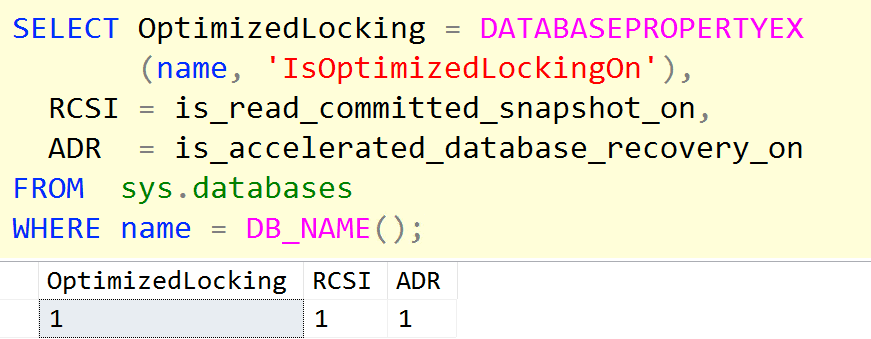
Configuration validation
As others have noted, to turn the behavior off, you need to submit a support request. But why would you want to do that? Well…
A behavior change
Before demonstrating the benefits, I wanted to highlight a potentially unexpected but important change in behavior that you’ll want to take into account. From the documentation:
Even without LAQ, applications should not assume that SQL Server (under versioning isolation levels) will guarantee strict ordering, without using locking hints. Our general recommendation for customers on concurrent systems under RCSI with workloads that rely on strict execution order of transactions (as shown in the previous exercise), is to use stricter isolation levels.
Put another way, locks on individual rows that would normally be held until the end of the transaction might now be released a lot earlier. Which means other transactions that started later may succeed in changing the row, without being blocked, but the first transaction that eventually commits will “win.” Until now, it’s always been the case that last writer wins, and now it’s possible for an earlier writer to have priority.
It’s also important to note that this feature will work with read committed but not with repeatable read or serializable:
When using stricter isolation levels like repeatable read or serializable, the Database Engine is forced to hold row and page locks until the end of the transaction.
Translation: if you want to maintain the older behavior for any reason (including application compatibility), you don’t necessarily need to submit a support ticket to disable optimized locking; you can just run all of your transactions under serializable.
That was a joke.
An example
I created this database in regular old on-prem SQL Server 2022, making it as close as possible to Azure SQL Database defaults:
|
1 2 3 4 5 6 7 8 9 |
CREATE DATABASE TXTesting; GO ALTER DATABASE TXTesting SET RECOVERY FULL; ALTER DATABASE TXTesting SET ACCELERATED_DATABASE_RECOVERY = ON; ALTER DATABASE TXTesting SET ALLOW_SNAPSHOT_ISOLATION ON; ALTER DATABASE TXTesting SET READ_COMMITTED_SNAPSHOT ON; |
And created a table with a million relatively wide rows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE dbo.Widgets ( WidgetID int NOT NULL, Status tinyint NOT NULL DEFAULT 0, Filler char(999) NOT NULL DEFAULT '', CONSTRAINT PK_Widgets PRIMARY KEY(WidgetID) ); INSERT dbo.Widgets(WidgetID) SELECT value FROM GENERATE_SERIES(1, 1000000); |
New databases may still get created in 150 compatibility level; if so, you will need to bump it:
|
1 2 3 |
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 160; |
If your on-premises database is on a version earlier than SQL Server 2022, the function won’t be an option anyway, and you’ll need to use another way to generate a million rows. I demonstrate a few alternatives in the aforementioned post on GENERATE_SERIES.
Then I set up two sessions to update 500 rows at a time in a loop; maybe they will collide on some sets of rows, maybe they won’t. But they probably will. Making note of @@SPID in each case, I set them both to start at the same time:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
WAITFOR TIME '18:37'; BEGIN TRANSACTION; DECLARE @i int = 1, @batch_size int = 500; WHILE @i <= 1000 BEGIN WITH x AS ( SELECT * FROM dbo.Widgets WHERE WidgetID > (@batch_size*(@i-1)) AND WidgetID <= (@batch_size*(@i)) ) UPDATE x SET Status = @@SPID; SET @i += 1; END COMMIT TRANSACTION; |
While those were running, I polled for locking and waits experienced by either session. First by creating a few temp tables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
CREATE TABLE #lock_snapshot ( event_time datetime2, spid smallint, resource_type nvarchar(60), request_mode nvarchar(60), resource_description nvarchar(max) ); CREATE TABLE #wait_snapshot ( event_time datetime2, spid smallint, wait_type nvarchar(60), wait_time_ms bigint, [status] nvarchar(30), blocker smallint, wait_resource nvarchar(256) ); SELECT cntr_value FROM sys.dm_os_performance_counters WHERE counter_name = N'Lock Memory (KB)'; |
Then running this loop referencing a #temp table with the SPIDs, which made it easier to run multiple tests starting from zero waits:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE TABLE #spids(spid smallint); INSERT #spids VALUES(76),(79); GO DECLARE @now datetime2 = sysutcdatetime(); INSERT #lock_snapshot SELECT @now, request_session_id, resource_type, request_mode, resource_description FROM sys.dm_tran_locks WHERE resource_database_id = DB_ID(N'TXTesting') AND request_session_id IN (SELECT spid FROM #spids) AND resource_type <> N'DATABASE'; INSERT #wait_snapshot SELECT @now, ws.[session_id], ws.wait_type, ws.wait_time_ms, r.[status], r.blocking_session_id, r.wait_resource FROM sys.dm_exec_session_wait_stats AS ws LEFT OUTER JOIN sys.dm_exec_requests AS r ON ws.[session_id] = r.[session_id] WHERE ws.[session_id] IN (SELECT spid FROM #spids) AND ws.wait_time_ms >= 1000 AND ws.wait_type <> N'WAITFOR'; WAITFOR DELAY '00:00:00.25'; GO 500 |
I didn’t bother timing the duration of the entire process, since so many other performance-influencing factors are different between an Azure SQL Database and an on-premises deployment. All four scripts took less than a minute, but how much less isn’t relevant. There is other data I collected that may be worth looking into if you follow my lead and try this out for yourself. Much more interesting (and perhaps predictable, given the intent of the feature) were the number of locks, the amount of lock memory, and the wait types. I used the following queries to summarize what had been captured:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT spid, rt = CASE resource_type /* XACT = Tid, GRAN = more granular (key/page) */ WHEN 'XACT' THEN 'XACT' ELSE 'GRAN' END, LockCount = COUNT(*) FROM #lock_snapshot GROUP BY spid, CASE resource_type WHEN 'XACT' THEN 'XACT' ELSE 'GRAN' END; SELECT spid, wait_type, WaitTime = MAX(wait_time_ms) FROM #wait_snapshot GROUP BY spid, wait_type; SELECT cntr_value FROM sys.dm_os_performance_counters WHERE counter_name = N'Lock Memory (KB)'; |
The results
In my local instance, the results were:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
spid rt LockCount -------- -------- --------- 76 GRAN 142,252 79 GRAN 186,894 spid wait_type WaitTime -------- --------- -------- 79 LCK_M_U 2,575 cntr_value ----------------------------- 110,346 higher KB than before |
In Azure SQL Database, the results were:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
spid rt. LockCount -------- -------- --------- 85 GRAN 63 86 GRAN 94 85 XACT 21 86 XACT 45 spid wait_type WaitTime -------- ------------------- -------- 86 LCK_M_S_XACT_MODIFY 4,894 85 LOG_RATE_GOVERNOR 5,610 86 LOG_RATE_GOVERNOR 4,642 cntr_value ---------- no change |
Let’s put these together and make it pretty (ignoring the log throttling):

Rather impressive results
In Azure, there are obviously some different performance constraints in play, particularly that writes to the transaction log are throttled pretty badly at lower tiers, never mind vastly different underlying hardware. So it’s not a fair apples-to-apples comparison, and there’s no way to test like-for-like: locally, you’d need a version that supports the feature, which doesn’t exist; in Azure, you’d need to downgrade to earlier behavior through support.
You could potentially spend more time than I did trying to find the “batch size sweet spot” to escape the clutches of LOG_RATE_GOVERNOR, but my limited testing has already told me enough without that equivalence.
You like it so far?
This change is, in a word, fantastic, and I am looking forward to it creeping its way into the full product. Though I hope it is not on by default, or tied solely to compatibility level, as I think there are still plenty of questions to answer here about the underlying behavior and how applications might need to adjust. It should also be a more discoverable option than one buried in DATABASEPROPERTYEX().
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments