
1. Introduction
When a critical report which used to complete very quickly starts performing poorly, there is a big chance that the generic reason for this time response degradation is due to a change in an execution plan. If you want to avoid this flip-flop on plan and execution time you have at your disposal a feature called SQL Plan Management (SPM) which, starting from Oracle 11g release and up, allows you to freeze the ‘’good” plan stabilizing as such your report execution time. In this article I’ll explain the basic concepts of SPM.
I said that you can fix the ‘’good’’ plan into a SPM baseline to avoid surprising response time during the report execution time. This is true provided the plan stored into a SPM baseline is still reproducible during the report execution time and there are many reasons that make an SPM plan non reproducible which I’ll tell you about in the second part of this article.
Inevitably we are not going to present all of the ‘’disturbing’’ situations which might lead to a non-reproducible SPM plan but we will certainly open a door for other possible investigations in how the Cost Based Optimizer (CBO) manage to reproduce a SPM plan; particularly when it comes to the CBO and to the NLS environment parameters used during the SPM plan capture and the ones used during the report execution time.
2. The model as preamble
This is the table and the index I will be using to demonstrate the interaction between the CBO and a SPM baseline
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
SQL> CREATE TABLE t_range ( ID NUMBER NOT NULL, X VARCHAR2(30 CHAR) NOT NULL, D DATE, C1 NUMBER ) PARTITION BY RANGE (ID) ( PARTITION P_10000 VALUES LESS THAN (10000) , PARTITION P_20000 VALUES LESS THAN (20000) , PARTITION P_30000 VALUES LESS THAN (30000) , PARTITION P_40000 VALUES LESS THAN (40000) , PARTITION P_50000 VALUES LESS THAN (50000) , PARTITION P_60000 VALUES LESS THAN (60000) ); SQL> INSERT INTO t_range VALUES (150, 'First Part', sysdate - 2, 42); SQL> INSERT INTO t_range VALUES (11500, 'Second Part',sysdate + 12, 82 ); SQL> INSERT INTO t_range VALUES (25000, 'Third Part',sysdate + 5, 102); SQL> INSERT INTO t_range VALUES (34000, 'Fourt Part',sysdate -25, 302); SQL> INSERT INTO t_range VALUES (44000, 'Fifth Part',sysdate -1, 525); SQL> INSERT INTO t_range VALUES (53000, 'Sixth Part',sysdate +15, 1000); SQL> create index t_r_i1 on t_range(id, c1); SQL> exec dbms_stats.gather_table_stats(user, 't_range'); SQL> var n1 number; SQL> var n2 number; SQL> exec :n1 := 150 SQL> exec :n2 := 42 SQL> alter session set optimizer_capture_sql_plan_baselines = TRUE; SQL> select * from t_range where id = :n1 and c1 = :n2; SQL> / SQL> alter session set optimizer_capture_sql_plan_baselines = FALSE; |
I have engineered a partitioned table with a composite index against which I issued a query and captured its execution plan into a SPM baseline, so that if executed again, it will, provided nothing has changed in between, be used as a known and fixed plan.
3. CBO and SPM plan interaction
Figure1 here below presents the interaction between the CBO and a SPM plan.
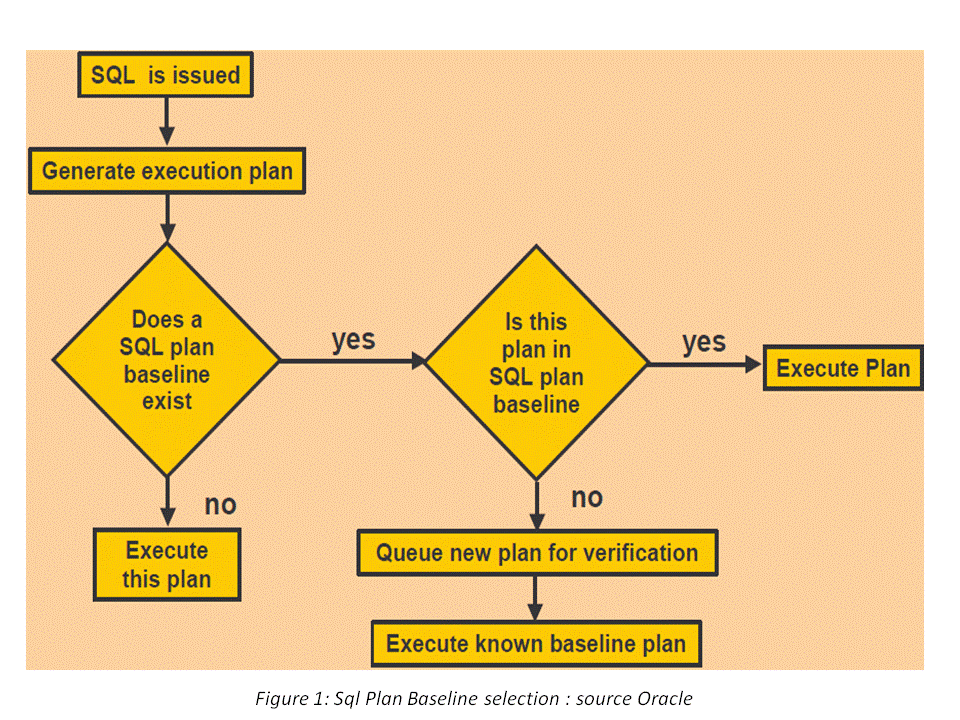
It shows that the CBO will, in the presence or the absence of a SPM baseline, start by optimizing an execution plan for the current SQL query. In reality the 10053 CBO trace file reveals that the CBO will immediately check if the current SQL statement is in an SPM plan or not by means of the following message in the corresponding trace file.
|
1 |
SPM: statement found in SMB |
Having said that, it is only when the plan optimization common task is accomplished that the CBO will embark on the SPM plan reproducibility. If an SPM plan doesn’t exist then the generated plan is used. If an SPM plan does exist the CBO will:
(a) verify if the two execution plans (CBO and SPM plan hash value 2) match
(b) ensure that the SPM plan is reproducible
If the cost-based generated plan matches one of the existing SPM plans, the CBO will use the SPM plan without trying to reproduce it. We can see this kind of comment in the corresponding 10053 trace file
|
1 2 |
SPM: cost-based plan found in the plan baseline, planId = 2239163167 SPM: cost-based plan <span style="color: #ff0000;">was successfully matched</span>, planId = 2239163167 |
If the cost-based generated plan doesn’t match one of the existing SPM plans, the CBO will reproduce all enabled and accepted SPM plans and compare their costs. The SPM reproduced plan having the best cost will be the one selected for use. We can see this kind of comment in the corresponding 10053 trace file:
|
1 2 3 4 |
SPM: planId's of plan baseline are: <span style="color: #ff0000;">2239163167</span> 1634389831 SPM: using qksan to reproduce, cost and select accepted plan, SPM: plan reproducibility round 0 (plan outline + session OFE) SPM: using qksan to reproduce accepted plan, planId = 2239163167 |
The CBO is signaling that it is aware of the existence of two plans in the SPM baseline and that it is going to reproduce and to re-cost each of them before choosing the best “costed” one.
This is the reproduction and the re-costing of the first plan:
|
1 2 |
SPM: planId in plan baseline = <span style="color: #ff0000;">2239163167</span>, planId of reproduced plan = 2239163167 SPM: best cost so far = 492.41, current accepted plan cost = 492.409691 |
And this is the reproduction and the re-costing of the second plan:
|
1 2 |
SPM: planId in plan baseline = <span style="color: #ff0000;">1634389831</span>, planId of reproduced plan = 1634389831 SPM: best cost so far = 272.96, current accepted plan cost = 272.961944 |
Since both plans have been reproduced, the CBO will use the second one because of its lower cost (272)
|
1 |
SPM: re-parsing to generate selected accepted plan, planId = <span style="color: #ff0000;">1634389831</span> |
That is, reduced to the bare minimum, how the CBO interacts with the presence of one or several SPM plan baselines. You have noticed that to guarantee plan stability you might pay in return a parsing time penalty. This is particularly true when you have multiple accepted and enabled baselines which enter in a cost competition when the CBO comes up with a different execution plan.
4. SPM plan reproducibility
We saw in the previous section that when the CBO comes up with a plan that doesn’t exist into the SPM baseline this plan will be constrained provided the base lined plans are still reproducible. This is why I am going to tell you few of those reasons that might lead to the non-reproducibility of a baselined plan. I will skip the obvious object absence like dropping an index that has been used during the baseline capture. Consider, for example, the following query on the partitioned table presented in the preamble section:
|
1 |
select * from t_range where id = :n1 and c1 = :n2; |
This query is already constrained and protected against any plan instability by the following “indexed” SPM baseline (see Note below in the code).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
----------------------------------------------------------------------------- SQL_ID ahufs9gr5x2pm, child number 0 ------------------------------------ Plan hash value: 2219242098 ----------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| ----------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 2 (100)| | 1 | TABLE ACCESS BY GLOBAL INDEX ROWID| T_RANGE | 1 | 26 | 2 (0)| |* 2 | INDEX RANGE SCAN | T_R_I1 | 1 | | 1 (0)| ----------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("ID"=:N1 AND "C1"=:N2) Note ----- - SQL plan baseline SQL_PLAN_9q2w8c3tu6407af6ef80e used for this statement |
We can get detailed execution plan of the above plan baseline using the very useful Oracle dbms_xplan package:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SQL> select * from table(dbms_xplan.<span style="color: #ff0000;">display_sql_plan_baseline</span>(plan_name => 'SQL_PLAN_9q2w8c3tu6407af6ef80e')); -------------------------------------------------------------------------------- SQL handle: SQL_9b0b8860f3a31007 SQL text: select * from t_range where id = :n1 and c1 = :n2 -------------------------------------------------------------------------------- -------------------------------------------------------------------------------- Plan name: SQL_PLAN_9q2w8c3tu6407af6ef80e <strong><span style="color: #ff0000;">Plan id: 2943285262</span></strong> Enabled: YES Fixed: NO Accepted: YES Origin: AUTO-CAPTURE -------------------------------------------------------------------------------- Plan hash value: 2219242098 -------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | -------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 27 | 2 (0)| 00:00:01 | | | | 1 | TABLE ACCESS BY GLOBAL INDEX ROWID| T_RANGE | 1 | 27 | 2 (0)| 00:00:01 | ROWID | ROWID | |* 2 | INDEX RANGE SCAN | T_R_I1 | 1 | | 1 (0)| 00:00:01 | | | -------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("ID"=TO_NUMBER(:N1) AND "C1"=TO_NUMBER(:N2)) |
The most important information in this SPM plan is the Plan id. We will see later in this article how crucial this is for the CBO to decide whether to use the plan it comes up with or the plan in the SPM baseline. Put simply, anything that changes the baselined Plan id will make the baseline plan non-reproducible and will make the CBO use its generated plan instead.
When the CBO realizes that the query it’s optimizing is constrained by a SPM plan, it has to ensure that the SPM plan is still reproducible before using it – in case the CBO plan is not found into the SPM baseline of course. For that it will compare the plan_hash_value_2 (phv2) of the reproduced plan with the plan id of the plan in the baseline. If they match then the SPM plan is used. If not then the CBO plan will be used.
Using the script phv2.sql shown below we can get the phv2 of our query which is identified by its sql_id (ahufs9gr5x2pm)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SQL> SELECT p.sql_id ,p.plan_hash_value ,p.child_number ,t.phv2 FROM v$sql_plan p ,xmltable('for $i in /other_xml/info where $i/@type eq "plan_hash_2" return $i' passing xmltype(p.other_xml) columns phv2 number path '/') t WHERE p.sql_id = '&1' and p.other_xml is not null; SQL> @phv2 ahufs9gr5x2pm SQL_ID PLAN_HASH_VALUE CHILD_NUMBER PHV2 ------------- --------------- ------------ ---------- ahufs9gr5x2pm 2219242098 0 2943285262 |
We can point out from the output of the phv2.sql script that our query has one child cursor with the same PHV2 value (2943285262) which is equal to the Plan Id (2943285262) of the SPM plan. And this is why our query has been honored via the stable and known base lined plan.
What would break this situation? A simple answer is: anything that will end up by associating a PHV2 value that is not the same as the Plan Id in the SPM baseline. And this is what I am going to show in the next section
4.1 Renaming the index
If we look at the content of the SPM baseline, we will see that we have only once accepted and enabled plan covering our query (or those with the same force matching signature) as shown below:
|
1 2 3 4 5 |
SQL> select sql_handle,plan_name,accepted, enabled from dba_sql_plan_baselines; SQL_HANDLE PLAN_NAME ACC ENA ------------------------------ ------------------------------ --- --- SQL_9b0b8860f3a31007 SQL_PLAN_9q2w8c3tu6407af6ef80e YES YES |
I am going now to rename the index T_R_I1 to T_R_I2 and execute again the same query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SQL> alter index t_r_i1 rename to t_r_i2; Index altered. SQL> select * from t_range where id = :n1 and c1 = :n2; ----------------------------------------------------------------------------- SQL_ID ahufs9gr5x2pm, child number 0 ------------------------------------- select * from t_range where id = :n1 and c1 = :n2 Plan hash value: 1053159049 ----------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| ----------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 2 (100)| | 1 | TABLE ACCESS BY GLOBAL INDEX ROWID| T_RANGE | 1 | 26 | 2 (0)| |* 2 | INDEX RANGE SCAN | T_R_I2 | 1 | | 1 (0)| ----------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("ID"=:N1 AND "C1"=:N2) |
Spot how the SPM plan is not anymore used. A new enabled and not accepted plan has been queued into the SPM Baseline for future verification:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SQL> select sql_handle,plan_name,accepted, enabled,optimizer_cost from dba_sql_plan_baselines; SQL_HANDLE PLAN_NAME ACC ENA OPTIMIZER_COST ------------------------------ ------------------------------ --- --- -------------- SQL_9b0b8860f3a31007 SQL_PLAN_9q2w8c3tu64076587b2e2 <span style="color: #ff0000;">NO</span> YES 2 SQL_9b0b8860f3a31007 SQL_PLAN_9q2w8c3tu6407af6ef80e YES YES 2 SQL> @phv2 ahufs9gr5x2pm SQL_ID PLAN_HASH_VALUE CHILD_NUMBER PHV2 ------------- --------------- ------------ ---------- ahufs9gr5x2pm 1053159049 0 <span style="color: #ff0000;">1703391970</span> |
The new PHV2 (1703391970) of the CBO produced plan is not equal to the SPM plan Id (2943285262). This explains why our query isn’t being honored anymore via the stored SPM plan thanks to the index name change. That’s pretty strange because when reproducing the plan, Oracle is not using the index name but the index column as it is clearly shown in the SPM plan details obtained using the OUTLINE option:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SQL> select * from table(dbms_xplan.display_sql_plan_baseline(plan_name => 'SQL_PLAN_9q2w8c3tu6407af6ef80e', format => '<span style="color: #ff0000;">OUTLINE</span>')); -------------------------------------------------------------------------------- Outline Data from SMB: /*+ BEGIN_OUTLINE_DATA <span style="color: #ff0000;"> INDEX_RS_ASC(@"SEL$1" "T_RANGE"@"SEL$1" ("T_RANGE"."ID" "T_RANGE"."C1"))</span> OUTLINE_LEAF(@"SEL$1") ALL_ROWS DB_VERSION('11.2.0.3') OPTIMIZER_FEATURES_ENABLE('11.2.0.3') IGNORE_OPTIM_EMBEDDED_HINTS END_OUTLINE_DATA */ -------------------------------------------------------------------------------- |
Despite the fact that the name of the index is not used in the SMB outline, renaming it impeaches the CBO to generate the same Plan Id (PHV2) and hence ceases to use the SPM plan.
4.2 Changing the index type
There are several index types and changing them might influence the reproducibility of the SPM plan. Now, I’ll change my original index type from a simple b-tree index to a locally prefixed index (index that does include the partition key) and re-execute the original query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
SQL> drop index t_r_i2; SQL> create index t_r_i1 on t_range(id,c1) local; SQL> select * from t_range where id = :n1 and c1 = :n2; --------------------------------------------------------------------------------------------------------- SQL_ID ahufs9gr5x2pm, child number 0 ------------------------------------- select * from t_range where id = :n1 and c1 = :n2 Plan hash value: 963134062 -------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | -------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 2 (100)| | | | | 1 | PARTITION RANGE SINGLE | | 1 | 26 | 2 (0)| 00:00:01 | KEY | KEY | | 2 | TABLE ACCESS BY LOCAL INDEX ROWID| T_RANGE | 1 | 26 | 2 (0)| 00:00:01 | KEY | KEY | |* 3 | INDEX RANGE SCAN | T_R_I1 | 1 | | 1 (0)| 00:00:01 | KEY | KEY | -------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - access("ID"=:N1 AND "C1"=:N2) SQL> @phv2 ahufs9gr5x2pm SQL_ID PLAN_HASH_VALUE CHILD_NUMBER PHV2 ------------- --------------- ------------ ---------- ahufs9gr5x2pm 963134062 0 522591432 |
Again changing the index type from a b-tree to a locally partitioned index breaks the SPM Plan Id generation.
There are nevertheless exceptions or particular cases where changing the index type seems to have no influence on the use of a SPM plan. I am going to illustrate two of these exceptions.
4.2.1. Function based index with the same starting columns
Suppose that I will change my initial index from a b-tree index to a function based index by adding a third column at the end of this index as shown below
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
SQL> drop index t_r_i1; SQL> create index t_r_i1 on t_range(id,c1, d desc); SQL> select * from t_range where id = :n1 and c1 = :n2; ----------------------------------------------------------------------------- SQL_ID ahufs9gr5x2pm, child number 0 ------------------------------------- select * from t_range where id = :n1 and c1 = :n2 Plan hash value: 2219242098 -------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | -------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 2 (100)| | | | | 1 | TABLE ACCESS BY GLOBAL INDEX ROWID| T_RANGE | 1 | 26 | 2 (0)| 00:00:01 | ROWID | ROWID | |* 2 | INDEX RANGE SCAN | T_R_I1 | 1 | | 1 (0)| 00:00:01 | | | -------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("ID"=:N1 AND "C1"=:N2) Note ----- - SQL plan baseline SQL_PLAN_9q2w8c3tu6407af6ef80e used for this statement SQL> @phv2 ahufs9gr5x2pm SQL_ID PLAN_HASH_VALUE CHILD_NUMBER PHV2 ------------- --------------- ------------ ---------- ahufs9gr5x2pm 2219242098 0 2943285262 |
This type of change doesn’t impact the base lined plan to be used. This is true only when the indexed columns that serve the SPM plan creation (id, c1) are (a) still in the new index, (b) at the same position and (c) always provided the new index name remain the same as the original one.
4.2.2. Reverse Index
The second particular case of index type change that seems to have no influence on the reproducibility of an indexed SPM plan is the action of reversing an index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
SQL> drop index t_r_i1; SQL> create index t_r_i1 on t_range(id,c1) reverse; SQL> select * from t_range where id = :n1 and c1 = :n2; ----------------------------------------------------------------------------- SQL_ID ahufs9gr5x2pm, child number 0 ------------------------------------- select * from t_range where id = :n1 and c1 = :n2 Plan hash value: 2219242098 -------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | -------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 2 (100)| | | | | 1 | TABLE ACCESS BY GLOBAL INDEX ROWID| T_RANGE | 1 | 26 | 2 (0)| 00:00:01 | ROWID | ROWID | |* 2 | INDEX RANGE SCAN | T_R_I1 | 1 | | 1 (0)| 00:00:01 | | | -------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("ID"=:N1 AND "C1"=:N2) Note ----- - SQL plan baseline SQL_PLAN_9q2w8c3tu6407af6ef80e used for this statement SQL> @phv2 ahufs9gr5x2pm SQL_ID PLAN_HASH_VALUE CHILD_NUMBER PHV2 ------------- --------------- ------------ ---------- ahufs9gr5x2pm 2219242098 0 2943285262 |
There are situations when reversing an index becomes a possible solution or a workaround for a problematic issue. I am not a fan of this operation because, while solving an index block contention in a highly multi-concurrent insert application, reversing an index might introduce several execution time penalties when range scanning it because the indexed values will be dispersed all over the index leaf blocks. This is without mentioning that distributed transactions are unable to use reversed indexes.
The good news (or bad news, it depends) is that reversing an index will not pre-empt an SPM plan using the original non reversed index, to be chosen by the CBO.
4.3 Changing the order of the index columns
We all know how very important the starting columns of an index are. We should always pay a particular attention to place the columns on which an equality predicate is applied at the leading edge of the index. The index column order obviously plays a crucial role into the reproducibility of a SPM plan. Consider the following change in my original index (the index being function based or b-tree) where I added a new column at the beginning of the index:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
SQL> drop index t_r_i1; SQL> create index t_r_i1 on t_range(d,id,c1); SQL> select * from t_range where id = :n1 and c1 = :n2; SQL_ID ahufs9gr5x2pm, child number 0 ------------------------------------- select * from t_range where id = :n1 and c1 = :n2 Plan hash value: 1281183209 -------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | -------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 2 (100)| | | | | 1 | TABLE ACCESS BY GLOBAL INDEX ROWID| T_RANGE | 1 | 26 | 2 (0)| 00:00:01 | ROWID | ROWID | |* 2 | INDEX SKIP SCAN | T_R_I1 | 1 | | 1 (0)| 00:00:01 | | | -------------------------------------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 2 - access("ID"=:N1 AND "C1"=:N2) filter(("ID"=:N1 AND "C1"=:N2)) SQL> @phv2 ahufs9gr5x2pm SQL_ID PLAN_HASH_VALUE CHILD_NUMBER PHV2 ------------- --------------- ------------ ---------- ahufs9gr5x2pm 1281183209 0 2224365886 |
The base lined plan is no longer reproducible.
5. Conclusion
Although I haven’t exhausted all the possible situations that might affect whether an SPM plan is reproducible, I have shown enough information to take into account before changing an object (index, table) used during the SPM plan capture so that you shouldn’t be surprised to see your critical report performing badly while you think that you’ve definitely constrained it with a stable and accurate plan. In the next article I will show two other aspects that influences the reproducibility of a base lined plan which are the CBO and the NLS parameters. In the next article I will also try to answer questions like: Which optimizer parameters will be used during the report execution? Are they the optimizer parameters stored during the baseline capture time or the optimizer parameters of the current execution environment?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments