
I have been working as a no-code data engineer: Focused on Data Factory ETL and visual tools. In fact, I prefer to use visual resources when possible.
On my first contact with Fabric Lakehouse I discovered to convert Files into Tables I need to use a notebook. I was waiting a lot of time for a UI feature to achieve the same, considering this is a very simple task.
Convert to Table feature is Available in Lakehouses
This feature is finally available in the lakehouse: You can right-click a folder and choose the option “Convert to Table”.
When converting, you can create a new table or add the information to an existing table. This allows you to make an incremental load manually, if needed.
It’s simple as a right-click over the folder and asking for the conversion.
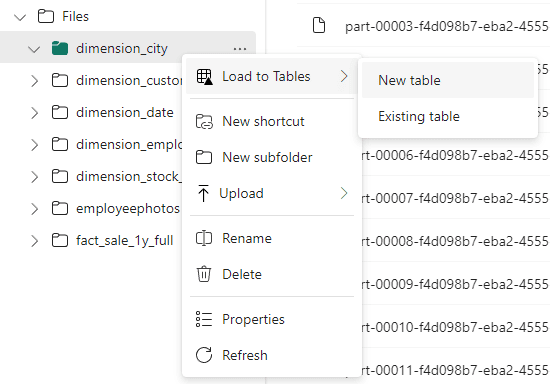
Table Optimizations in Lakehouses
There are optimizations we should do when writing delta tables. We usually do these optimizations on the spark notebooks we create.
For example:
- spark.sql.parquet.vorder.enabled
- spark.microsoft.delta.optimizeWrite.enabled
- spark.microsoft.delta.optimizeWrite.binSize

You can discover more about these optimizations on this article from Microsoft
How would we make these configurations if we use the UI feature?
Workspace Level Spark Configuration
We can make these configurations on workspace level. In this way, these configurations will become default and be applied to every write operation.
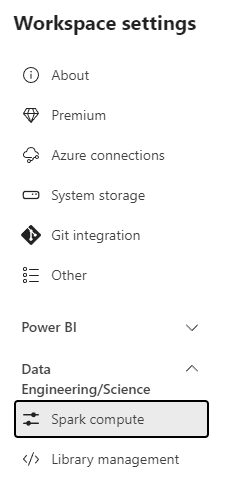
- On the workspace, click the button Workspace Settings

- On the Workspace settings window, click Data Engineering/Science on the left side.
- Click Spark compute option.
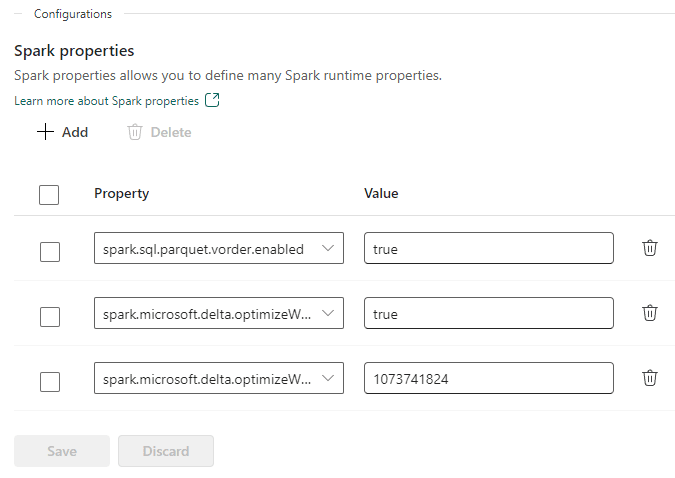
- Under Configurations area, add the 3 properties we need for optimization.
Differences between converting using UI or Notebooks
Let’s analyze some differences in relation to the usage of the UI and the usage of a spark notebook:
|
UI Conversion |
Spark Notebook |
|
No writing options configuration, it depends on workspace level configuration |
Custom writing options configuration |
|
No partitioning configuration. The table can’t be partitioned |
Custom partitioning is possible for the tables. |
|
Manual Process, no scheduling possible |
Schedulable process |
Summary
This is an interesting new interactive feature for lakehouse in Fabric, but when we need to build a pipeline to be scheduled, we still need to use notebooks or data factory.
The workspace level configuration for spark settings is also very interesting.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments