
A SQL Server deadlock occurs when two or more sessions each hold a lock that the other session needs, creating a circular dependency that SQL Server resolves by killing one session (the deadlock victim) with error 1205.
This article is a comprehensive reference covering three areas: (1) capturing deadlock information – using Extended Events (recommended for SQL Server 2008+), Trace Flags 1204 and 1222, SQL Profiler, Service Broker event notifications, and WMI; (2) reading and interpreting deadlock graphs in XML and text formats; and (3) identifying and eliminating the most common deadlock patterns – bookmark lookup deadlocks, serializable range scan deadlocks, cascading constraint deadlocks, intra-query parallelism deadlocks, and access-order deadlocks. Error handling with TRY/CATCH and DEADLOCK_PRIORITY is also covered.
A deadlock is defined in the dictionary as “a standstill resulting from the action of equal and opposed forces,” and this turns out to be a reasonable description of a deadlock in SQL Server: two or more sessions inside of the database engine end up waiting for access to locked resources held by each other. In a deadlock situation, none of the sessions can continue to execute until one of those sessions releases its locks, so allowing the other session(s) access to the locked resource. Multiple processes persistently blocking each other, in an irresolvable state, will eventually result in a halt to processing inside the database engine.
A common misconception is that DBAs need to intervene to “kill” one of the processes involved in a deadlock. In fact, SQL Server is designed to detect and resolve deadlocks automatically, through the use the Lock Monitor, a background process that is initiated when the SQL Server instance starts, and that constantly monitors the system for deadlocked sessions. However, when deadlocks are reported, the DBA must investigate their cause immediately. Many of the same issues that cause severe blocking in the database, such as poor database design, lack of indexing, poorly designed queries, inappropriate isolation level and so on, are also common causes of deadlocking. This article will provide the tools, techniques and tweaks you need to diagnose and prevent deadlocks, and to ensure that they are handled gracefully if they ever do occur. Specifically, it will cover:
- how to capture deadlock graphs using a variety of techniques, including Trace Flags, the Profiler deadlock graph event, and service broker event notifications
- how to read deadlock graphs to locate the sessions, queries and resources that are involved
- common types of deadlock and how to prevent them
- using server- or client-side TRY…CATCH error handling for deadlocks, to avoid UnhandledException errors in the application.
The Lock Monitor
When the Lock Monitor performs a deadlock search and detects that one or more sessions are embraced in a deadlock, one of the sessions is selected as a deadlock victim and its current transaction is rolled back. When this occurs, all of the locks held by the victim’s session are released, allowing any previously blocked other sessions to continue processing. Once the rollback completes, the victim’s session is terminated, returning a 1205 error message to the originating client.
SQL Server selects the deadlock victim based on the following criteria:
- Deadlock priority – the assigned DEADLOCK_PRIORITY of a given session determines the relative importance of it completing its transactions, if that session is involved in a deadlock. The session with the lowest priority will always be chosen as the deadlock victim. Deadlock priority is covered in more detail later in this article.
- Rollback cost – if two or more sessions involved in a deadlock have the same deadlock priority, then SQL Server will choose as the deadlock victim the session that has lowest estimated cost to roll back.
Capturing Deadlock Graphs
When 1205 errors are reported, it is important that the DBA finds out why the deadlock happened and takes steps to prevent its recurrence. The first step in troubleshooting and resolving a deadlocking problem is to capture the deadlock graph information.
A deadlock graph is an output of information regarding the sessions and resources that were involved in a deadlock. The means by which you can capture a deadlock graph have diversified and improved over recent versions of SQL Server. If you are still running SQL Server 2000, then you are stuck with a single, somewhat limited, Trace Flag (1204). SQL Server 2005 added a new Trace Flag (1222), provided the XML Deadlock Graph event in SQL Server Profiler, and enabled deadlock graph capture via Service Broker event notifications, and the WMI (Windows Management Instrumentation) Provider for Server Events. In each case, the deadlock graph contains significantly more information about the nature of the deadlock than is available through Trace Flag 1204. This minimizes the need to gather, manually, additional information from SQL Server in order to understand why the deadlock occurred; for example, resolving the pageid for the locks being held to the objectid and indexid, using DBCC PAGE, and using SQL Trace to walk the deadlock chain and find out which currently executing statements are causing the problem. SQL Server 2008 provides all of these facilities, plus the system_health Extended Events Session.
To allow you to work through each section, and generate the same deadlock graphs that are presented and described in the text, the resource materials for this article include example code to generate a deadlock in SQL Server.
Trace Flag 1204
Trace Flags in SQL Server enable alternate “code paths” at key points inside the database engine, allowing additional code to execute when necessary. If you are seeing queries failing with deadlock errors on a SQL Server instance, Trace Flags can be enabled for a single session or for all of the sessions on that instance. When Trace Flag 1204 is enabled for all sessions on a SQL Server instance, any deadlock detected by the deadlock monitor will cause a deadlock graph to be written to the SQL Server error log.
In SQL Server 2000, this Trace Flag is the only means by which to capture a deadlock graph, which makes troubleshooting deadlocking in SQL Server 2000 quite challenging, though still possible. In later SQL Server versions, this Trace Flag is still available although superseded by Trace Flag 1222.
Trace Flag 1204, like all Trace Flags, can be enabled and disabled on an ad hoc basic using the DBCC TRACEON and DBCC TRACEOFF database console commands. Listing 1 shows how to enable Trace Flag 1204, for a short term, at the server-level (specified by the -1 argument) so that all subsequent statements run with this Trace Flag enabled.
|
1 |
DBCC TRACEON(1204, -1) |
Listing 1: Turning on Trace Flag 1204 for all sessions.
Alternatively, Trace Flags can be turned on automatically, using the -T startup parameter. To add a startup parameter to SQL Server, right-click on the Server Node in Enterprise Manager and open the Server Properties page. Under the General tab, click the Startup Parameters button, and then add the startup parameter to the server as shown in Figure 1.
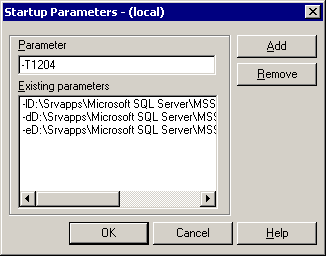
Figure 1: Using the -T startup parameter.
In cases where it is possible to perform an instance restart, using a startup parameter can be helpful when you want to capture every deadlock that occurs from the server, over a long period of time. However, once deadlock troubleshooting has been completed, the Trace Flag should be removed from the startup parameters. Since the Trace Flag enables the instance to write the deadlock graph to the SQL Server error log, the only way to retrieve the graph is to read the error log file and then extract the events from the log file for analysis.
Trace Flag 1222
SQL Server 2005 added Trace Flag 1222 to capture the deadlock graphs in an easier-to-read and more comprehensive format than was available with the 1204 flag. It captures and presents the information in a manner that makes it much easier to identify the deadlock victim, as well as the resources and processes involved in the deadlock (covered in detail in the Reading Deadlock Graphs section).
Trace Flag 1204 is still available, for backwards compatibility reasons, but when using Trace Flags to capture deadlock graphs in SQL Server 2005 or later, you should always use Trace Flag 1222 in preference to Trace Flag 1204. Trace Flag 1222 is enabled in the same manner as 1204, using DBCC TRACEON(), as shown in Listing 1 or the -T startup parameter, as shown in Figure 1.
SQL Profiler XML Deadlock Graph event
New to SQL Server 2005, the Deadlock Graph event in SQL Trace captures the deadlock graph information, without writing it to the SQL Server Error Log. The Deadlock Graph event is part of the Locks event category and can be added to a SQL Server Profiler trace by selecting the event in Profiler’s Trace Properties dialog, as shown in Figure 2.
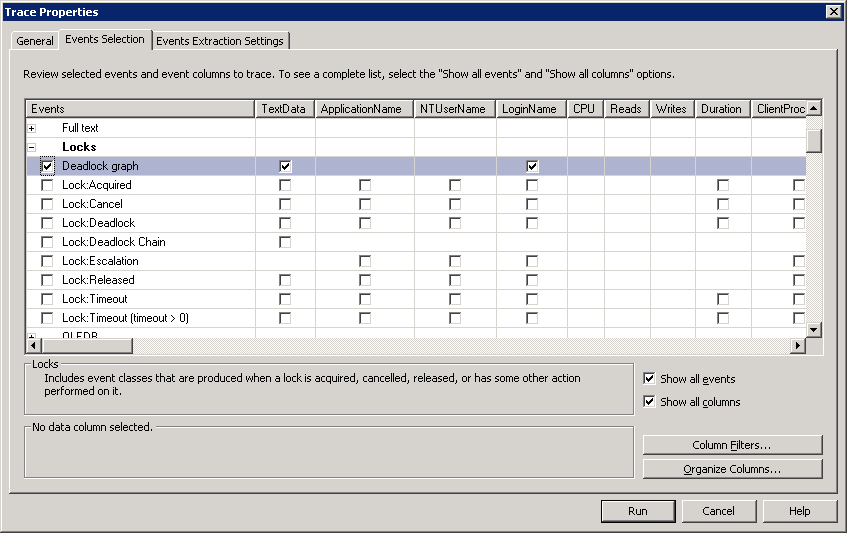
Figure 2: Selecting Deadlock Graph event in the Trace Properties dialog.
SQL Profiler can be configured to save the deadlock graphs separately, into XDL files, as shown in Figure 3.
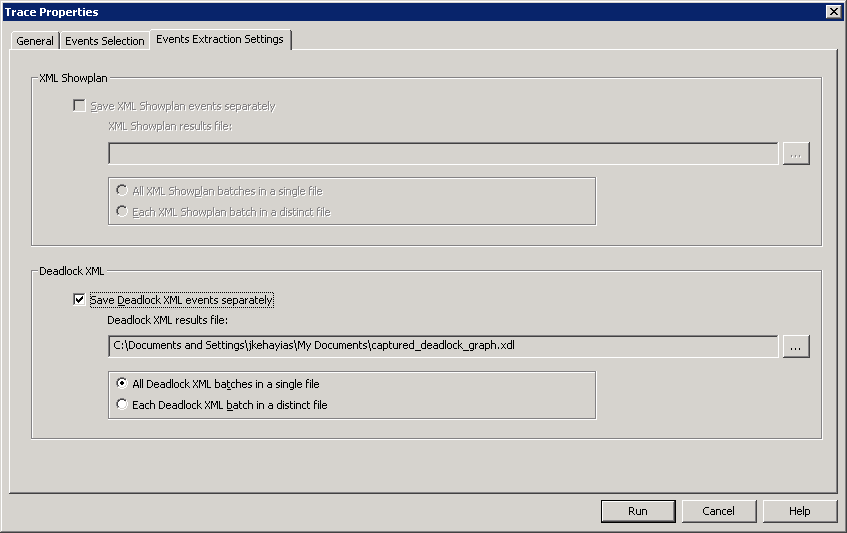
Figure 3: Saving deadlock graphs.
An XDL file is a standard XML file. Management Studio recognizes the file extension when opening the file and displays the deadlock information graphically, rather than as XML.
If you prefer to work directly with server-side traces, removing the overhead of the Profiler client, then you can capture the deadlock graph information directly from your scripts, using the SP_TRACE_* set of system stored procedures. The captured graphs will be written to a SQL Trace file on the SQL Server. The easiest way to generate a script for a server-side trace is to first create the trace in SQL Profiler, and then export it to a script using File | Export | Script Trace Definition.
A server-side trace file can be read using the system function fn_trace_gettable, or by opening it inside of SQL Profiler. When using SQL Profiler to view the trace file contents, the deadlock events can be exported to individual XDL files that can be opened up graphically using SQL Server Management Studio, through the File | Export | Extract SQL Server Events | Extract deadlock Events menu item.
Service Broker event notifications
Also new in SQL Server 2005, event notifications allow the capture of deadlock graph information using SQL Server Service Broker, by creating a service and queue for the DEADLOCK_GRAPH trace event. The information contained in the deadlock graph captured by event notifications is no different than the information contained in the deadlock graph captured by SQL Trace; the only difference is the mechanism of capture.
Setting up an event notification to capture deadlock graph information requires three Service Broker objects:
- A QUEUE to hold the DEADLOCK_GRAPH event messages
- A SERVICE to route the messages to the queue
- An EVENT NOTIFICATION to capture the deadlock graph and package it in a message that is sent to the Service.
Listing 2 shows how to create these objects using T-SQL. Note that you need to create the objects in a broker-enabled database, like msdb. The Master database is not enabled for broker, by default.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE msdb; -- Create a service broker queue to hold the events CREATE QUEUE DeadlockQueue GO -- Create a service broker service receive the events CREATE SERVICE DeadlockService ON QUEUE DeadlockQueue ([http://schemas.microsoft.com/SQL/Notifications/PostEventNotification]) GO -- Create the event notification for deadlock graphs on the service CREATE EVENT NOTIFICATION CaptureDeadlocks ON SERVER WITH FAN_IN FOR DEADLOCK_GRAPH TO SERVICE 'DeadlockService', 'current database' ; GO |
Listing 2: Creating the Service Broker service, queue, and event notification objects.
With the objects created, deadlock graphs will be collected in the queue, as deadlocks occur on the server. While the queue can be queried using a SELECT statement, just as if it were a table, the contents remain in the queue until they are processed using the RECEIVE command, as demonstrated in Listing 3.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
USE msdb ; -- Cast message_body to XML and query deadlock graph from TextData SELECT message_body.valuequery('(/EVENT_INSTANCE/TextData/ deadlock-list)[1]', 'varchar(128)') AS DeadlockGraph FROM ( SELECT CAST(message_body AS XML) AS message_body FROM DeadlockQueue ) AS sub ; GO -- Receive the next available message FROM the queue DECLARE @message_body XML ; RECEIVE TOP(1) -- just handle one message at a time @message_body=message_body FROM DeadlockQueue ; -- Query deadlock graph from TextData SELECT @message_body.valuequery('(/EVENT_INSTANCE/TextData/ deadlock-list)[1]','varchar(128)') AS DeadlockGraph GO |
Listing 3: Query and processing DEADLOCK_GRAPH event messages in the queue.
Since Event Notifications utilize a service broker queue for processing, additional actions can be performed when the deadlock event fires. When a deadlock event occurs, Service Broker can “activate” a stored procedure that processes the message and responds appropriately, for example, by sending an email notification using Database Mail, logging the event in a table, or gathering additional information, like the execution plans for both statements, from SQL Server, based on the information contained inside of the deadlock graph. Full coverage of this topic is beyond the scope of this article. However, a full example of how to use queue activation to completely automate deadlock collection can be found in the code download file for this book.
WMI Provider for server events
Also new to SQL Server 2005, the WMI Provider for Server Events allows WMI to be used to monitor SQL Server events as they occur. Any event that can be captured through event notifications has a corresponding WMI Event Object, and any WMI management application can subscribe to these event objects.
SQL Server Agent was updated to manage WMI events, through the use of WMI Query Language (WQL), a query language similar to T-SQL that is used with WMI and Agent Alerts for WMI events.
A full example of how to create a SQL Agent alert to capture and store deadlock graphs is out of scope for this article, and can be found in the Books Online Sample: (Creating a SQL Server Agent Alert by Using the WMI Provider for Server Events). However, in essence, it involves creating, via the WMI Event Provider, a SQL Agent alert to monitor deadlock graph events. The alert queries for events using WQL, and when it receive notification that one has occurred, it fires a job that captures the deadlock graph in a designated SQL Server table.
To capture deadlock graphs using the WMI Event Provider and a SQL Agent alert in this manner requires that the “Replace tokens for all job responses to alerts” in SQL Server Agent Alert System properties must be enabled. It also requires that Service Broker (which processes the notification messages) is enabled in msdb as well as the database in which the deadlock graphs are stored.
WMI event provider bug
It is worth noting that there is a known bug in the WMI Event Provider for server names that exceed fourteen characters; this was fixed in Cumulative Update 5 for SQL Server 2005 Service Pack 2.
Extended Events
Prior to SQL Server 2008, there was no way to retroactively find deadlock information. Obtaining deadlock graphs required that a SQL Trace was actively running, or that Trace Flag 1222 or 1205 was turned on for the instance. Since tracing deadlocks by either of these methods can be resource intensive, this usually meant that a series of deadlocks had to occur to prompt starting a trace or enabling the Trace Flags.
SQL Server 2008 includes all of the previously discussed techniques for capturing deadlock graphs, and adds one new one, namely collecting the deadlock information through the system_health default event session in Extended Events. This default event session (akin, in concept, to the default trace) is running by default on all installations of SQL Server 2008 and collects a range of useful troubleshooting information for errors that occur in SQL Server, including deadlocks. Deadlock graphs captured by Extended Events in SQL Server 2008 have the unique ability to contain information about multi-victim deadlocks (deadlocks where more than session was killed by the Lock Monitor to resolve the conflict).
Multi-victim Deadlock Example
We can’t cover Extended Events in detail in this article but, for a good overview of the topic, read Paul Randal’s article, “SQL 2008: Advanced Troubleshooting with Extended Events“. Also, an example of how to create a multi-victim deadlock in SQL Server can be found on my blog post from 2009, “Changes to the Deadlock Monitor for the Extended Events xml_deadlock_report and Multi-Victim Deadlocks“.
The system_health session uses a ring_buffer target which stores the information collected by events firing in memory as an XML document in the sys.dm_xe_session_targets DMV. This DMV can be joined to the sys.dm_xe_sessions DMV to get the session information along with the data stored in the ring_buffer target, as shown in Listing 4.
|
1 2 3 4 |
SELECT CAST(target_data AS XML) AS TargetData FROM sys.dm_xe_session_targets st JOIN sys.dm_xe_sessions s ON s.address = st.event_session_address WHERE name = 'system_health' |
Listing 4: Retrieving system_health session information.
The query in Listing 5a shows how to retrieve a valid XML deadlock graph from the default system_health session using XQuery, the target_data column, and a CROSS APPLY to get the individual event nodes. Note that, due to changes in the deadlock graph to support multi-victim deadlocks, and to minimize the size of the event data, the resulting XML cannot be saved as an XDL file for graphical representation.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT CAST(event_data.value('(event/data/value)[1]', 'varchar(max)') AS XML) AS DeadlockGraph FROM ( SELECT XEvent.query('.') AS event_data FROM ( -- Cast the target_data to XML SELECT CAST(target_data AS XML) AS TargetData FROM sys.dm_xe_session_targets st JOIN sys.dm_xe_sessions s ON s.address = st.event_session_address WHERE name = 'system_health' AND target_name = 'ring_buffer' ) AS Data -- Split out the Event Nodes CROSS APPLY TargetData.nodes('RingBufferTarget/ event[@name="xml_deadlock_report"]') AS XEventData ( XEvent ) ) AS tab ( event_data ) |
Listing 5a: Retrieving an XML deadlock graph in SQL Server 2008
Note, also, that there is a bug in the RTM release of SQL Server 2008 that causes deadlock graphs not to be captured and retained in an Extended Events session. This bug was fixed in Cumulative Update 1 for SQL Server 2008 and is also included in the latest Service Pack. An additional bug exists for malformed XML in the deadlock graph generated by Extended Events, which was corrected in Cumulative Update Package 6 for SQL Server 2008 Service Pack 1. It is still possible to generate a valid XML document in these earlier builds, by hacking the deadlock graph being output by Extended Events. However, since the fix to SQL Server has already been released, the specifics of the work-around will not be covered in this article.
In SQL Server 2012 there are changes associated to how the Extended Events targets store XML data inside of the value element of the Event XML output. Listing 5 shows the use of the .value() method from XML in SQL Server, but in SQL Server 2012, a .query() method has to be used to retrieve the deadlock graph from the Event XML output.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- Retrieve from Extended Events in 2012 SELECT XEvent.query('(event/data/value/deadlock)[1]') AS DeadlockGraph FROM ( SELECT XEvent.query('.') AS XEvent FROM ( SELECT CAST(target_data AS XML) AS TargetData FROM sys.dm_xe_session_targets st JOIN sys.dm_xe_sessions s ON s.address = st.event_session_address WHERE s.name = 'system_health' AND st.target_name = 'ring_buffer' ) AS Data CROSS APPLY TargetData.nodes ('RingBufferTarget/event[@name="xml_deadlock_report"]') AS XEventData ( XEvent ) ) AS src; |
Listing 5b: Retrieving an XML deadlock graph in SQL Server 2012
Reading Deadlock Graphs
The precise format of the deadlock graph in SQL Server has changed from version to version, and mainly for the better. In general, it now contains better information in an easier-to-digest format, such as the graphical display provided in SQL Server Management Studio and SQL Profiler, so allowing us to more easily troubleshoot deadlocks.
Even with the changes to the deadlock graph XML that is output by Extended Events, in SQL Server 2008, the fundamentals of how to interpret the graph are the same as for any other XML deadlock graph.
Interpreting Trace Flag 1204 deadlock graphs
Perhaps one of the most difficult aspects of troubleshooting deadlocks in SQL Server 2000 is interpreting the output of Trace Flag 1204. The process is complicated by the need to query the sysobjects and sysindexes system tables to find out exactly what objects are involved in the deadlock.
Listing 6 shows an example deadlock graph that was generated by enabling Trace Flag 1204, and then creating a deadlock situation (the code to do this is provided as part of the code download for this book).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
Deadlock encountered .... Printing deadlock information Wait-for graph Node:1 KEY: 13:1993058136:2 (08009d1c9ab1) CleanCnt:2 Mode: S Flags: 0x0 Grant List 0:: Owner:0x567e7660 Mode: S Flg:0x0 Ref:1 Life:00000000 SPID:54 ECID:0 SPID: 54 ECID: 0 Statement Type: SELECT Line #: 3 Input Buf: Language Event: WHILE (1=1) BEGIN INSERT INTO #t1 EXEC BookmarkLookupSelect 4 TRUNCATE TABLE #t1 END Requested By: ResType:LockOwner Stype:'OR' Mode: X SPID:55 ECID:0 Ec:(0x26F7DBD8) Value:0x58f80880 Cost:(0/3C) Node:2 KEY: 13:1993058136:1 (040022ae5dcc) CleanCnt:2 Mode: X Flags: 0x0 Grant List 1:: Owner:0x58f80940 Mode: X Flg:0x0 Ref:0 Life:02000000 SPID:55 ECID:0 SPID: 55 ECID: 0 Statement Type: UPDATE Line #: 4 Input Buf: Language Event: SET NOCOUNT ON WHILE (1=1) BEGIN EXEC BookmarkLookupUpdate 4 END Requested By: ResType:LockOwner Stype:'OR' Mode: S SPID:54 ECID:0 Ec:(0x2F881BD8) Value:0x567e76c0 Cost:(0/0) Victim Resource Owner: ResType:LockOwner Stype:'OR' Mode: S SPID:54 ECID:0 Ec:(0x2F881BD8) Value:0x567e76c0 Cost:(0/0) |
Listing 6: Sample deadlock graph from Trace Flag 1204, involving KEY locks.
The first thing to pay attention to in the graph output is that there are two nodes, each node representing a locked resource. The first line of output for each node shows the resource on which the lock is held, and then the Grant List section provides details of the deadlocking situation, including:
- Mode of the lock being held on the resource
- SPID of the associated process
- Statement Type the SPID is currently running
- Line # (line number) that marks the start of the currently executing statement
- Input Buf, the contents of the input buffer for that SPID (the last statement sent).
So, for Node 1, we can see that a shared read (S) lock is being held by SPID 54 on an index KEY of a non-clustered index (:2) on an object with ID 1993058136. Node 2 shows that an exclusive (X) lock is being held by SPID 55 on an index key of the clustered index (:1) of the same object.
Further down, for each node, is the Requested By section, which details any resource requests that cannot be granted, due to blocking. For Node 1, we can see that that SPID 55 is waiting for an exclusive lock on the non-clustered index key (it is blocked by the S lock held by SPID 54). For Node 2, we can see that SPID 54 is waiting to acquire a shared read lock on the clustered index key (it is blocked by the exclusive lock held by SPID 55).
Furthermore, back in the Grant List section, we can see that SPID 54 has issued the SELECT statement on Line # 3 of the BookmarkLookupSelect stored procedure (but is unable to acquire a shared read lock) and SPID 55 has issued the UPDATE statement on Line # 4 of the BookmarkLookupUpdate stored procedure (but is unable to acquire an exclusive lock).
This is a classic deadlock situation, and happens to be one of the more common types of deadlock, covered in more detail later in this article, in the section titled Bookmark lookup deadlock.
Finally, in the Victim Resource Owner section we can find out which SPID was chosen as the deadlock victim, in this case, SPID 54. Alternatively, we can identify the deadlock victim by matching the binary information in the Value to the binary information in the Owner portion of the Grant List.
We’ve discussed a lot about the deadlocking incident, but so far we know only that it occurred on an object with an ID of 1993058136. In order to identify properly the object(s) involved in the deadlock, the information in the KEY entry for each node needs to be used to query sysobjects and sysindexes. The KEY entry is formatted as databaseid:objected:indexid. So, in this example, SPID 54 was holding a Shared (S) lock on index id 2, a non-clustered index, with objectID 1993058136. The query in Listing 7 shows how to determine the table and index names associated with the deadlock.
|
1 2 3 4 5 6 |
SELECT o.name AS TableName , i.name AS IndexName FROM sysobjects AS o JOIN sysindexes AS i ON o.id = i.id WHERE o.id = 1993058136 AND i.indid IN ( 1, 2 ) |
Listing 7: Finding the names of the objects associated with the deadlock.
If a deadlock involves a PAG lock instead of a KEY lock, the deadlock graph might look as shown in Listing 8.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Wait-for graph Node:1 PAG: 8:1:96 CleanCnt:2 Mode: X Flags: 0x2 Grant List 0:: Owner:0x195fb2e0 Mode: X Flg:0x0 Ref:1 Life:02000000 SPID: 56 ECID: 0 Statement Type: UPDATE Line #: 4 Input Buf: Language Event: SET NOCOUNT ON WHILE (1=1) BEGIN EXEC BookmarkLookupUpdate 4 END Requested By: ResType:LockOwner Stype:'OR' Mode: S SPID:55 ECID:0 Ec:(0x1A5E1560) Value:0x1960dba0 Cost:(0/0) |
Listing 8: Page lock example, generated by Trace Flag 1204.
Notice now that the lock reference is of the form databaseid:fileid:pageid. In order to identify the object to which this page belongs, we need to enable Trace Flag 3604, dump the page header information to the client message box DBCC PAGE(), and then disable the Trace Flag, as shown in Listing 9.
|
1 2 3 |
DBCC TRACEON(3604) DBCC PAGE(8,1,96,1) DBCC TRACEOFF(3604) |
Listing 9: Identifying the objects involved in a deadlock involving page locks.
The output of the DBCC PAGE() command will include a PAGE HEADER section, shown in Listing 10, which contains the IDs of the object (m_objId field) and index (m_indexId) to which the page belongs.
|
1 2 3 4 5 6 7 8 9 |
Page @0x1A5EC000 ---------------- m_pageId = (1:96) m_headerVersion = 1 m_type = 1 m_typeFlagBits = 0x0 m_level = 0 m_flagBits = 0x4 m_objId = 1977058079 m_indexId = 0 m_prevPage = (0:0) m_nextPage = (1:98) pminlen = 116 m_slotCnt = 66 m_freeCnt = 110 m_freeData = 7950 m_reservedCnt = 0 m_lsn = (912:41:3) m_xactReserved = 0 m_xdesId = (0:0) m_ghostRecCnt = 0 m_tornBits = 2 |
Listing 10: Page Header section from the output of the DBCC PAGE().
Understanding the statements that are being executed along with the indexes and objects involved in the deadlock is critical to troubleshooting the problem. However, there are situations where the currently executing statement may not be the actual statement that caused the deadlock. Multi-statement stored procedures and batches that enlist an explicit transaction will hold all of the locks acquired under the transaction scope until the transaction is either committed or rolled back. In this situation, the deadlock may involve locks that were acquired by a previous statement that was executed inside the same transaction block. To completely troubleshoot the deadlock it is necessary to look at the executing batch from the Input Buf as a whole, and understand when locks are being acquired and released.
Interpreting Trace Flag 1222 deadlock graphs
The format of the information, as well as the amount of information, returned by Trace Flag 1222 is very different than the output from Trace Flag 1204. Listing 11 shows the Trace Flag 1222 output, in SQL Server 2005, for an identical deadlock to the one previously seen for the Trace Flag 1204 output, from SQL Server 2000.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
deadlock-list deadlock victim=process8d8c58 process-list process id="process84b108"> taskpriority=0 logused=220 waitresource=KEY: 34:72057594038452224 (0c006459e83f) waittime=5000 ownerId=899067977 transactionname=UPDATE lasttranstarted=2009-12-13T00:22:46.357 XDES=0x157be250 lockMode=X schedulerid=1 kpid=4340 status=suspended spid=102 sbid=0 ecid=0 priority=0 transcount=2 lastbatchstarted=2009-12-13T00:13:37.510 lastbatchcompleted=2009-12-13T00:13:37.507 clientapp=Microsoft SQL Server Management Studio - Query hostname=SQL2K5TEST hostpid=5516 loginname=sa isolationlevel=read committed (2) xactid=899067977 currentdb=34 lockTimeout=4294967295 clientoption1=673187936 clientoption2=390200 executionStack frame procname=DeadlockDemo.dbo.BookmarkLookupUpdate line=4 stmtstart=260 stmtend=394 sqlhandle=0x03002200e7a4787d08a10300de9c00000100000000000000 UPDATE BookmarkLookupDeadlock SET col2 = col2-1 WHERE col1 = @col2 frame procname=adhoc line=4 stmtstart=82 stmtend=138 sqlhandle=0x020000002a7093322fbd674049d04f1dc0f3257646c4514b EXEC BookmarkLookupUpdate 4 inputbuf SET NOCOUNT ON WHILE (1=1) BEGIN EXEC BookmarkLookupUpdate 4 END process id="process8d8c58"> taskpriority=0 logused=0 waitresource=KEY: 34:72057594038386688 (0500b49e5abb) waittime=5000 ownerId=899067972 transactionname=INSERT EXEC lasttranstarted=2009-12-13T00:22:46.357 XDES=0x2aebba08 lockMode=S schedulerid=2 kpid=5864 status=suspended spid=61 sbid=0 ecid=0 priority=0 transcount=1 lastbatchstarted=2009-12-13T00:22:46.347 lastbatchcompleted=2009-12-13T00:22:46.343 clientapp=Microsoft SQL Server Management Studio - Query hostname=SQL2K5TEST hostpid=5516 loginname=sa isolationlevel=read committed (2) xactid=899067972 currentdb=34 lockTimeout=4294967295 clientoption1=673187936 clientoption2=390200 executionStack frame procname=DeadlockDemo.dbo.BookmarkLookupSelect line=3 stmtstart=118 stmtend=284 sqlhandle=0x03002200ae80847c07a10300de9c00000100000000000000 SELECT col2, col3 FROM BookmarkLookupDeadlock WHERE col2 BETWEEN @col2 AND @col2+1 frame procname=adhoc line=3 stmtstart=50 stmtend=146 sqlhandle=0x02000000e00b66366c680fabe2322acbad592a896dcab9cb INSERT INTO #t1 EXEC BookmarkLookupSelect 4 inputbuf WHILE (1=1) BEGIN INSERT INTO #t1 EXEC BookmarkLookupSelect 4 TRUNCATE TABLE #t1 END resource-list keylock hobtid=72057594038386688 dbid=34 objectname=DeadlockDemo.dbo.BookmarkLookupDeadlock indexname=cidx_BookmarkLookupDeadlock id="lock137d65c0" mode=X associatedObjectId=72057594038386688 owner-list owner id="process84b108" mode=X waiter-list waiter id="process8d8c58" mode=S requestType=wait keylock hobtid=72057594038452224 dbid=34 objectname=DeadlockDemo.dbo.BookmarkLookupDeadlock indexname=idx_BookmarkLookupDeadlock_col2 id="lock320d5900" mode=S associatedObjectId=72057594038452224 owner-list owner id="process8d8c58" mode=S waiter-list waiter id="process84b108" mode=X requestType=wait |
Listing 11: Sample deadlock graph, generated by Trace Flag 1222.
The new format breaks a deadlock down into sections that define the deadlock victim, the processes involved in the deadlock (process-list), and the resources involved in the deadlock (resource-list). Each process has an assigned process id that is used to uniquely identify it in the deadlock graph. The deadlock victim lists the process that was selected as the victim and killed by the deadlock monitor. Each process includes the SPID as well as the hostname and loginname that originated the request, and the isolation level under which the session was running when the deadlock occurred. The execution stack section, for each process, displays the entire execution stack, starting from the most recently executed (deadlocked) statement backwards to the start of the call stack. This eliminates the need to perform additional steps to identify the statement being executed.
The resource-list contains all of the information about the resources involved in the deadlock and is generally the starting point for reading a deadlock graph. The index names are included in the output and each resource displays the owner process and the type of locks being held, as well as the waiting process and the type of locks being requested.
The definitive source for understanding the output from Trace Flag 1222 is Bart Duncan. He has a three-part series on troubleshooting deadlocks with the output from Trace Flag 1222 on his blog, starting with (Deadlock Troubleshooting, Part 1).
Using the same technique employed in these posts, we can construct a description of the deadlock described, as shown in Listing 12.
|
1 2 3 4 5 6 7 8 9 10 11 |
SPID 102 (process84b108) is running this query (line 4 of the BookmarkLookupUpdate sproc): UPDATE BookmarkLookupDeadlock SET col2 = col2-1 WHERE col1 = @col2 SPID 61 (process8d8c58 )is running this query (line 3 of BookmarkLookupSelect sproc): SELECT col2, col3 FROM BookmarkLookupDeadlock WHERE col2 BETWEEN @col2 AND @col2+1 SPID 102 is waiting for an Exclusive KEY lock on the idx_BookmarkLookupDeadlock_col2 index (on the BookmarkLookupDeadlock table). (SPID 61 holds a conflicting S lock) SPID 61 is waiting for a Shared KEY lock on the index cidx_BookmarkLookupDeadlock (on the BookmarkLookupDeadlock table).. (SPID 102 holds a conflicting X lock) |
Listing 12: Deadlock analysis, constructed from the Trace Flag 1222 deadlock graph.
As we can see from the deadlock list section of Listing 11, SPID 61, attempting to run the SELECT statement against cidx_BookmarkLookupDeadlock, is chosen as the deadlock victim.
Interpreting XML deadlock graphs
The information contained in XML deadlock graph, obtained from SQL Profiler, or Service Broker Event notifications, and so on, is essentially the same as that obtained from the output of Trace Flag 1222, and it is interpreted in exactly the same way. However, the format in which the information is presented is very different. The XML deadlock graph can be displayed graphically in Management Studio by saving the XML to a file with a .XDL extension and then opening the file in Management Studio (although, as discussed earlier, the XML generated by Extended Events can’t be displayed graphically, in this manner).
Figure 4 displays graphically the same deadlock graph that we saw for the two Trace Flags.
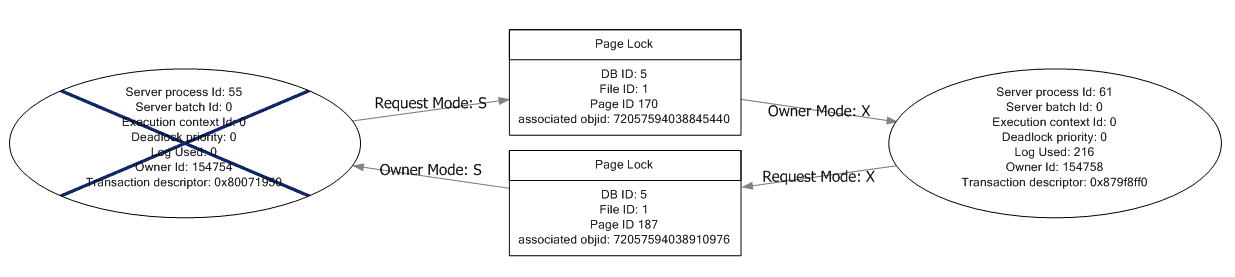
Figure 4: SSMS graphical deadlock graph.
In the graphical display, the deadlock processes are displayed as ovals. The process information is displayed inside of the oval, and includes a tooltip, which pops up when the mouse hovers over the process, and displays the statement being executed, as shown in Figure 5. The deadlock victim process is shown crossed out.
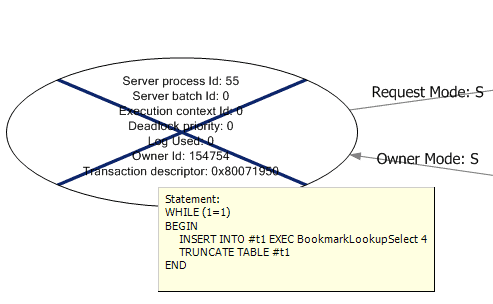
Figure 5: SSMS graphical deadlock graph: the victim process.
The resources contributing to the deadlock are displayed in rectangular boxes in the center of the graphical display. The locks, and their respective modes, are displayed by arrows between the processes and the resources. Locks owned by a process are shown with the arrow pointed towards the process, while locks being requested are shown with the arrow pointed towards the resource as shown in Figure 6.

Figure 6: SSMS graphical deadlock graph: processes and resources.
A visual display like this makes it much easier to understand the circular blocking that caused the deadlock to occur.
Common types of deadlock and how to eliminate them
When troubleshooting any type of problem in SQL Server, you learn with experience how to recognize, from a distance, the particular varieties of problem that tend to crop up on a regular basis. The same is true of deadlocks; the same types of deadlock tend to appear with predictable regularity and, once you understand what patterns to look for, resolving the deadlock becomes much more straightforward.
This section assumes knowledge of basic locking mechanisms inside SQL Server and examines how to resolve the most common types of deadlock, namely the bookmark lookup deadlock, the serializable range scan deadlock, the cascading constraint deadlock, the intra-query parallelism deadlock and the accessing objects in different orders deadlock.
Bookmark lookup deadlock
Bookmark lookup deadlocks are one of the most common deadlocks in SQL Server. Fortunately, although they have a habit of appearing randomly, without any changes to the database or the code inside of it, they are also one of the easiest types of deadlock to troubleshoot.
Bookmark lookup deadlocks generally have a SELECT statement as the victim, and an INSERT, UPDATE, or DELETE statement as the other contributing process to the deadlock. They occur partly as a general consequence of SQL Server’s pessimistic locking mechanisms for concurrency, but mainly due to the lack of an appropriate covering index for the SELECT operation.
When a column is used in the WHERE clause to filter the SELECT statement and a non-clustered index exists on that column, then the database engine takes a shared lock on the required rows or pages in the non-clustered index. In order to return any additional columns from the table, not covered by the non-clustered index, the database engine performs an operation known as KEY, or RID, lookup (in SQL Server 2000, the term “bookmark lookup” was used). This operation uses either the Clustered Index Key or RID (in the case of a heap) to look up the row in the table data and retrieve the additional columns.
When a lookup operation occurs, the database engine takes additional shared locks on the rows or pages needed from the table. These locks are held for the duration of the SELECT operation, or until lock escalation is triggered to increase the lock granularity from row or page to table.
The deadlock occurs, as we have seen in previous sections, when an operation that changes the data in a table (for example, an INSERT, UPDATE, or DELETE operation) occurs simultaneously with the SELECT. When the data-changing session executes, it acquires an exclusive lock on the row or page of the clustered index or table, and performs the data change operation. At the same time the SELECT operation acquires a shared lock on the non-clustered index. The data-changing operation requires an exclusive lock on the non-clustered index to complete the modification, and the SELECT operation requires a shared lock on the clustered index, or table, to perform the bookmark lookup. Shared locks and exclusive locks are incompatible, so if the data-changing operation and the SELECT operation affect the same rows then the data-changing operation will be blocked by the SELECT, and the SELECT will be blocked by the data change, resulting in a deadlock.
One of the most common online recommendations for curing this type of deadlock is to use a NOLOCK table hint in the SELECT statement, to prevent it from acquiring shared locks. This is bad advice. While it might prevent the deadlock, it can have unwanted side effects, such as allowing operations to read uncommitted changes to the database data, and so return inaccurate results.
The correct fix for this type of deadlock is to change the definition of the non-clustered index so that it contains, either as additional key columns or as INCLUDE columns, all the columns it needs to cover the query. Columns returned by the query that are not used in a JOIN, WHERE, or GROUP BY clause, can be added to the index as INCLUDE columns. Any column used in a JOIN, the WHERE clause, or in a GROUP BY should ideally be a part of the index key but, in circumstances where this exceeds the 900-byte limit, addition as an INCLUDE column may work as well. Implementing the covering index will resolve the deadlock without the unexpected side effects of using NOLOCK.
A shortcut to finding the appropriate covering index for a query is to run it through the Database Engine Tuning Advisor (DTA). However, the DTA recommendations are only as good as the supplied workload, and repeated single-query evaluations against the same database can result in an excessive number of indexes, which often overlap. Manual review of any index recommendation made by the DTA should be made to determine if modification of an existing index can cover the query without creating a new index.
Range scans caused by SERIALIZABLE isolation
The SERIALIZABLE isolation level is the most restrictive isolation level in SQL Server for concurrency control, ensuring that every transaction is completely isolated from the effects of any other transaction.
To accomplish this level of transactional isolation, range locks are used when reading data, in place of the row or page level locking used under READ COMMITTED isolation. These range locks ensure that no data changes can occur that affect the result set, allowing the operation to be repeated inside the same transaction with the same result. While the default isolation level for SQL Server is READ COMMITTED, certain providers, like COM+ and BizTalk, change the isolation to SERIALIZABLE when connections are made.
Range locks have two components associated with their names, the lock type used to lock the range and then the lock type used for locking the individual rows within the range. The four most common range locks are shared-shared (RangeS-S), shared-update (RangeS-U), insert-null (RangeI-N), and exclusive (RangeX-X). Deadlocks associated with SERIALIZABLE isolation are generally caused by lock conversion, where a lock of higher compatibility, such as a RangeS-S or RangeS-U lock, needs to be converted to a lock of lower compatibility, such as a RangeI-N or RangeX-X lock.
A common deadlock that occurs under SERIALIZABLE isolation has a pattern that involves a transaction that checks if a row exists in a table before inserting or updating the data in the table. A reproducible example of this deadlock is included in the code examples for this article. This type of deadlock will generally produce a deadlock graph with a resource-list similar to the one shown in Listing 13.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<resource-list> <keylock hobtid="72057594050969600" dbid="5" objectname="AdventureWorks.Sales.SalesOrderHeader" indexname="IX_SalesOrderHeader_CustomerID" id="lock35bcc80"" mode="RangeS-U" associatedObjectId="72057594050969600"> <owner-list> <owner id="processad4d2e8""" mode="RangeS-U" /> <owner id="process9595b8""" mode="RangeS-S" /> </owner-list> <waiter-list> <waiter id="processad4d2e8""" mode="RangeI-N" requestType="convert" /> <waiter id="process9595b8""" mode="RangeI-N" requestType="convert" /> </waiter-list> </keylock> </resource-list> |
Listing 13: Extract from a deadlock graph for a SERIALIZABLE range scan deadlock.
In this example, two processes have acquired compatible shared locks, RangeS-S and RangeS-U, on the SalesOrderHeader table. When one of the processes requires a lock conversion to a lock type that is incompatible with the lock being held by the other process, in this case a RangeI-N, it is blocked. If both processes require a lock conversion to RangeI-N locks, the result is a deadlock since each session is waiting on the other to release its high compatibility lock.
There are several possible solutions to this type of deadlock and the most appropriate one depends on the database and the application it supports. If it is not necessary for the database to maintain the range locks acquired during the SELECT operation that checks for row existence and the SELECT operation can be moved outside of the transaction that performs the data change, then the deadlock can be prevented.
If the operation doesn’t require the use of SERIALIZABLE isolation, then changing the isolation level to a less restrictive isolation level, for example READ COMMITTED, will prevent the deadlock and allow a greater degree of concurrency.
If neither of these solutions is appropriate, the deadlock can be resolved by forcing the SELECT statement to use a lower-compatibility lock, through the use of an UPDLOCK or XLOCK table hint. This will block any other transactions attempting to acquire locks of higher compatibility. This fix is specific to this particular type of deadlock due to the usage of SERIALIZABLE isolation. Using UPDLOCK hints under READ COMMITTED may result in deadlocks occurring more frequently under certain circumstances.
Cascading constraint deadlocks
Cascading constraint deadlocks are generally very similar to a Serializable Range Scan deadlock, even though the isolation level under which the victim transaction was running isn’t SERIALIZABLE. To enforce cascading constraints, SQL Server has to traverse the FOREIGN KEY hierarchy to ensure that orphaned child records are not left behind, as the result of an UPDATE or DELETE operation to a parent table. To do this requires that the transaction that modifies the parent table be isolated from the effects of other transactions, in order to prevent a change that would violate FOREIGN KEY constraints, when the cascade operation subsequently completes.
Under the default READ COMMITTED isolation, the database engine would acquire and hold, for the duration of the transaction, Exclusive locks on all rows that had to be changed. This blocks users from reading or changing the affected rows, but it doesn’t prevent another session from adding a new row into a child table for the parent key being deleted. To prevent this from occurring, the database engine acquires and holds range locks, which block the addition of new rows into the range affected by the cascading operation. This is essentially an under-the-cover use of SERIALIZABLE isolation, during the enforcement of the cascading constraint, but the isolation level for the batch is not actually changed; only the type of locks used for the cascading operation are changed.
When a deadlock occurs during a cascading operation, the first thing to look for is whether or not non-clustered indexes exist for the FOREIGN KEY columns that are used. If appropriate indexes on the FOREIGN KEY columns do not exist, the locks being taken to enforce the constraints will be held for longer periods of time, increasing the likelihood of a deadlock between two operations, if a lock conversion occurs.
Intra-query parallelism deadlocks
An intra-query parallelism deadlock occurs when a single session executes a query that runs with parallelism, and deadlocks itself. Unlike other deadlocks in SQL Server, these deadlocks may actually be caused by a bug in the SQL Server parallelism synchronization code, rather than any problem with the database or application design. Since there are risks associated with fixing some bugs, it may be that the bug is known and won’t be fixed, since it is possible to work around it by reducing the degree of parallelism for that the query, using the MAXDOP query hint, or by adding or changing indexes to reduce the cost of the query or make it more efficient.
The deadlock graph for a parallelism deadlock will have the same SPID for all of the processes, and will have more than two processes in the process-list. The resource-list will have threadpool, exchangeEvent, or both, listed as resources, but it won’t have lock resources associated with it. In addition, the deadlock graph for this type of deadlock will be significantly longer than any other type of deadlock, depending on the degree of parallelism and the number of nodes that existed in the execution plan.
Additional information about this specific type of deadlock can be found on Bart Duncan’s blog post, (Today’s Annoyingly-Unwieldy Term: “Intra-Query Parallel Thread Deadlocks”.
Accessing objects in different orders
One of the easiest deadlocks to create, and consequently one of the easiest to prevent, is caused by accessing objects in a database in different operation orders inside of T-SQL code, inside of transactions, as shown in Listings 14 and 15.
|
1 2 3 4 5 6 7 |
BEGIN TRANSACTION UPDATE TableA SET Column1 = 1 SELECT Column2 FROM TableB |
Listing 14: Transaction1 updates TableA then reads TableB.
|
1 2 3 4 5 6 7 |
BEGIN TRANSACTION UPDATE TableB SET Column2 = 1 SELECT Column1 FROM TableA |
Listing 15: Transaction2 updates TableB then reads TableA.
Transaction1’s UPDATE against TableA will result in an exclusive lock being held on the table until the transaction completes. At the same time, Transaction2 runs an UPDATE against TableB, which also results in an exclusive lock being held until the transaction completes. After completing the UPDATE to TableA, Transaction1 tries to read TableB but is blocked and unable to acquire the necessary shared lock, due to the exclusive lock being held by Transaction2. After completing its UPDATE to TableB, Transaction2 reads TableA and is also blocked, unable to acquire a shared lock due to the exclusive lock held by Transaction1. Since the two transactions are both blocking each other, the result is a deadlock and the Lock Monitor will kill one of the two sessions, rolling back its transaction to allow the other to complete.
When using explicit transactions in code, it is important that objects are always accessed in the same order, to prevent this type of deadlock from occurring.
Handling Deadlocks to Prevent Errors
In most cases, the same issues that cause severe blocking in the database, such as poor database design, lack of indexing, poorly designed queries, inappropriate isolation level and so on, are also the common causes of deadlocking. In most cases, by fixing such issues, we can prevent deadlocks from occurring. Unfortunately, by the time deadlocks become a problem, it may not be possible to make the necessary design changes to correct them.
Therefore, an important part of application and database design is defensive programming; a technique that anticipates and handles exceptions as a part of the general code base for an application or database. Defensive programming to handle deadlock exceptions can be implemented in two different ways:
- database-side, through the use of T-SQL TRY…CATCH blocks
- application-side, through the use of application TRY…CATCH blocks.
In either case, proper handling of the 1205 exception raised by SQL Server for the deadlock victim can help avoid UnhandledException errors in the application and the ensuing end-user phone calls to Help Desk or Support.
T-SQL TRY…CATCH blocks
Depending on how an application is designed, and whether there is separation between application code and database code, the simplest implementation of deadlock error handling could be via the use of BEGIN TRY/CATCH blocks inside of the T-SQL being executed.
This technique is most applicable in cases where an application calls stored procedures for all of its data access. In such cases, changing the code in a stored procedure so that it handles the deadlock exception doesn’t require changes to application code, or recompiling and redistribution of the application. This greatly simplifies the implementation of such changes.
The best way to deal with a deadlock, within your error handling code, will depend on your application and its expected behavior in the event of a deadlock. One way of handling the deadlock would be to retry the transaction a set number of times before actually raising an exception back to the application for handling. The cross-locking situation associated with a deadlock generally only lasts a very short duration, usually timed in milliseconds so, more often than not, a subsequent attempt at executing the T-SQL code selected as a victim will succeed, and there will be no need to raise any exceptions to the application.
However, it is possible that the deadlock will continue to occur, and we need to avoid getting into an infinite loop, attempting repeatedly to execute the same failing code. To prevent this, a variable is used to count down from a maximum number of retry attempts; when zero is reached, an exception will be raised back to the application. This technique is demonstrated in Listing 16.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
DECLARE @retries INT ; SET @retries = 4 ; WHILE ( @retries > 0 ) BEGIN BEGIN TRY BEGIN TRANSACTION ; -- place sql code here SET @retries = 0 ; COMMIT TRANSACTION ; END TRY BEGIN CATCH -- Error is a deadlock IF ( ERROR_NUMBER() = 1205 ) SET @retries = @retries - 1 ; -- Error is not a deadlock ELSE BEGIN DECLARE @ErrorMessage NVARCHAR(4000) ; DECLARE @ErrorSeverity INT ; DECLARE @ErrorState INT ; SELECT @ErrorMessage = ERROR_MESSAGE() , @ErrorSeverity = ERROR_SEVERITY() , @ErrorState = ERROR_STATE() ; -- Re-Raise the Error that caused the problem RAISERROR (@ErrorMessage, -- Message text. @ErrorSeverity, -- Severity. @ErrorState -- State. ) ; SET @retries = 0 ; END IF XACT_STATE() <> 0 ROLLBACK TRANSACTION ; END CATCH ; END ; GO |
Listing 16: TRY…CATCH handling of deadlock exceptions, in T-SQL.
Handling ADO.NET SqlExceptions in .NET code
While it is possible to handle deadlocks in SQL Server 2005 and 2008, using BEGIN TRY and BEGIN CATCH blocks, the same functionality doesn’t exist in SQL Server 2000, and in any event it may not be acceptable to have the database engine retry the operation automatically. In either case, the client application should be coded to handle the deadlock exception that is raised by SQL Server.
There isn’t much difference between the error handling in .NET and the error handling in T-SQL. A TRY…CATCH block is used to execute the SQL call from the application and catch any resulting exception raised by SQL Server. If the code should reattempt the operation in the event of a deadlock, a maximum number of retries should be set by a member variable that is decremented each time a deadlock is encountered.
The example in Listing 17 shows how to catch the SqlException in C#, but can be used as a model to handle deadlocks in other languages as well.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
int retries = 4; while (retries > 0) { try { // place sql code here retries = 0; } catch (SqlException exception) { // exception is a deadlock if (exception.Number == 1205) { // Delay processing to allow retry. Thread.Sleep(500); retries --; } // exception is not a deadlock else { throw; } }} |
Listing 17: TRY…CATCH handling of deadlock exceptions, in C#.
Rather than retrying the operation, it may be desirable to log the exception in the Windows Application Event Log, or perhaps display a MessageBox dialog and determine whether or not to retry the operation, based on user input. These are two examples of how handling the deadlock exception in the application code allows for more flexibility over handling the deadlock in the database engine.
Controlling Deadlock Behavior with Deadlock Priority
There are circumstances (for example, a critical report that performs a long running SELECT that must complete even if it is the ideal deadlock victim) where it may be preferable to specify which process will be chosen as the deadlock victim in the event of a deadlock, rather than let SQL Server decide based purely on the cost of rollback. As demonstrated in Listing 18, SQL Server offers the ability to set, at the session or batch level, a deadlock priority using the SET DEADLOCK PRIORITY option.
|
1 2 3 4 5 6 7 8 9 10 |
-- Set a Low deadlock priority SET DEADLOCK_PRIORITY LOW ; GO -- Set a High deadlock priority SET DEADLOCK_PRIORITY HIGH ; GO -- Set a numeric deadlock priority SET DEADLOCK_PRIORITY 2 ; |
Listing 18: Setting deadlock priority.
A process running in a batch or session with a low deadlock priority will be chosen as the deadlock victim over one that is running with a higher deadlock priority. Like all other SET options in SQL Server, the DEADLOCK PRIORITY is only in effect for the current execution scope. If it is set inside of a stored procedure, then when the stored procedure execution completes, the priority returns to the original priority of the calling execution scope.
Note that SQL Server 2000 offers only two deadlock priorities; Low and Normal. This allows the victim to be determined by setting its priority to Low. SQL Server 2005 and 2008 however, have three named deadlock priorities; Low, Normal, and High, as well as a numeric range from -10 to +10, for fine-tuning the deadlock priority of different operations.
The deadlock priority is set at execution time, and all users have the permission to set a deadlock priority. This can be a problem if users have ad hoc query access to SQL Server, and set their deadlock priority higher than other processes, in order to prevent their own process from being selected as a victim.
Summary
This article has covered how to capture and interpret deadlock graph information in SQL Server to troubleshoot deadlocking. The most common deadlocks have also been covered to provide a foundation for troubleshooting other types of deadlocks that might occur. Most often, deadlocks are the result of a design problem in the database or code that can be fixed to prevent the deadlock from occurring. However, when changes to the database are not possible to resolve the deadlock, adding appropriate error handling in the application code reduces the impact caused by a deadlock occurring. The information included in this article should allow rapid and efficient troubleshooting of most deadlocks in SQL Server.
 If you’ve found this article useful, the full eBook Troubleshooting SQL Server: A Guide for the Accidental DBA is available to download for free for Simple-Talk site members.
If you’ve found this article useful, the full eBook Troubleshooting SQL Server: A Guide for the Accidental DBA is available to download for free for Simple-Talk site members.
FAQs: How to handle deadlocks in SQL Server
1. What is a SQL Server deadlock and how does it differ from blocking?
A deadlock is a circular lock dependency between two or more sessions where neither can proceed – both are waiting for the other to release a lock it holds. SQL Server automatically detects this and kills one session (the deadlock victim) with error 1205. Blocking, by contrast, is one session simply waiting for another to release a lock – it resolves itself when the blocking session finishes. Blocking can persist indefinitely; deadlocks are always resolved automatically by SQL Server.
2. How do I capture deadlock graphs in SQL Server?
The recommended method is Extended Events: create a session that captures the deadlock_graph event and stores results to a target file or ring buffer. For SQL Server 2008+, use the system_health Extended Events session (enabled by default) which captures deadlock graphs automatically – query sys.fn_xe_file_target_read_file to retrieve them. Legacy methods include Trace Flag 1222 (writes to the error log) and SQL Profiler’s XML Deadlock Graph event.
3. What are the most common types of SQL Server deadlocks?
The most common are: bookmark lookup deadlocks (a reader using a non-clustered index key lookup conflicts with a writer on the clustered index – fix by adding covering index); serializable range scan deadlocks (SERIALIZABLE isolation holds range locks that conflict with inserts – fix by changing isolation level or using SNAPSHOT); access-order deadlocks (two sessions access the same tables in different orders – fix by standardising access order); and intra-query parallelism deadlocks (a single session deadlocks itself in a parallel query – fix by limiting DOP or rewriting the query).
4. How do I handle SQL Server deadlock errors in application code?
In T-SQL, use a TRY/CATCH block with XACT_STATE() check to detect error 1205 and implement a retry loop. In .NET/C#, catch SqlException and check for Number == 1205 or Number == 1222 before implementing application-level retry logic. Set DEADLOCK_PRIORITY LOW on lower-priority sessions to ensure they are preferentially chosen as the deadlock victim, protecting more critical transactions. The appropriate retry count and delay between retries depends on the application and deadlock frequency.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments