

Welcome back to the MySQL indexing series! We’ve already covered the nuances surrounding indexes in MySQL as well as walked you through B-tree indexes.
MySQL, however, has many other index types it can offer for your use case, and one of those indexes are hash indexes, too.
What are Hash Indexes?
In MySQL, hash indexes are indexes that are used in queries that use the equality operators like = or <=> (which is the MySQL NULL safe equality operator, equivalent to the SQL Standard IS NOT DISTINCT FROM). Hash indexes are not used in other situations, so they can be useful for things like random or generated PRIMARY KEY values where you are looking up single rows and not needing to order rows or searching for a range of values.
As per the documentation, MySQL only supports the use of hash indexes for the MEMORY storage engine, and these kinds of indexes are known to facilitate blazing-fast single-row searches through data residing in memory. Hash indexes may start to become an option when index structures can save your disk in return for occupying computational power and the memory available on your server.
Note: Such indexes can also be defined within other storage engines (I’ll get to that in a second); however, in use cases not revolving around the MEMORY storage engine, hash indexes are likely to be turned into B-tree indexes.
The Subtleties of Hash Indexes
Hash indexes are not as widely implemented as B-Tree indexes, and as mentioned, part of that is their narrow use case. But even though they can be useful, there are a few concerns that you need to have to be aware of:
For the hash table, one needs to know the number of rows likely to be within the table. That helps with determining whether the amount of memory available within our server will be sufficient to store hash indexes on our data.
Hash indexes may have to be rebuilt from time to time for them to be useful. Rebuilding hash indexes may become necessary when your data changes considerably—if you have larger or smaller tables than expected, are not shutting down your server, and want your index to shrink, hash indexes may have to be rebuilt.
That’s where we come to the upsides of storing such indexes in the memory of your server because as our data grows, that could add an overhead on our disk I/O, but because hash indexes primarily work with data residing in memory, the rebuilding of such index types is likely to be significantly faster.
Hash indexes are used for in-memory tables. Since the only way to acquire and work with in-memory tables within MySQL and its counterparts is the usage of MEMORY storage engine, the use cases of hash indexes will also involve MEMORY-based tables within MySQL.
Aside from that, it would be a shame not to note that disk-based storage engines such as InnoDB provide support for a type of hash index called Adaptive Hash Indexes. More on this later in the article.
Hash Indexes in MariaDB
Now that you’ve familiarized yourself with hash indexes, it’s time to dig into what makes them tick. I’ll use a demo table to demonstrate hash indexes in action. Its structure will be defined like so (note – here, we don’t denote MEMORY as our storage engine to demonstrate how MariaDB “thinks in InnoDB” internally when hash indexes are defined):
|
1 2 3 4 5 6 7 8 9 10 |
DROP TABLE IF EXISTS TABLE `demo_table`; CREATE TABLE `demo_table` ( `id` INT(20) NOT NULL AUTO_INCREMENT PRIMARY KEY, `first_name` VARCHAR(50) NOT NULL, `last_name` VARCHAR(50) NOT NULL DEFAULT ‘’, `email` VARCHAR(50) NOT NULL DEFAULT ‘’, `gender` VARCHAR(50) NOT NULL DEFAULT ‘’, `ip` VARCHAR(50) NOT NULL DEFAULT ‘’ ); |
After we have the InnoDB table up and running, we will also drop a hash-based index on top of it using the CREATE INDEX query:
|
1 |
CREATE INDEX `hash_idx` ON `demo_table`(`first_name`) USING HASH; |
When we combine the CREATE INDEX clause with the CREATE TABLE query in phpMyAdmin, we have the following result:
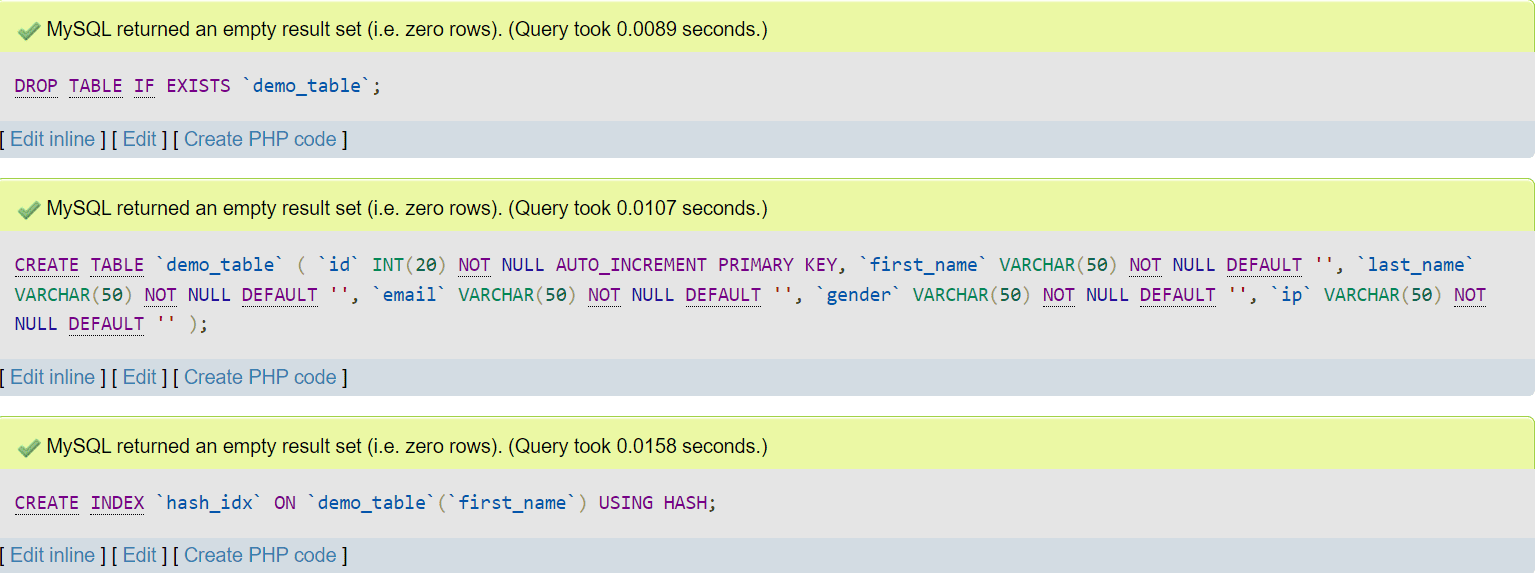
Image 1 – Creating Hash Indexes when Creating a Table in MariaDB
After we execute the code and then inspect the structure of our table once, we can see that the hash index is indeed a BTREE index under the hood – that happened because the default table storage engine definition for all tables that don’t have the storage engine defined is InnoDB:

Image 2 – The Hash Index you expected to create is actually created as a BTREE Index
Let’s now try doing the same thing with a table running the MEMORY storage engine instead (uses the same code, with one small change to the CREATE TABLE statement to denote the usage of the MEMORY storage engine):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DROP TABLE IF EXISTS TABLE `demo_table_mem`; CREATE TABLE `demo_table_mem` ( `id` INT(20) NOT NULL AUTO_INCREMENT PRIMARY KEY, `first_name` VARCHAR(50) NOT NULL DEFAULT ‘’, `last_name` VARCHAR(50) NOT NULL DEFAULT ‘’, `email` VARCHAR(50) NOT NULL DEFAULT ‘’, `gender` VARCHAR(50) NOT NULL DEFAULT ‘’, `ip` VARCHAR(50) NOT NULL DEFAULT ‘’ ) ENGINE = MEMORY; -- < add this CREATE INDEX `hash_idx` ON `demo_table_mem`(`first_name`) USING HASH; |
Now, execute the create statements again, and you will see a different output:
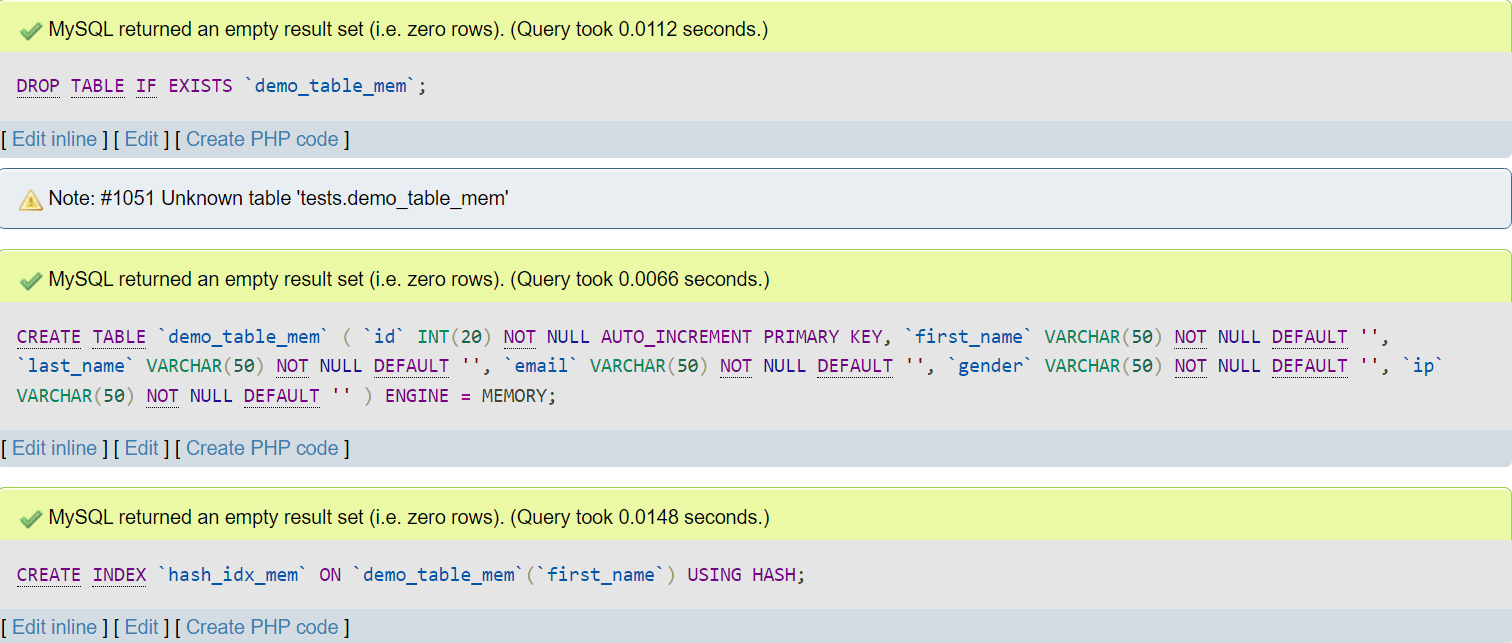
Image 3 – Defining a Hash Index on the MEMORY Storage Engine
If we inspect the memory-based table structure now, we will see that all of our indexes are hash indexes instead:
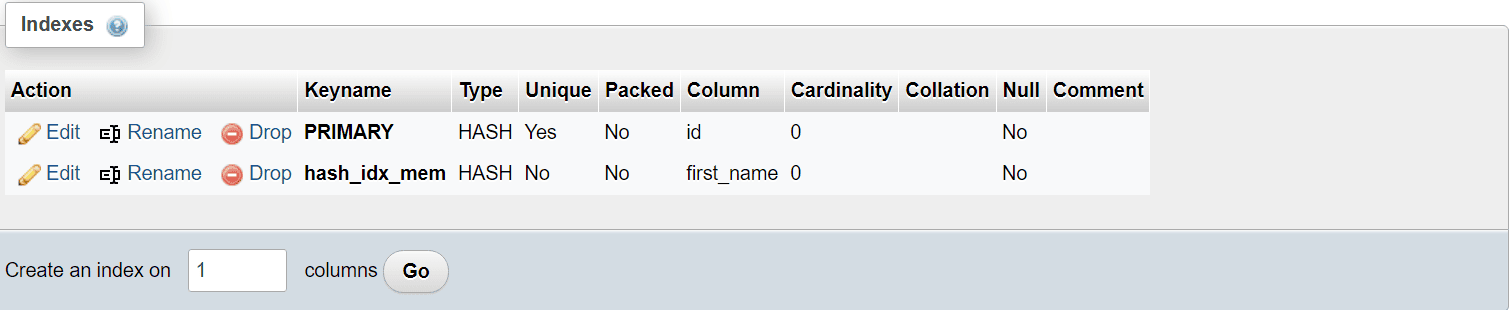
Image 4 – Hash Indexes in MariaDB
Even the primary key index is a hash index! Interesting, right?
That’s because our table is based on the MEMORY storage engine, and as all of its data is stored in memory, MySQL doesn’t have to default to using B-tree indexes and can suggest (and choose) the faster option – a hash-based index – instead.
The same is true for clustered indexes – define an AUTO_INCREMENT on an ID column on a memory-based storage engine, and you will have a hash-based clustered index, too – it will be hyper-fast to its clustered nature and hash-based structure. Cool, right?

Image 5 – Creating an AUTO_INCREMENT Column Using the MEMORY Storage Engine

Image 6 – the AUTO_INCREMENT Column on a MEMORY Table is a HASH Index
Now, we will insert some data into our table and review how such indexes work.
Hash Indexes in Action
First, let’s insert some data into our in-memory-based table – for that, we can make use of ordinary INSERT or LOAD DATA INFILE statements without inventing anything revolutionary either (you can see the details for loading the data in the Appendix):

Image 7 – LOAD DATA INFILE Into a MEMORY Table
Everything works as usual – COUNT(*) queries too:
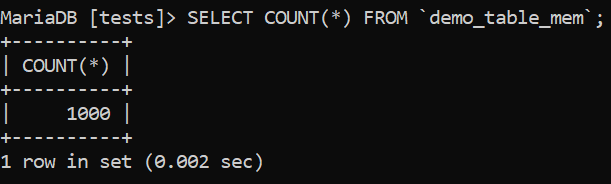
Image 8 – COUNT(*) On a MEMORY Table
One thing I would direct your attention to is the time taken by MariaDB to complete each query – the first query was completed in 0.01 sec., and the second one in 0.002 sec., and that’s not because we heavily optimized our database, but because our data resides in memory and can be accessed much faster. This can be confirmed once we run some basic tests on an InnoDB table and one running the MEMORY storage engine.
First, note that the same table (the structure is the same, too) will occupy space in memory the same way it occupies space on the disk, meaning that, likely, you won’t be able to store as much data in memory as you would be able to store on the disk. The MEMORY storage engine has some more caveats, too:
MEMORYtables are similar to MyISAM tables in that they perform full-table locks when performingINSERT,UPDATE, andDELETEoperations. X amount of these operations means X amount of full table locks per second.MEMORYtables still incur disk I/O: the MySQL daemon will contact the .frm file belonging to theMEMORYtable to verify that the table exists before parsing an SQL query. In other words, if you run many SQL queries against aMEMORYtable, you can notice some disk I/O.
These caveats are discussed in a StackOverflow thread by a former Pythian employee, and they do have an impact on how you work with your database and the operations performed within. One of those operations may be a comparison of the storage engines (InnoDB vs. MEMORY):
|
1 2 3 |
SELECT * FROM `users_innodb` WHERE `email` = ‘sample@sample.com’; |

Image 9 – InnoDB Table Example
|
1 2 3 |
SELECT * FROM `users_memory` WHERE `email` = ‘sample@sample.com’; |

Image 10 – MEMORY Table Example
Here, the difference may be negligible because we only have 5,000 rows we run our tests on; once the row count in our tables increases, the results will become more and more visible. However, at the same time, the amount of space taken on the memory will increase accordingly – chances are that you don’t have more than 64GB of RAM available, so tread that line carefully.
To understand these results, consider this illustration of hash indexes:
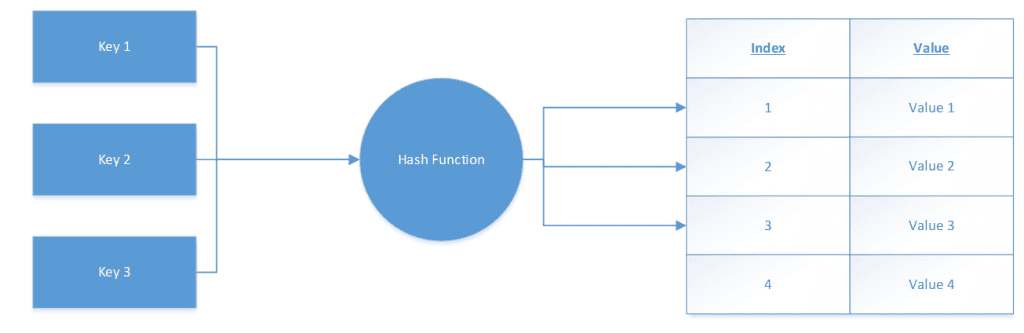
Image 11 – Basic Illustration of Hash Indexes in MySQL
Since hash indexes use a hash function to map keys to an index position (see illustration above), such an algorithm becomes very useful when searching for specific data. Let’s try hash indexes out – we will do that with 7 queries, which will search for different things using the equality, less than, more than, or all of those operators. We will:
- Search for an
IDvalue using the “more than” operator. (>) - Search for an
IDvalue using the “equal or more than” operator. (>=) - Search for a string value with an exact match. (
=) - Search for two exact string values using an OR operator.
- Utilize a
LIKEquery that uses an index (we won’t have a wildcard in front of the query.) - Search for an
IDvalue using theNULLsafe equality operator. (<=>) - Run a search using the “less than or equal to” operator. (
<=)
Our results will look like so:
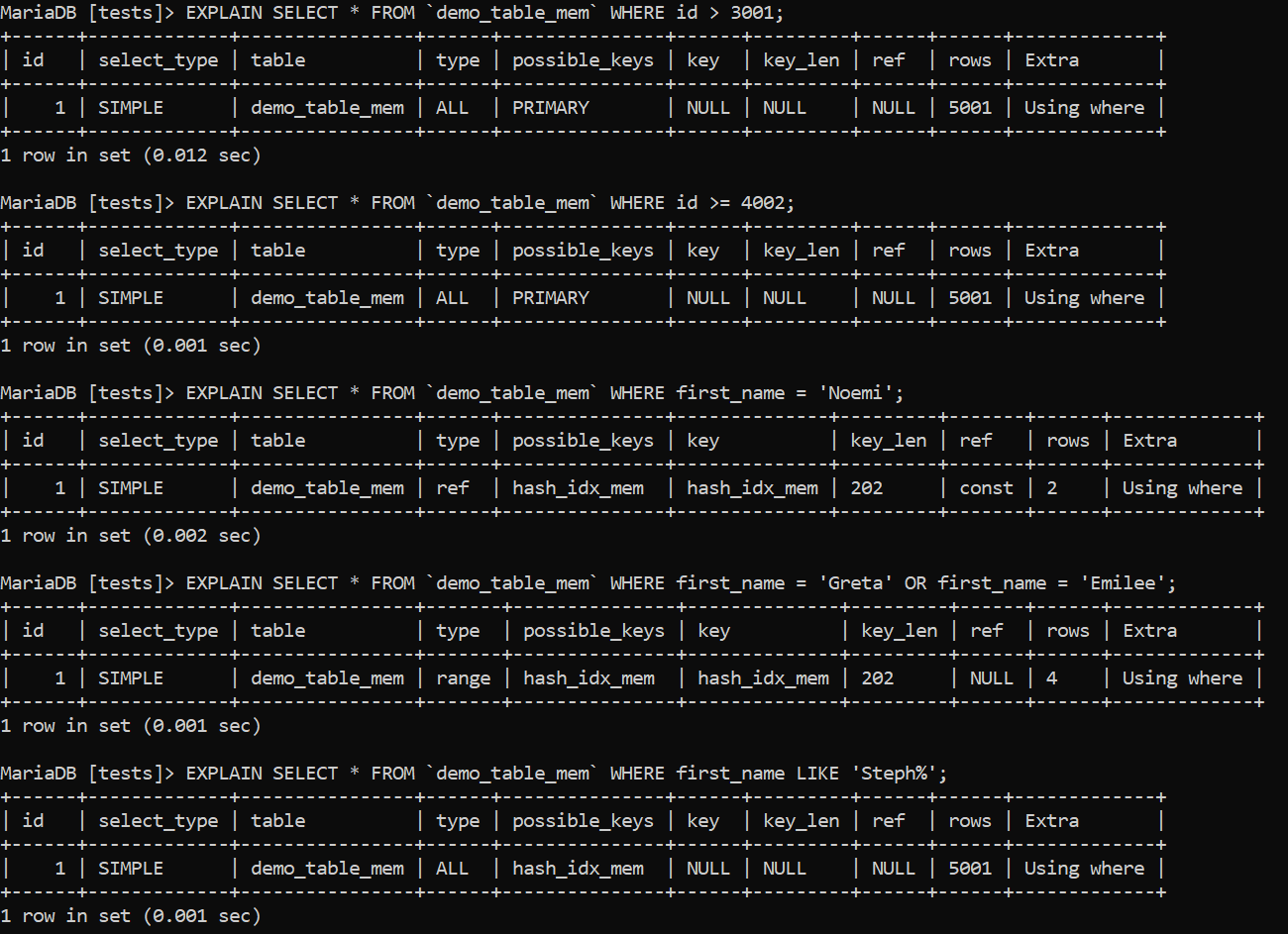
Image 12 – EXPLAINing HASH Indexes in MariaDB
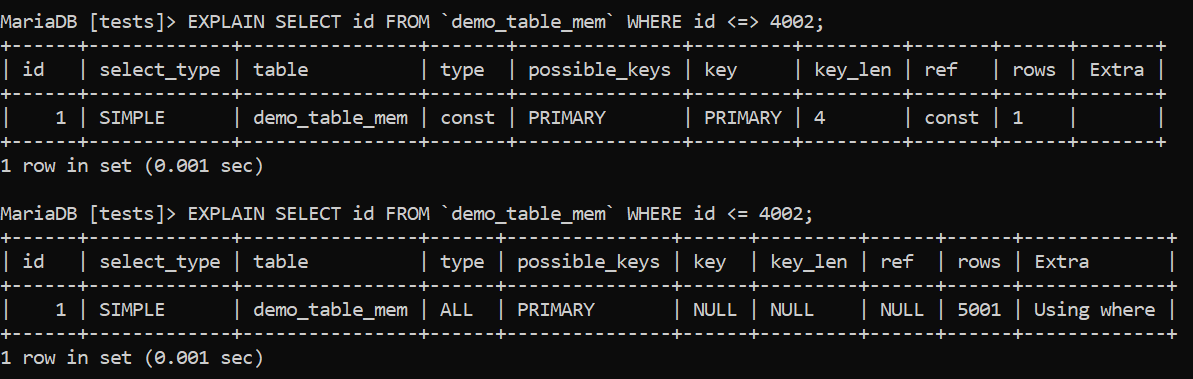
Image 13 – EXPLAINing HASH Indexes in MariaDB Part 2
Attentive readers will notice that the internal functionality of hash indexes is somewhat different than that of B-trees. From the examples above, we can notice that, unlike B-tree indexes that can be used together with the =, <, >=, <, <= or BETWEEN operators, hash-based indexes can only be considered for use if we search for an exact match together with the = or <=> operators.
In other words, hash indexes are useless if we are searching for more than a single value because our database won’t even consider such an index for use in the first place. That happens because hash indexes are used to improve data access speed when employing them in a single-value lookup operation and not anything else – as the core premise of such indexes is data residing in memory, they don’t have the luxury of assisting searches for a range of values or anything in that realm, and that’s why queries using clauses like BETWEEN, LIKE, >, or < are out of the question. They won’t make use of a hash index, no matter how your query is written.
To find a row using a hash index, your database will calculate the hash value of the value you’re searching for, then perform a search of the buckets of values that hashed to that same value. If it finds a result in the bucket, the result is returned.
The examples above support all hash index characteristics defined in the documentation of MySQL.
MySQL’s Adaptive Hash Index
Many users of MySQL will also be aware of an index called the adaptive hash index. The InnoDB adaptive hash index acts as a feature assisting in-memory hash lookups for indexing. InnoDB builds the adaptive hash index at runtime, and such an index adapts to your workload in the sense that if it “senses” that a particular value is being looked up more often, it creates an entry in itself either with the full value or its prefix, depending on your use case. Then, if such a value is searched for once again, MySQL will then use the Adaptive Hash Index instead of a B-tree index.
Such an index can be enabled by fiddling with the innodb_adaptive_hash_index variable (available values include 0 and 1), and it can be used to “add a layer” between MySQL and the InnoDB buffer pool. Then, the entire structure of your database would look like this:

Image 14 – The Adaptive Hash Index in Between the InnoDB Buffer Pool and the Disk
In MySQL, MariaDB, and Percona Server, the adaptive hash index is enabled by default and will be built automatically if InnoDB deems it to be necessary:
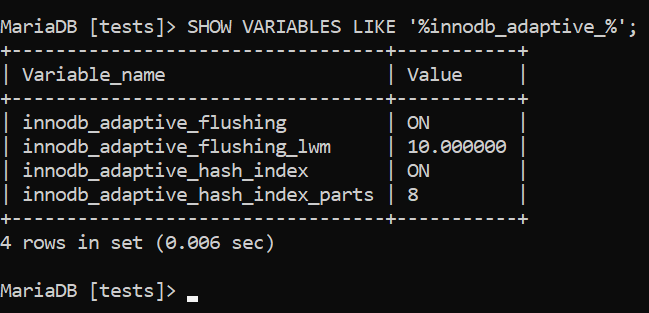
Image 15 – An Adaptive Hash Index is Enabled by Default
Coming back to hash indexes, though, understand that a hash index works by taking the keys of the indexed values and “hashing them” into output values. As such, and as I’ve already mentioned numerous times in this blog post alone, hash indexes should only be used if we’re 100% certain that we will only ever need a column to be looked up with equality operators and not with anything else.
To recap, consider a hash index when:
- The primary types of SQL queries you find yourself running are related to equality comparisons. If you’re building an app on a key-value store, hash indexes can help you.
- You don’t have a necessity to search for a range of values. In other words, if your query is using the “less than” or “more than” operators to assist your use case, hash indexes won’t work.
- Your use case involves storing data in memory (for that, consider using the
MEMORYstorage engine or InnoDB with the Adaptive Hash Index if your use case necessitates InnoDB.) - You carefully consider the upsides and downsides of the multiple types of indexes available in MySQL, and the usage of a B-tree index doesn’t satisfy your use case.
- Your queries don’t include an ORDER BY clause (if they do, a hash index wouldn’t even be considered for use.)
Finally, remember that hash indexes are only as useful as the memory within your server—exceed that limit, and your data is cactus. Don’t store too much data in memory: such indexes have drawbacks, and those drawbacks can burn your database to ashes if not considered in full.
Summary
Hash indexes are an exclusive type of index that makes searching through in-memory values as quick as possible by avoiding disk I/O. The downside of this kind of index type in MySQL is that it can only be directly with the MEMORY storage engine (or in InnoDB with an Adaptive Hash Index in some cases), that the only kinds of data that can be indexed is in-memory data due to the storage engine in use, and that SQL queries will only make use of a hash index when an exact equality operator is in use.
Nonetheless, these kinds of indexes have their use case: it’s up to you to decide whether the use case is something that should be used in your specific scenario or not. No matter which kind of index type you elect to use, keep in mind that each one of them has upsides and downsides unique to themselves: choose the one most useful for your specific use case and until next time.
Appendix – Table Structure & Data
The table structure and data in this blog were generated by a demo data generator Mockaroo. The data used in examples can be found at https://ghostbin.cloud/v6svw.
The table structure in question is as follows:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE `demo_table_mem` ( `id` INT(20) NOT NULL AUTO_INCREMENT PRIMARY KEY, `first_name` VARCHAR(50) NOT NULL DEFAULT ‘’, `last_name` VARCHAR(50) NOT NULL DEFAULT ‘’, `email` VARCHAR(50) NOT NULL DEFAULT ‘’, `gender` VARCHAR(50) NOT NULL DEFAULT ‘’, `ip` VARCHAR(50) NOT NULL DEFAULT ‘’ ) [ENGINE = InnoDB|MEMORY|…]; |
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments