
First I found an article from a Brazilian explaining why Power BI is not an ETL. I’m surprised this kind of explanation was needed.
Some days later I found an article in English telling the opposite, talking about Power BI as an ETL tool. I was wrong. An explanation about this is critical and needed. When we mistake Power BI features as an ETL, we are one step away to believe Power BI is a tool to build a Data Warehouse. After that, everything goes downhill.
Let’s start from the extremely basic, what’s an ETL? ETL means Extract, Transform and Load. An ETL tool to Extracts data from a source, Transform the data and Load the data to a destination.
I think most of you will agree that SQL Server Integration Services (SSIS) and Azure Data Factory are ETL tools. At most some would define Data Factory as ELT, but the order doesn’t affect the final result.
These tools have something in common: They have support for many different data sources and they also support many different destinations. You can move your data basically from any source to any destination.
Usually the destination of the ETL is a Data Warehouse, but I think it’s better not tie this to the definition.
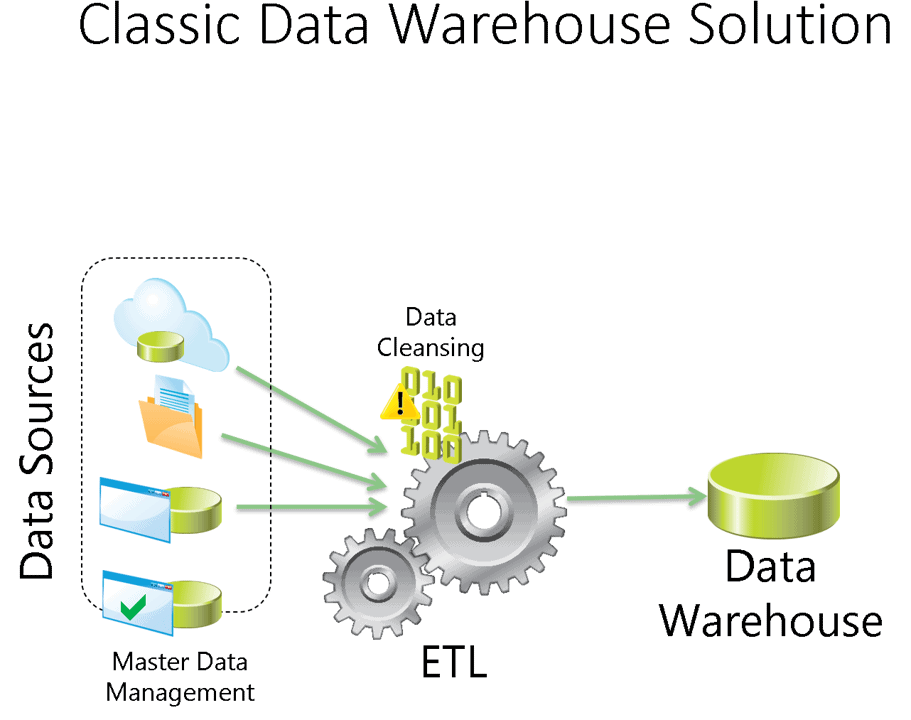
Power BI, on the other hand, using Dataflows and Power Query, can only move the data to Power BI, creating datasets. SQL Server Analysis Services (SSAS), is also capable of extract data from different data sources, make some transformations and load it to its tabular semantic model. However, no one never mistakes Analysis Services as an ETL tool, why they mistake Power BI?
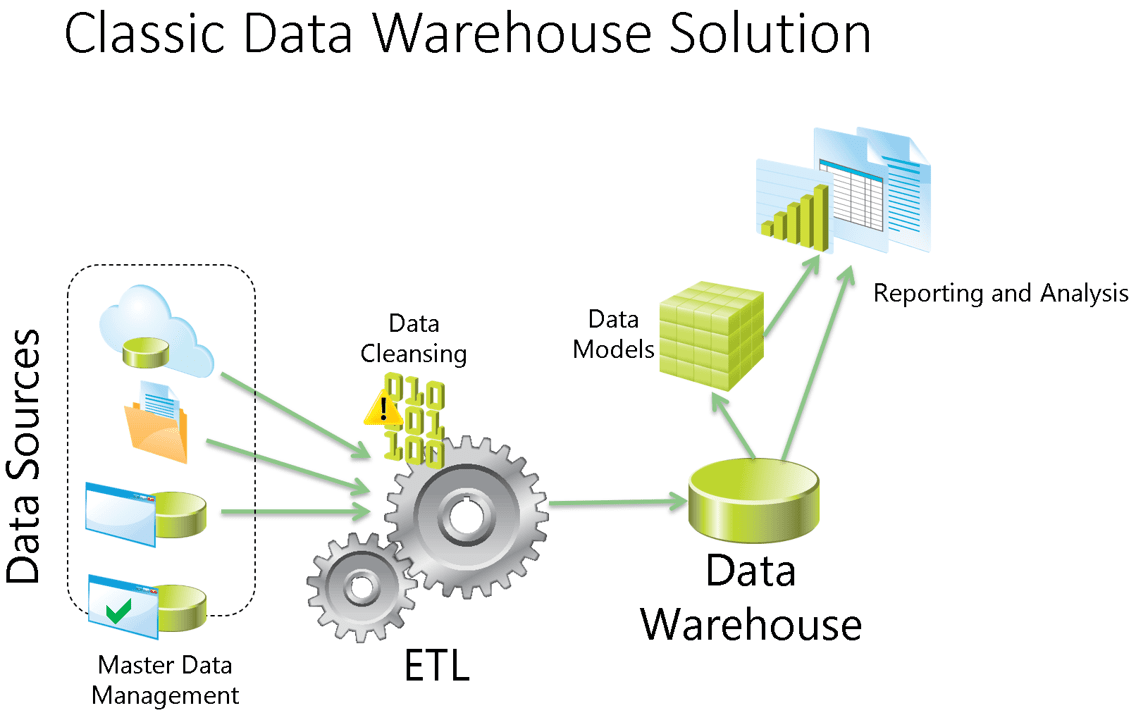
The image below shows the classic data platform model including the semantic model usually built by SSAS.
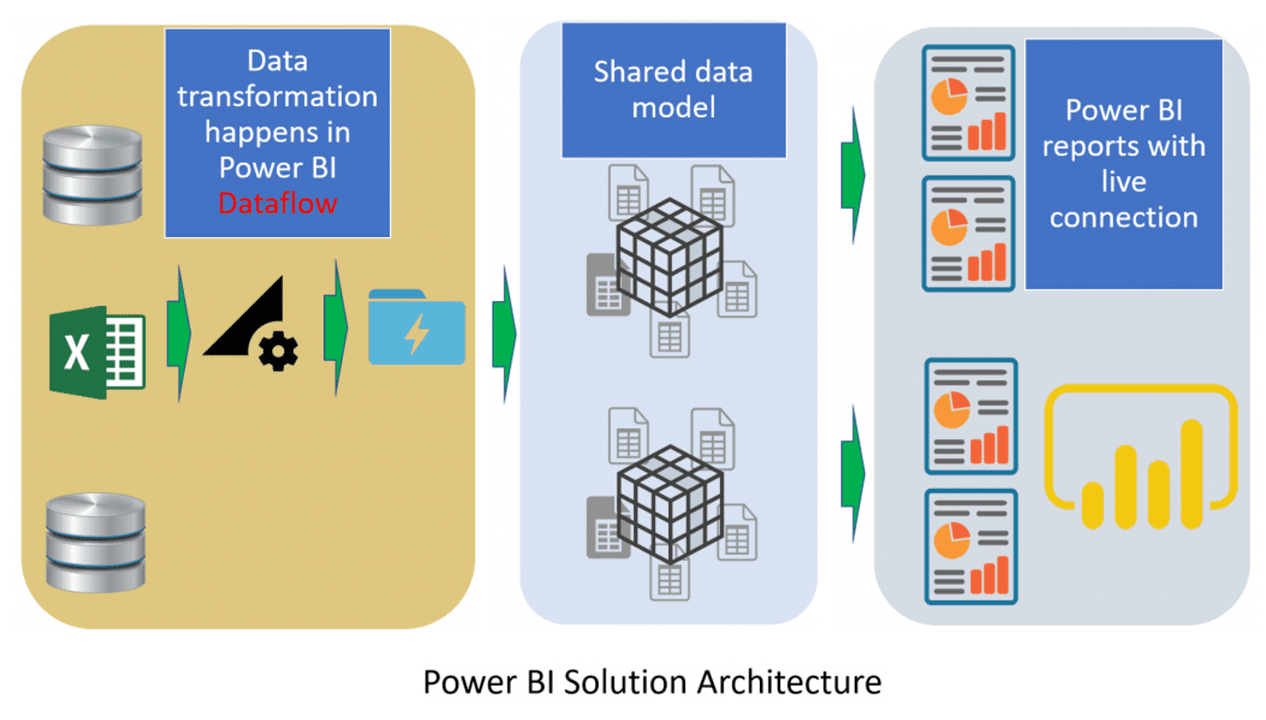
I understand how this is confusing. The dataflows and M language in Power Query are way more powerful than the import features in Analysis Services, but this has a reason. It also doesn’t change the fact the only destination of the data is Power BI Tabular Model. The image below illustrates this Power BI architecture.
The past ETL problem and the Created Solution
In the past, when building a Data Platform solution, even with a very good solution we always end up with one problem. The end users always required more data, different data than what they receive and different transformations on the data.
These requirements kept IT personnel overwhelmed by requests on never-ending projects. The solution for this problem was to put more power on the hand of the users, allowing the users to play with the data and even add more data to the solution. We call these features Self-Service ETL. I hear this name since Power Query was first created as an excel add-in, before Power BI existed.
I realize now the name Self-Service ETL is not so good, because it’s not ETL in the first place. That’s why self-service ETL has a very different definition than ETL. While Power BI doesn’t fit the definition of ETL, it’s a self-service ETL, no doubt about that.
I doubt there is any consensus about the definition of Self-Service ETL. But we know what it’s used for: To relief IT teams by allowing the user to merge his own data with the data coming from the single source of truth built by the company. The user is happy and the company’s IT Team is happy.
Power BI implements self-service ETL tool to make everyone happy. As a consequence, Power BI is not the single source of truth of the company. It’s built to get data from the single source of truth, merge with additional data and build a semantic model. The image below shows how it fits on the classic Data Warehouse model
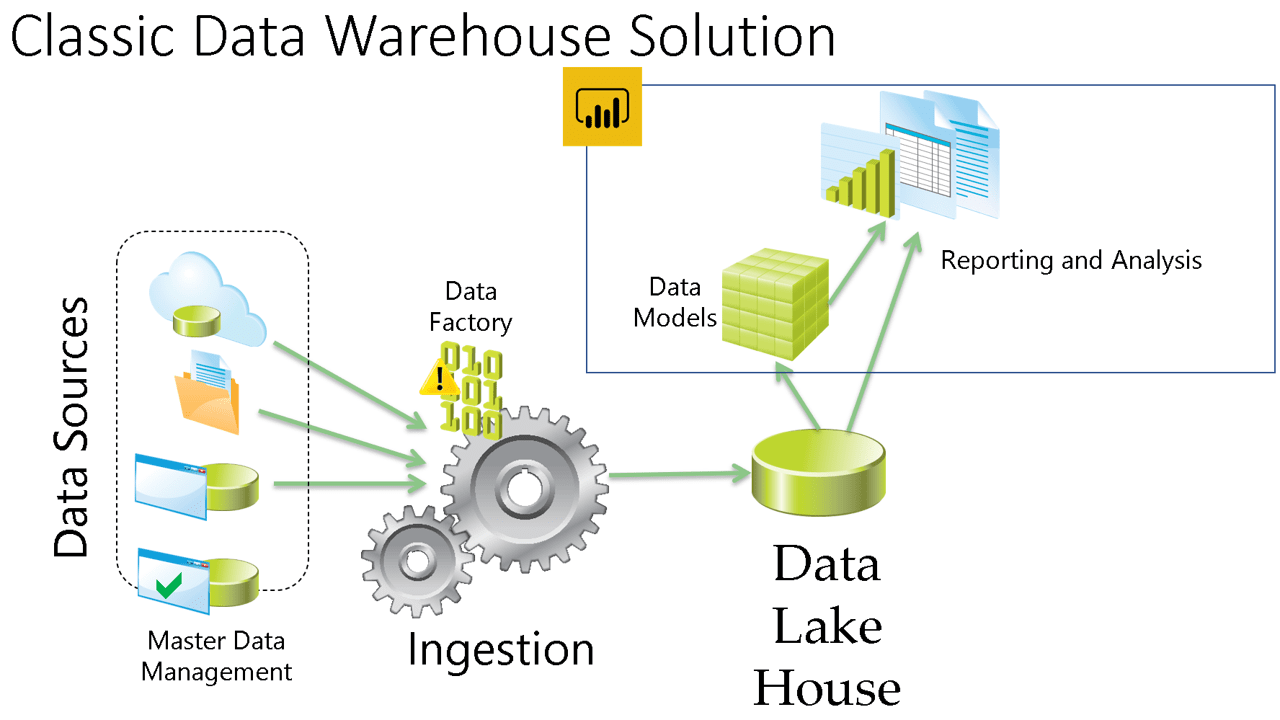
Semantic Model versus Data Warehouse
You are not sure about this yet? The semantic model built by Power BI is a Tabular Model containing cubes. This is the same introduced in SQL Server Analysis Services in 2012. It was never intended to be the single source of truth of the company.
The purpose of a semantic model is to organize the data in such a way the user can understand. For example, how could the user understand and analyse data from a data warehouse full of dimensions type 2 or even type 3 ? A semantic model can get the data and put in a way the user will understand and analyse. Meanwhile, the complete history information will still be kept safe in the data warehouse, the single source of truth of the company.
Summary
Misconceptions about how to build a data platform can easily lead to a huge amount of unreliable data extracted from production without any commitment with the truth of the company data history.
The lines between different technologies will be blurred even more by Microsoft, they always are. It’s responsibility of every Data Platform specialist to be aware of the concepts and don’t get tricked by new features that may come.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments