

This article is based on exciting information just released at Microsoft’s Build conference on May 23, 2023.
What we have today
When Synapse Analytics was created, technical sessions inspired me with some comparisons and explanations, and I reproduced them in my own technical sessions and writing.
Synapse was created from a request from many Microsoft customers. They requested to be able to use one single tool for the entire data intelligence platform: Ingest Data, store, process, query, apply data science, and generate reports.
Synapse is a real Swiss Army knife: We can make ingestion using Synapse Data Factory; query and process the data using different methods, Serverless SQL Pool or Dedicated SQL Pool; and apply data science using spark pool and additional ML frameworks. Finally, Synapse is also linked to Power BI, allowing us to use some shortcuts to create visualizations.
This unique set of features were always great, much better than the isolated tools we had before. But on the light of Microsoft Fabric, we can notice the missing points on Synapse:
- The integration of the different tools was limited. It was the best for the time, but compared with Microsoft Fabric, the integration was limited.
- We still need to decide between different infrastructure resources, such as Serverless SQL Pool and Dedicated SQL Pool, instead of using all together over the data.
- We still need to make decisions about infrastructure, especially the size of the dedicated SQL Pool. Many times, decisions were based mostly by guess.
- It doesn’t totally isolate storage and processing. When using a Dedicated SQL Pool, processing and storage are tied together.
Synapse is considered so advanced that only a few noticed these problems, and not all the problems. Microsoft Fabric, the new product announced during BUILD, exposes to us this and more.
What’s Microsoft Fabric
Like Synapse, Microsoft Fabric brings all the services needed for a data intelligence environment aggregated together, heavily integrated and built in a way that requires far less technical effort for the implementation.
The image below illustrates the services included in Microsoft Fabric
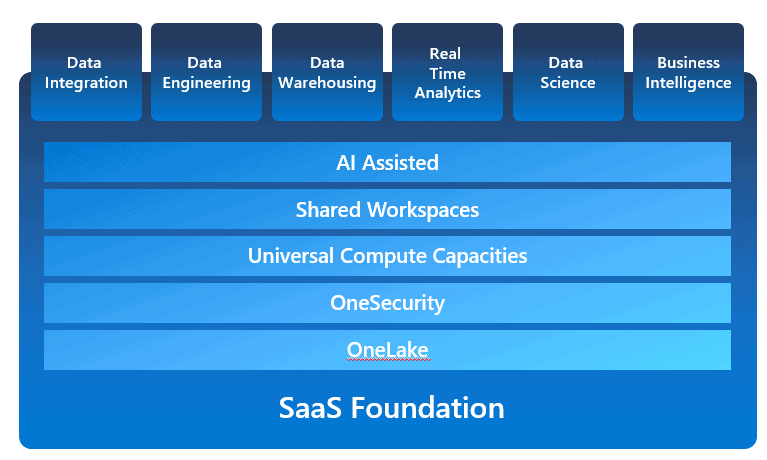
In the following sections I will introduce these new concepts.
Data Intelligence as Software as a Service (SaaS)
Microsoft Fabric arrives, breaking standards and solidifying new ones. In the cloud environment, we are used to classify the services as Infrastructure as a service (IaaS), Platform as a service (PaaS) and SaaS. Synapse is classified as a PaaS, while Microsoft Fabric is officially classified as SaaS. The following chart shows the general areas that each level of management that each level of hosted management provides.
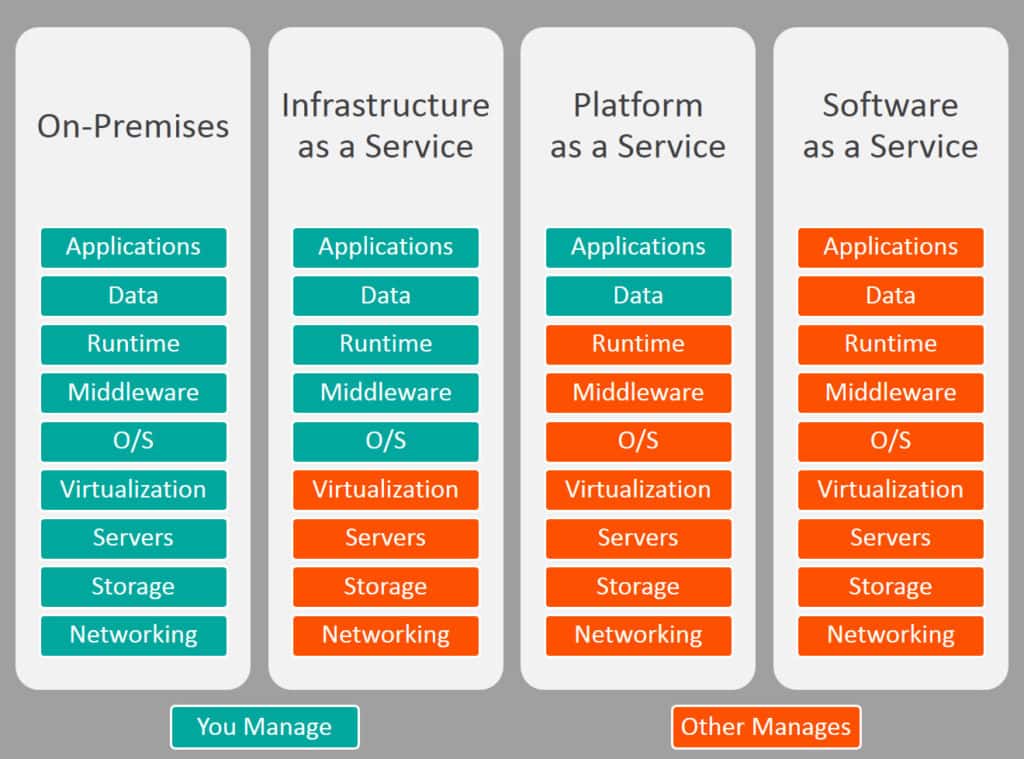
Undoubtedly, the level of managed services provided by Microsoft Fabric is way above Synapse. Many tasks in Synapse would need to be carefully configured, yet in Microsoft Fabric brings a kind-of auto-settings, just working out of the box.
Usually, when we think about a SaaS service, we think about an end user application, such as Office 365 or many other applications where the user just uses it. It’s a concept that usually doesn’t match software used to ingest, transform, model and generate intelligent results from data.
That’s what Microsoft Fabric is, a software breaking the barriers of what we know about cloud software and services.
A different environment
Microsoft Fabric is not located inside the Azure environment but rather inside Power BI Portal. This leads to a very different environment than the one we have in Synapse.
But the new environment is not like anything we know about Power BI Portal as well. The environment is organized for different experiences: You select a experience according to the kind of task you would like to execute, and the environment will adapt to the usual tasks related to this experience.
The following experiences are available:
- Power BI: The typical Power BI environment and tools
- Data Factory: Using this persona, you can create and manage dataflows and data pipelines as in data factory.
- Data Activator: This is an entirely new feature which enables you to create triggers over your visuals in Power BI
- Data Engineering: This experience involves multiple tasks. It’s responsible for creating and managing the lakehouses, but it’s also the one that will allow you to create notebooks and orchestrate them with pipelines.
- Data Science: Using this experience, you can apply Azure ML techniques over your data.
- Data Warehouse: This experience allows you to model your data as in a SQL database and use SQL over your data. It’s difficult to compare this to anything else. We can create many star models over our data lake and these models will be reused by our Power BI datasets, making it easier to have a central model for all our reports.
- Real-time Analytics: This persona is in some ways comparable with Power BI Streaming Dataflows, allowing ingestion of real time data.

Changing from ingestion (Data Factory), processing (Data Engineering), Modelling and SQL (Data Warehouse), and more is just a matter of choosing the correct experience to make the work over the same sets of data.
The change of the personas is like a method to focus the environment on the kind of activities you would like to execute. The object’s creation itself is still happening inside a Power BI workspace.
Besides that, the main new objects: a lakehouse and a data warehouse, have their own way to switch the work between one and another.
Microsoft Fabric and OneLake
OneLake is the core service in Microsoft Fabric. It provides a data lake as a service, allowing us to build our data lake without all the trouble of provisioning it first. It’s the central data storage for all data in Microsoft Fabric and it’s provisioned for the tenant when the first Microsoft Fabric artifact is created.
The name OneLake also matches very well with the shortcut feature in the OneLake: We can create shortcuts to files located externally and access them directly as if they were in our own lake.
The image below illustrates how the OneLake relates with the other Microsoft Fabric features.
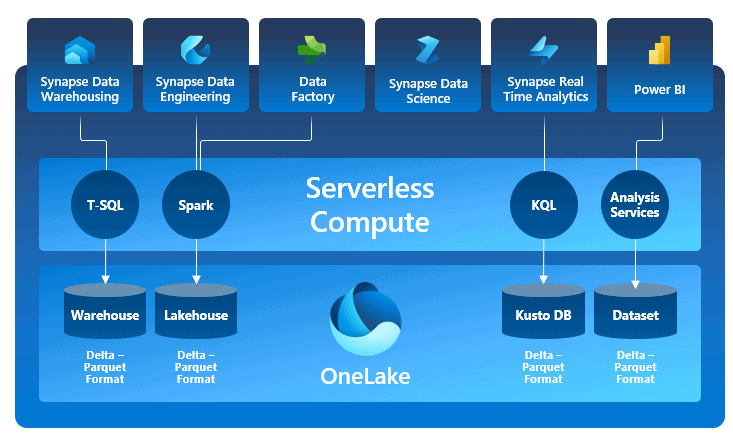
Onelake, Lakehouse and Workspaces
The lakehouse is one of the core objects we can create inside a Onelake. We create the lakehouse using the Data Engineer persona and the lakehouse will be contained inside a Workspace, which we know as a Power BI Workspace.
Once we create a lakehouse, we can use Data Factory to ingest data into the files area or the tables area.
The Files area is the unmanaged area of the lake, which accepts any kind of file. That’s where we put the RAW files for further processing. The Tables, on the other hand, contains data only in Delta format.
The lakehouse optimizes the Tables area with a special structure capable to make a regular delta table up to 10x faster while still maintaining full Delta format compliance.
However, the lakehouse is not the biggest data structure we have. This position is reserved for the OneLake. It is an invisible, auto-provisioned data storage containing all the data for data warehouse, lakehouses, datasets and more.
In this way, we can build an enterprise architecture using Workspaces to hold departmental lakehouses. The data can be shared across multiple departments using lakehouse shortcuts. This ensures the domain ownership of the data and a relationship between domains at the same time.
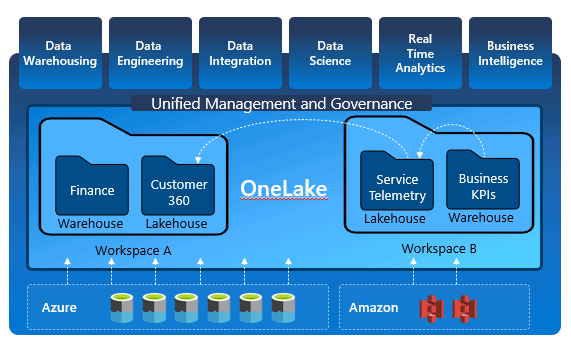
This is only the starting point of an enterprise architecture: The OneLake ensures a unified management and governance of the data. Data Lineage, Data Protection, Certification, Catalog Integration and more are unified features provided by the OneLake to all lakehouses created in an enterprise.
All these features are inherited from the Power BI environment, ensuring an Enterprise Governance environment to the company.
OneLake and Processing Isolation
When using Synapse, the Synapse Dedicated Pool stores and process the data. This is a scenario where storage and processing are tied together.
In OneLake, storage and processing are independent. The same data in the OneLake can be processed by many different methods, ensuring the storage and processing independence.
Let’s analyse the different methods we have available to process the data in OneLake.
Spark Notebooks
All the workspaces enabled for Microsoft Fabric have a feature called Live Pool. The Live Pool allows the execution of notebooks without the need to previously make the Spark Cluster configuration.
Once the first code block is executed in a notebook, the Live Spark Pool kicks in in a few seconds and makes the execution.
We can process the OneLake data using Spark Notebooks with the advantage of the Live Pools
Data Factory
Data Factory objects, such as pipelines and dataflows, inside the Power BI environment are a start of a unification of the ETL tools: We have the Pipelines and Dataflows from data factory and the dataflows from Power BI.
These two are now united and working together under Microsoft Fabric. We have an additional advantage: the Dataflows Gen2.
The Dataflows Gen2 are an advance in relation to the Power BI Dataflows or Wrangling Dataflows we are used to. One of the most interesting features, in my opinion, is the possibility to define the target of a transformation, what we never could do in Power BI Dataflow (or Wrangling Dataflows)
SQL Queries
The Microsoft Fabric provides two different methods to access the data using SQL, as if the data is in a regular database.
One of the methods is using the Lakehouse object. This object provides us a SQL Endpoint, which allows us to model the tables and query the data using SQL.
The second method uses a Data Warehouse object, which provides a complete SQL processing environment over the data in the OneLake.
The table below highlights all the differences between the Lakehouse SQL Endpoint and the Data Warehouse. Some of these differences are available in the documentation; some are my personal conclusions.
|
Microsoft Fabric Offering |
Warehouse |
SQL Endpoint of the Lakehouse |
|
Processor Engine |
SQL MPP – Polaris |
|
|
Optimization Engine |
Vertipaq |
Vertipaq for Tables |
|
Storage Layer |
Open Data Format – Delta |
|
|
Primary Capabilities |
ACID compliant Full data warehouse with transactions support in T-SQL |
Read Only, system generated SQL Endpoint for lakehouse for T-SQL Querying and serving. Supports queries and views on top of lakehouse delta tables only |
|
Recommended Use Case |
|
|
|
Development Experience |
|
|
|
T-SQL Capabilities |
Full DQL, DML and DDL T-SQL support. Full transaction support |
Full DQL, no DML, limited DDL T-SQL Support such as SQL Views and TVFs |
|
Data Loading |
SQL, pipelines, dataflows |
Spark, pipelines, dataflows, shortcuts |
|
Delta Table Support |
Reads and Write Delta Table |
Reads Delta table |
Power BI
Microsoft Fabric is deeply linked to the Power BI environment. We can in many points of our work, either from a lakehouse or a warehouse, start the creation of a Power BI report.
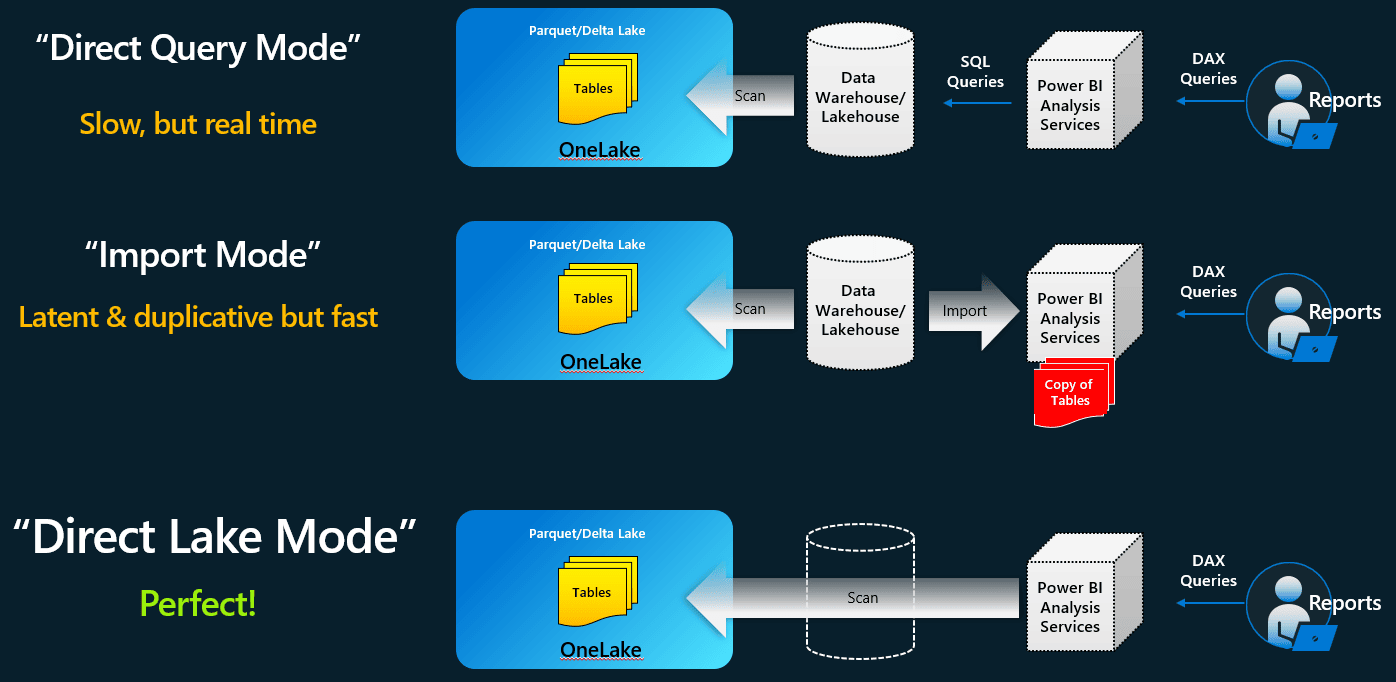
The best is the access method: Power BI has a new access method to the OneLake, called Direct Lake.
Direct Lake is a new connection method between Power BI Datasets and the OneLake.
When we use DirectQuery, every refresh requires a new load of the source, which makes the connection slower. On the other hand, when we use Import, the data is stored in memory and the performance is better, but when the data is updated, a refresh on the dataset is needed. Updates are not immediately visible on datasets and reports.
The Direct Lake connection mix the best of both scenarios: It has the performance of the Import mode for keeping the data in memory, and the real time update of the data achieved by the DirectQuery.
What about Azure Synapse and Data Factory
Customers using Data Factory and Synapse Dedicated Pool can also expect easy ways to migrate to Microsoft Fabric. Micorosoft is focused on making the transition as smoothy as possible.
Data Factory users have even the benefit of Gen2 dataflows, which are not supported by Azure data factory. So, you have advantages in developing dataflows and pipelines using Microsoft Fabric and you will an easy migration path from one to another.
Conclusion
Microsoft Fabric seems to be the start of a new era. In a time of Open AI/ChatGPT and co-pilots, we are getting an extremely powerful tool making complex data solutions accessible to all companies and the in the future we can think about a co-pilot for Microsoft Fabric
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments