
There is no single definition of Big Data, but there is currently a lot of hype surrounding it. An accurate operational definition is that organizations have to use Big Data when their data processing needs get too big for traditional relational database systems (RDBMS). Knowing that Big Data is really big and more common every day, it does not mean that starting from tomorrow you will be analyzing petabytes of data from The Large Hadron Collider (I wish you). However; there is a quite big chance that you will come across the project where you will have to process the data that can’t be stored on your personal flash drive.
Hence, in this article I will start by explaining why it might be a good idea for a developer or data professional to get familiar with Apache Spark – a fast and general engine for large-scale data processing. First I explain the advantages of it, next we’ll see some basic examples how to use its shell to write your first application. Then we will jump into Databricks – a simple, integrated development environment, where you can even use your familiar SQL skills to tackle the analysis of vast quantities semi-structured data.
Do you really need Apache Spark?
There are many data frameworks that allow you to process data and you probably have your favorite tool already in your tool belt. You’re familiar with its syntax and you know its caveats or limitations; so what is a reason to learn yet another framework?
If you are struggling in a project that has to deal with a high volume of unstructured data, and you need to get a measure of business insight from it, you probably need to use a completely different computing framework; one that allows you to process the data with ease without waiting hours for the results.
Old school approach
The first question that arises is, why can’t you use Relational Database Systems (RDBMS) with many disks to do large-scale analysis? Why would you need a completely new data framework? The answer to these questions comes from the way that disk drives are evolving: seek time is improving more slowly than transfer rate. If the data access pattern is dominated by seeks, it will take longer to read or write large portions of the dataset than it would by streaming through it sequentially at the speed of the transfer rate. You can also buy a Massively-parallel processor (MPP) SQL appliance that could do the job for you. Beware though that, MPP gets used on expensive, specialized hardware tuned for CPU, storage and network performance, whereas a cheaper solution such as Hadoop runs on a cluster of commodity servers.
Meet Apache Hadoop
You may be asking, if the old-school RDBMS approach is not likely to be appropriate for very large unstructured data, why not just use Hadoop with its classical MapReduce approach? It seems to be a mature technology as all 100 fortune companies like Google, Facebook, Twitter and LinkedIn use it to harness their Big Data.
The Hadoop ecosystem emerged as a cost-effective way of working with such large data sets. It imposes a divide-and-conquer programming model, called MapReduce. Computation tasks are broken into units that can be distributed around a cluster of commodity servers, thereby providing cost-effective, horizontal scalability. Underneath this computation model is a distributed file system called Hadoop Distributed Filesystem (HDFS).
MapReduce involves a two-step batch process:
- Map phase – first, the data is partitioned and sent to mappers generating key value pairs;
- Reduce phase – the key value pairs are then collated, so that the values for each key are together, and then the reducer processes the key value pairs to calculate one value per key.
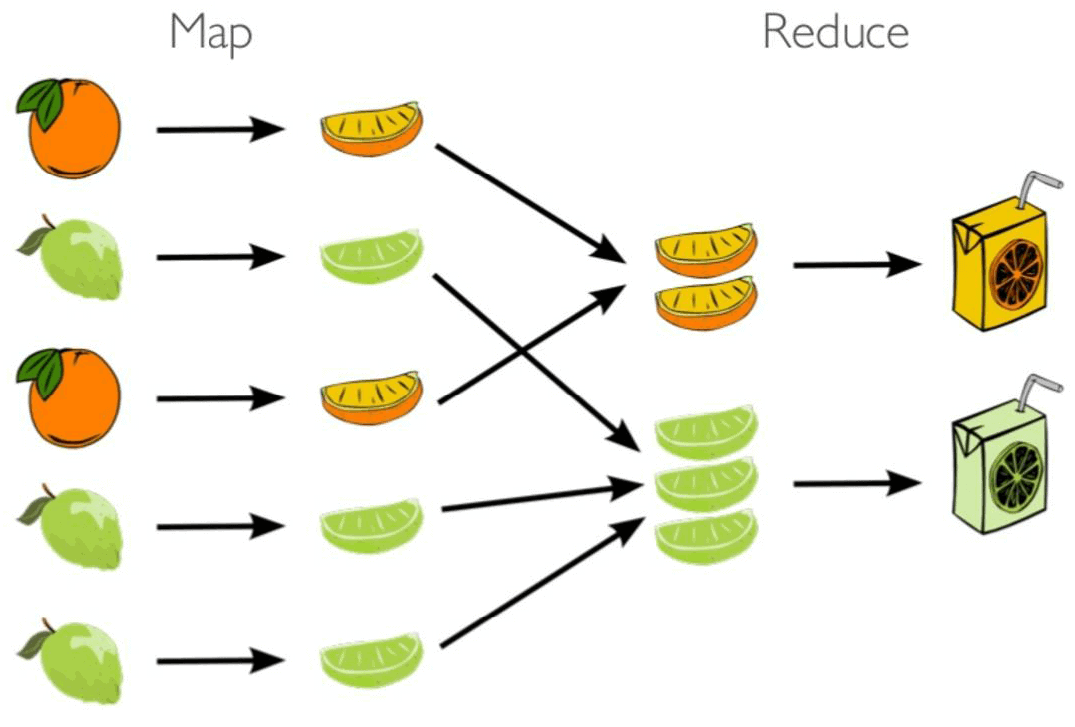
Figure 1: MapReduce in one picture
Apache Hive is coming!
If we’re sure that RDBMS is not the right tool for our job, let’s use Hadoop! However, a challenge remains to determine a way of moving to Hadoop an existing data infrastructure based on traditional relational databases? What about the large base of SQL users, database developers and administrators, as well as casual users who use SQL on a daily basis?
SQL, first developed by IBM in the early 1970s., is widespread for a reason. It’s an effective, intuitive model for organizing and using data. Mapping these familiar data operations to the low-level MapReduce Java API can be daunting, even for experienced Java developers. This is where Apache Hive comes in. Apache Hive grew in Facebook. They needed a way to manage and learn from the huge volumes of data that Facebook produced every day from its burgeoning social network. After trying a few different systems, the team chose Hadoop for storage and processing, since it was cost-effective and met the scalability requirements. Apache Hive was created to make it possible for analysts with strong SQL skills, but meager Java programming skills, to run queries on the huge data volumes stored in HDFS.
Apache Hive provides a SQL dialect, called Apache Hive Query Language (abbreviated Apache HiveQL or just HQL) for querying data stored in a Hadoop cluster. Behind the scenes, it translates most queries to MapReduce jobs, thereby exploiting the scalability of Hadoop, while presenting a familiar SQL abstraction. It means that Apache Hive does this drudgery for you, so you can focus on the query itself. Hive even supports an ODBC driver so that existing applications are easier to convert.
Figure 2: Facebook data scientist reality
Sooner or later, data scientists in Facebook realized that working with datasets always loaded from the disk are very slow. It turned out that two most important performance killers are disk IO operations and data serialization and replication in HDFS. They wanted a framework that operates in memory instead of writing and reading all intermediate steps of computation from disk.
Getting started with Apache Spark
Spark is known for being able to keep large working datasets in memory between jobs. Thanks to this, many distributed computations, even ones that process terabytes of data across dozens of machines, can run in a few seconds. It provides a performance boost that is up to 100 times faster than Hadoop. Unlike most of the other Big Data processing frameworks, Spark does not use MapReduce as an execution engine; instead, it uses its own distributed runtime for executing work on a cluster.
Spark can be used with Python, Java, Scala, R, SQL and recently in .NET, so it is up to you to select your favorite programming language. It is written in Scala, and runs on the Java Virtual Machine (JVM). You can run it either on your laptop or a computing cluster, all you need is an installation of Java 6+.
The first step in using Spark is to download and unpack it. Let’s start by downloading a recent precompiled version of Spark. Select the package type of “Pre-built for Hadoop 2.7 and later,” and click “Direct Download.” This will download a compressed file.
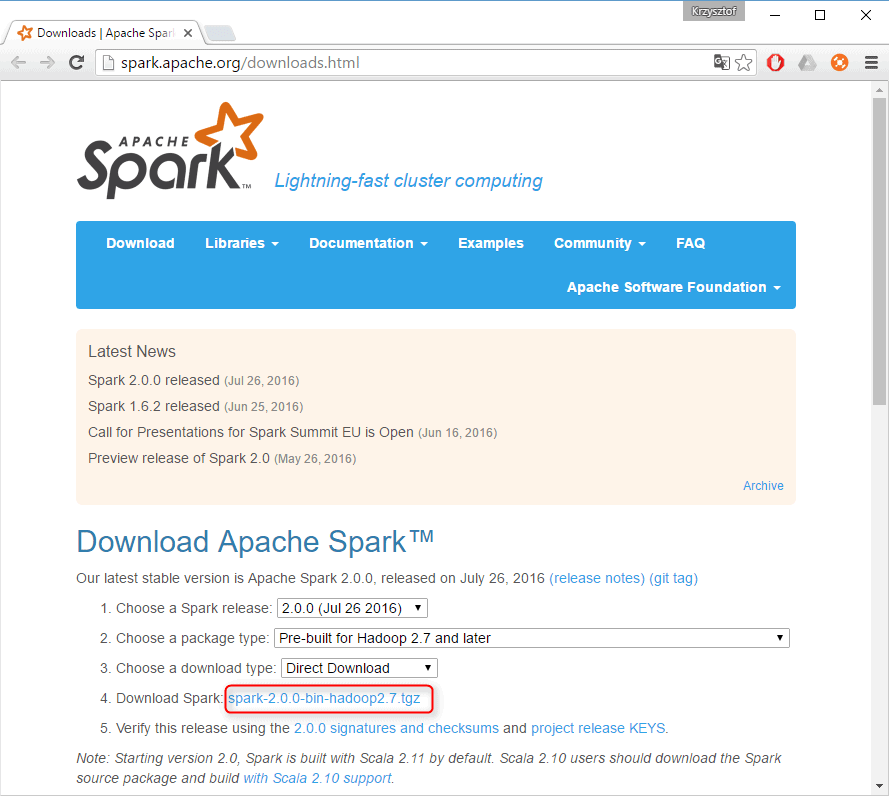
Figure 3: Apache Spark official download page
If you are a Windows user like me, you may run into issues installing Spark into a directory with a space in the name. Instead, install Spark in a directory with no spaces (e.g., C:\spark). You also don’t need to have Hadoop cluster in place, but as you are Windows user you need to mimic the Hadoop environment. To do this:
- Install Java Development Kit on your machine.
- Create a local directory (e.g. C:\spark-hadoop\bin\) and copy there Windows binaries for Hadoop (winutils.exe)
- Add environment variable called HADOOP_HOME and set value to your winutils.exe location.
To start with Spark, let’s run an interactive session in your command shell of choice. Go to your Spark bin directory and start up the shell with the following command: spark-shell. The shell prompt should appear within a few seconds. It is a Scala REPL (read-eval-print loop) with a few Spark additions.
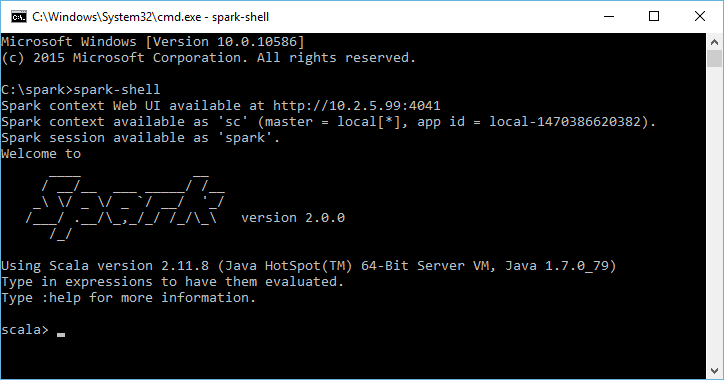
Figure 4: Apache Spark shell welcome screen
The easiest way to demonstrate the power of Spark is to walk through the example from the Quick Start Guide in the official Spark documentation. Spark’s primary abstraction is a distributed collection of items called a Resilient Distributed Dataset (RDD). Once created, RDDs offer two types of operations: transformations and actions. Actions compute a result based on an RDD. Let’s make a new RDD from the text of the README file in the Spark source directory:
|
1 2 3 4 5 6 |
scala> val textFile = sc.textFile("README.md") textFile: org.apache.spark.rdd.RDD[String] = README.md MapPartitionsRDD[1] at textFile at :24 scala> textFile.count() // Number of items in this RDD res0: Long = 99 scala> textFile.first() // First item in this RDD res1: String = # Apache Spark |
Figure 5: First action in Spark shell
One example of an action we called in above example is count, which returns number of elements in an RDD. Transformations, on the other hand, construct a new RDD from a previous one. So let’s use a filter transformation to return a new RDD with a subset of the items in the file.
|
1 2 3 4 5 |
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark")) linesWithSpark: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at :27 scala> linesWithSpark.take(10) res0: Array[String] = Array(# Apache Spark, Spark is a fast and general cluster computing system for Big Data. It provides, rich set of higher-level tools including Spark SQL for SQL and DataFrames,, and Spark Streaming for stream processing., ...) |
Figure 6: Transformation example in Spark shell
Although you can define new RDDs using transformations at any time, Spark computes them only in a lazy fashion – that is, the first time an action is used. This approach might seem unusual at first, but makes a lot of sense when you are working with Big Data. Consider the above example, where we defined a text file and then filtered the lines that include Spark keyword. If Spark were to load and store all the lines from the file as soon as we wrote lines = sc.textFile(…), it would waste a lot of storage space, given that we then immediately filter out many lines. Instead, it computes and returns only this data that are a result of all transformations.
This wouldn’t be a complete picture of Big Data framework, if we didn’t have a word count example Spark can implement MapReduce pattern easily. So, let’s do this in last example:
|
1 2 3 4 5 6 7 8 |
scala> val wordCounts = { textFile | .flatMap(line => line.split(" ")) | .map(word => (word, 1)) | .reduceByKey((a, b) => a + b) | } wordCounts: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[9] at reduceByKey at :29 scala> wordCounts.collect() res6: Array[(String, Int)] = Array((means,1), (under,2), (this,3), ...) |
Figure 7: Word count example in Spark shell
Here, we have combined the flatMap, map, and reduceByKey transformations to compute the per-word counts. To collect the word counts, we can use the collect action. As you can see, it is pretty simple to implement this word count example on a single machine. Keep in mind that, in a distributed framework, it is a common challenge because it involves processing data from many nodes.
Spark records into log files the detailed progress information that is produced by the driver and executor processes. However, there is a better way to learn the behavior and performance of your application. Spark, out of the box offers a web UI that contains detailed information about the jobs being executed. This is Spark’s built-in web UI available on the machine where the driver is running (by default on 4040 port). You can easily analyze and monitor the progress of execution in order to help you to tweak your code for better performance.
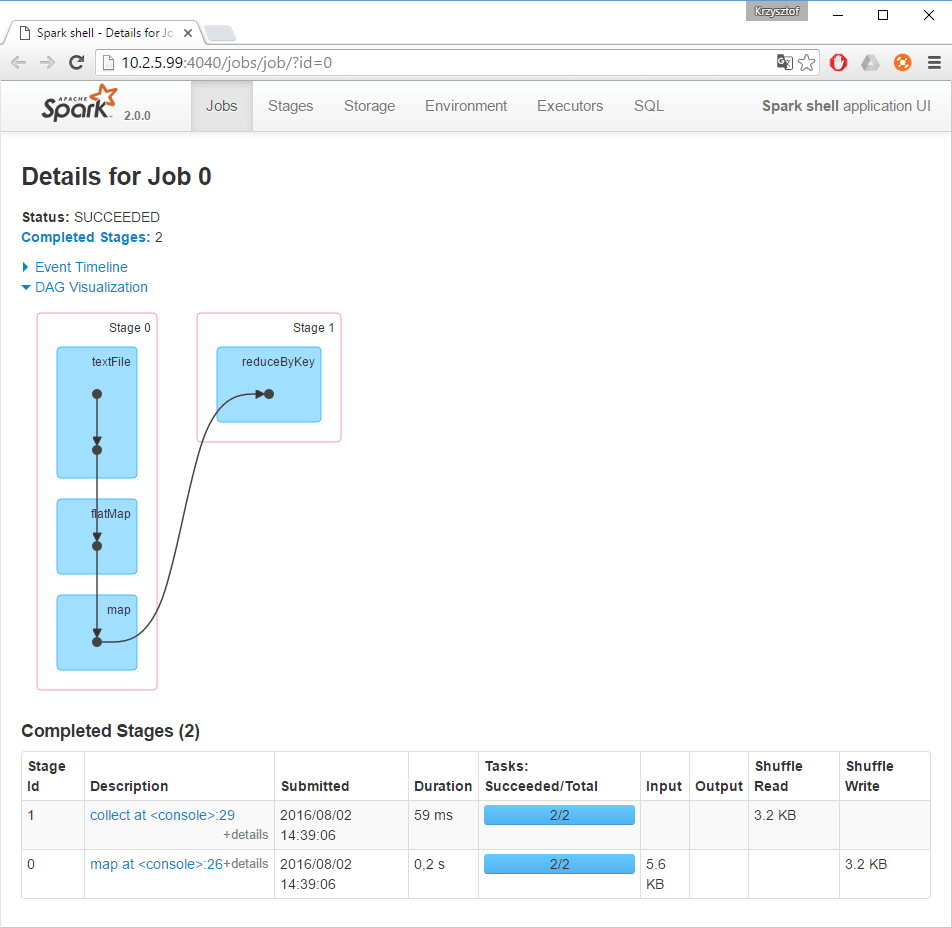
Figure 8: Spark’s built-in web UI
In Spark, a job is associated with a chain of RDD dependencies organized in a direct acyclic graph (DAG). Another great feature of Spark UI is DAG visualization. It is a great way to learn how the application is executed step by step. You can see that each RDD maintains a pointer to one or more parents along with metadata about the type of relationship that they have. It constitutes the lineage of an RDD.
Databricks Community Edition – you owe yourself to have a cluster!
Apache Spark is a sophisticated distributed computation framework for parallel code execution across many machines. While the abstractions and interfaces are simple, the same isn’t true for managing clusters of computers and ensuring production-level stability. Databricks, a company founded by the creators of Spark, makes Big Data simple by providing Apache Spark as a hosted solution. A free Databricks Community Edition (DCE) service enables everyone to learn and explore Apache Spark by providing access to a simple, integrated development environment. That means you don’t have to learn complex cluster management concepts or perform tedious maintenance tasks to take advantage of Spark! All you need to do is to register, click one button and voilà, you have your own Big Data cluster in a cloud!
Figure 9: Databrics service welcome page
First thing what you should do after logging into DCE is to read that great publication A Gentle Introduction to Apache Spark on Databricks. After that, you will be familiar with concepts such as workspace or notebook. The next step is to create a cluster by means of one click of your mouse.
Figure 10: Creating cluster in DCE
At the time of writing this article, you will receive a free cluster with 48 GB memory and 7 CPU cores for worker nodes, and 6 GB and almost 1 CPU for a driver. This sounds promising, so let’s go and write some code! Instead of doing “hello world” examples, let’s jump to some real world data from Wikipedia. DCE offers an access 3.2 billion requests from Wikipedia collected during the month of February 2015. Let’s use it in our first notebook. We will use Databricks library for CSV file reading.
|
1 2 3 4 5 6 7 |
// Load the raw dataset stored as a CSV file val clickstreamRaw = sqlContext.read .format("com.databricks.spark.csv") .option("header", "true") .option("delimiter", "\t") .option("inferSchema", "true") .load("dbfs:///databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed") |
Figure 11: Loading Wikipedia data source in DCE notebook
As we loaded around 1 GB of aggregated data, it would be valuable to use a more efficient format to store it. Without going into the details, as it is out of scope for this article, the best option is to use some columnar storage such as Parquet.
|
1 2 3 4 5 |
// Convert the dataset to a more efficent format to speed up our analysis clickstreamRaw.write .mode("overwrite") .format("parquet") .save("/datasets/wiki-clickstream") |
Figure 12: Converting CSV to columnar format
After saving to Parquet, we were able to limit the size of the dataset from circa 1GB to 280 MB which is a pretty good compression ratio. It also allows us to reduce execution time from 40 sec to 0.68 sec!
|
1 2 3 4 |
// Read Parquet file val clicks = sqlContext.read.parquet("/datasets/wiki-clickstream"); // Register sql table in the SQLContext clicks.registerTempTable("myWikiTable") |
Figure 13: Reading compressed file and registering SQL table
Having all clickstream Wikipedia data from February 2015, we can now use it to find out what was the most interesting topic at that moment. Since Spark is a unified platform, we can switch between different programming languages and choose the best one for the job. In that case we will use Spark SQL.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
%sql // Find the most popular wiki site select prev_title, curr_title, n from myWikiTable where prev_title not like 'other%' and prev_title != 'Main_Page' order by n desc limit 10 |
Figure 14: Finding the most popular Wikipedia site in February 2015
Unsurprisingly, the most interesting article was about the movie Fifty Shades of Grey, because February was Oscar season. The wiki movie website was visited around 370k times.

Figure 15: Notebook query results in tabular format presented
Documentation and books
There are a lot of books, blogs and official technical documentation available on the Apache foundation and Databricks site. There is also an official Apache Spark channel available on YouTube, where you can find many interesting webinars, including e.g. Spark Essentials with Adam Breindel or Srini Penchikala introduction to Spark.
If you would like to start your journey with Spark and looking for a book, I would recommend Learning Spark as a starter. Databricks Community Edition is also a great platform to learn Spark. Since its launch, tens of US universities have already used it for teaching, including UC Berkeley and Stanford. To make learning Apache Spark even easier, DCE gives you three notebooks to provide a “gentler” introduction to Apache Spark. You can find these new notebooks here:
- A Gentle Introduction to Apache Spark on Databricks
- Apache Spark on Databricks for Data Engineers
- Apache Spark on Databricks for Data Scientists
Summary
Spark is growing fast and the community becomes larger and larger day by day. Recently, the new 2.0 version has been released with a lot of new features. It is considered as a next-generation ETL framework, thanks to its flexibility, scalability, conciseness, team-based development capabilities and great performance. If you are a data scientist or an engineer interested in modern data processing Apache Spark should be at the top of your learning list.
Load comments