

DevOps, Continuous Delivery & Database Lifecycle Management
Version Control
Imagine a simple problem. You have created a database application to manage the payroll process for a company. To make it efficient, you have encapsulated quite a lot of the business logic in the database. As always, each company using the software needs alterations to the code to meet their particular local legislative requirements, and so, after a while, the ‘production’ version of the system exists in many subtly-different versions. Then, changes in the regulatory framework require you to alter the basic database system to a new version, and the changes have to be ready for the date that the new regulations come into force. Your customers need to have all their special features retained in the new system. At the same time, you are developing a radically-different cloud-based service, based on the same database design, but with many differences. The timescales are different. You’re using source control, so what could possibly go wrong?
Recognize the problem? If you do, you may agree that you’ll need to plan your branching, merging, and versioning strategies carefully.
Branching and Merging, a brief overview
Every Version Control System (VCS) will allow us to copy a particular file version (or set of files) and use and amend them for a different purpose, without affecting the original files, which is referred to as creating a branch, or fork.
The methods used to implement branching vary from one VCS to the next, but the basic branching concepts apply universally. From the point of view of a user accessing the repository through their working folder, branching is similar to copying a folder and its contents from one file system location to another. Of course, From the VCS’s viewpoint, the branch is usually not a full copy of the files and their histories, but rather pointers to the files’ origins, but the end result is that we two distinct versions of the same folder, and we can modify the contents of each independently.
An example often quoted is where one team is working on new development (e.g. version 2.0) of a project in trunk, while another creates a branch to work on bug fixes for version 1.0. Another example is the need to separate off and stabilize a certain version of the repository for QA testing or customer assessment or similar, while the main development effort continues.
While working in a branch, the VCS tracks all changes made to the branch files (it stores the file deltas within the branch, rather than in the trunk where the files originated). The VCS also knows the exact revision in the origin (trunk, say) from which the branch originated, so it knows how far back to look on each path to gather the information it needs to carry out any subsequent merge operation.
If creating branches is easy, then the flip side of that coin is that, without a lot of care, the subsequent merge operation, bringing the branch and origin streams back together, can be painful and time consuming. The team will need to resolve any merge conflicts that result from a change to a file in the branch that is incompatible with a change to equivalent file in the origin. As well as causing merge conflicts, branching can also delay integration testing, and so can delay finding functional problems, where two changes that are not in the same file and thus are not flagged as a conflict, are incompatible with each other and cause a bug upon merging.
The more branches diverge, and the longer the period between merging, the greater the likelihood of conflict and bugs.
Physical Branching and Merging Strategies
Physical branching and merging strategies vary greatly from team to team, according to the project, the VCS, and the overarching deployment and product lifecycle strategies.
In small projects, with few developers, many teams work almost exclusively in the trunk (or a dedicated ‘mainline’ development branch), creating other branches only when strictly necessary. With everyone working in the same repository location, the team will have to deal with any potentially conflicting changes caused by concurrent modification of the same file. The developer who sees the merge conflict will need to merge the repository’s version of a branch or the trunk, with the local version of the same branch or trunk.
On bigger projects, with more developers, such an approach can result in lower productivity, as well as irregular and delayed deployments, as team members end up a) dealing with more conflicting changes, and b) waiting for others to complete their work before they can proceed. With this comes the increasing need to optimize concurrent development by separating out each of the various strands of the development effort into a dedicated branch. The potential downside is that, when it comes time to merge, the team may need to merge in a lot of files that have changed both in the origin and in their branch, merging manually all these changes that the VCS can’t handle automatically.
Branch when needed (release branches)
A common strategy is to create a branch only as required, typically as the team approach a release, and the team need to deploy to Quality Assurance (QA) for testing, for example.
During the project development phase, all members of the team work on a single, dedicated development branch (often referred to as “mainline”). When all of their development and testing is complete, they merge the changes into a release branch. The team deploy to QA from the release branch, fix bugs that QA reports and address any other outstanding issues, and then merge into “master” (the trunk, in figure 1), tagging the release and deploying to production. The idea is that ‘master’ is always in a production-ready state. After deployment the team might continue to use the release branch for ongoing maintenance, or create another ‘hotfixes’ branch specifically for that purpose.
In the meantime, development continues in the development branch in preparation for the next release. During the QA process, the team might wish to merge into the development branch the bug fixes on the release branch, either at regular intervals or when the product is ready for release. It may also be necessary to merge bug fixes from mainline to the release branch.
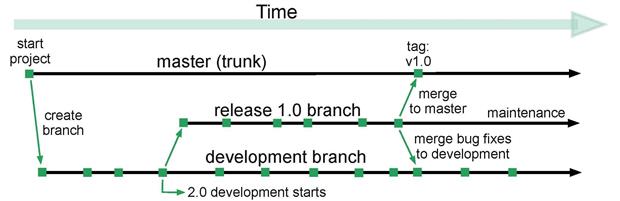
Figure 1: Using a release branch to test and refine an application.
Release braches solve certain issues towards the end of a development cycle and the merging process is generally fairly straightforward, largely involving merging single bug fixes.
Ultimately, though, while having a single branch for development makes the VCS processes rather straightforward, it can lead to delays in deployment. No matter how carefully team break down a given feature into a series of small, incremental changes, some features take longer to develop than others, and notionally the team can deploy only when all planned features for that release are complete, unless they start trying to “cherry pick” which changes to merge between branches, which can get messy quickly.
Another problem that can arise is that all features are ready to go except one which has thrown up unexpected difficulties, and management decides to release the product without the errant feature. One option, although again it’s not ideal, is to create a temporary branch that contains all features except the errant one, and deploy from the temporary branch to QA/Staging/Production. Once v2.0 is complete, the team can merge to master and remove the temporary branch. A better option, and the norm in a third-generation VCS, is to create a specific feature branch for any “long-running” feature and not merge it into master for deployment until it is ready.
Typically, when the team start “cherry picking” commits or creating temporary branches, it’s an indicator of a broader problem in their development process. The team may need to consider refining their branching strategy to separate more cleanly the various strands of development For example, they could create a separate branch for release patching, and a separate branch for major feature. This is a strategy we call “feature and release branching.”
Feature and release branching
A popular approach within development teams who work to shorter, more frequent release cycles, is to create feature braches in addition to release branches. The team creates temporary branches to develop specific product features, rolling out one branch per feature, or “user story,” so that they can develop each one in isolation, without causing instability in the development branch, or allowing any single development effort to disrupt the nightly build process.
When that feature is complete and fully tested, the team can merge the feature into the development branch, from where they can incorporate it into the development and QA processes. Figure 2 illustrates one example of feature branching with multiple active features, none of which will affect the main line of development.
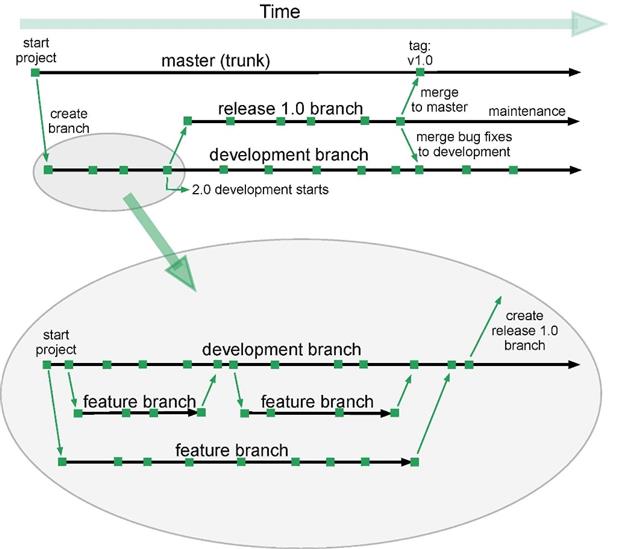
Figure 2: Implementing feature branches to isolate development strands.
Use of feature branches, with a dedicated purpose for each branch, allows for a consistent deployment strategy for every release, and it allows “maximum concurrency” in the team’s development efforts. Ultimately, one may arrive at a rather expansive branching and merging scheme, such as the one described in Vincent Driessen’s article, A successful Git branching model.
As you can imagine, however, such a strategy also requires very strict discipline with regard to the subsequent merging processes. The last thing you want is for a stored procedure to get updated in the release branch, but never have the update make it back to the development branch.
The ‘hidden’ risk of feature branching is that a lot of code can sit in the feature branch, unintegrated, for longer than intended, and will cause bugs, as well as merge conflicts, when they eventually do get merged into mainline. The team needs to employ the principles of continuous integration to ensure they avoid such difficulties. This means performing frequent merges from mainline to branch to “update” the branch with any changes made in mainline development so the two strands don’t drift too far apart, and also frequently merging small, tested changes from branch to mainline.
Third generation version control systems such as mercurial and git treat branching and merging as a very natural part of the source control process, and many teams use this strategy successfully. Also, several of the more advanced Continuous Integration servers (Bamboo and Team City, for example) have features to automate regular merging operations.
However, even with strict discipline, it is inevitable that occasionally, when a completed feature merges to origin, it will cause significant disruption to the developers working in origin, a situation referred to as a “merge ambush”.
Logical Branching and Feature Toggles
With physical feature branching, we isolate in its own branch a large-scale or complex change to a component, or a fix to a difficult bug, so that other developers can continue to work undisturbed on “mainline”, and so that it doesn’t disrupt the established build cycle. One of the major drawbacks of this approach is that it runs counter the fundamental principles of Continuous Integration, where we are supposed to make frequent, small changes that we integrate constantly with the work of others.
When working in a branch there is a strong risk of isolating changes for too long, and then causing mass disruption when the merge ambush eventually arrives. It also discourages other good behavior. For example, if a developer is fixing a bug in a branch and spots an opportunity to do some general refactoring to improve the efficiency of the code, the thought of the additional merge pain may dissuade them from acting.
Over recent years, an increasingly popular approach is to do all development in “mainline” (called trunk-based development), creating branches only for releases. Instead of creating feature branches, the team use logical branching, by introducing abstraction layers. In short, instead of isolating the development of a new version of a feature in a branch, the new and the old version exist side by side in mainline, behind an abstraction layer.
Let’s say that many client components in our code base call the component we wish to refactor. In this approach, we write a simple abstraction layer, so that just one client communicates entirely through that abstraction layer. Step by step, we expand the layer so that all dependent clients call it, rather than the underlying component. We then write the new version of the component test it and then, step by step, we switch each client over to the refactored components, still via the abstraction layer. In this manner, we reestablish the principles of small, incremental changes, with continuous integration, and we avoid the potential pain of merging. Of course, such as scheme will be relatively easy to implement for any application designed with good object-oriented principles in mind, where good abstraction layers will likely already exist.
If we wish to introduce a new feature that will take longer to develop than our established deployment cycle, rather than push it out to a branch we hide it behind a feature toggle within the application code. We maintain a configuration file that determines whether a feature is on or off. We then write conditional statements around the new feature that prevents it from running until enabled by the ‘switch’ in the configuration file. It means the team can deploy these unfinished features alongside the completed ones, and so avoid having to deployment till the new feature is complete.
Of course, there are some potential downsides to the approach. If a team gleefully implements hundreds of fine-grained feature toggles, it could quickly create maintenance problems in the code. It’s advisable to keep each toggle coarse-grained, and the number of live toggles in single figures.
Also, it does have the fundamental problem that the whole team are committing to trunk, and so the likelihood of “toe stepping” and conflict increases. While teams at the likes of Google and Microsoft might be able to coordinate “TBD at scale“, with thousands of commits to mainline in a day, most teams might find progress hampered with teams larger than a few tens of developers.
Logical Branching and the database
A database can have a variety of relationships with applications, from almost total integration within the data layer of the application, to being a remote server providing data services via a protocol such as the Open Data Protocol (OData). Commonly in enterprises, a single database will provide services to a number of applications, and provide integration, and reporting services, for them, via abstraction layers provided for each application, within the database.
It means that there will be a number of perfectly valid approaches to managing the change process. At one extreme, the database sits in an entirely separate development regime, sometimes not even subject to the same version control, test and build processes as the application. At the other, the database code is treated on equal terms in source control to the rest of the code, settings and materials of the application.
If the ‘modus operandi’ for the delivery process hasn’t been planned properly, and changes span both the application and the database, the subsequent ‘big bang’ integration between application and database changes can be painful and time-consuming . This, along with deploying the new versions of database and application to QA for testing, then on to the operations team for deployment to Staging and then, finally to Production, forms part of the infamous “last mile” that can delay releases interminably.
Both the Continuous Delivery and Dev-ops movements share a goal in ”integrating early, and automating and refining the deployment process to the point where they can deliver early and often to a “production-like” environment, spotting and fixing possible issues much earlier in the project lifecycle.
Where database and application are close-coupled, it is necessary to adopt a unified approach to the development and deployment of both application and database, and therefore a unified strategy for versioning a project, with all project resources organized side by side in the same repository. Of course, often this means little more than creating a directory for the database alongside the application, in the VCS, evolving the structure of the database rapidly alongside the application, with the necessary branching and merging, as their understanding of the problem domain evolves. For a relational database of any size, with complex object interdependencies, this can prove challenging, especially given that when the team need to upgrade an existing database with what’s in the VCS, then every database refactoring needs to be described in a way that will carefully preserve all business data.
Rather than creating physical branches, meaning more different versions of the database in the VCS, the logical branching model is conceptually a much better fit for database development in many ways. However, of course, logical branching and trunk-based development model will only work if the database is subject to the same careful design principles, and levels of abstraction, as the application.
The following sections discuss practices that are required for successful logical branching, and will make working with the database in VCS much simpler regardless of the branching strategy.
Published application-database interface
Each application should have a stable, well-defined interface with the database (one for each application, usually, if more than one application uses a single database).
The application development team owns the interface definition, which should be stored in the VCS. It form a contract that determines, for example, what parameters need to supplies, what data is expected back and in what form.
The database developers implement the interface, also stored in the VCS. Database developers and application developers must carefully track and negotiate any changes to the interface. Changes in it have to be subject to change-control procedures, as they will require a chain of tests. The database developers will, of course, maintain their own source control for the database “internals,” and will be likely to maintain versions for all major releases. However, this will not need to be shared with the associated applications. An application version should be coupled to an application-database interface version, rather than to a database version.
If, for example, the database developer role wishes to refactor schema must, he or she must do so without changing the public interface, at least until the application is ready to move to a new version, at which point the team can negotiate an interface update.
Abstraction in the database
A good interface implementation will never expose the inner workings of the database to the application, and will therefore provide the necessary level of abstraction. Regardless of the exact branching strategy, a team that creates an application that makes direct access to base tables in a database will have to put a lot of energy into keeping database and application in sync (to say nothing of having to tackle issues such as security and audit). When using physical “feature and release” branching, this issue will only worsen, the more branches we maintain and the more versions of the database we have in the VCS.
Relational databases have become increasingly adept at providing abstractions, but it has always been possible. ODBC itself has always provided one of the most remarkable abstractions of a database. This enables a data source ranging in complexity from a directory of text files to a SQL Server database to present itself as a SQL database with a standard syntax. It provides a highly predictable application programming interface (API) for developing applications and queries that are decoupled from the backend database. However, it can only deal with tables and views. Calls to routines are just passed through, rather than being dealt with by the abstraction layer.
Logical branching, and trunk-based development, for the database requires us to abstract the base tables using various routines, such as stored procedures and functions, as well as views. By creating such an abstraction layer, we decouple database and application deployments, to some extent. As long as the published interface remains unchanged, we can test and “dark launch” database changes, such as adding a new table or column, ahead of time, and then adapt the application to benefit from the change at a later point.
Use of Schemas
Trunk-based development of procedural applications is done quite differently from the database. In SQL Server, use of schemas, and the permission system, is the obvious way of doing this. Features within a SQL database are only visible to those users who have the necessary permissions. This means that the hiding of features is extremely easy, merely by means of changing permissions.
Schemas group together database objects that support each logical area of the application’s functionality. Ideally, the VCS structure for the database will reflect the schema structure, in the same way that C# code can be saved in namespaces. This will make it easier to break down the development work per logical area of the database, and minimize interference when all developers are committing to trunk. With physical branching, it is also likely to make the subsequent merging processes less painful.
It is even possible, via the use of schemas, to maintain a whole series of interfaces, being collections of views, procedures and functions, each representing an interface, and each version of the interface with the same names for its component routines. Versions can then be switched merely by changing the default schema for the user, and to give them permission for the schema. This requires them to not specify the schema of the interface routine they access if they use the four-part naming convention.
Schemas bring other benefits too that include the ability to provide namespaces and to implement simple but robust security using database roles and ownership chaining.
In the highly-simplified representation shown below, the dbo schema houses the base tables, but the Payroll application client accesses the PayrollA schema by default. This schema contains the views, stored procedures and functions that it needs to access only the necessary data. Where a parameter is required to specify the data, then a table-valued function is an important feature (though in this case it is important to provide the table with a primary key and UNIQUE constraints to provide performance). The three different types of routines together can provide an abstraction layer.
In this example, dbo owns the interface objects, and they are placed in the PayrollA schema. Because members of the PayrollA database role are assigned execute permissions on the PayrollA schema, permission to use the interface objects is assigned to them automatically, and ownership chaining then allows the application access to the actual data.
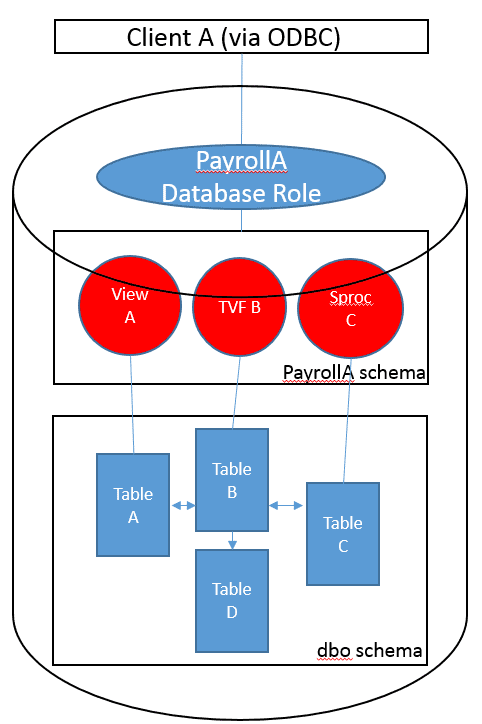
Feature Toggling in the Database
The easiest ‘feature toggling’ device in SQL Server to appreciate and use is the proxy stored procedure. This is a stored procedure that merely calls the real, current stored procedure, passing the parameters, converted if necessary.
Let’s say that at some point we need to split TableC, moving columns, and maybe adding new ones. However, we cannot at this stage touch the interface definition, as the Payroll client is not ready to upgrade. Instead we create a new stored procedure that will access TableC. The existing stored procedure (SprocC) simply becomes a proxy that calls the new stored procedure.
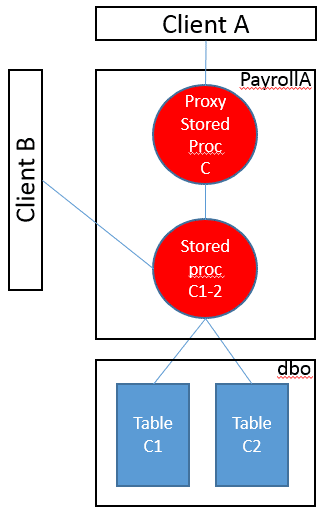
We can then split the tables without affecting the client in any way. The new stored procedure (C1-2) would would have to ‘filter’ data to pass it into C in the form it expects. However, it could also supply all the data, including new columns, to another client that had already been updated appropriately.
As the actual metadata changes as the database evolves, the changes are entirely hidden from the user. As far as the user is concerned, if the proxy provides the right results across the range of parameters allowed, it is correct for the application and nothing breaks, even though there may be considerable changes in the database itself.
Synonyms for abstraction in the database?
A simple, schema-based way of providing an abstraction for a database object might be to use synonyms (see, for example, Using Synonyms in SQL Server 2005). SQL Server verifies the bindings between a synonym and its base object at runtime, not design time, so if we access a table via a synonym, we can refactor (e.g. rename) that table and then just change the synonym to point to the new version, as soon as it’s ready, and the change is instant. Of course, it would mean clients would reference all objects by one-part synonyms, which could cause confusion. We’d only recommend synonyms as a possible option for particularly large, ‘unstable’ tables, subject to frequent refactoring.
The advantage to the application developer of a proxy is that it means that this can be emulated for testing on the developer’s machine via LocalDB or SQL Server Express, with reduced test data. A simple change in connection string will allow testing without any artificial mocks of the database. The tactical advantage for the development process is that the procedure decouples application development from database development.
What use is all this? I just want a data repository
Returning to our initial example, we had a payroll system that originally just served as a database for an application. When it was a single application, it could have had a single interface with the application, as we’ve described. However, it was faced with having to amend the basic logic of the database to deal with individual client sites, because of the prevailing local payroll legislation. A ‘branch-less’ development can be done easily in these circumstances by creating a schema-based interface for each ‘diverging’ client. This would be in the database build but visible, and accessible, only by that particular client. The permission system deals with that. Even where alterations are done on the client site, these can be fed back into source control since they will be within the client’s schema. In effect, each of site-specific schema become, from the logical standpoint, an application.
By having this ‘abstraction layer’ in the payroll database, the database can be radically reorganized whilst maintaining the same interface with the application(s). The schedule of the database development can effectively be decoupled from that of the application. As long as the integration tests can be successfully run against each interface, the team can be confident that nothing will break.
It is even possible, where different versions of the application have to be supported, to have different interfaces for all live versions of the application. Even in this case, it is possible to do development work in the trunk, rather than require branching.

DevOps, Continuous Delivery & Database Lifecycle Management
Go to the Simple Talk library to find more articles, or visit www.red-gate.com/solutions for more information on the benefits of extending DevOps practices to SQL Server databases.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments