
In the previous parts of these MySQL optimization series, we’ve told you how queries work on a high level, then dived deeper into the power of SELECT and INSERT statements. In this blog, I will cover some of the ways to optimize modifying your data too.
UPDATE Queries – the Basics
As the name of the statement suggests, UPDATE queries provide us with the ability to make changes to our existing data. The UPDATE statement modifies the values of rows in a table and in its most basic form, looks like so:
|
1 2 3 |
UPDATE demo_table SET [column] = [‘value’] WHERE [specific details] [LIMIT x] |
Where:
- The column after the
SEToption defines the specific column we want to update. It’s worth noting that we can update the values of multiple columns as well by specifying them after we specify the value of the first column. [specific details]refer to the details after theWHEREclause. This part of the query is mostly used to update a specific set of columns matching a given condition, for exampleWHERE id > 500would update all of the rows with an ID higher than 500. These conditions are known as the predicate of the query.[LIMIT x]allows us to update only the specified number of rows (LIMIT 100would only update 100 rows, 200 would update 200 rows, etc.) We can also specify an offset to start from:LIMIT 100,200would update 100 rows starting from the 100th row. AnORDERBY option will order the results according to a given clause, add anASC|DESCoption and you will be able to sort the rows in an ascending or a descending order.
These are the basics of the UPDATE statement – as you can tell, these queries are nothing fancy, but their performance can be made better by following a couple of tips.
Optimizing UPDATE Queries
Most MySQL DBAs know that indexes make UPDATE statements slow – however, while this statement is true, there’s much more to updating data than just that. When updating data, we need to keep the following things in mind:
- Indexing – Indexes have positive and negative effects on
UPDATEstatements. This is because anUPDATEis logically a two-step process. One to find the row to modify, the another to modify the data.- Positive – At the same time, if you are updating a small number of rows (most
UPDATEstatements only affect 1 row, usually accessed by a primary key indexed value), indexes improve performance by improving access to the rows that need to be modified. - Negative – Indexes can slow
UPDATEstatements down when you modify columns that are indexed. This is because when an index is in place and anUPDATEquery is running, theUPDATEneeds to update the data in the index and the data itself – that’s some additional overhead right then and there.
- Positive – At the same time, if you are updating a small number of rows (most
- Partitions – as a rule, partitions slow down
UPDATEandDELETEoperations makingSELECTstatements faster in return, and they also have a couple of caveats unique to themselves:- Partitioning integers – Suppose that we partition tables by range and a partition A holds integers that are less than 1000, and a partition B holds integers from 1001 to 2000. Then, suppose that we update our data with a query like so:
UPDATE `demo_table`;
SET `partitioned_column` = 1500
Such a query means that if the values in the column originally resided in the partition A, they would now be located in the partition B – the update would switch the partitioned column from partition A to partition B. For some, that may be a source of confusion, so it’s useful to keep that in mind. - Beware of NULL values– if you insert a row having the value of
NULLinto a specific partition and then want to update your partitions, beware that the row will reside in the lowest partition possible. For more information on how partitioning handlesNULLvalues, refer to the documentation on handling NULL values in partitioning.
- Partitioning integers – Suppose that we partition tables by range and a partition A holds integers that are less than 1000, and a partition B holds integers from 1001 to 2000. Then, suppose that we update our data with a query like so:
- Locking – if we lock the table, perform many updates one by one (we can use the
LIMITorWHEREclauses to achieve this goal), and then unlock the table, the speed of the queries will likely be much faster than running a singleUPDATEquery that updates many rows at once. Such an approach would look like this (replace x with the name of your table and column with the name of your column. Feel free to update as many rows in one go as you want):
|
1 2 3 4 5 6 7 |
LOCK TABLE [WRITE|READ] x; UPDATE x SET column = ‘value’ LIMIT 0,50000; UPDATE x SET column = ‘value’ LIMIT 50000,100000; UPDATE x SET column = ‘value’ LIMIT 100000,150000; ... UNLOCK TABLE x; |
It is also worth noting that locks have two types – one can either lock the table for writing (INSERT queries) or for reading (SELECT queries) if clauses WRITE or READ are specified. Locking tables for reads or writes means just that – all INSERT or SELECT operations will fail to complete if a specific (writing or reading) lock is in place and everything will be OK once the lock is released (once the table is unlocked.)
Also, keep in mind that if you use the MyISAM engine and use LOCK TABLE queries in the same fashion, your UPDATE statements will be faster because the key cache (MyISAM’s equivalent of the InnoDB buffer pool) will only be flushed after all of the UPDATE queries are completed.
WHEREandLIMIT– theWHEREand (or)LIMITclauses can dramatically speed up the performance ofUPDATEqueries too since they would limit the number of rows that would be updated. Always remember to specify them if you don’t need to update the entire table.- The load of your database – finally, beware of the usage and load of your database before updating data. Updating data at 1AM at night will likely be a better option than updating it at peak usage times if you’re updating data in a live environment. The aim of this approach is to ensure that the database has to put in as little effort as possible.
If you come across a situation where you need to update bigger sets of data (millions of rows and above), it’s also a good idea to keep additional tips in mind. We walk you through these below.
Optimizing UPDATE Queries for Bigger Data Sets
If you’re updating a column and have a lot of data to update, there’s a neat workaround you can employ by making use of a DEFAULT clause. Perform these steps (replace demo_table with your table name and only include columns that you want to keep the data from in the new table.):
- Issue a query such as:
SELECT username,email,registration_date
FROM demo_table
INTO OUTFILE ‘/tmp/backup.txt’;
This will take a backup that doesn’t come with much overhead when re-importing (SELECT INTO OUTFILEstatements remove the clutter that comes withINSERTqueries and only backs up raw data – you might need to useFIELDS TERMINATED TOto specify a delimiter that tells MySQL where one column ends and the other begins. Refer to the documentation for more information.) - Create a table identical to the one you’re working with by running a
SHOW CREATE TABLEstatement, then setting the default value of a column you need to update – here we set the default value of the column ip_address:
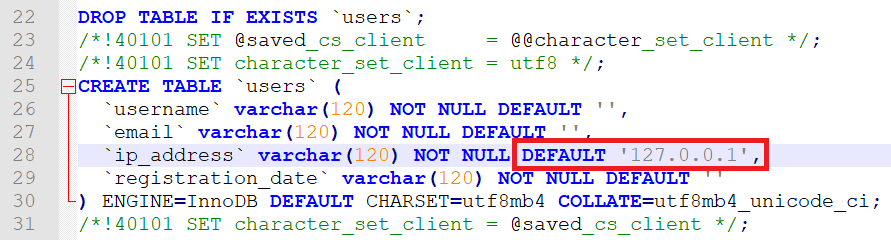
- Re-import the partial backup without specifying the column with the default value inside of the operation (it will be populated by default.) Specify
IGNOREif there are more fields in the file than the amount of columns in the database and specify aFIELDS TERMINATED BYoption at the end of the query if the fields are terminated by a character too:
LOAD DATA INFILE ‘/tmp/backup.txt’ IGNORESuch an approach is exceptionally useful for cases involving huge amounts of data that need to be updated to the same value: this operation will always be significantly faster than running an
INTO TABLE users (username,email,registration_date);
UPDATEquery because that way MySQL will think that the column is already populated by default. Additionally, asLOAD DATA INFILEis able to skip certain operations involving overhead, millions of rows can be updated in a matter of seconds. For more details, refer to the documentation of MySQL or our coverage ofLOAD DATA INFILE.
ALTER vs. UPDATE in MySQL
The advice above should be a good starting point for those of you who frequently update data – however, always keep in mind that as MySQL develops, new issues arise too. For example, did you know that even though ALTER and UPDATE are two different queries, one of them updates data, but another one updates structures, including columns (changes their data types, names, etc.)?
That’s why you need to familiarize yourself with ALTER too: for frequent readers of this blog this query won’t cause many problems, but those who aren’t too familiar with its internals should always keep in mind that when ALTER is being run, copies of the table are being made in the background. ALTER works like this (for the purposes of this example, we will assume the table that is being modified is called “A” and a new table is called “B”):
- A copy of the table
Ais made – it’s called tableB. - All data within the table
Ais copied into tableB. - All of the necessary operations (changes) are performed on table
B. - The table
Bis switched with the tableA. - Table
Bis destroyed
For some, the steps defined above are the primary reason behind the struggle around storage – some developers are quick to point out that they’re “running out of space for no apparent reason” when an ALTER query is in progress – that’s the reason why.
UPDATE Queries in MyISAM
It’s widely known that MyISAM is obsolete, but if you find yourself using MyISAM instead of InnoDB or XtraDB for your COUNT(*) queries (MyISAM stores the row count inside of its metadata which isn’t the same for InnoDB), look into the following settings:
key_buffer_sizeis the equivalent toinnodb_buffer_pool_size– the bigger this value is, the fasterUPDATEstatements will finish.- If you find yourself using
LOAD DATA INFILEto update data, look into thebulk_insert_buffer_sizeparameter. Since MyISAM uses this parameter to makeLOAD DATA INFILEfaster, it’s recommended you increase its size. This parameter is also used whenever ALTER statements are being run. As we’ve already explained above, such statements are not exactly UPDATE queries, but they can be used to update column names instead of data within them.
If you must run UPDATE operations on MyISAM, you should be wary of updating rows to a value larger than their specified length since MySQL documentation states that doing so may split the row and would require you to occasionally run OPTIMIZE TABLE queries. Finally, consider switching your storage engine to InnoDB or XtraDB as MyISAM is only a fit for running simple COUNT(*) queries – since the storage engine holds the number of rows inside of its metadata, it can return results quickly, while InnoDB cannot.
Summary
At the end of the day, updating data isn’t rocket science – MySQL documentation states that all update statements can be optimized just like SELECT queries just with an overhead of a write, plus additional writes if you modify indexed columns. All of the advice given above resonates with that – indexes slow down UPDATE statements, retrieving data when the database isn’t at its peak is a good decision, delaying updates and performing many updates in a row later on is a way to go too, and LOAD DATA INFILE is significantly faster than INSERT INTO as well.
Optimizing UPDATE operations in MySQL may not be a piece of cake – but it isn’t rocket science either. Some basic knowledge does indeed go a long way – familiarize yourself with the internals and the advice above, read the documentation, and your database should be well on its way to quickly perform UPDATE operations.
However, simple UPDATEs never saved a database from disaster – read up on other articles in these series and learn how to improve the speed of SELECT, INSERT, and DELETE queries, and until next time.






Load comments