
Nikola Ilic, best known as Data Mozart, published a great article and video about how to make semantic model data available in Microsoft Fabric. This allows the data to be used in lakehouses or data warehouses.
One major question that arises is, “should we use a top-down or bottom-up (or both) approach in Microsoft Fabric?” This decision especially affects custom projects built for large corporations.
What’s Top-down approach?
Top-down is the name we use for the traditional and old centralized approach. A team of data engineers uses ETL to create a centralized data intelligence repository. After the repository is ready, the data is distributed across the company using data marts and semantic models.
That’s why we use the name top-down. It starts from the top hierarchy of the company, centralizing all the data. After that, the data is distributed among the company departments.
The problem with the top-down approach is often the lack of enough time and work force to handle all departmental reporting needs. The result ends up covering the needs of the top executives of the company, but leaving behind the regional needs.
Bottom-Up Approach
Bottom-up is the approach intended to work around the limitations of the top-down. While the company implements the top-down approach, each department needs to manage its data and BI needs on its own.
 Each department builds its own BI/data intelligence solution, known as the bottom-up approach.
Each department builds its own BI/data intelligence solution, known as the bottom-up approach.
There are many typical problems with the bottom-up approach. Here are some of them:
- It creates data silos. Pieces of isolated data intelligence spread among the company
- Data and work may be duplicated. Different departments may have overlap of data needs and end up duplicating pieces of data.
- The data may be questionable and not trustworthy. The tight focus on the department’s needs may create untrustworthy data.
- The modeling may be questionable. The data intelligence modelling should be different than the source production database modelling. It should have a historical focus, avoiding common workarounds in source data. Usually we can’t achieve this this better modelling while using a tight departmental focus.
How to choose the best approach
If you check in detail the problems of both approaches, you may notice they complement each other. When used together, they become a complete data reporting scenario for a company.
The top-down approach creates a well-modelled, trustworthy central repository provided to the benefit of the entire company. The Self-Service features allow each department to consume the well-modelled data from the central repository and join it with their own local data.
On the other hand, the bottom-up approach allows the departments to cover for their local needs. This therefore creates a workaround for the lack of a centralized workforce by empowering departments to .
In this way, both approaches should and will almost always be present in large corporations.
The Evolution of the Bottom-Up
Considering both approaches living together, should the bottom-up approach evolve in some way, or should it always be kept as bottom up?
The centralized workforce building the top-down approach only leaves some local information behind because of priorities. It doesn’t mean the local data is not on their task list, it only means it’s lower on their task list. The department, on the other hand, can’t wait; in this way, the bottom-up implementation is used to fill the gap.
I imagine two possibilities for the bottom-up implementation:
- The centralized workforce’s priority list will move until it reaches that implementation. The centralized workforce will use the effort of the departmental workforce, transform their local implementation, and integrate with the centralized one.
In this way, what was once a bottom-up implementation becomes a new part of a top-down implementation, with an increase in the data quality and additional benefits for the business, while still allowing self-service.
- The second possibility is the departmental data, being so specific to the department, has no value to include it in the centralized data intelligence system. In many cases, the bottom-up implementation will live by itself as a self-service implementation, never being integrated into the central repository.
Semantic Model available in OneLake
This new feature is very interesting from a technical point of view: We can mirror the semantic model data in OneLake and make it available to lakehouses and data warehouses. For more information, read this blog from Markus Cozowicz at Microsoft, and my recent blog on the subject here. However, considering the architecture as a whole and what we know about top-down and bottom-up, this practice can make managing both styles of reporting projects tricky.
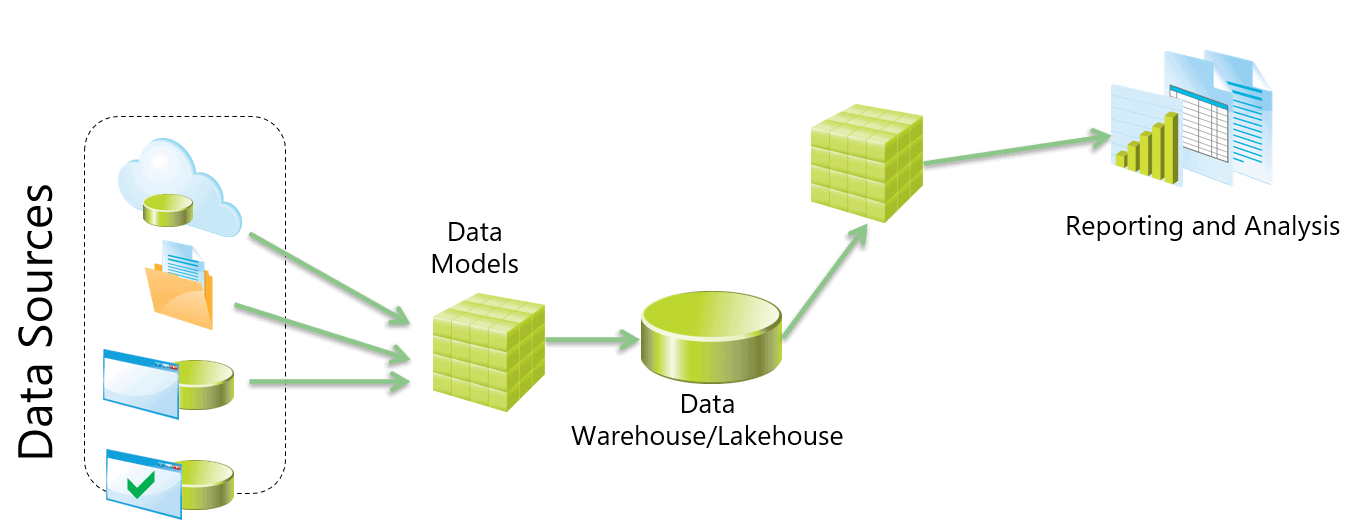
The top-down architecture usually has the following flow of data:
Sources – > Centralization (lakehouse or data warehouse) -> Data Marts -> Semantic Models
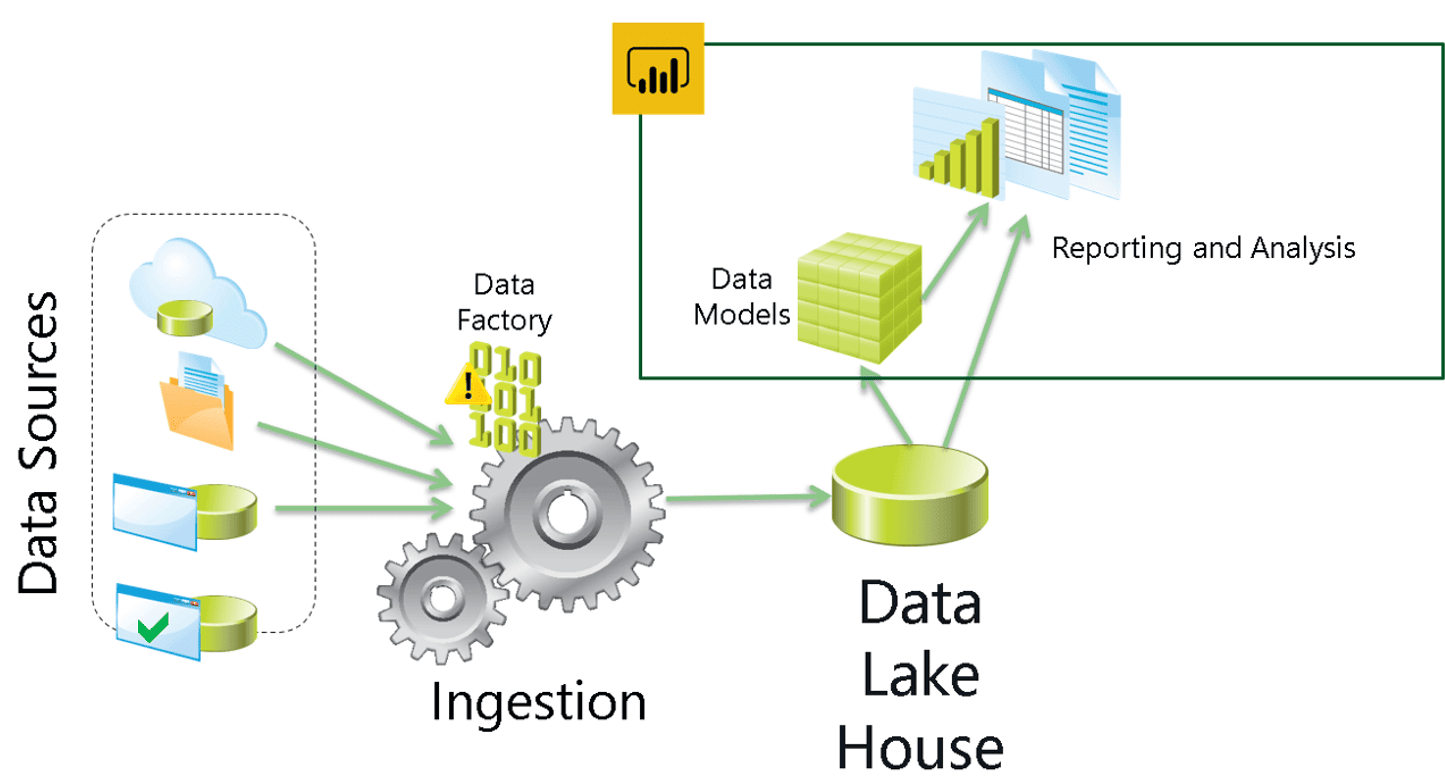
The semantic model access on OneLake makes possible a bottom-up architecture with the following sequence:
Sources -> Semantic Model -> Lakehouse -> Data Marts -> Semantic Models
Considerations about the Bottom-Up using shortcuts to Semantic Model
Let’s analyze some considerations about this new possibility explained by DataMozart for bottom-up implementation in the article noted earlier.
| Reasons to use it | Reasons not to use it |
|
|
|
|
|
|
There are scenarios to use the bottom up method, and there are definitely scenarios to not use this method when you start to employ the semantic model in Fabric. I would mostly use as a temporary workaround to avoid remaking something which is ready, accepting the risk the temporary will become a long living technical debt.
For certain, I would not suggest it to be used it for a completely new solution.
Lakehouses everywhere
Fabric is already available. Why bottom-up implementations should continue to use semantic models reading from production sources, which was already a not recommended practice before?
In my opinion, the Fabric knowledge should be spread in the company to every department with the potential to build a bottom-up solution. In this way the department could start their bottom-up work from a departmental lakehouse.
Check the benefits:
- The department would have a centralized model from the lakehouse, instead of duplicating work in multiple semantic models, what usually happens. This brings business benefits to the scenario.
- The future integration between the bottom-up and top-down solutions will be easier because it will be an integration between two lakehouses.
Data Intelligence future: Data Mesh
If you don’t Know about Data Mesh yet, you should read about it:
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
- Data Mesh Principles and Logical Architecture
I will not make a thoroughly explanation about Data Mesh, this is a subject for another article. But we can simplify it in one definition: It’s the architecture for building multiple single sources of truth.
Microsoft Fabric and Data Mesh are a perfect match because Fabric provides all the technology needs for a Data Mesh implementation. Besides that, Data Mesh is very closely related with the idea of a bottom-up architecture using lakehouses.
If you don’t know Data Mesh yet, keep an eye on it. I will be delivering a session about Data Mesh with Fabric on the Power BI Summit and later publish an article about it.
Summary
How to implement your Fabric architecture is an interesting question. In this article I have covered what top-down and bottom-up means for your Fabric architecture and how it may need to change if you plan to use the Semantic Model feature. The semantic model availability in OneLake is a very interesting feature from the technical point of view and from the architectural point of view, but it is important that it is correctly used or you may end up with less than adequate results.
I already found people asking about the future of the data engineering profession, considering the features are now easily accessible by everyone in Microsoft Fabric. However, making the correct architectural decisions and coordinating all the processes necessary to come close to the ever important source of truth (especially when you need multiple sources of truth to actually be true) is something you are going to need a data engineer to do for many years to come.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments