
A few weeks ago, a coworker had a scenario where he was trying to import a large amount of data into some format (I think it was JSON, but I think it was a special limitation… that isn’t really important to the solution), and it didn’t allow certain characters. Narrowing down what the bad character was, was proving to be a hassle.
This reminded me of a solution that I had used back when I first had gotten into the whole numbers table thing. Using a number’s table, you can break down every value in a column into one character per row, and then do some analysis. In our case, I want to find a bad character, by eliminating known acceptable characters.
For an example, I am going to take a fresh version of the WideWorldImporters database, and look at their Application.People table. The Fullname column contains characters that are not in the US centric characters, and can cause some, poorly written, pieces of software to fail.
To start with, we will create a number table, with basically contains 1 row for every number from 0 up. We will load it up to 999999, not that our strings will be that long, but this is a typical good size for most uses of a number table, and you can increase that pretty simply by adjusting the query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
USE WideWorldImporters; GO CREATE SCHEMA Tools; GO CREATE TABLE Tools.Number ( I int CONSTRAINT PKTools_Number PRIMARY KEY ); GO ;WITH digits (I) AS (--set up a set of numbers from 0-9 SELECT I FROM (VALUES (0),(1),(2),(3),(4),(5), (6),(7),(8),(9)) AS digits (I)) --builds a set of data from from 0 to 999999 ,Integers (I) AS ( SELECT D1.I + (10*D2.I) + (100*D3.I) + (1000*D4.I) + (10000*D5.I) + (100000*D6.I) FROM digits AS D1 CROSS JOIN digits AS D2 CROSS JOIN digits AS D3 CROSS JOIN digits AS D4 CROSS JOIN digits AS D5 CROSS JOIN digits AS D6 ) --insert into table INSERT INTO Tools.Number(I) SELECT I FROM Integers; |
Check out the data exists:
|
1 2 3 |
SELECT * FROM Tools.Number ORDER BY I; |
If the output isn’t 1000000 rows, starting at 0 and ending at 999999, then something is incorrect in your configuration. Otherwise, let’s move on to the using this data.
Now, the idea is that we will join the Application.People table to the Numbers table for a number of rows. We will do this for all of the numbers that are from 1 to the length of the name. Then use that value to get the substring of the value for that 1 character. I also include the Unicode value in the output to allow for some case sensitive operations, since UNICODE(‘a’) <> UNICODE(‘A’).
|
1 2 3 4 5 6 7 8 9 10 |
SELECT People.FullName, Number.I AS position, SUBSTRING(People.FullName,Number.I,1) AS [char], UNICODE(SUBSTRING(People.FullName, Number.I,1)) AS [Unicode], CASE WHEN i = LEN(People.FullName) THEN 1 ELSE 0 END AS last_character_flag FROM Application.People AS People JOIN Tools.Number ON Number.I BETWEEN 1 AND LEN(People.FullName) ORDER BY FullName; |
The output will have the full name repeated in the first column, then have the character position in the second, along with the character and Unicode output of the value (and an indicator if it is the last character of the string.) Now we can simply use a NOT LIKE expression against our single character, eliminating from contention the numbers (0-9) and letters (a-z), space, -, and a single quote (my database is case sensitive, adjust if you are dealing with case sensitive character sets):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT People.FullName, Number.I AS position, SUBSTRING(People.FullName,Number.I,1) AS [char], UNICODE(SUBSTRING(People.FullName, Number.I,1)) AS [Unicode], CASE WHEN i = LEN(People.FullName) THEN 1 ELSE 0 END AS last_character_flag FROM Application.People AS People JOIN Tools.Number ON Number.I BETWEEN 1 AND LEN(People.FullName) WHERE SUBSTRING(People.FullName,Number.I,1) NOT LIKE '[- a-z0-9'']' --LIKE expr on the single char ORDER BY FullName; |
What you will see is a set of data that has the characters that are not our like (which may actully mean the fullname value is duplicated) This may look like the following (This being output from Azure Data Studio), depending of course on your client, and if this looks ok in your regional dialect, but unicode 129 appears to be a control character: https://www.compart.com/en/unicode/U+0081):
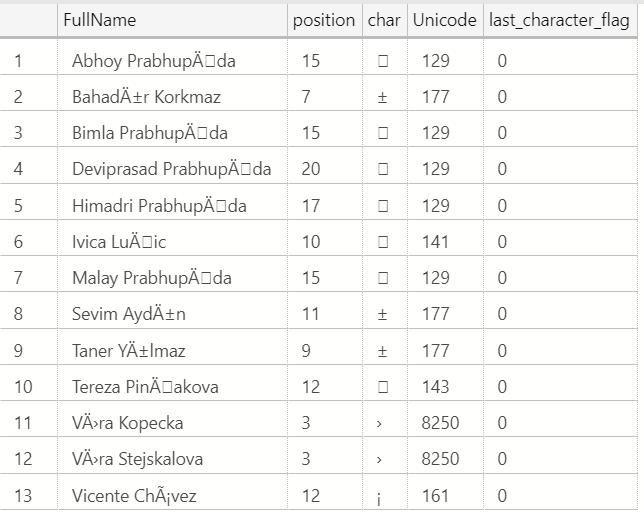
I believe these characters are there just to make it fun to use the WideWorldImporters database, but of course, this is a good thing when you are testing/demonstrating software.
Now, once you have this base set of data, with the characters now each on their own row to work with, you can use this query in a CTE and look at some “interesting” details about the characters in a set.
For example, if you want to know which characters (ignoring case, in a case sensitive db) are used the most (and least) in a column (for some reason):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
WITH CharacterRows AS ( SELECT People.FullName, Number.I AS position, SUBSTRING(People.FullName,Number.I,1) AS [char], UNICODE(SUBSTRING(People.FullName, Number.I,1)) AS [Unicode], CASE WHEN i = LEN(People.FullName) THEN 1 ELSE 0 END AS last_character_flag FROM Application.People AS People JOIN Tools.Number ON Number.I BETWEEN 1 AND LEN(People.FullName) ) SELECT char, COUNT(*) FROM CharacterRows GROUP BY char ORDER BY COUNT(*) DESC; |
Or, if you want to see it case sensitive, you can use the Unicode value of the character:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
WITH CharacterRows AS ( SELECT People.FullName, Number.I AS position, SUBSTRING(People.FullName,Number.I,1) AS [char], UNICODE(SUBSTRING(People.FullName, Number.I,1)) AS [Unicode], CASE WHEN i = LEN(People.FullName) THEN 1 ELSE 0 END AS last_character_flag FROM Application.People AS People JOIN Tools.Number ON Number.I BETWEEN 1 AND LEN(People.FullName) ) SELECT Unicode, MAX(char), COUNT(*) FROM CharacterRows GROUP BY Unicode ORDER BY COUNT(*) DESC; |
What is the most used character in the English language? The Internet tells me that it is e, but in the People.FullName column, it is the lowercase letter a, by a large margin.
As for performance, I have use the version of this query to search through rows with millions of rows, with an average of 20 or so characters per value with very good performance. Aggregating the number of characters that were used in the strings was, on my Surface 4 laptop, notably laggy, taking around 10 seconds as opposed to sub second response to return the 13 rows using the characters that were not in the typical set of 26 letters, 10 numbers, – and space. Your mileage certainly may vary, so test, test, test.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments