


Edit on 25/10/2024: According to some official documentations, there is an inaccuracy on this blog.
The costs involved on data and processing are broken down in two parts: Storage and Processing. The Storage costs are the costs which goes to the source capacity hosting the data, while the processing cost stays with the consumer of the data.
This makes sense, a break down of responsibilities.
But I’m not sure if this completely explain the real scenario I faced, when a production environment stopped because the source of the shortcuts was in a capacity over its limits. There is a thread on reddit about this
Let’s start with a question:
Question: Where is the cost charted when one or more shortcuts in a lakehouse points to a table located in a different capacity ? From the capacity which holds the shortcut or from the capacity which holds the data?
Answer: The charges go to the capacity holding the data, the target of the shortcut
This simple feature brings many interesting consequences and possibilities.
Costs Accountability and Shortcuts
Consider that you have a distributed environment, where each department is building their own intelligence solution.
You decide to build a solution consuming data from two different departments through shortcuts.
Let’s consider Department A, Department B and Solution C consuming shortcuts from the two departments.
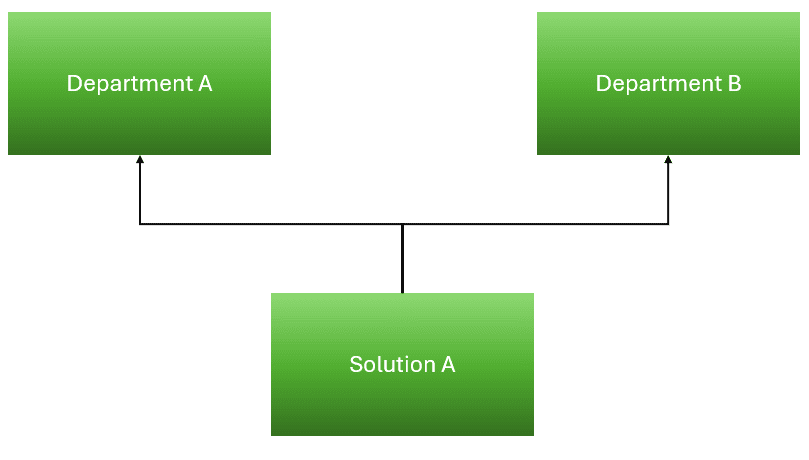
Considering the shortcuts’ behavior, the consumption costs goes to the capacities used by Department A and Department B.
The distribution of capacities in the company can be done in such a way to make each department responsible for the costs of the consumption of their data.
We can plan many more combinations in relation to capacity consumption, this is only a starting point.
Data Mesh
This feature is one more contribution towards a Data Mesh architecture. Each domain can have their own capacity, and the domain team will be the responsible for the costs related to the domain consumption
A Bad Side
One bad side in relation to this cost distribution is that you are adding one more failure point to your solution. If one in many capacities is over its capacity limit and refuses the execution, your solution may fail.
This is a reason, for example, why you should not make shortcuts from Production to Test or Development.
Reliability: One more possibility
This one is not related to shortcuts, but I thought it would be interesting to mention here.
What would happen if the region where your capacity is located goes down or has some intermittent outage?
Cry?
If your code objects (dataflows, notebooks, pipelines) are in their own workspaces, in case of an emergency, you can move the workspace to a capacity in a different region. In this way you achieve reliability against a region’s partial outage.
Data objects, such as lakehouse and data warehouse, can’t be moved to different regions, but code objects can. One more reason to isolate data from code.
Reference
You may would like to check this video:
Fabric Monday: 52: Managing Shortcuts
Summary
Considering shortcuts and capacity consumption, many different organization methods are possible.




Load comments