
Some database developers believe that traditional relational SQL databases are not ideally suited for Agile development because you need to design a schema upfront and, even then, you have the extra effort of having to migrate the existing data whenever the database design changes. This is hardly likely to fit well within the 2- to 3-week sprint cycles of a typical Agile or Continuous Integration approach. MongoDB, on the other hand, aims to free developers from this chore. It supports dynamic schemas which can evolve along with the application, thereby avoiding expensive migrations. It is an attractive idea, but is it appropriate to enterprise-scale IT?
Though MongoDB is ideal for the early stages of a typical corporate development because it can accommodate a fast-moving development methodology, such as Agile, that needs to change its understanding of the data over time, this virtue doesn’t necessarily make it the ideal standalone platform for a mature application in the rest of the lifecycle of the database. NoSQL databases like MongoDB can therefore benefit from successful coexistence with relational databases. In a recent survey of MongoDB developers and data engineers, fewer than 20% reported using MongoDB exclusively. Of the 80% working in a mixed environment, just under half of them use MySQL, 35% use SQL Server, 25% have PostgreSQL alongside their MongoDB installation and 19% are also working with Oracle. More than a third develop against three or more different databases on a daily or weekly basis. Relational databases must be able to cohabit with NoSQL, and this means that ops people and governance need to be able to perform their roles without necessarily buying into the NoSQL mystique.
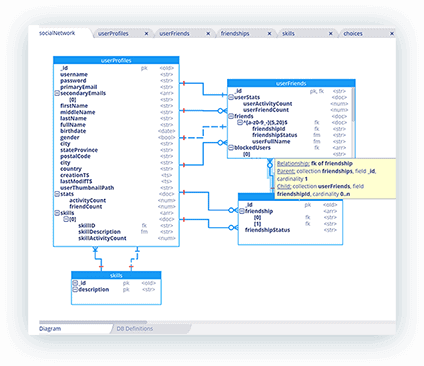
Visual data modeling for MongoDB schemas
In the early days of NoSQL databases, they were also labeled as “schema-less” and “non-relational”. Although this term emphasized the ease with which the data model could be changed, it has given some developers a false impression that they should not care about how data is being stored. It also implied that data modeling was no longer necessary. There are many perceptions about this. Some people don‘t see the value that data modeling provides. Others perceive it as just documentation, as a bottleneck to agile development, or even as too expensive to be worth it. But is it realistic to think that one can actually design an application with no structure, no schema, and no relationships? The problem is compounded by the ever-increasing diversity of languages, systems and stacks that are on offer at the coder’s smorgasbord.
“The development world is increasingly polyglot,” advises DJ Walker-Morgan of Compose.io, the IBM owned DB.a.a.S which started out with MongoDB but now offers ten different hosted database options, both relational and non-relational. “Modeling is about expressing things in a common lingua franca, which is often SQL but does not have to be.” In a mixed database environment, it pays to share a standard way of expressing data schemas, as well as having a common means of transfer.
The problem is that there is a world of difference between a database supporting an isolated stand-alone application, and a database supporting an enterprise. While schemas for small applications may be simple enough that no up-front design or documentation is necessary, it quickly becomes necessary to perform data modeling when data structures become complex and teams grow. Whatever type of database you use in supporting a business, there is no escaping the need to understand the data.
Businesses need the information to allow them to make decisions based on data. Data is a corporate asset. Data modeling is critical to understanding this data, its interrelationships, and its rules.
NoSQL, no bottleneck
A data model is not just documentation, because the physical database can be built from it. Far from being a bottleneck to application development, data modeling has been shown time and again to accelerate development, significantly reduce maintenance, and increase application quality. Experience has shown that relying on the intuition of software developers is not a repeatable process or one likely to ensure right-first-time success.
As it turns out, the power and flexibility of JSON makes physical data modeling even more important, since there are no rules on how to properly structure the data stored in NoSQL databases.
A new generation of data modeling tools is available on the market to properly represent physical data models for MongoDB collections and views. Pascal Desmarets, CEO at Hackolade, has been pioneering data modeling for NoSQL and multi-model databases. “We built it from the ground-up to support the polymorphic and evolving structure of JSON documents. We see value in smoothing the adoption of NoSQL technology in corporate IT environments.” For Hackolade, even non-relational DBs have relationships.
One size fits none
Organisations therefore have a problem. They have a range of skills and inclinations that need to assist with the use of NoSQL databases. Although developers will be motivated to spend the time to learn new tools and skills in pursuit of a pioneering way of rapidly delivering new functionality to businesses, other teams won’t be able to make the same investments.
The vendors of database systems aren’t well-equipped to provide software tools that encourage a diversity of database systems. They cannot help but have a ‘preferred workflow’ in mind. Although their Product Managers may tick the multiple use-case boxes, in their passionately beating hearts they know there’s really only one way their users should be working. It’s human nature. Cheesemakers like to call it vision.
Anyone who seeks to introduce a new database system to database professionals can only achieve a huMONGOus user-base and profitable maturity once they embrace and cultivate a free market in ways of working. Developers are impatient and opinionated and if they find a better, faster way of working, then they don’t appreciate being told, “We don’t do that on this side of the data wall.” They’ll find a way to get over, or under, the wall. By the same token, those who have to maintain systems in operations, or who need to interface to them will need to do so without having to suffer huge cultural change.
Even as database estates become more diverse, so do the teams operating them. On any given agile project, and with the rise of distributed development teams, the range of skills and experience levels is becoming wider. Sharing a common working environment becomes critical to project success. Developers need to use tooling that is designed for agile development: IDEs (Integrated Development Environments), GUIs (Graphical User Interfaces), and data modeling software, as well as an array of add-on services for providing functions such as hosted search and encryption key management. Some developers may continue to prefer command line interfaces and text editors, while their Product Manager colleague, and occasional business users, may prefer graphical tools for building queries via drag-and-drop fields, along with auto-completion capabilities. Over in the analytics corner, the resident BI specialist may want to build sophisticated aggregation pipelines while the variously named ‘database guy’ responsible for production deployments has come from a background in relational databases and prefers a SQL-based approach.
Multi-threaded skills for the future
How can we encourage the market to provide tools that will accommodate all these different legitimate ways of working?
The IDE can only become useful if it can accommodate all the different ways of working that are required. For MongoDB in particular, the in-house GUI offering called ‘Compass’ is mainly a charting tool directed at high-level Business Intelligence users. Studio 3T, on the other hand, is a full-featured IDE written by people who appreciate that teams are made up of many roles and each role has complimentary but different needs when it comes to accessing and handling the data. “Studio 3T takes a different approach,” says co-founder Graham Thomson. “We make it possible for different teams to work together on the MongoDB platform in ways they are individually comfortable with. That way they can iterate faster, more profitably.”
The mid-range edition of Studio 3T comes with multiple querying options, from an auto-completion ‘Intellishell’, to an Aggregation Pipeline builder, a SQL query capability and in the latest release, a query code generator. “Now you can write standard SQL queries against a MongoDB collection,” says Thomson, “and have Studio 3T instantly translate it, to learn what the equivalent MongoDB query would be. You can also compose your query graphically, or using the standard MonogDB script in Studio 3T.
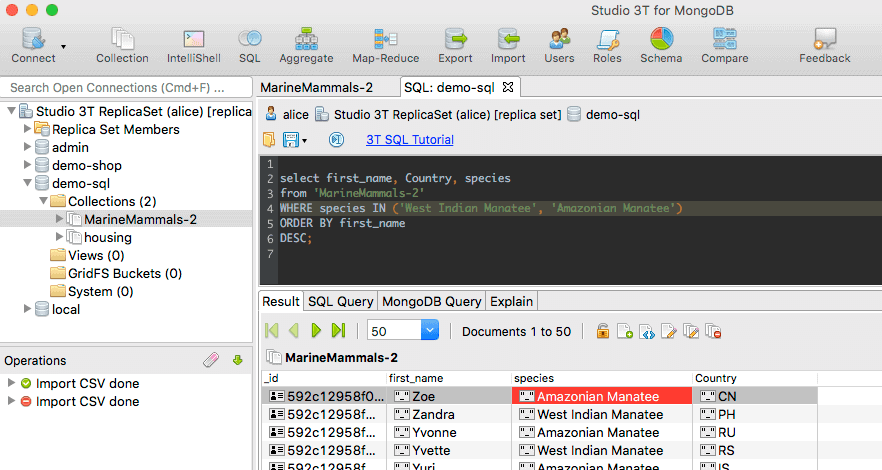
Then instead of having to rewrite it all over again in your preferred driver, we generate the relevant localized query code, in Java, Javascript, C# or Python. You just copy and paste it. It’s fair to say our IDE is properly polyglot.”
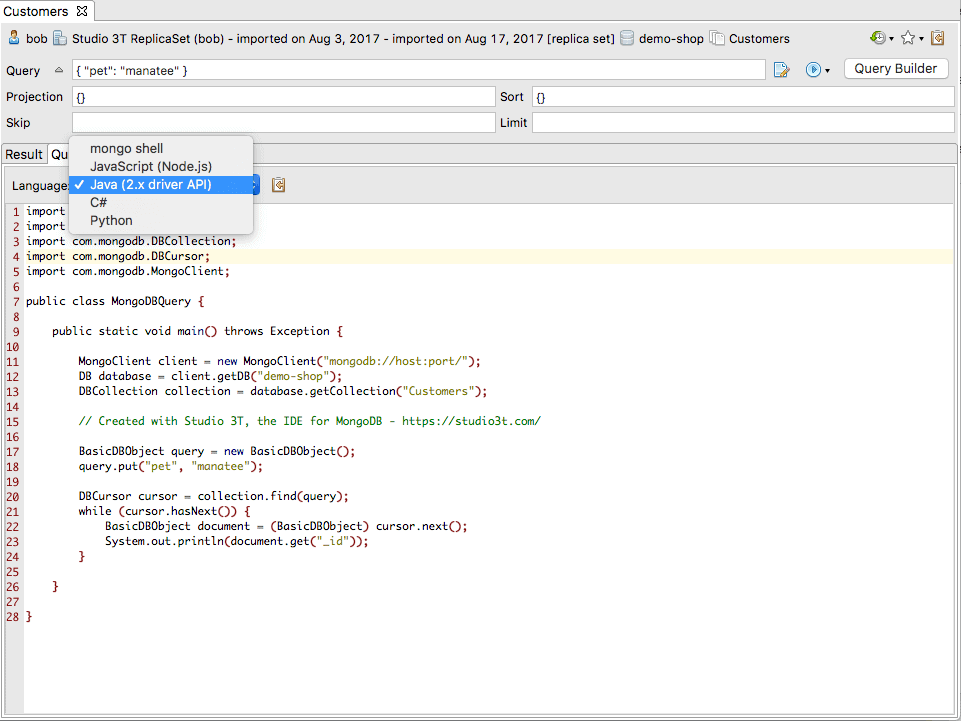
A basic GUI (such as Robomongo) may be fine for handling small datasets the size of an Excel Spreadsheet, but as soon as you have a team of three or more, working to commercial deadlines, then there is no practical alternative to having an IDE to work with, along with whatever preferred tooling your team needs.
At IBM’s database-as-a-service Compose.io, Walker-Morgan emphasizes the essentially pragmatic nature of decision-making at the architectural stage. Ideology has nothing to do with it. It’s about selecting the right technology for the job in hand, and that is rarely going to be a single, multi-function technology. It’s far more likely to be a development garage-space with a wall of preferred tools that happen to fit nicely in the palm and also work well together:
Opt for whatever is best for your task; not just one but as many as you need. If your application stack needs an in-memory database or messaging bus binding together applications using a document database for client facing applications, a database for backend analytics and a JSON document search database, then that’s the architecture you should go for.
Select tools that do one thing brilliantly and can be linked together to automate the important processes within the database lifecycle. Also, sharing a common development environment will help generate sufficient deployment speed, the escape velocity you need for exiting your startup garage. Major releases should be as like smooth gear-changes as possible and deliver acceleration into an eagerly waiting market.
Load comments