
Earlier this year, we migrated the entire Stack Overflow for Teams platform to Azure. This was a lengthy endeavour and Wouter de Kort, one of our core engineers, wrote about multiple technical aspects of the project in these posts:
- Journey to the cloud part I: Migrating Stack Overflow Teams to Azure
- Journey to the cloud part II: Migrating Stack Overflow for Teams to Azure
In this post, I’ll share a little more detail about the SQL Server portions of the migration, what we’ve done since, and how we’ve approached modernizing our environment while migrating to Azure. I’ll talk about a few key choices we made and trade-offs between simplicity and risk in case they are helpful as you face similar decisions.
Background
In our New York (actually, New Jersey) and Colorado data centers, the databases supporting Teams ran on four physical servers, two in each data center. The infra consisted of a Windows Server Failover Cluster (we’ll call it NYCHCL01), and four servers (NY-CHSQL01/02 and CO-CHSQL01/02), hosting 103 databases in a single availability group. Primary was always on one of the NY nodes, with a sync secondary on the other NY node and two async secondaries in Colorado:
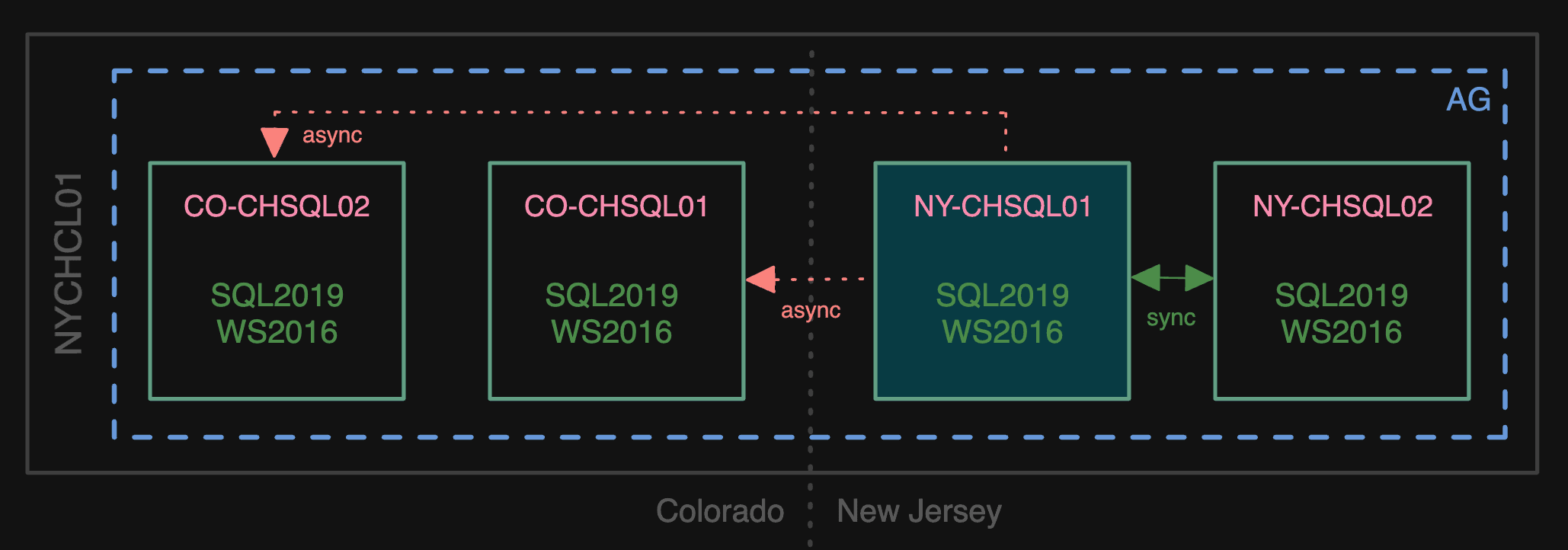
What Teams looked like in the data center
But we wanted out of the data center
In order to migrate to the cloud, we built a mirrored environment in Azure: two Azure VMs in East US and two Azure VMs in West US. These servers joined the same cluster in the data center, and ran the same version of the operating system (Windows Server 2016) and SQL Server (2019).
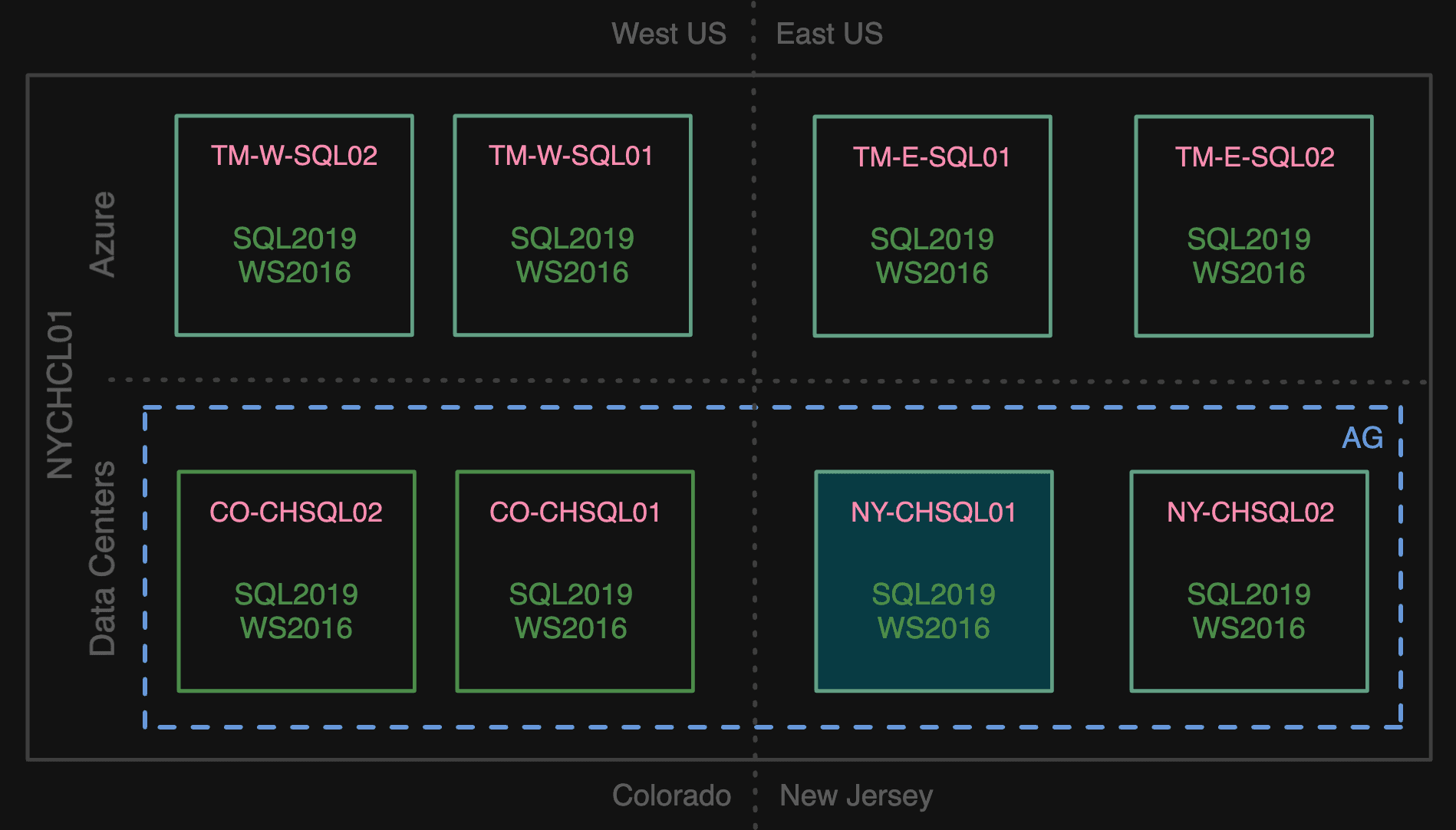
A new mirrored environment in Azure
We went with Azure VMs running “on-prem” SQL Server, over PaaS offerings like Azure SQL Managed Instance (MI), for a few reasons:
- A rule I tend to strictly follow is to change as few things as possible. In this case, we felt that sticking with the exact same engine and version would make for a more stable experience.
- When possible, we want to make sure a migration is reversible. Since the source systems were still running SQL Server 2019, and we didn’t want to upgrade them before the migration, we couldn’t take advantage of newer features that would allow failing over and back between MI and SQL Server 2022.
- We already exceeded MI’s hard limit of 100 databases. Fitting into a managed instance would mean breaking it up so not all databases were on the same instance – not insurmountable, but not something we’ve ever done with this system, and we didn’t want to disrupt the timeline trying it out.
- When analyzing and forecasting costs, we just couldn’t find a sweet spot in the price/performance ratio that made sense – for the same power, a VM running SQL Server is currently the most economical choice for us. Even if it means we still have to manage some of the maintenance (e.g., OS patching and cumulative updates). We’ll continue to watch MI pricing over time and see if it comes down into an orbit that makes it attractive.
Once built and configured, we joined these new nodes to the AG, making them all async secondaries, and removed the Colorado nodes from the AG:
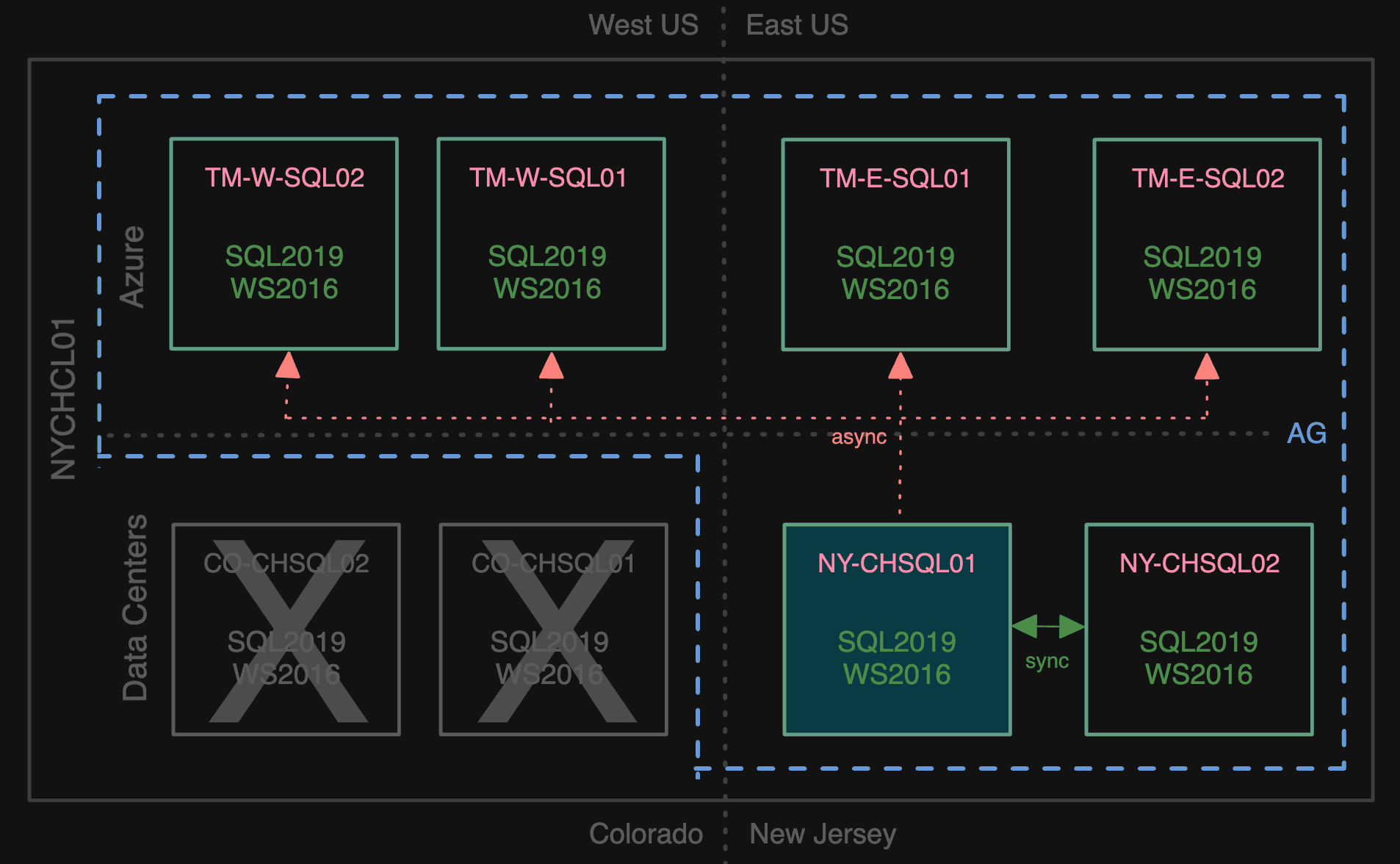
Getting Colorado out of the picture
We didn’t want to stay in this mode for long since that is a lot of secondaries to maintain. We quickly made TM-E-SQL01 synchronous and the other NY secondary async.
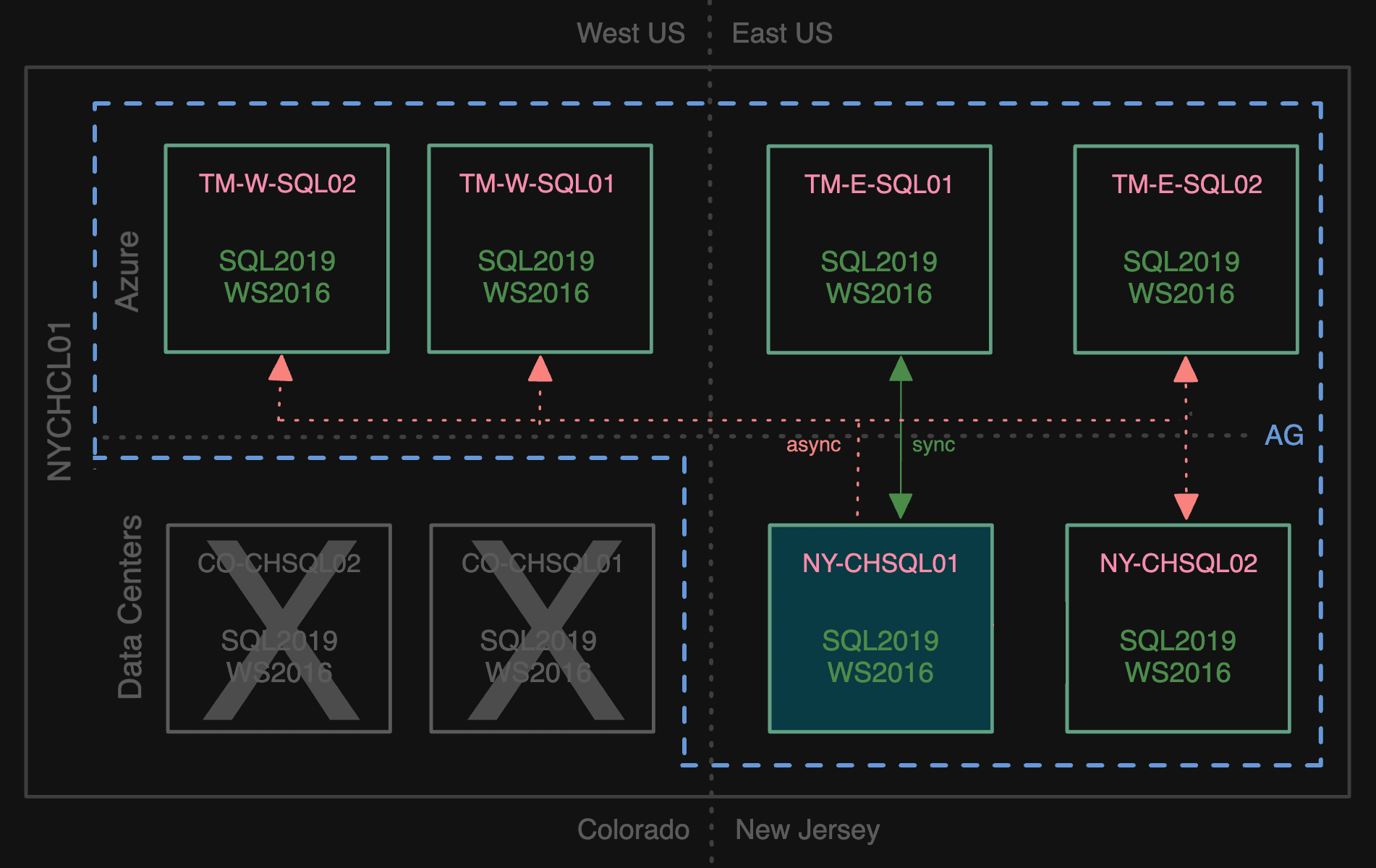
Briefly using sync mode to Azure
Making TM-E-SQL01 synchronous and the other NY secondary async let us fail over to Azure (during a maintenance window), making TM-E-SQL01 primary and TM-E-SQL02 a sync secondary. This was not a point of no return, since we could fail back to the data center if we needed to, but we gradually cut remaining ties with the data center by removing the NY secondaries:
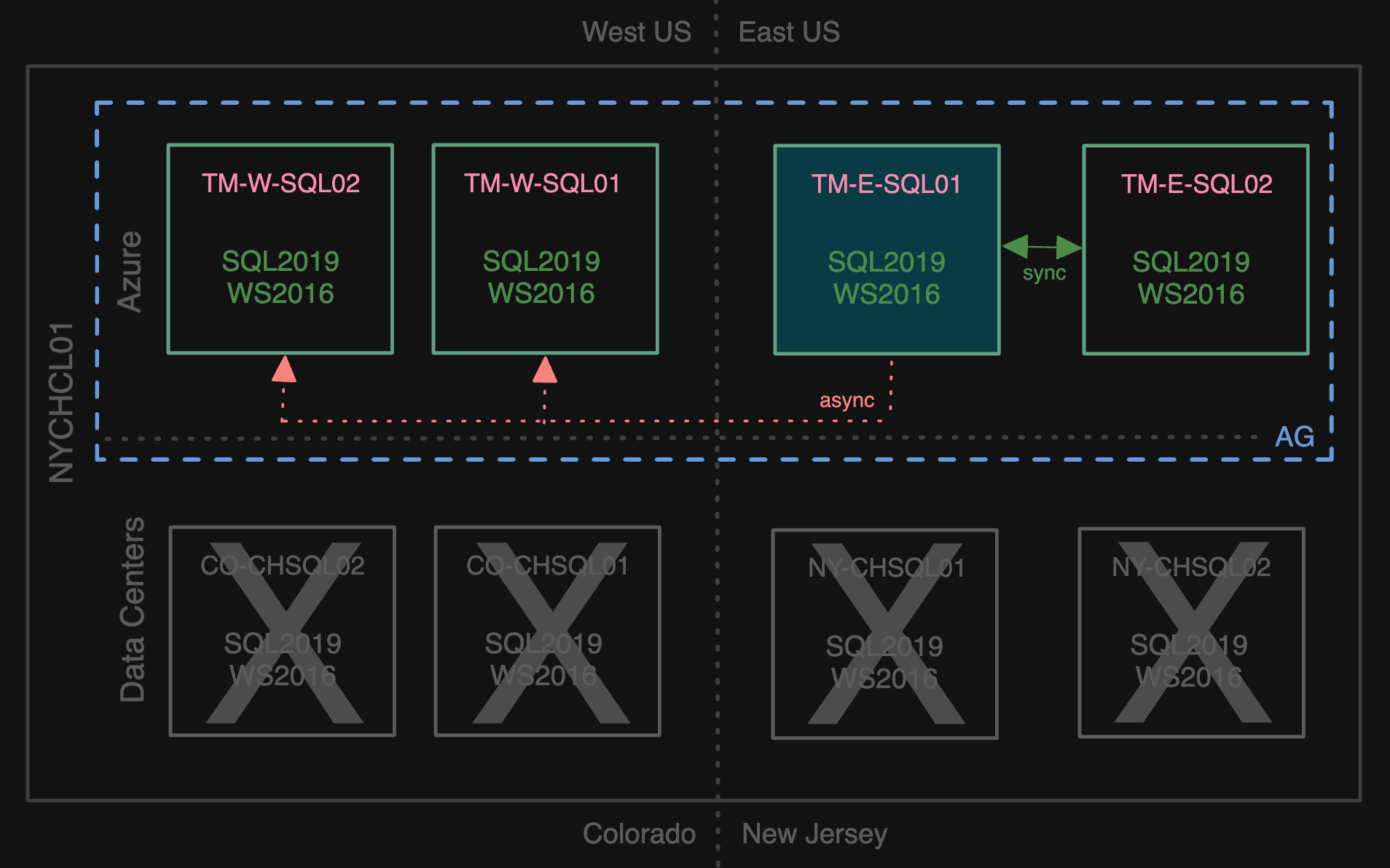
Saying goodbye to the data center
Now we had the AG fully in Azure, with zero customer impact other than the announced maintenance window.
Some notes
- I’ve intentionally left a lot of the complexity out, as this was more than a simple AG failover. The operation required coordinating moving the application to Azure at the same time, since we didn’t want to have the app running in the data center talking to databases in Azure or vice-versa.
- The failover itself should have been a tiny blip, measured in seconds, which wouldn’t even require a maintenance window. I’m glad we did plan for a window because the migration wasn’t as smooth as it should have been (the failover due to network constraints, and other pieces due to various application-side issues). Wouter talked about some of that in the second part of his blog series.
We thought we were done
During and after that migration, we came across some sporadic and not-so-well-documented issues with cross-region network performance. We’re talking about transfer speeds that were 60X slower at times – observed while backing up, restoring, or copying files between east and west nodes. While we could mitigate some of this by using Azure storage exclusively, this would cause double effort for some operations. In addition, there was valid concern that this unreliable network could cause broader latency for log transport and could even jeopardize successful failovers between regions. We also theorize that it contributed to some of the struggles we faced on migration day.
Several colleagues ran boatloads of tests using iPerf and other tools. We discovered that newer generation VM images running Windows Server 2019, while not completely immune to the issue, were much less likely to experience drastic fluctuations in transfer performance than our older gen images running Windows Server 2016. We also believed (but couldn’t explicitly prove) that the old cluster’s ties to the data center might contribute to the issue, since we could reproduce sluggishness or failures on those servers when performing operations that involve domain controllers (e.g., creating server-level logins or creating computer objects) – issues that never occur on identically configured servers that aren’t part of that cluster.
The new plan
We made a plan to ditch the old cluster and get off of Windows Server 2016 completely. This puts us in a much better position to have reliable cross-region failovers, helps us clean up some tech debt, and paves the way for upgrading to SQL Server 2022. Since we can’t just take new maintenance windows on the fly, we would have to do this with minimal downtime. For me, this means no data movement (e.g. manual backup / restore of all 103 databases). We also wanted to do this in a simple way, which for me means no distributed availability groups. So how would we move an AG to a new cluster with minimal downtime, no data movement, and without using a distributed AG?
We started by evicting the NY and CO nodes from the old cluster. Then we created a new cluster in Azure (let’s call it AZTMCL01), and four new VMs all running Windows Server 2019 (we’ll call them TM-E-SQL03/04 and TM-W-SQL03/04). The two 03 nodes ran SQL Server 2019, and were added as nodes to the existing cluster. The two 04 nodes ran SQL Server 2022, and were added as nodes to the new cluster.
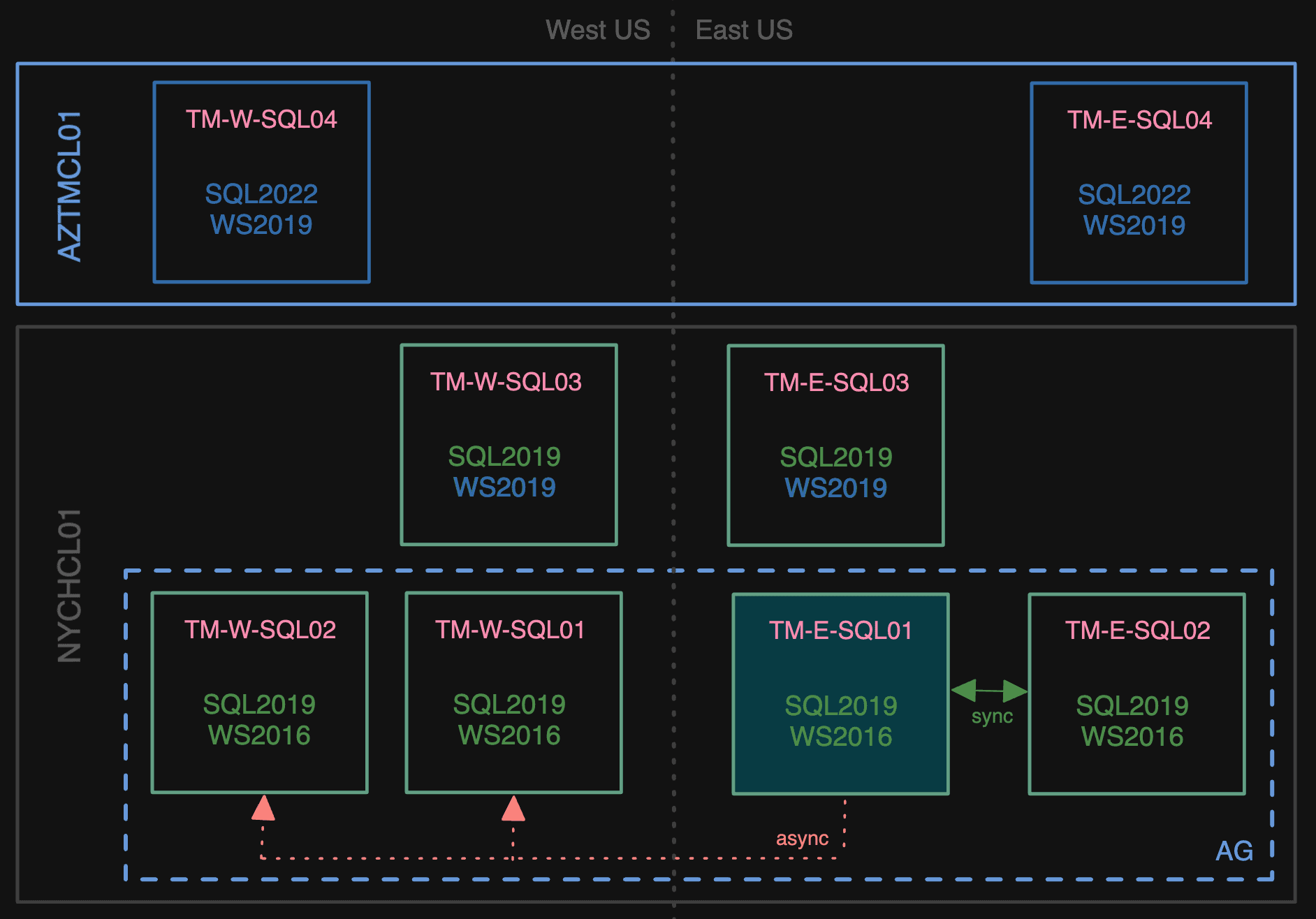
A new cluster has entered the chat
Next, we removed the west 01/02 nodes from the AG, and joined the new 03 nodes as async secondaries.
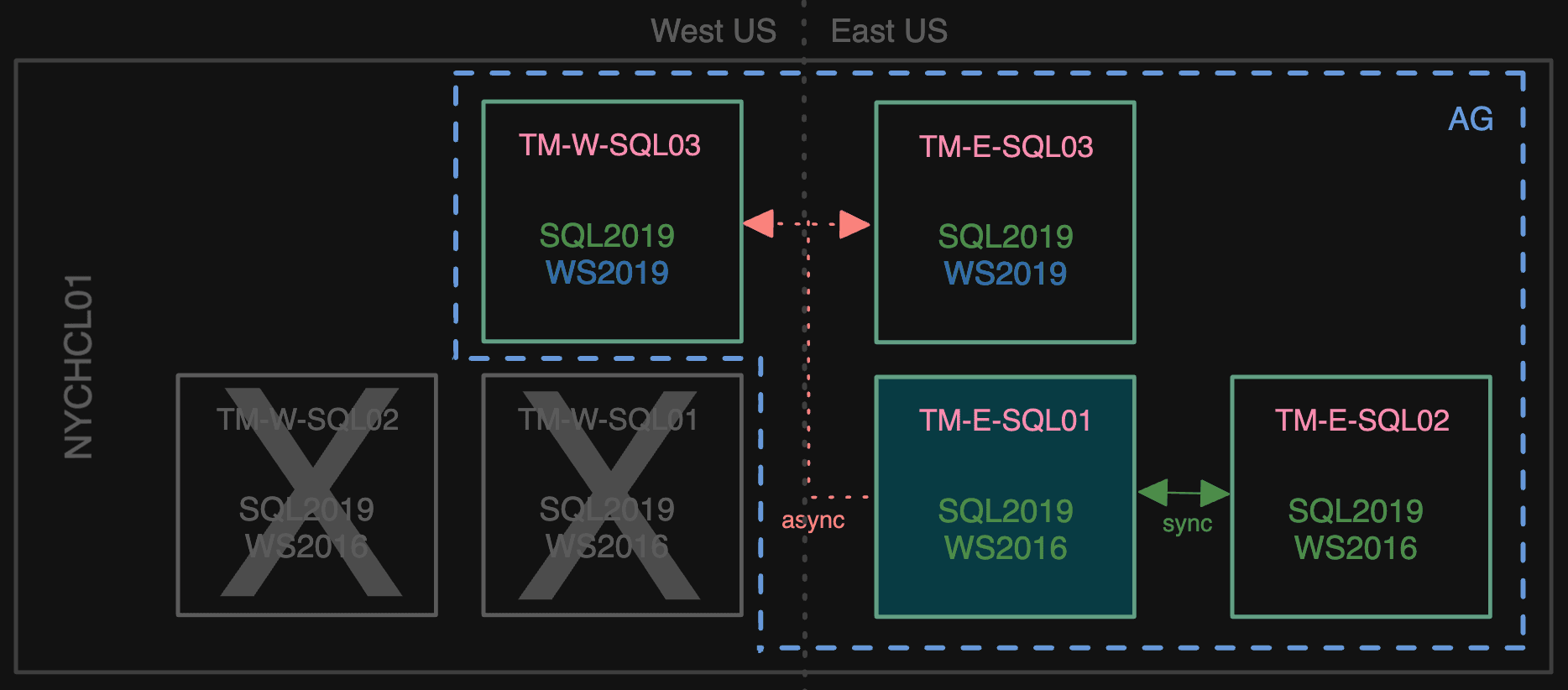
Losing the west 01/02 secondaries
Then we made TM-E-SQL03 a sync secondary, and kicked TM-E-SQL02 out of the AG.
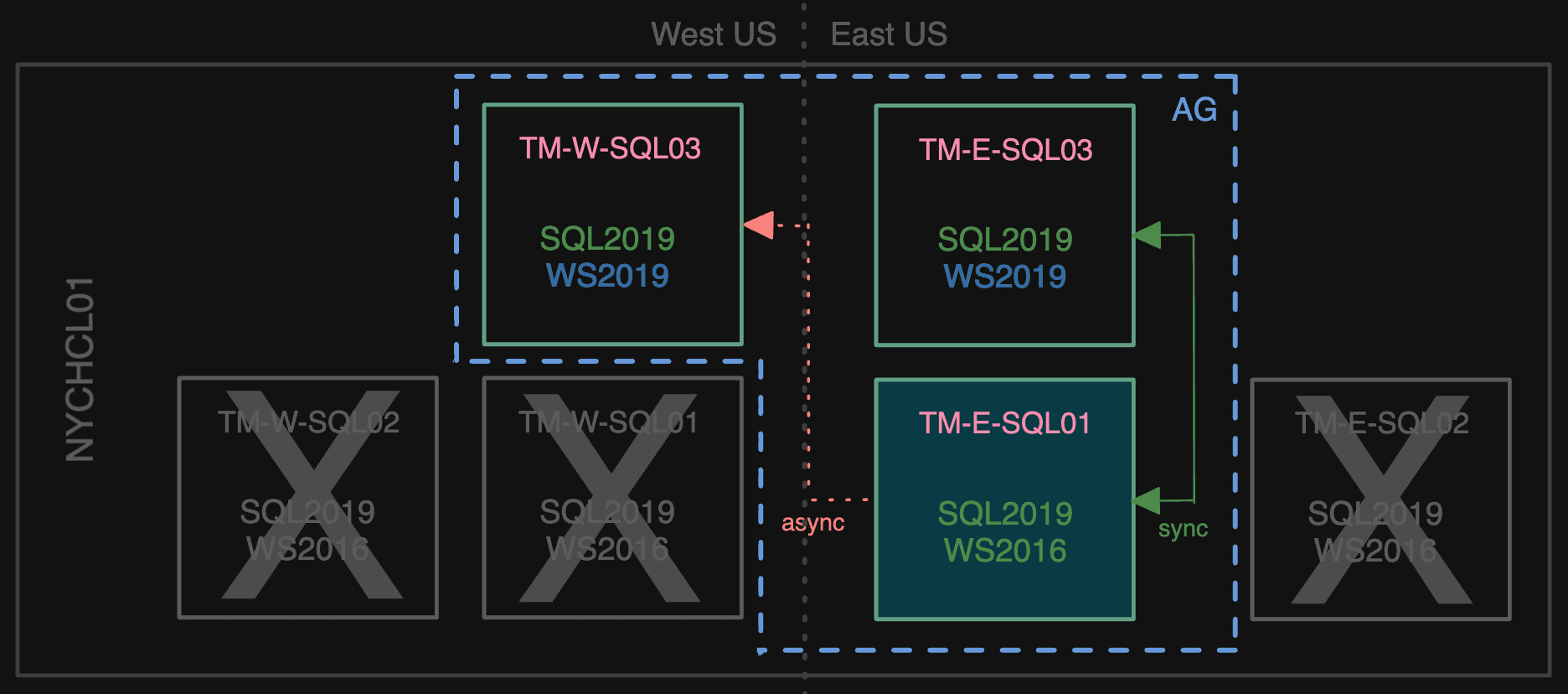
Losing one more Windows Server 2016 node
After that, we failed over to TM-E-SQL03, made TM-W-SQL03 a sync secondary temporarily, and removed TM-E-SQL01 from the AG.
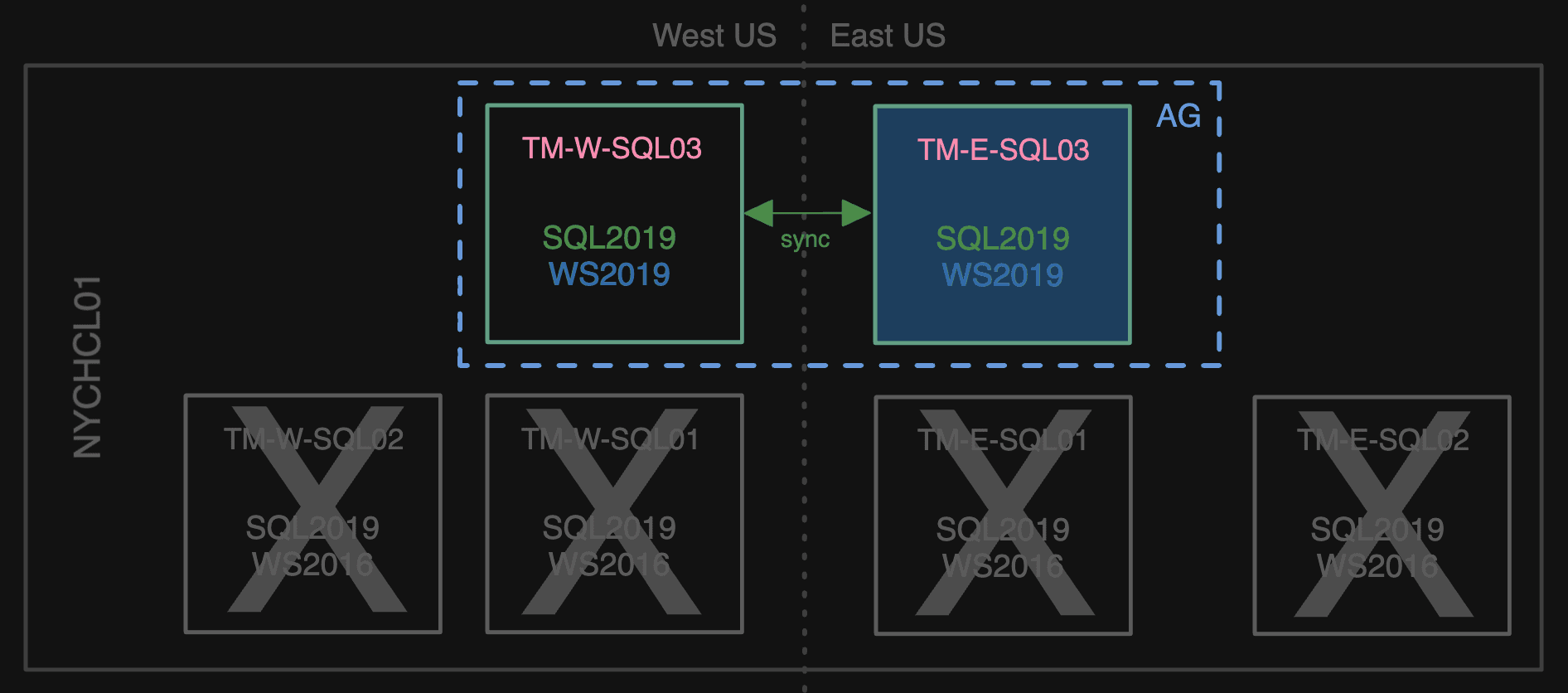
And then there were two
The trickiest part
Next up, how would we actually move the 03 nodes to the new cluster? As mentioned before, we didn’t want to use distributed AGs to additional nodes already in the new cluster, though this would probably be a common and logical suggestion. Instead, we developed a plan to use a short maintenance window and simply move the existing nodes out of the old cluster and into the new cluster. Now, that sounds simple, but there are a lot of steps, and we can’t get there while the AG is up and running, so we’d have to perform the following before and during the maintenance window:
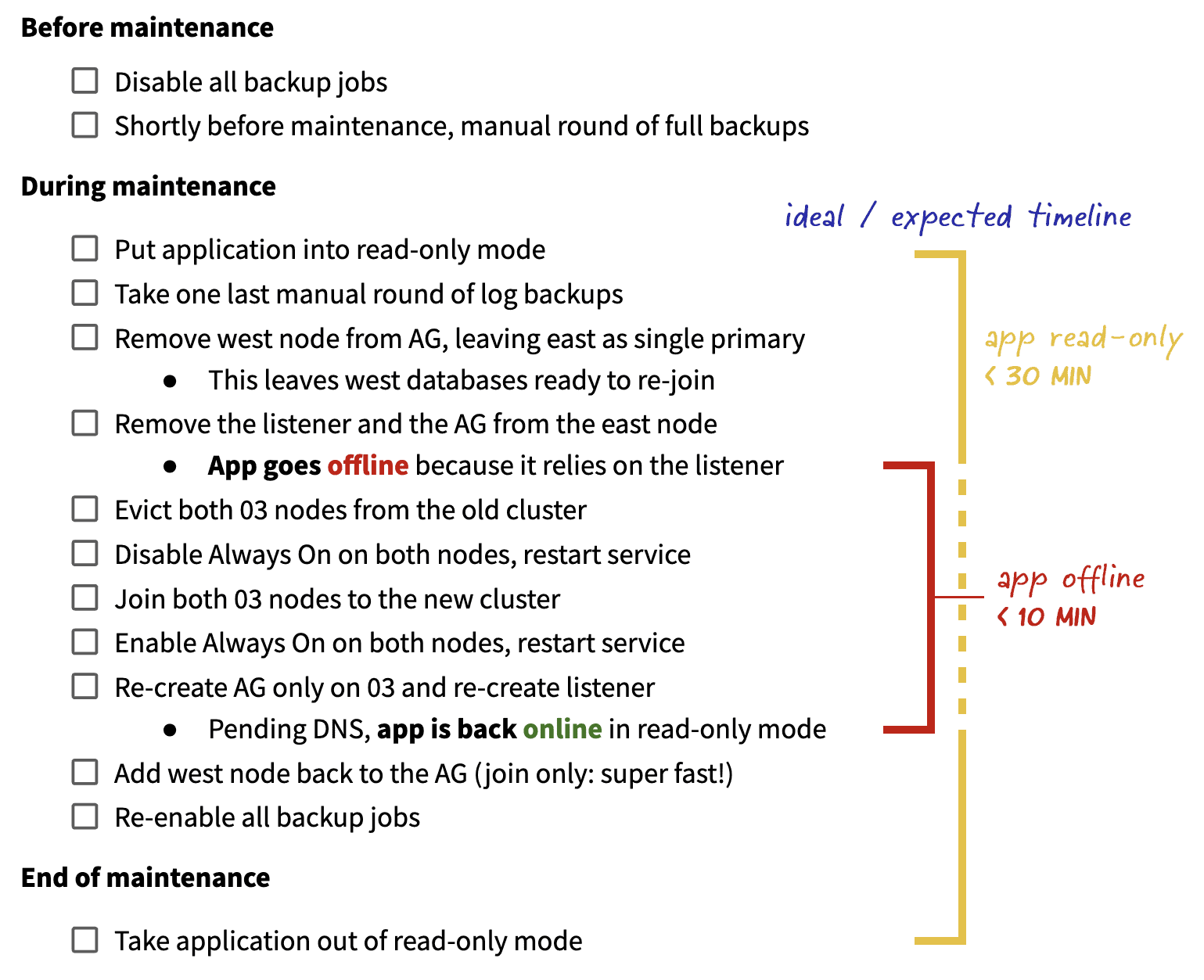
Checklist with guesstimates for duration
There is some risk there, of course, and a few points of no (or at least cumbersome) return. If anything went wrong while the AG was offline or while the primary was the single point of failure, we’d have to resort to the west node (or a full restore). And if the west node couldn’t join successfully, we’d have to seed the AG there from scratch, and would have a single point of failure until that finished. This is why we take a round of backups before the window and a round of log backups immediately after putting the app into read-only mode.
Spoiler: nothing went wrong. The transition was smooth, and the app was in read-only mode for a grand total of 25 minutes, with the offline portion lasting just 9 minutes (most of this time waiting for AD/DNS). Could we have avoided those 9 minutes of downtime? Sure. We could have deployed connection string changes to point to an explicit node instead of the listener then deployed another change to set it back. Then the only downtime would have been two brief service restarts. But this is a lot of additional work and pipeline orchestration to elevate the end-user experience – during an announced maintenance window – from 9 minutes of “offline for maintenance” to 2 minutes of “offline for maintenance” and 7-8 minutes of “you can read, but you can’t write.”
Once we were in a happy state, we could end the maintenance window and turn the app back on:
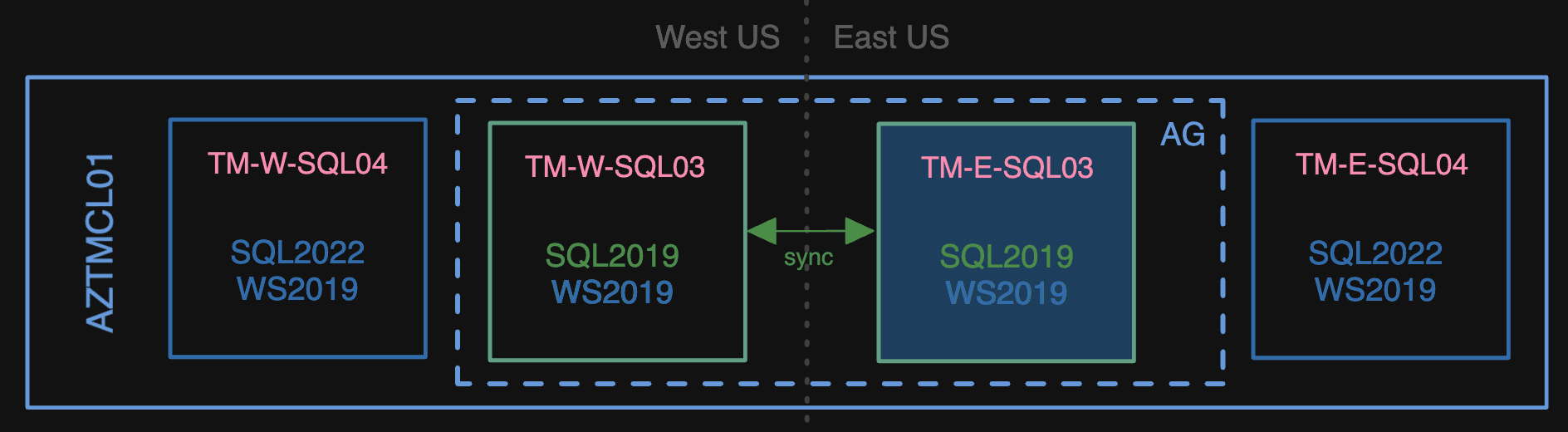
All Windows Server 2019 now
Now, on to SQL Server 2022
With the migration to the new cluster out of the way, we turned our attention to upgrading the environment to SQL Server 2022. This time, we could perform a rolling upgrade without a maintenance window and with just a minor failover blip, similar to when we perform patching. We disabled read-only routing for the duration of these operations, knowing that would mean increased workload on the primary.
First, we added the 04 nodes as secondaries, but – being a newer version of SQL Server – they were not readable.
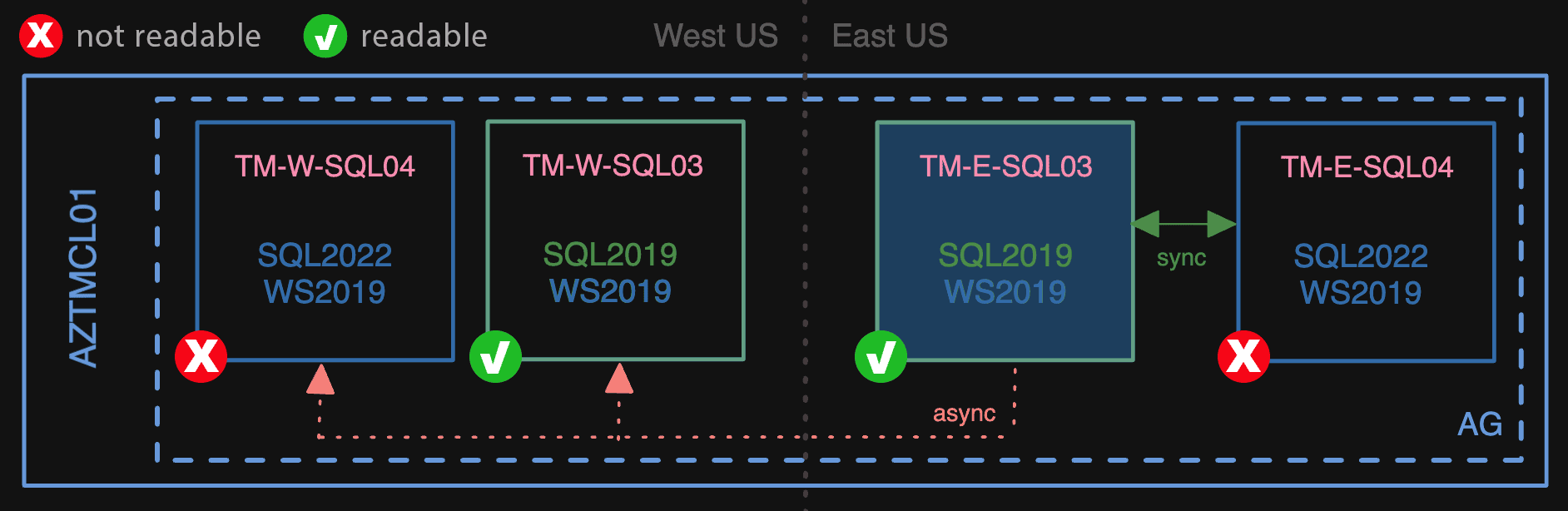
First, we made the 2022 nodes secondaries
Next, we failed over to TM-E-SQL04 as primary, which made the 03 nodes unreadable. This transition was the only downtime for customers, and the only point of no return. The most any customer might have been affected was 42 seconds – this was the longest any database took to come fully online, however this was not even a wholly user-facing database, more of a background scheduler type of deal.
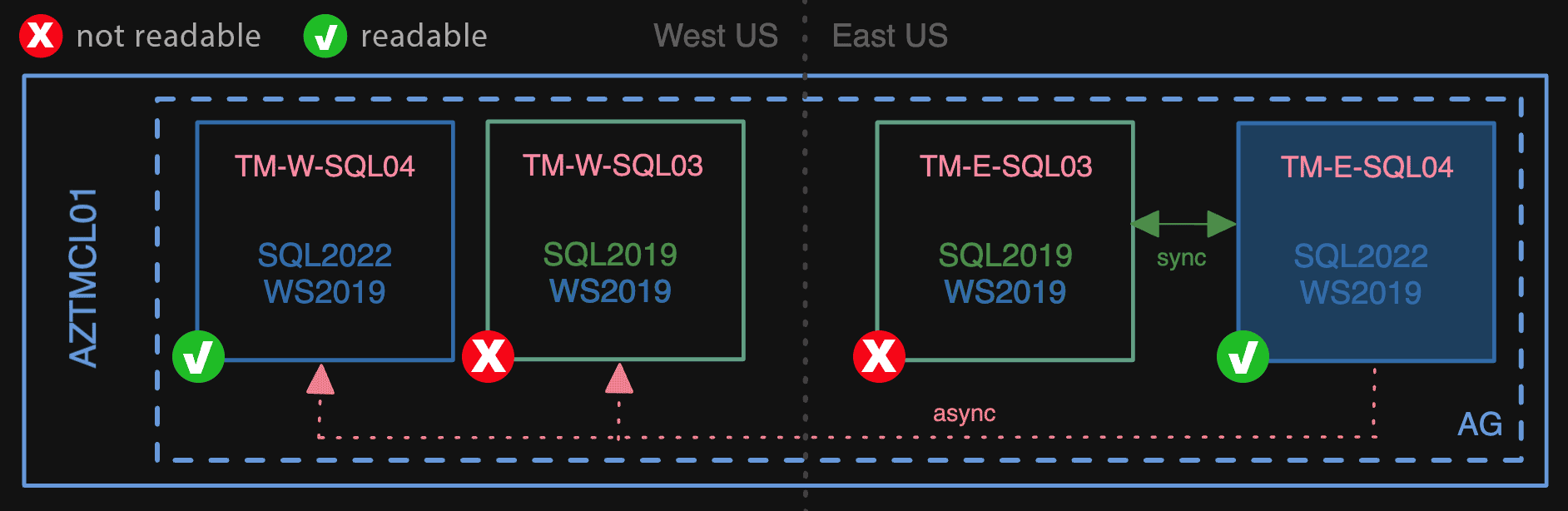
Then, we failed over to a 2022 node
This is another state we didn’t want to be in for long. Not only were the lower version nodes unreadable but, also, the AG could no longer sync to those nodes. This means the primary couldn’t flush logs until the secondaries were all brought up to the same version (or removed from the AG). For expediency, we upgraded the 03 nodes to SQL Server 2022 in place; this isn’t my favorite approach, but it sure is simpler than building yet more VMs and working those into the mix:
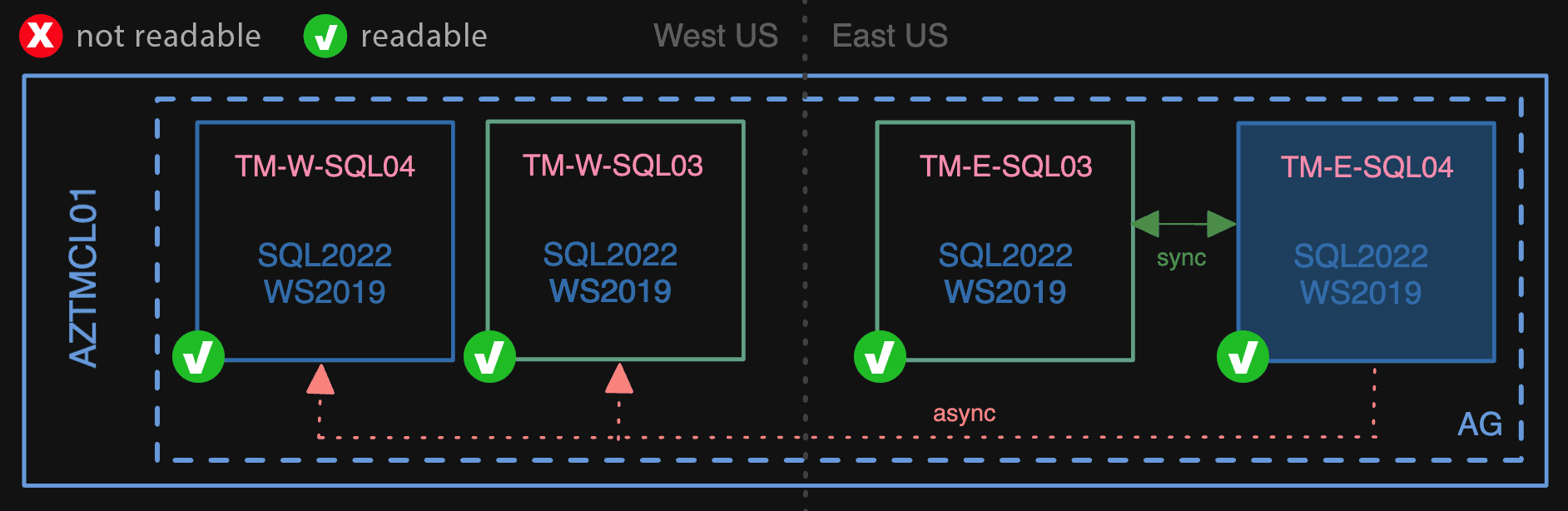
Finally, we upgraded the 2019 nodes
If we needed to take a longer time to perform those upgrades, then in order to avoid undue duress on the primary, we would have just removed those nodes from the AG, and added them back when they (or their replacements) were ready.
At this point, all four nodes are running on Windows Server 2019 and SQL Server 2022, and everything has been smooth so far. Hopefully there is some valuable information here that can help you in your next migration or upgrade.
Next on the list: taking advantage of some of those SQL Server 2022 features, and following similar steps to modernize the public Q & A platform.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments