
SQL Source Control plugs into SSMS and connects your databases to your version control system, allowing you to version control your database schemas, and then deploy them using Redgate’s trusted comparison engine SQL Compare.
The latest release (shipped this week!) features an improved version of migration scripts, which allow you to write your own SQL to override the deployment script generated by SQL Compare, making it possible for your teammates to get the latest changes from source control without the risk of losing data. You can learn more about what we’ve done, and why, in another recent blogpost of mine.
But here, I wanted to talk you through how it works using a common scenario.
How to avoid data loss when renaming a table
Common tasks which might be affected include splitting or merging columns and tables, adding a NOT NULL constraint to a column, changing the data type or size of a column, and renaming a table.
In the instance of renaming a table on your development database, SQL Source Control would interpret this change as a DROP and CREATE. If another member of your team uses the Get latest tab to get these changes, data in the target table is lost.
To avoid this data loss, you can write a migration script to rename the table using the sp_rename stored procedure. This script replaces the DROP and CREATE statements the SQL Compare engine would otherwise generate for this change.
Once you’ve renamed your table (in this instance from users to customers) the next step would be to commit the changes to your source control system using the Commit changes tab in SQL Source Control. SQL Source Control will warn you that data loss may occur by committing the change and suggest you write a migration script.

On the Migrations tab and under Replace uncommitted schema changes, you’d then use the checkboxes to select the relevant schema changes.
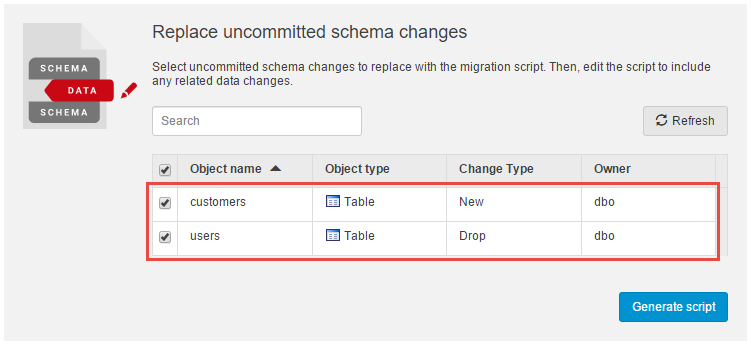
In this example you’re replacing uncommitted schema changes because you’ve already renamed the table, but haven’t yet committed it. The rename is actually interpreted by SQL Compare as a DROP and CREATE and the migration script will replace those changes in the deployment script (the other option would be to start with a blank script, which you’d do if you’d already prepared your schema for the migration and committed those changes).
By clicking Generate script SQL Source Control generates a migration script based on the uncommitted changes and you can then replace the automatically generated DROP and CREATE statements.
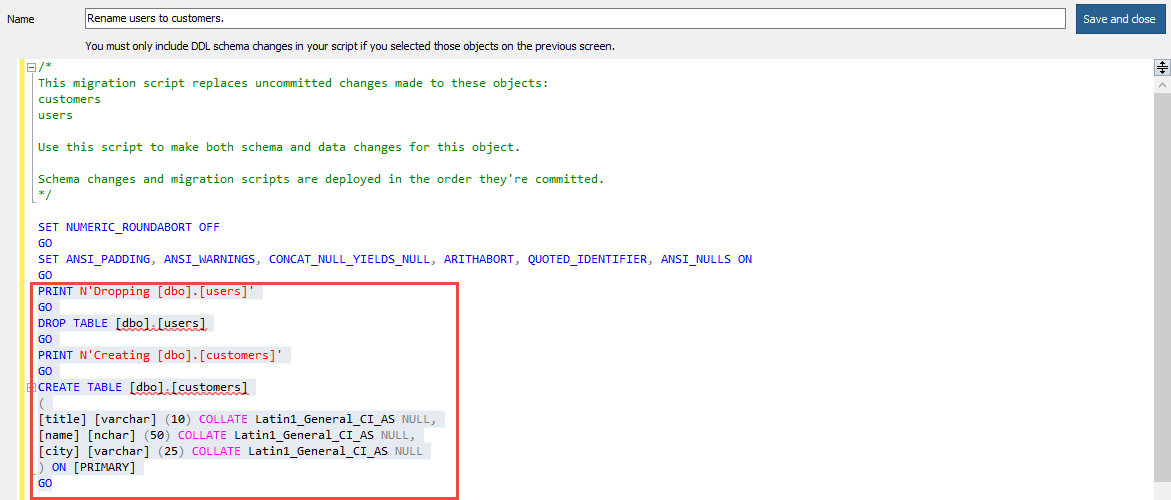
this case we’d use the following SQL:
|
1 2 3 4 |
EXEC sp_rename 'dbo.users', 'customers' GO CREATE SYNONYM dbo.users FOR customers GO |
The synonym for the customers table here will avoid issues where the table is referenced using the old name.
Then you can Save and close and this migration script now replaces the changes made.
Back in the Commit tab you’ll see the migration script with the associated schema changes nestled underneath. Then all you need do is select the new migration script, enter a comment and commit the changes.
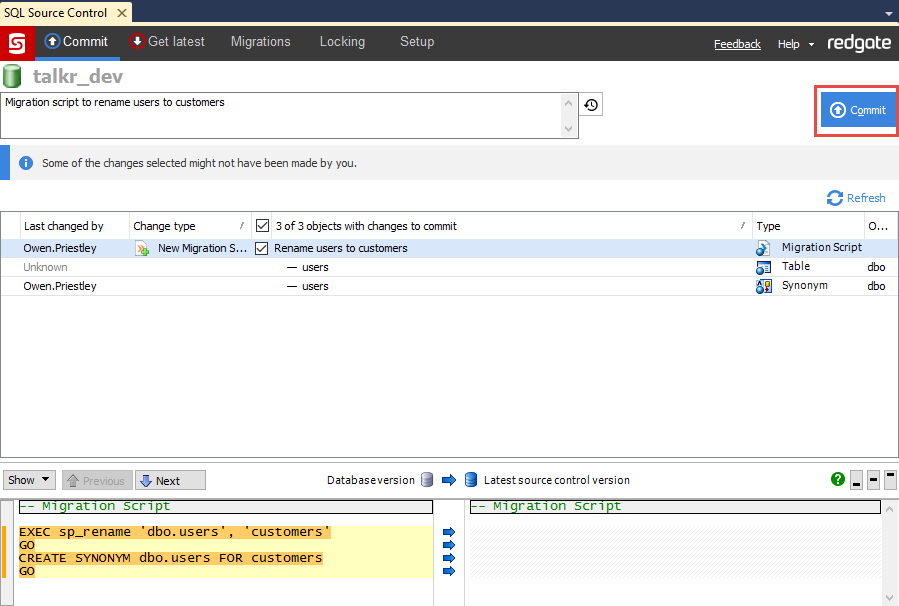
You’re now ready to deploy the changes. If you’re using SQL Compare then the migration script is automatically executed during the deployment, using the sp_rename stored procedure in place of the DROP and CREATE statements originally generated by the SQL Compare engine.
How can I use migration scripts in SQL Source Control?
If you’re new to SQL Source Control you can try it out free by downloading it here.
If you’re already using SQL Source Control you can get the new version via Check for updates in the Help menu of SQL Source Control, inside SSMS.
And you can learn more about migration scripts in SQL Source Control and see more example of where to use them here.
Load comments