
Download the notebook used on this blog
I explained in a previous article how the Tables in a lakehouse are V-Order optimized. We noticed this configuration depends on our settings, which can be enabled or not.
One question remains: How could we check if the tables are V-Order optimized or not?
The tables we will use in this example are the same provided by Microsoft as a sample and we described in details how to load them in our article about lakehouse.
You can check more details about V-ORDER Optimization on this link
Checking tables configuration
We can use the following PySpark script to check the configuration of the tables in our lakehouse:
import pyarrow.dataset as pq import os def show_metadata(delta_file_path,tablename): # Print schema metadata print(f"\nSchema Properties for : {tablename}") print("--------------------") schema_properties = pq.dataset(delta_file_path).schema.metadata if schema_properties: for key, value in schema_properties.items(): print(f"{key.decode('utf-8')}: {value.decode('utf-8')}") else: print("No schema properties found.") # Test the function with a path to your delta file# full_tables = os.listdir('/lakehouse/default/Tables') for table in full_tables: show_metadata('//lakehouse/default/Tables/' + table,table)

This script is inspired on a script provided by a user in the Fabric Community forums.
What we should notice about how this code works:
- We have a procedure defined, called show_metadata.
- The procedure receives an array of table names as a parameter.
- In order to generate the array dynamically, we use os.listdir. In this way, the script works for all tables in the lakehouse.
- The show_metadata procedure is called in a loop for each one of the tables. Mind the standard path for the tables in the lakehouse.
- Inside the procedure, we generate a dataset and use the properties .schema.metadata to read the properties of the table.
- We make a loop on the table properties to show each one.
- The table properties need to be decoded from UTF-8
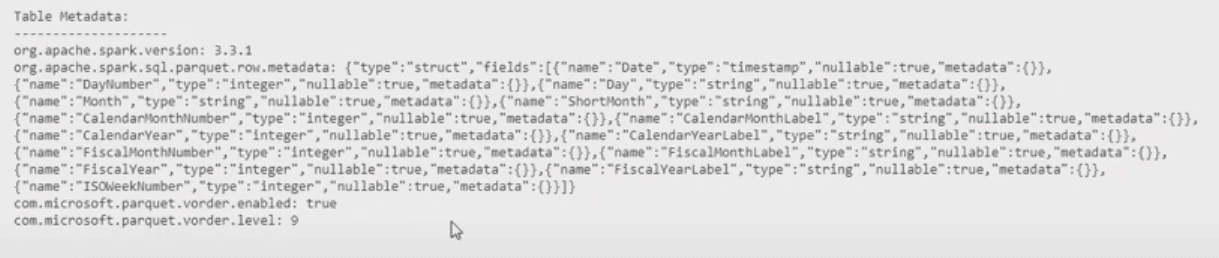
The image below shows a piece of the result after executing this script, highlighting the V-ORDER property on the tables:

Using the script to test the configurations
Using this script, we can test the default configuration in different situation, and we will discover the following:
- The default configuration for spark sessions is to use V-ORDER when writing tables unless we explicitly disable it.
- This makes the V-ORDER also default when using the Convert-To-Table UI, unless we disable it on workspace levell (Why would we do such thing?)
Fixing a table without V-ORDER
Considering V-ORDER is default on spark sessions in Fabric, it will not be common to have tables not using V-ORDER.
But let’s create one in this situation and discover how to fix it when needed.
If the table dimension_stock_item already exists in your demo environment, you will need to drop it before running this script.
A simple spark SQL statement solves it:
%%sql
drop table dimension_stock_item

We can use the following pyspark code to create a table without the v-order optimization:
from pyspark.sql.types import * spark.conf.set("spark.sql.parquet.vorder.enabled", "false") def loadFullDataFromSource(table_name): df = spark.read.format("parquet").load('Files/' + table_name) df.write.mode("overwrite").format("delta").save("Tables/" + table_name) full_tables = [ 'dimension_stock_item' ] for table in full_tables: loadFullDataFromSource(table)

We should mind the following about this pyspark script:
- We have a loadFullDataFromSource procedure to make the load in a default way. It works unless the table has some specific partitioning.
- We disable the v-order configuration for the session on the start of the script.
- We create an array of the tables, but it has only one table. It’s only a standard way to build it.
- We make a for loop on the array, calling the loadFullDataFromSource procedure. Once again, it’s only a standard way to build it, since in our example it’s only for one table.
Once the import is executed with the V-ORDER disabled, we can execute again the script to check the Tables metadata and we may notice the lack of V-Order property on this table. The image below illustrates this:

Fixing the lack of V-ORDER
We need to fix this problem without loading the entire table again. In order to do so, we can use the OPTMIZE statement. This statement can reorganize the PARQUET files to avoid the small file size problem and apply the V-ORDER when this one is missing.
It’s very simple:
%%sql
OPTIMIZE dimension_stock_item VORDER;

We can execute the script to check the table’s metadata again and there it is: The table will have the V-ORDER enabled.
Disclaimer
On the documentation, the OPTIMIZE is used to reorganize the files and apply the V-ORDER. The ALTER TABLE, also present on the documentation, is used to set a TBLPROPERTY which should ensure future writes in the table use V-ORDER.
TBLPROPERTY seems to have no relation with the metadata extracted by the script illustrated here. The TBLPROPERTY could be set and the metadata not, and the opposite.
Microsoft Fabric is still in preview, many of these details are still going to change and the documentation may not be precise.
Conclusion
All the defaults lead to the V-ORDER always being enabled in lakehouse (data warehouses are a completely different story). But it’s important to be able to check it every time a different scenario appears.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments