
Welcome back to the MySQL optimization series! In case you haven’t been following this series, in the past couple of articles we have discussed the basics of query optimization, and told you how to optimize SELECT queries for performance as well.
In this blog, we’re further learning ways to optimize INSERT operations and look at alternatives when you need to load more than a few rows in the LOAD DATA INFILE statement.
How Does INSERT Work?
As the name suggests, INSERT is the query that’s used to create data in tables in a database. The internal functioning of a basic INSERT query is pretty much identical to that of aSELECTstatement as seen in the previous article, first, the database checks for permissions, opens tables, initializes operations, checks whether rows need to be locked, inserts data (updates the indexes), and then finishes coming to a stop.
We can back this up by performing some profiling:
Image 1 – INSERT Query Profiling – the Query
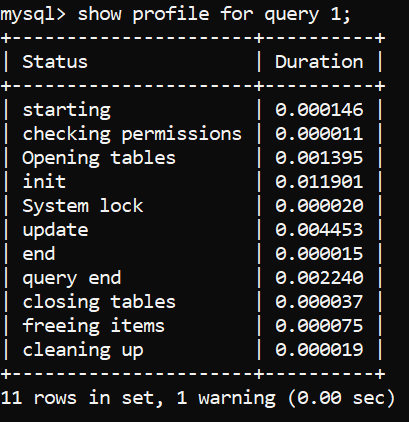
Image 2 – INSERT Query Profiling – Status and Duration
To know what these status codes mean in detail, please refer to preview blog about SELECT queries where we explain them one by one, but in a nutshell, the profiling codes outlined above enable MySQL to figure out the following things, amongst others:
- Whether appropriate privileges have been set.
- Whether tables are ready to perform any operations on (i.e., whether they are locked or not.)
- How best to perform the
INSERToperation. This step includes*:- Sending the query to the server.
- Parsing the query.
- Scanning the table for any indexes or partitions.
- Inserting rows into tables
- Adding data to applicable indexes.
- Closing the process.
* Do note that each step takes up a proportion of the total time INSERT queries take. According to the MySQL documentation, the fastest process is the closing of the query, the second fastest one pertains to sending the query to the server and parsing it, and the slowest is adding data to the table. (Note that for very small amounts of data, connecting to the server can be more costly).
As far as profiling is concerned, it’s indeed helpful when performing read operations, but not very much in other cases: knowing how queries work is a good thing to do, but when optimizing INSERT queries, profiling doesn’t take us far and that’s why we need to employ techniques that we’ll share with you in a second.
Another thing to remember is that no matter what database management system is in use (INNODB, etc.), many queries go through the same steps – INSERT queries share many steps with SELECT queries too, however, while there are a lot of shared steps, it’s important to remember that all queries are different in their own regard too – an INSERT query is different from a SELECT query in that SELECT queries benefit from indexes and partitions, while they generally make INSERT queries slower.
Advanced DBAs will also know that INSERT queries are sometimes used in concert with SELECT queries – we’ll start from the basic ways that will help you improve your INSERT query performance, then gradually evolve towards more complex scenarios.
Basic Ways to Improve INSERT Query Performance
To improve INSERT query performance, start with the advice above: profile your queries, then remove indexes or partitions on a table if necessary. All indexes and partitions will make all INSERT queries slower because of one simple reason – every time data is inserted into a table, all indexes and partitions on that table must be updated for the database to know where the row resides. That’s true no matter what kind of partitions or indexes are in use – the more partitions or indexes exist on a table, the slower your query will become.
Note: Remember that performance tuning must be treated as a holistic activity and we are focusing on tuningINSERT statements only here. Indexes are needed by most of your SQL statements and unless you are adding a LOT of data to your table, removing them just to make a particular INSERT operations go a little bit faster (and then killing read performance) is typically not desirable.
Another very popular and simple way to improve query performance is to combine small operations into a single, larger operation. We can also lock tables and unlock tables only when all operations are completed, and these approaches look like so:

Image 3 – a basic way to improve INSERT query performance.
And that’s the crux of it – to optimize INSERT query speed, we need to “think big” in terms of queries. The whole magic goes like this: instead of having many queries that insert a couple of rows each, run one huge query that inserts many rows at once after making sure that all the table locks, index updates, and consistency checking are as delayed as possible (ideally delay these processes until the very end of the query.)
When it is feasible, delaying everything isn’t hard and can be done by following some or all these steps. Consider performing these steps if you’re working with more than a million rows and (or) whenever you see that your INSERT queries can be combined into a single operation just like in the example above (it’s not necessary to follow the steps from the top to bottom – following one or two steps will usually be a good start):
- Lock the tables before inserting data into them and unlock them once all the data has been inserted, but not before (see example above.) By locking your tables, you will ensure that the data within them will not be modified while the data will be inserted.
- Consider starting a transaction (
START TRANSACTION) before runningINSERTqueries – once done, issue aCOMMITquery. - Avoid adding any indexes before insert operations have been completed.
- If possible, make sure that the table you’re inserting data into is not partitioned because partitioning splits your table into sub-tables and once you insert data into your table, MySQL has to go through a couple of additional steps to figure out which partition to insert what data into, etc. Also, while the proper use of partitions help improve the performance of
SELECTstatements, partitioned tables will inevitably take up a little more space on the disk, so be wary of that.
Follow these steps and that’s it – you’re on the way to INSERT heaven! However, do note that these are only the basics and such an approach may not cover your scenario – in that case, we may need to perform some additional optimization by allocating the number of I/O threads within InnoDB by modifying my.cnf (refer to the options in the screenshot below), or improve query performance by doing other things you will learn in this article. Keep reading – your INSERT query performance will soon skyrocket!
Improving INSERT Query Performance Beyond the Basics
Once you’re sure that all of your INSERT queries are profiled and doing what you expect, employ the basic steps outlined above to improve their performance. If that didn’t help, consider the following advice:
- We can start an explicit transaction using
START TRANSACTIONor issueautocommit=0, run all of ourINSERTqueries, then run aCOMMITquery. By doing so we delay commit operations until after the very lastINSERTquery has been finished – in that case, MySQL saves time because it doesn’t commit SQL statements as soon as they’re executed, but commits them all at once later instead. The bigger the data set is, the more time will be saved.
Such an approach isn’t very feasible with billions of rows (INSERTqueries are not designed for more than 50 or 100 million rows at a time – somewhat depends on hardware in use – and we need to useLOAD DATAfor that sinceINSERTstatements come with a lot of overhead – more on that later), but if we’re dealing not dealing with that many rows, it certainly could be viable. - We can modify the
my.cnffile and add or modify the following options to increase the I/O capabilities ofInnoDB(the main storage engine within MySQL):

Image 3 – Increasing I/O Capabilities of InnoDB- The
innodb_read_io_threadsoption sets the number of threads handling read operations – in most cases, the value of 32 is sufficient and should be left at default. - The
innodb_write_io_threadsoption sets the number of threads handling write operations – in most cases, the value of 32 is also sufficient and should be left at default. - The
innodb_io_capacityoption defines the total I/O capacity of InnoDB and its value should be set at the maximum value of IOPS available to the server
It is mostly related to the threads that perform various database-related tasks in the background (working with the buffer pool, writing changes, etc.) – these threads are trying to not have a negative effect on InnoDB at the same time. for more information, head over to the MySQL documentation over here. - For more details on optimizing
my.cnffor general performance, I previously posted the following article on Simple-Talk: Optimizing my.cnf for MySQL performance.
- The
- We can insert more data at once by using the bulk insert operation available within the INSERT statement itself. When using such an approach, we can avoid defining the columns we load the data into if we load the data into all of them at once as well. Do note that if we elect to ignore columns and we have an
AUTO_INCREMENTcolumn, we must specify the value as NULL (an example is given below.)

Image 4 – INSERT INTO Example
Additional considerations for INSERT performance
These steps previously covered will help you optimize your INSERT queries; however, these are only the basics. Advanced DBAs know of a couple of additional ways to improve their INSERT query performance and some of advanced tips include combining INSERT statements with SELECTstatements too!
Locks and Inserting rows concurrently
Many of you know that issuing INSERT statements means locks for InnoDB: MySQL deals with each statement differently, and as far as INSERT statements are concerned, InnoDB row-level locks are advantageous for the end-user: the storage engine sets a lock on the inserted row thus not disrupting any operations with any of the other rows in the same table. Users can still work with their InnoDB-based tables as they’re inserting data as long as the rows they need are not locked and they didn’t take a table lock).
Before any row is inserted, MySQL also lets InnoDB know that a row is going to be inserted by setting an insert intention lock. The purpose of that lock is to let other transactions know that data is inserted into a certain position, so that other transactions do not insert data into the same position.
To make the best out of locks within InnoDB, follow the advice above – make use of bulk INSERT statements and consider delaying all commit operations until after the very last INSERT query: bulk INSERT statements will insert data in a quicker fashion and committing an operation only after the last query will be faster as well.
Inserting rows from a SELECT Query
As noted above, INSERT queries are the primary way of inserting data into MySQL, but many DBAs will know that INSERT queries are not always simple either: certain situations may require us to use them in concert with other – typically SELECT – queries too. A query like so would also work quite successfully:
|
1 2 3 |
INSERT INTO table_name (FirstColumnName, SecondColumnName) SELECT FirstColumnName, SecondColumnName FROM another_table [options] |
For example:

Image 5 – INSERT and SELECT Queries Together
Note that in this case indexes will not be beneficial to the table where new rows are being created, but they will be beneficial fetching rows from the table in the SELECT statement. Note that in the sample query, the another_table reference in the query can be the same table. So:
|
1 2 3 |
INSERT INTO table_name (FirstColumnName, SecondColumnName) SELECT FirstColumnName, SecondColumnName FROM table_name [options] |
Is possible as well, in which indexes can (depending on if you have a where clause on the table,) can both be helpful and detrimental at the same time.
The CREATE TABLE … SELECT Query
To select data directly into a new table, we can also employ a CREATE TABLE statement together with a SELECT query. In other words, we can create a table and insert data into it without running a separate INSERT query afterwards. There are two ways to do this:
- Run a
CREATE TABLEstatement with aSELECTstatement without defining any columns or data types:
CREATE TABLE new_table [AS] SELECT [columns] FROM old_table;
MySQL will recreate all columns, data types and data from the old_table. - You can also define the columns and constraints and insert data to the new table like so:
CREATE TABLE new_table (
column1 VARCHAR(5) NOT NULL,
column2 VARCHAR(200) NOT NULL DEFAULT ‘None’
) ENGINE = InnoDB
SELECT demo_column1, demo_column2
FROM old_table;
Selecting data from one table to insert directly into another table is generally faster than INSERT INTO ... SELECT.
The Best Way to Load Massive Data Sets – INSERT vs. LOAD DATA INFILE
LOAD DATA INFILE is built for blazing fast data insertion from text files. Speed is achieved by ignoring or eliminating overhead posed by INSERT queries done by:
- Working with “cleaner” data (data only separated by certain denominators (think “,”, “:”, “|”, or not separated at all.)
- Providing us with the ability to only load data into specific columns or skip loading data into certain rows or columns altogether.
To use LOAD DATA INFILE, make sure you have a file that’s separating its columns by a certain denominator (common denominators include, but are not limited to “,”, the TAB sign, spaces, the “|”, “:”, and “-“ characters, etc.) and preferably one that’s saved in a CSV or TXT format. Save the file in a directory, remember the path towards that directory, then use the following query (replace the path to the file with your file, the “|” sign with your denominator and demo_table with the name of your table) – use IGNORE to ignore all errors posed by the query (duplicate key issues, etc.):
|
1 |
LOAD DATA INFILE ‘/var/lib/mysql/tmp/data.csv’ [IGNORE] INTO TABLE demo_table FIELDS TERMINATED BY ‘|’; |
To export data from your database and make the data able to be re-imported by using the LOAD DATA INFILE query, use the SELECT * INTO OUTFILE query – use IGNORE if you want to ignore all errors.
|
1 2 3 4 |
SELECT * FROM demo_table [IGNORE] INTO OUTFILE '/var/lib/mysql/tmp/data.csv' FIELDS TERMINATED BY '|'; |
LOAD DATA INFILE has many parameters that can be used as well. These parameters include, but are not limited to:
- The
PARTITIONparameter allows us to define the partition where we want to insert data into. - Combining the
IGNOREoption with theLINESorROWSoptions to tell MySQL how many lines or rows to ignore when inserting data. - Providing us with the ability to set the values of certain columns by using the
SEToption (the query below takes data from the file called “demo.csv” and loads the data with its columns terminated by “:” into a table called demo after ignoring the 100 lines from the beginning and also sets the date column to the current date when inserting all of the rows):
|
1 |
LOAD DATA INFILE ‘demo.csv’ INTO TABLE demo FIELDS TERMINATED BY ‘:’ IGNORE 100 LINES SET date=CURRENT_DATE(); |
LOAD DATA INFILE can be made even faster if we employ DEFAULT constraints. If there are columns that need to be populated with the same data for each row, the DEFAULT constraint will be faster than fetching it from the data stream. That way, all columns having the default keyword will be pre-filled without the need to load data into them.
Such an approach is very convenient to save time when one row consists of the same data and we don’t want to employ ALTER queries (those queries make a copy of the table on the disk, insert data into it, perform operations on the newly created table, then swap the two tables.) An example is given below:
|
1 2 3 4 |
CREATE A TABLE demo_table ( `demo_prefilled_column` VARCHAR(120) NOT NULL <strong>DEFAULT 'Value Here’</strong>, ) ENGINE = InnoDB; |
To dive even deeper into LOAD DATA INFILE, refer to the MySQL documentation itself.
Indexes, Partitions, and INSERT FAQ
If even LOAD DATA INFILE doesn’t help, you may want to look into indexes and partitions. Remember what we said above? The more indexes or partitions your table has, the slower your INSERT query will be. You already know the drill – but you may be pressed with some extra questions, some of them being the following:
|
Question |
Answer |
|
Should I drop all of the indexes before running an |
Typically No – while indexes are used to improve the performance of finding rows, and generally slow down However, in some cases when loading hundreds of millions or billions of rows, indexes should certainly be removed (they can be added again by using an |
|
Does using a |
Yes – primary keys are always indexed and indexes make |
|
Does the amount of indexes or partitions on a table make a difference in |
Yes – the more indexes or partitions you have on a table, the slower your |
|
Are |
Yes – |
|
When optimizing |
Yes – aim to use
|
|
When inserting data, is there a difference if the table we insert data into is locked or not? |
Yes – inserting data into locked tables is generally faster than the other way around since database management systems check for table locks as part of the query execution process. |
|
How do I achieve a balance between |
Testing – Load testing is important to see what effects any change will have on a system. A lot will depend on how you are using a system, and how concurrent users use a system is important. If users are simultaneously creating and querying data, it is different than if data is loaded in a time window, then queried at other times. Generally, aim to have only as many indexes and partitions as necessary, |
|
Foreign keys – are they a problem for |
No – |
|
The |
Yes – the In many cases, the constraint will only be problematic if the constraint evaluates to More details about the |
|
Is it possible to insert data and update it at the same time? |
Yes – that can be done by using the |
|
Are there any lesser-known ways to improve |
Yes – if you’re working with bigger data sets, make use of the |
|
When to switch to |
Typically, when loading any data where you have many rows to load – There are no set “rules” that define when you should switch
|
Balancing INSERT Performance and Reads
To balance out the performance between INSERT and SELECT queries, keep the following in mind:
- Basics do help – Select as few rows as possible by using a column list with your
SELECTofSELECT *, and index only the columns you’re searching through. - Normalize your tables – Table normalization helps save storage space as well as increases the speed of your read queries if used properly. Choose a normalization method suitable for you, then proceed further.
Do note that as with everything, normalization also can have negative effects – more tables and relationships can mean more individualINSERTor LOAD DATA INFILEstatements, but if you do everything correctly, your database should roll just fine! - Use the proper storage engine – this should be obvious, but you would be surprised how many inexperienced DBAs make a mistake of using an inappropriate storage engine for their use case. If you’re using MySQL, aim to use
InnoDBorXtraDB for general use cases.
If you’re in a testing environment and memory is not an issue, theMEMORYstorage engine could also be an option, but note that the storage engine cannot be as heavily optimized and that the data won’t be stored on the disk either – at that point the insert queries would be blazing fast, but the data would be stored in the memory itself meaning that a shutdown of the server would destroy all of your data as well. - Use a powerful server – this goes hand in hand with optimizing
my.cnfor other files. If your server is powerful enough, balancing the performance ofINSERTandSELECToperations will be a breeze. - Only use indexes and partitions where necessary and don’t overdo it – aim to index only the columns you’re running heavy
SELECTqueries on, and only partition your tables if you have more than 50 million records. - Consider ditching INSERT statements altogether – if you must import huge chunks of data, consider splitting them into files and uploading those files with
LOAD DATA INFILEinstead.
Summary
In this blog, we’ve walked you through how best to optimize INSERT queries for performance and answered some of the most frequently asked questions surrounding these sorts of queries. We’ve also touched upon the importance of balancing INSERT and SELECT operations and walked you through a way to ditch INSERT queries altogether when loading lots of data.
Some of the advice we’ve provided in this blog is known by many DBAs, while some might not be known at all. Take from this blog what you will – there’s no necessity to follow everything outlined in the article step by step, but combining some of the advice in this article with the advice contained in other parts of this series will be invaluable for your database and your applications alike.
We hope that this blog has taught you something new, and we’ll see you in the next one.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments