
MongoDB has a prodigious appetite for unstructured data and has its place in a Database Developer’s toolkit. Even with indexes in place, some operations that involve aggregation are a lot slower than they are with relational databases: So it is when using ‘joins’ between collections. Lookup, the MongoDB equivalent to Joins, cannot yet do Merge joins or hash joins, so is never going to be fast in the current form. It is far more suitable for enumerations where there is a limited range of alternatives. We can help Lookup along by providing an index that allows it to do an index nested loops join, but beyond that we have difficulties in getting dramatic improvements in the performance of any ‘JOIN’.
We can, of course, argue that collections of documents render joins unnecessary, but this is only true of relatively static, unchanging information. Data that is liable to change is always best stored in one place only.
This article explains how to make such a MongoDB database perform reasonably when reporting historic and slowly-changing information.
Joins in MongoDB
Why bother with joins in a document database? As well as creating entirely new databases in MongoDB, we are beginning to see a lot more databases ported to MongoDB from the relational. These require a lot of lookups, especially for reporting. Some people argue that document databases should de-normalise the data to get rid of the requirement for lookups. I’m going to argue that, if you provide and maintain summary collections, known as aggregates or pre-aggregates, and you use a thread that is separate from the application in order to maintain them when the data in the tables change, then it doesn’t matter so much. It is the database equivalent to cooking the meal beforehand in the kitchen rather than requiring each guest to cook their own meal at the table.
Just as a test-bed, we’ll use a conversion to MongoDB of SQL Server’s classic practice database, AdventureWorks. I chose this because you need to do several lookups to get reports from it, and it can come up with some awkward migration problems that are useful for our purposes. It also allows us to do a direct comparison of the two database systems, though we do this with due warnings that it is like comparing apples and kittens. I include the extended JSON for this database with the article. It takes just a moment to load.
Querying without an index
For our example, we will start without any indexes and then add them later, making sure that they are being used by checking the timings. We will also use the MongoDB profiler to check on the strategy being used.
We execute the following SQL query in MongoDB using Studio 3T, a MongoDB GUI with a handy SQL Query feature:.
|
1 2 3 4 5 6 7 8 9 |
SELECT p.PersonType, Sum(soh.TotalDue), Count(*) FROM "Sales.SalesOrderHeader" soh INNER JOIN "Sales.Customer" c ON soh.CustomerID = c.CustomerID INNER JOIN "Person.Person" p ON c.PersonID = p.BusinessEntityID GROUP BY p.PersonType --Primary type of person: SC = Store Contact, --IN = Individual (retail) customer |
It provides a result that tells us the number of individual customers and store contacts, and the total value of their orders. Our only change from SQL Server is to put string-delimiters around the name of the collection.
It has two joins, implemented by lookups. We bang the button. Five minutes and seventeen seconds later, it finishes. Soon afterwards, a concerned but reproachful person phones from the Society for the Prevention of Cruelty to Databases. She points out that a few indexes would have saved a great deal of anguish. (The cursor method cursor.maxTimeMS() only works with queries)
It is best to look at the auto-generated code at this point.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 |
// Requires official MongoShell 3.6+ use AdventureWorks; db.getCollection("Sales.SalesOrderHeader").aggregate( [ { "$project" : { "_id" : NumberInt(0), "soh" : "$$ROOT" } }, { "$lookup" : { "localField" : "soh.CustomerID", "from" : "Sales.Customer", "foreignField" : "_id", "as" : "c" } }, { "$unwind" : { "path" : "$c", "preserveNullAndEmptyArrays" : false } }, { "$lookup" : { "localField" : "c.PersonID", "from" : "Person.Person", "foreignField" : "BusinessEntityID", "as" : "p" } }, { "$unwind" : { "path" : "$p", "preserveNullAndEmptyArrays" : false } }, { "$group" : { "_id" : { "p᎐PersonType" : "$p.PersonType" }, "SUM(soh᎐TotalDue)" : { "$sum" : "$soh.TotalDue" }, "COUNT(*)" : { "$sum" : NumberInt(1) } } }, { "$project" : { "p.PersonType" : "$_id.p᎐PersonType", "SUM(soh᎐TotalDue)" : "$SUM(soh᎐TotalDue)", "COUNT(*)" : "$COUNT(*)", "_id" : NumberInt(0) } } ], { "allowDiskUse" : true } ); |
When you do a lookup in MongoDB, the key field that you specify in the aggregation stage is the field of the documents in the collection you are looking up. This field defines the documents that you will collect as an array of documents.
The $lookup process matches the foreign field with the local field from the input documents that come down the pipeline.
That key field might not exist in the referenced document, in which case it is assumed to be null. If you don’t have an index on the foreign field, it will do a full collection scan (COLLSCAN) query for each one of the documents in the pipeline. This gets expensive: we need index hits instead of table scans.
A note on indexes
If you need to fetch just a few fields from a collection, then it is far more efficient to include these fields with the actual query criteria in a ‘covering index’. This allows MongoDB to use the quicker strategy of returning a result from the index directly without having to access the document. It makes sense to do this with any query that is likely to be frequently executed.
Which fields should have an index?
- Any ‘key’ fields that are used in lookups or searches to identify a particular document
- Fields that are used as foreign keys
- Where the key uses several fields, such as a Firstname/Lastname combination, it is best to use a compound index.
- Where one or more fields is used for sorting.
It is a good idea to consider the way you want sorting to be done in reports, because this determines the best order for the fields in the index.
Creating the index
Whenever the relational tables have a single column as the primary keys, we’ve added them as the _id field as part of the import. These special _id fields work very much like clustered indexes. We have to call them _id to get them adopted as clustered indexes. We’ve added the original field under its original name so that queries don’t break. We just need create an index for all the other fields that are used for the lookup; the ‘from’ fields and also those which are referenced by the lookup; the ‘foreignField’. This is equivalent to what is specified in the ON clause of the JOIN. In this case, that means Sales.Customer.PersonID, Person.Person.BusinessEntityID and Sales.SalesOrderHeader.CustomerID. We change the primary key reference to Sales.Customer.CustomerID to use our already-indexed _id, which has the same values as customer_id.
We retest and the response comes down to 6.6 seconds This is better than the 5 minutes, 17 seconds without an index, but is a long way off what the original SQL Server database can do. On the same server as MongoDB, SQL Server manages the same aggregation in 160 ms.
Sadly, the MongoDB profiler cannot tell us much to help, beyond telling us that a COLLSCAN was used. This is unavoidable because, although individual lookups have quietly used an index, an index can’t easily be used as part of an overall aggregation unless it has an initial match stage.
If we change the order of joins in the SQL query in Studio 3T, SQL Server executes exactly the same plan as before, which is to do a hash match inner join on the customer and person tables, using clustered indexes scans on both tables, followed by an inner join of the result with SalesOrderHeader.
Here is the Studio 3T version:
|
1 2 3 4 5 6 7 8 9 |
SELECT p.PersonType, Sum(soh.TotalDue), Count(*) FROM "Sales.Customer" c INNER JOIN "Person.Person" p ON c.PersonID = p.BusinessEntityID INNER JOIN "Sales.SalesOrderHeader" soh ON soh.CustomerID = c.CustomerID GROUP BY p.PersonType --Primary type of person: SC = Store Contact, --IN = Individual (retail) customer |
In Studio 3T, the order of aggregation reflects the order of the joins, so the order of execution is different and better at 4.2 seconds. Optimising the aggregation script in the Aggregation Editor makes little difference to this, taking it down to just over three seconds. Basically, the optimisations consisted merely in reducing the fields being taken through the pipeline to just the essential ones
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
// Requires official MongoShell 3.6+ use AdventureWorks2016; db.getCollection("Sales.Customer").aggregate( [ { "$project" : { "_id" : NumberInt(0), "CustomerID" : 1.0, "PersonID" : 1.0 } }, { "$lookup" : { "localField" : "PersonID", "from" : "Person.Person", "foreignField" : "BusinessEntityID", "as" : "p" } }, { "$unwind" : { "path" : "$p", "preserveNullAndEmptyArrays" : false } }, { "$project" : { "CustomerID" : 1.0, "PersonID" : 1.0, "PersonType" : "$p.PersonType" } }, { "$lookup" : { "localField" : "CustomerID", "from" : "Sales.SalesOrderHeader", "foreignField" : "CustomerID", "as" : "soh" } }, { "$unwind" : { "path" : "$soh", "preserveNullAndEmptyArrays" : false } }, { "$project" : { "CustomerID" : 1.0, "PersonID" : 1.0, "PersonType" : 1.0, "TotalDue" : "$soh.TotalDue" } }, { "$group" : { "_id" : { "PersonType" : "$PersonType" }, "SUM(TotalDue)" : { "$sum" : "$TotalDue" }, "COUNT(*)" : { "$sum" : NumberInt(1) } } }, { "$project" : { "PersonType" : "$_id.PersonType", "Total" : "$SUM(TotalDue)", "Transactions" : "$COUNT(*)", "_id" : NumberInt(0) } } ], { "allowDiskUse" : false } ); |
If we continue to go down this route, it means we spend a lot of time optimising each query. We need to imagine that there are managers badgering us for a whole stack of revenue reports. What should we do instead?
Using pre-aggregation collections to simplify reporting
You are better off creating an aggregation collection that is at the lowest granularity you are likely to report on. This is the equivalent of an OLAP cube. In this case, we are dealing with records of trading taken from the invoices. These don’t change and there are good reasons why they shouldn’t. I’m always surprised to find historical data being fetched and aggregated every time there is a report. It would only make sense if there were time-travellers suddenly refusing to pay for their bicycles retrospectively (in the case of our example, AdventureWorks) or you were reporting on Enron’s data. In MongoDB we simply prepare and maintain our historical data in ‘pre-cooked’ form.
If we pre-aggregate with an intermediate collection such as this…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
// Requires official MongoShell 3.6+ use AdventureWorks2016; db.getCollection("Sales.Customer").aggregate( [ { "$project" : { "_id" : NumberInt(0), "CustomerID" : 1.0, "PersonID" : 1.0 } }, { "$lookup" : { "localField" : "PersonID", "from" : "Person.Person", "foreignField" : "BusinessEntityID", "as" : "p" } }, { "$unwind" : { "path" : "$p", "preserveNullAndEmptyArrays" : false } }, { "$project" : { "CustomerID" : 1.0, "PersonID" : 1.0, "PersonType" : "$p.PersonType" } }, { "$lookup" : { "localField" : "CustomerID", "from" : "Sales.SalesOrderHeader", "foreignField" : "CustomerID", "as" : "soh" } }, { "$unwind" : { "path" : "$soh", "preserveNullAndEmptyArrays" : false } }, { "$project" : { "CustomerID" : 1.0, "PersonID" : 1.0, "PersonType" : 1.0, "TotalDue" : "$soh.TotalDue" } }, { "$group" : { "_id" : { "PersonType" : "$PersonType" }, "SUM(TotalDue)" : { "$sum" : "$TotalDue" }, "COUNT(*)" : { "$sum" : NumberInt(1) } } }, { "$project" : { "PersonType" : "$_id.PersonType", "Total" : "$SUM(TotalDue)", "Transactions" : "$COUNT(*)", "_id" : NumberInt(0) } } ], { "allowDiskUse" : false } ); |
… then our report drops from 4.2 seconds to 25 milliseconds.
In practice, I wouldn’t want to store such a specialised aggregation-collection. I would slice the more general report by a time period such as weeks, months, or years so that you can then plot sales over a time period. I’d also add the sales person’s ID and the ID of the store so that someone gets the credit for the sale.
Even with extra fields and more documents, you are still going to be in the same region of performance in creating the aggregation. If you use this technique, you have to maintain the cubes, or aggregation-collections, in just the same way as an OLAP cube whenever the data changes. This must be done as a scheduled job in background. If, instead, it was done as part of a user session whenever the aggregation was found to be out-of-date, then you could cause congestion, especially if a connection is shared.
Because I tend to think in SQL, I’ll rough out the aggregation I want. As the SQL is necessarily limited in what it can do, I leave out such things as the date calculations and the output stage.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT c.PersonID, p.PersonType, soh.SalesPersonID, psp.Name, psp.CountryRegionCode, Sum(soh.TotalDue), Count(*) --, --Year(soh.OrderDate) AS year, Month(soh.OrderDate) AS month, --DatePart(WEEK, soh.OrderDate) AS week FROM "Sales.SalesOrderHeader" AS soh INNER JOIN "Sales.Customer" AS c ON c.CustomerID = soh.CustomerID INNER JOIN "Person.Person" AS p ON p.BusinessEntityID = c.PersonID INNER JOIN "Person.Address" AS pa ON pa.AddressID = soh.BillToAddressID INNER JOIN "Person.StateProvince" AS psp ON psp.StateProvinceID = pa.StateProvinceID GROUP BY c.PersonID, p.PersonType, soh.SalesPersonID, psp.Name, psp.CountryRegionCode --, Year(soh.OrderDate), Month(soh.OrderDate), --DatePart(WEEK, soh.OrderDate); |
Getting the order right and tying up loose ends
Once this is running, I copy the mongo shell query code and paste it into the Aggregation Editor, Studio 3T’s MongoDB aggregation query builder.
I then fine-tune the aggregation:
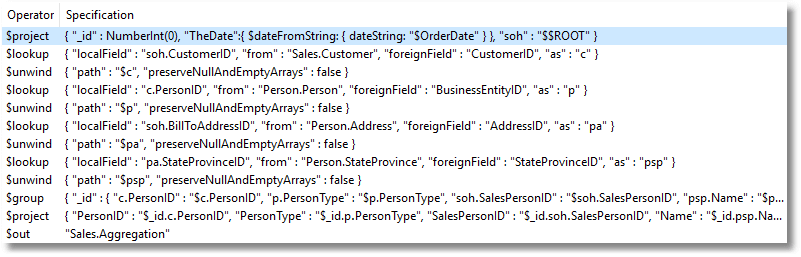
Once this is executed, I can then do reports directly from Studio 3T’s SQL Query tab:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
--total invoice value per year for AdventureWorks Select Year, sum(Total) from "Sales.Aggregation" group by Year order by Year asc --total invoice value per year for each country --for AdventureWorks Select Year, CountryRegionCode, sum(Total) from "Sales.Aggregation" group by Year,CountryRegionCode order by CountryRegionCode --Top twenty locations for buying from adventureworks Select Name,sum(Total),sum(invoices) from "Sales.Aggregation" group by Name order by sum(Total) desc limit 20 --Top twenty Sales people Select pp.FirstName,pp.LastName,sum(sa.Total),sum(sa.invoices) from "Person.Person" pp inner join "Sales.Aggregation" sa on pp.BusinessEntityID=sa.SalesPersonID group by pp.FirstName,pp.LastName,sa.SalesPersonID order by sum(sa.Total) desc limit 20 --Top twenty Customers Select pp.FirstName,pp.LastName,sum(sa.Total),sum(sa.invoices) from "Person.Person" pp inner join "Sales.Aggregation" sa on pp.BusinessEntityID=sa.PersonID group by pp.FirstName,pp.LastName,sa.PersonID order by sum(sa.Total) desc limit 20 |
… and so on and on.
That last one is an example where it pays to redo the code as a MongoDB aggregation pipeline.

The full aggregation, which you can view in the mongo shell language through Query Code, is as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
use AdventureWorks2016; db.getCollection("Sales.Aggregation").aggregate( [ { "$group" : { "_id" : { "PersonID" : "$PersonID" }, "Total" : { "$sum" : "$Total" }, "Invoices" : { "$sum" : "$Invoices" } } }, { "$project" : { "Total" : 1.0, "Invoices" : 1.0, "PersonID" : "$_id.PersonID", "_id" : NumberInt(0) } }, { "$sort" : { "Total" : NumberInt(-1) } }, { "$limit" : NumberInt(20) }, { "$lookup" : { "localField" : "PersonID", "from" : "Person.Person", "foreignField" : "BusinessEntityID", "as" : "p" } }, { "$unwind" : { "path" : "$p", "preserveNullAndEmptyArrays" : false } }, { "$project" : { "Customer" : { "$concat" : [ "$p.Title", " ", "$p.FirstName", { "$ifNull" : [ { "$concat" : [ " ", "$p.MiddleName" ] }, "" ] }, " ", "$p.LastName" ] }, "Total" : 1.0, "Invoices" : 1.0 } } ], { "allowDiskUse" : false } ); |
This does the aggregation in 120ms on my machine which, when you consider the steps involved, is pretty good. It is down from 4 seconds in the version generated from that SQL code.
The same applies to the salesperson report. We create this very quickly by adding the word ‘sales’ to the initial grouping.
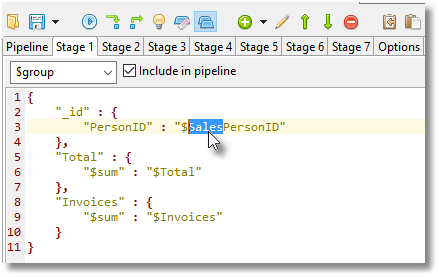
This is even quicker (48 ms) because we can first eliminate all records with $null salespeople (mail-order customers).
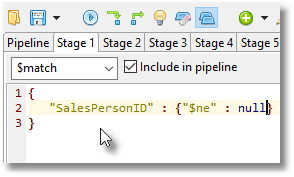
The trick here is to do the expensive lookup operation on as few documents as possible.
What we do is:
- Eliminate all nulls (in the case of the salespeople)
- Perform the grouping on the person_ID first, then
- Sort out just the top twenty customers
Only when the output is reduced to as few documents as possible do we perform the lookup. Because the operation is done only a few times, we can afford to be lavish and generate the customers names properly!
Conclusions
By dint of craft, guile and ingenuity, we can reduce a query from over five minutes to around 100 milliseconds. To get past the initial despair of waiting minutes, we just add the common sense indexes on foreign key references and keys, and try out covering and intersecting indexes.
Having got the obvious out of the way, it pays to check whether you are repeatedly scanning historic or unchanging data unnecessarily. This is such a common mistake that it is almost endemic.
In this article, I’ve illustrated how a ‘cube’ can speed up the creation and production of a whole lot of reports that take their information from the same basic data.
Finally, it is important to get the order of the stages in an aggregation pipeline in the right order. Lookups, like sorting, should be postponed until you have only the documents you need for the final report. Matching and projecting should be done early on. The point where you do grouping is a more tactical decision, but it isn’t a particularly slow operation in MongoDB. It makes sense to keep the pipeline lean, pushing just the data you need within each document as it goes through the pipeline, but this is best seen as part of the final tidy-up, and though it will speed things up, it doesn’t provide huge gains.
Current transactional information can never be dealt with in this way, of course: you would never want out-of-date information about current trading, for example. However this is of relatively small volume and is much less likely to show up as a problem with lookups.
The Extended JSON files for the MongoDB version of AdventureWorks is here
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments