
(Updated 14th Jan 2012, 26th Jan 2012, and 3rd Aug 2017)
Every so often, before SQL Server 2016, the question came up on forums of how to pass a list as a parameter to a SQL procedure or function.
Nowadays, of course, one uses the STRING_SPLIT() function ….
|
1 2 |
DECLARE @tags VARCHAR(200) = 'Yan,Tyan,Tethera,Methera,Pimp,Sethera,Lethera,Hovera,Dovera,Dik,Yanadik,Tyanadik,Tethera dik,Methera dik,Bumfitt,Yanabumfit,Tyanabumfitt,Tetherabumfitt,Metherabumfitt,Giggot' SELECT value FROM STRING_SPLIT(@tags, ',') |
There was a time that I used to love this question because one could spread so much happiness and gratitude by showing how to parse a comma-delimited list into a table. Jeff Moden has probably won the laurels for the ultimate list-parsing TSQL function, the amazing ‘DelimitedSplit8K’. Erland Sommarskog has permanently nailed the topic with a very complete coverage of the various methods for using lists in SQL Server on his website.. With Table-Valued parameters, of course, the necessity for having any lists in SQL Server is enormously reduced, though it still crops up.
Element-based XML seems, on the surface, to provide a built-in way of handling lists as parameters. No need for all those ancillary functions for splitting lists into tables, one might think. Yes, indeed, but be careful of the XQuery syntax that you use, as we’ll see.
Let’s just take the very simplest example of taking a list of integers and turning it into a table of integers. One can use a simple element-based XML list based on a fragment like this…
|
1 2 |
DECLARE @XMLlist XML SELECT @XMLList = '<list><i>2</i><i>4</i><i>6</i><i>8</i><i>10</i><i>15</i><i>17</i><i>21</i></list>' |
…to give a table like this ..
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
IDs ----------- 2 4 6 8 10 15 17 21 (8 row(s) affected) |
..by using this TSQL expression
|
1 2 |
SELECT x.y.value('.','int') AS IDs FROM @XMLList.nodes('/list/i') AS x ( y ) |
It isn’t as intuitive as a simple comma-delimited list to be sure, but it is bearable. In small doses, this shredding of element-based XML lists works fine, but,<added 26th January> using this particular syntax for getting the value of the element </added 26th January> one soon notices the sigh from the server as the length of the list starts to increases into four figures. Try it on a list of a hundred thousand integers and you’ll have time to eat a sandwich.
OK. Let’s do a few measurements and do a graph.
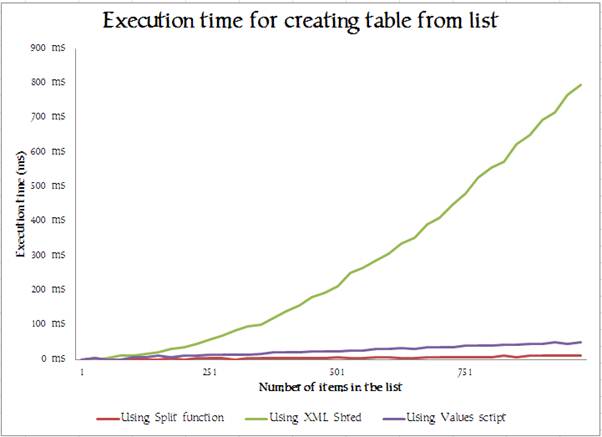
Jeff Moden’s Split function, scales beautifully as shown by the red line, and it is difficult to measure it, it is so quick. The XML eShred technique by contrast, using the element-based list, and this XQuery syntax, exhibits horrible scaling. This sort of curve is enough to strike terror into the developer. Just as a comparison, I did the process of taking a list and turning it into a table by creating a VALUES expression from the list. Even this took longer than Jeff’s function, presumably because of the overhead of compiling the expression. Of course, the comparison is rather unfair because this third approach , the ‘Using Values Script’ approach, does no validation, but still one wonders what on earth the XML expression is DOING all that time. It must be gazing out the window, reading the paper and scratching itself, one assumes. No. Actually, the CPU is warming up on the task, so it involves frantic activity.
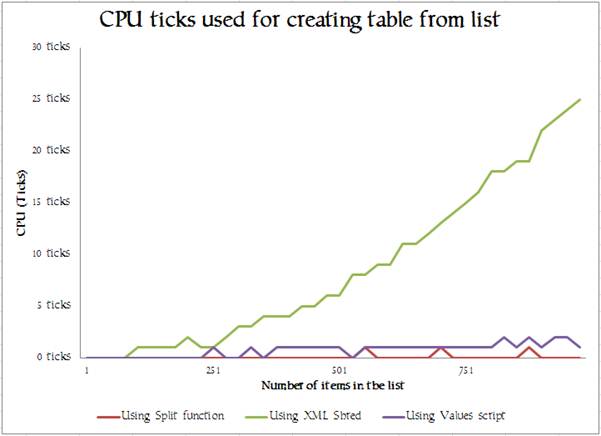
Operations involving XML can be startlingly fast in SQL Server, but this particular critter seems startlingly slow once one gets to a three-figure number in the list that you’re turning into a relation that can then be used in SQL Expressions. Imagine this getting loose in a production system when someone starts passing more values in the list and the database suddenly slows down. How would you track the problem down?
<added 26th January>The big problem here is one of the expression. As pointed out by a reader of the blog, if you modify the expression slightly to
|
1 2 |
SELECT x.y.value('.','int') AS IDs FROM @XMLList.nodes('/list/i/text()') AS x ( y ) |
The shredding suddenly goes like a rocket</added 26th January>.
There is a second, and more wordy version of the simple XML list, The attribute-based list. Here
|
1 2 |
DECLARE @XMLlist XML SELECT @XMLList = '<list><y i="2" /><y i="4" /><y i="6" /><y i="8" /><y i="10" /><y i="15" /><y i="17" /><y i="21" /></list>' |
…to give exactly the same table ..
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
IDs ----------- 2 4 6 8 10 15 17 21 (8 row(s) affected) |
by using a very similar syntax like this…
|
1 2 |
SELECT x.y.value('@i','int') FROM @XMLList.nodes('list/y') AS x( y ) |
‘Eh? What difference could this make?’, you’re wondering. Well, rather a lot, it turns out. Thanks to a reader comment on the first version of this blog by wBob, we can reveal that this version scales as well as Jeff’s amazing ‘split’ function. I must admit to being rather surprised at the difference in performance of the two. By using the Attribute-based list, or the modified XQuery expression, you can cheerfully pass lists of substantial length to procedures without worrying, it seems. It reminded me of an argument I had some years ago with a distinguished Database Developer who was advising us all not to use XML-based lists because of their performance problems. I’d been using attribute-based lists simply because I copied Bob Beauchamin’s example code in ‘The Book’, and hadn’t hit any problem. We couldn’t convince each other. Perhaps we’d hit this performance difference.
<added 26th January>We can even improve on this. as Sviridov Konstantin has pointed out, you can tweak it to the point that it goes around twice the speed of Jeff’s TSQL split function by using syntax like this…
|
1 2 |
SELECT x.y.value('.','int') FROM @XMLList.nodes('list/y/@i') AS x( y ) |
Which will give a performance comparison with the the TSQL split function. These modified XML shreds must be the fastest non-CLR method of transferring list-based data as a variable in SQL.
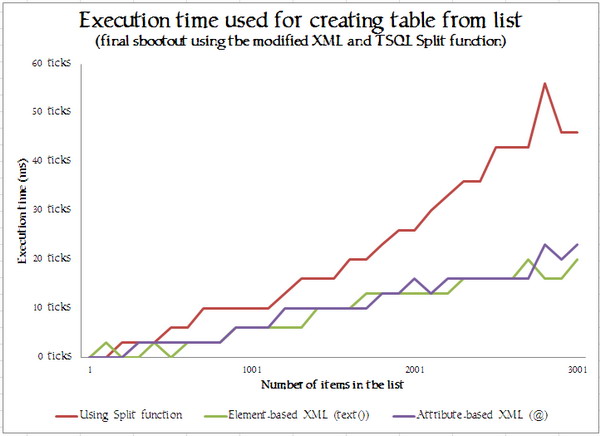
</added 26th January>XML in SQL Server seems to remind me of the old poem by Henry Wadsworth Longfellow. (1807-1882)
There was a little girl, who had a little curl
Right in the middle of her forehead,
And when she was good, she was very, very good,
But when she was bad she was horrid.’.
Just as a comparison, here is the horrid XML performing against the first attribute-based XML Shred, and the TSQL split function
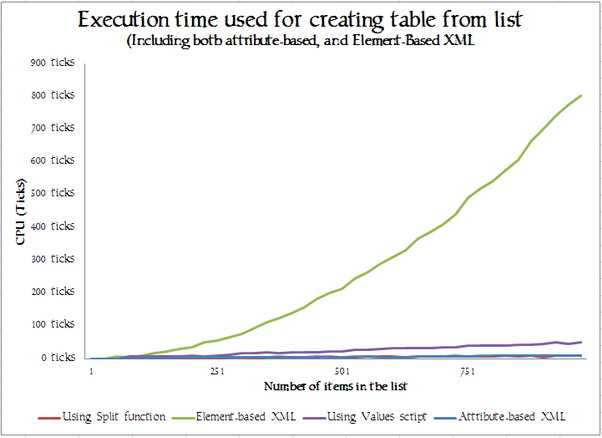
As always, one should measure everything you can, and take nothing for granted if you have to deliver a scalable application.
Here is the simple code I used to do the metrics. The results were simply pasted into excel and graphed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 |
--in order to record the timings, we prepare a log. DECLARE @log TABLE ( Log_Id INT IDENTITY(1, 1),TheeVent VARCHAR( 2000 ), [Values] INT, CPU FLOAT DEFAULT @@CPU_BUSY, DateAndTime DATETIME DEFAULT GETDATE()) ; --define working variables DECLARE @List VARCHAR(MAX),@XMLList XML,@AttributeBasedXMLList XML, @buildScript VARCHAR(MAX), @XMLbuildScript NVARCHAR(MAX), @ii INT, @Values INT; --and table variables to receive the results/relations DECLARE @ByteBucket TABLE (TheNumeral INT) DECLARE @ByteBucket2 TABLE (TheNumeral INT) DECLARE @ByteBucket3 TABLE (TheNumeral INT) DECLARE @ByteBucket4 TABLE (TheNumeral INT) DECLARE @ByteBucket5 TABLE (TheNumeral INT) DECLARE @ByteBucket6 TABLE (TheNumeral INT) SET NOCOUNT ON SELECT @Values=1 --start with one item in the list WHILE @Values<=3000 BEGIN --build up the list with random integers SELECT @List='1',@ii=@Values WHILE @ii>1 BEGIN SELECT @List=@List+','+CONVERT(VARCHAR(3),CONVERT(INT,RAND()*100)) SELECT @ii=@ii-1 -- .. to the required length END --and pre-prepare the XML List and VALUES script SELECT @XMLList='<list><i>'+REPLACE(@List,',','</i><i>')+'</i></list>' SELECT @BuildScript='SELECT x FROM (values ('+REPLACE(@List,',','),(')+'))d(x)' --and pre-prepare the XML List and VALUES script SELECT @XMLBuildScript='SELECT @AttributeBasedXMLList = ( SELECT x AS "@x" FROM (values (' +REPLACE(@List,',','),(')+'))d(x) FOR XML PATH(''y''), ROOT(''root''), TYPE )' EXEC sp_executesql @XMLBuildScript, N'@AttributeBasedXMLList XML OUT', @AttributeBasedXMLList OUT --try doing the delimited list function INSERT INTO @log (TheEvent, [Values]) SELECT 'Using Split function',@Values INSERT INTO @ByteBucket (TheNumeral) SELECT item FROM dbo.DelimitedSplit8K (@list,',') --use the XML Shred trick INSERT INTO @log (TheEvent, [Values]) SELECT 'Element-based XML',@Values INSERT INTO @ByteBucket2 (TheNumeral) SELECT x.y.value('.','int') AS IDs FROM @XMLList.nodes('/list/i') AS x ( y ) --use the XML Shred trick INSERT INTO @log (TheEvent, [Values]) SELECT 'Element-based XML (text())',@Values INSERT INTO @ByteBucket6 (TheNumeral) SELECT x.y.value('.','int') AS IDs FROM @XMLList.nodes('/list/i/text()') AS x ( y ) --try the VALUES method INSERT INTO @log (TheEvent, [Values]) SELECT 'Using Values script',@Values INSERT INTO @ByteBucket3 (TheNumeral) EXECUTE (@BuildScript) --use the XML Shred trick INSERT INTO @log (TheEvent, [Values]) SELECT 'Attribute-based XML',@Values INSERT INTO @ByteBucket4 (TheNumeral) SELECT x.y.value('@x','int') FROM @AttributeBasedXMLList.nodes('root/y') AS x(y) INSERT INTO @log (TheEvent, [Values]) SELECT 'finished',@Values --use the XML Shred trick INSERT INTO @log (TheEvent, [Values]) SELECT 'Attribute-based XML (@)',@Values INSERT INTO @ByteBucket5 (TheNumeral) SELECT x.y.value('.','int') FROM @AttributeBasedXMLList.nodes('root/y/@x') AS x(y) INSERT INTO @log (TheEvent, [Values]) SELECT 'finished',@Values SELECT @Values=@Values+100 END --Yes, we need to check that they all agree! SELECT COUNT(*), SUM(TheNumeral) FROM @ByteBucket UNION ALL SELECT COUNT(*), SUM(TheNumeral) FROM @ByteBucket2 UNION ALL SELECT COUNT(*), SUM(TheNumeral) FROM @ByteBucket3 UNION ALL SELECT COUNT(*), SUM(TheNumeral) FROM @ByteBucket4 UNION ALL SELECT COUNT(*), SUM(TheNumeral) FROM @ByteBucket5 UNION ALL SELECT COUNT(*), SUM(TheNumeral) FROM @ByteBucket6 SELECT TheStart.[Values], MAX(CASE WHEN TheStart.TheeVent ='Using Split function' THEN DATEDIFF( ms, TheStart.DateAndTime, Theend.DateAndTime ) ELSE 0 END) AS [Using Split function], MAX(CASE WHEN TheStart.TheeVent ='Element-based XML' THEN DATEDIFF( ms, TheStart.DateAnddTime, Theend.DateAndTime ) ELSE 0 END) AS [Element-based XML], MAX(CASE WHEN TheStart.TheeVent ='Using Values script' THEN DATEDIFF( ms, TheStart.DateAndTime, Theend.DateAndTime ) ELSE 0 END) AS [Using Values script], MAX(CASE WHEN TheStart.TheeVent ='Attribute-based XML' THEN DATEDIFF( ms, TheStart.DateAndTime, Theend.DateAndTime ) ELSE 0 END) AS [XML Attributes],*/ MAX(CASE WHEN TheStart.TheeVent ='Element-based XML (text())' THEN DATEDIFF( ms, TheStart.DateAndTime, Theend.DateAndTime ) ELSE 0 END) AS [Element-based XML (text())], MAX(CASE WHEN TheStart.TheeVent ='Attribute-based XML (@)' THEN DATEDIFF( ms, TheStart.DateAndTime, Theend.DateAndTime ) ELSE 0 END) AS [Attribute-based XML (@)] FROM @log TheStart INNER JOIN @log Theend ON Theend.Log_Id = TheStart.Log_Id + 1 WHERE TheStart.TheEvent<>'finished' GROUP BY TheStart.[Values]; SELECT TheStart.[Values], MAX(CASE WHEN TheStart.TheeVent ='Using Split function' THEN theEnd.cpu-TheStart.cpu ELSE 0 END) AS [Using Split function], MAX(CASE WHEN TheStart.TheeVent ='Element-based XML' THEN theEnd.cpu-TheStart.cpu ELSE 0 END) AS [Element-based XML], MAX(CASE WHEN TheStart.TheeVent ='Using Values script' THEN theEnd.cpu-TheStart.cpu ELSE 0 END) AS [Using Values script], MAX(CASE WHEN TheStart.TheeVent ='Attribute-based XML' THEN theEnd.cpu-TheStart.cpu ELSE 0 END) AS [XML Attributes], MAX(CASE WHEN TheStart.TheeVent ='Element-based XML (text())' THEN theEnd.cpu-TheStart.cpu ELSE 0 END) AS [Element-based XML (text())], MAX(CASE WHEN TheStart.TheeVent ='Attribute-based XML (@)' THEN theEnd.cpu-TheStart.cpu ELSE 0 END) AS [Attribute-based XML (@)] FROM @log TheStart INNER JOIN @log Theend ON Theend.Log_Id = TheStart.Log_Id + 1 WHERE TheStart.TheEvent<> 'finished' GROUP BY TheStart.[Values]; |
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments