

No matter the ETL tool used, there are some basic patterns to follow when transferring data between systems. There are many data tools and platforms, but the basic patterns remain the same. This focuses on SQL Server, but most of these methods work in any data platform. Even if you are using a virtualization layer, you likely need to prepare the data before exposing it to that engine, which means ETL and data transfers.
Warehouse is very loosely a data warehouse, but the same process applies to other systems. This includes virtualization layers, and to a smaller degree, bulk transfers between transactional systems.
The concept is simple. You want to move data from here to there with the best performance possible, in the least amount of time, with the smallest impact to all systems involved. Consistency and careful planning are required to ensure the process works smoothly. Systems and data are unpredictable. Planning and working closely with the business help make the process more predictable and consequently more reliable.
This also assumes that basic diligence has been performed and other methods aren’t used in the enterprise to access data. Those methods might be a read-only replica, a virtualization layer such as PolyBase, or a vendor specific method. Moving data incurs a cost, even with a seasoned data team and excellent methodology and standards. Spending the time at the beginning of the process is worth the effort, even if you think you understand all aspects involved with the current data story.
This article covers requirements for starting a data story. You won’t need to cover all of these items for each data story when the same systems are involved, but you will need to be sure you understand these requirements. General patterns that can apply to all ETL are covered at the end of this section. The next article covers ETL patterns, use cases for each, and potential gaps.
Requirements / prerequisites
Before a decision can be made for the warehouse load pattern, you must understand the systems involved. It is not possible to make a good decision without understanding the source system, security, business or vendor limitations, and the destination system. Enterprise systems generally involve more than one source, but they must each be considered and analyzed individually.
Much of this falls into the category of basic data project planning. There are some unique considerations for determining the correct load patterns you will use compared to your project planning. This is the detailed section of your project plan. As you go through this the first few times, patterns should emerge. It is extremely helpful to create a template to capture requirements. Even if you don’t need all sections for the current data story or project, confirming these items is crucial. You don’t want to be surprised by a new requirement during user acceptance testing (UAT).
Use cases
The business reason / use cases must be defined, even for simple data stories. This may seem like an unimportant detail for a purely technical implementation, but it is critical to understanding how data loads can work. Defining the use cases will drive out high-level, but crucial, aspects of your process. Things like performance expectations, data latency, service level agreement (SLA), disaster recovery requirements, and security will all rely heavily on the business analysis.
Having the use case also helps you evaluate if the data really should be transferred between systems. If the users want a live view of the data, they may just need a new screen in a transactional system. You won’t be able to make that evaluation without the use cases.
Enterprise standards
The impact of enterprise standards on your ETL strategy is direct. Existing standards will generally limit your options more than anything else. But standards are also an opportunity to build on existing patterns and start your project quickly and efficiently.
Naming standards, coding standards, design patterns, acceptable tools, and deployment methodology all fall under enterprise standards. If your organization is small or doesn’t have standards for any of the above, this is another opportunity to create and set the standards. The goal for a project should be that the code and objects all look like they were created by a single developer. This is a virtually impossible standard in large projects, but it’s a good objective.
The actual naming standards aren’t as important as having a set of standards and sticking to them as much as possible. I have very strong opinions about how objects should be named but the best standards are the ones that are followed by the team. If the enterprise or project naming standards are already set, it’s better to be consistent. Team members will be added and removed from teams. Following standards, even if you think they are suboptimal, makes the process easier.
Coding standards are different from naming standards because some coding methods are better than others. This is more difficult to document but there are many good guides available. There are patterns that should be followed for SQL Server that will optimize the tables and system for transactional operations, patterns for warehouse operations, indexing patterns and patterns for almost all aspects of database development. Code reviews help. Experienced team members also help, but diligence by the team is the only way to have quality code on a consistent basis.
Data governance
Data governance can vary considerably between organizations, but primary goals include ensuring data is consistent, documented, and correct. Aligning with the data governance team and the standards they set at the beginning of a project greatly reduces potential refactoring later. It also helps users in the enterprise understand and find the data quickly. It can also reduce redundancy. If there is a central team maintaining a list of data available for consumers, this can be checked before a project begins.
Seek guidance from data governance on naming standards, correct formulas and data classifications. I would also expect the data governance team to provide a method to document source and destination data sources, record column definitions, and optimally, provide data lineage. This documentation will also include business units and owners for each data source.
If a data governance team isn’t in place and there are no standards, this is the perfect time to create standards. As discussed above in enterprise standards, everything should be consistent and well documented.
Protect your data. Demonstrate compliance.
Data dictionary / glossary filled
Working with the business is crucial for most successful ETL projects or even just simple stories. Knowing what is getting transferred, the columns involved in transformations, source information, destination information and any other relevant data is critical for maintenance scenarios. It also is critical for day-to-day operations with self-service data.
Ideally, the business will be responsible for the business glossary and define terms, algorithms, and even acceptable values or ranges for particular fields. Having the terms defined helps with consistency. If the business provides the definition, communication is easier since everyone is speaking the same language.
Source information
Server specifics
Source information should be well defined, at an architectural level. Detailed system, database, and table information will also be needed to choose the best pattern.
The data source must be defined to understand the capabilities of the system and the options available. This includes the database engine or system, including the installed version. This is an important detail since functionality can change between versions and even service pack levels. You have to be sure you have drivers installed, and firewall rules / NSGs are in place too. Having detailed server information is crucial for this process.
Table specifics
As with server specific information, table specific information is also required to choose the best pattern. If the table is temporal enabled or has CDC enabled, you may choose to use that in your ETL.
Also as with server specifics, the business users may not be able to give you the kind of detailed information you need. Work with the technical administrators of the source server and tables to get this detailed information. If you are able to run DMVs and query metadata for the database, this information is readily available via those methods and is easier than coordinating with other teams.
Natural key
Knowing the natural key (the columns that make a row unique) is an absolute requirement for this process. If you don’t know the columns that define the natural key, it makes it very difficult to define the load pattern.
An artificial key can be used, but you are then dependent on the source system and won’t be able to match to other systems unless they also use the same artificial key. The usual reason for an artificial key is to improve performance. But it generally should be tied to a natural key so cross-system queries will work correctly.
When a natural key, or an artificial key, are not present, then you will likely need to replace the entire dataset for each load, or compare all columns. This is not an efficient operation and should avoided at all costs.
Columns defined
Columns must be defined before the load pattern can be established. You don’t need to know every column you will transfer, but you do need to understand the essential columns. Not just the unique key, but the date columns or other columns that identify modified records are essential. You will need detailed column information for your table acceptance criteria (AC), so it needs to be defined soon after this part of the process. Detailed column information is also needed to shape the data correctly into facts and dimensions.
Related dimensions
You likely won’t have explicitly defined foreign keys in a warehouse, but there are related tables and dimensions used for lookups. This is especially important when building reports or exporting data from the warehouse. Dimensions and lookups should be defined before work begin. They will be used to filter and limit data. Related data is also used to validate data in columns and find outliers or missing data.
Load schedule and refresh rate
The schedule that the source data is refreshed (refresh rate) will help determine how frequently your ETL runs (the load schedule). The load schedule for your ETL and the refresh rate will determine certain design patterns. Specifically, it can exclude some design patterns.
The expected load schedule is a requirement for defining the ETL pattern used, especially when large datasets are involved. You may need to look at other solutions if you aren’t able to meet the required load schedule. If data is only extracted daily, but the users need live data for a safety related report, a different solution is needed.
Pattern for self-healing
Failures between systems are virtually inevitable. They should be infrequent and related to things such as password changes, network issues, or unexpected data. Some items can be anticipated, but not everything. There is a cost to coding for all potential issues, especially when the source is large and trusted.
When a data load fails, the pattern should support self-healing (fixing the missing / out-of-date data without user intervention). This is where a sliding window or flagging successfully transferred rows comes into play. The next time the ETL runs, it should catch the rows that were missed. The size of the sliding window or the amount of overlap will be determined by the stability and reliability of the systems involved. The maturity and capabilities of the maintaining team also needs to be considered.
The major downsides of a self-healing pattern are the extra overhead in development and processing time for the ETL. Both of these are obvious, but need to be explored. A simple method is a full reload on the weekend. But whatever is chosen it generally should be anti-fragile. It will often include a method for overlapping ETL from the previous pipeline. Finally, all ETL processes should recover gracefully no matter the status of the last run.
Full load / first load capability
When deciding on the overall load pattern for your new ETL process, be sure to consider the first load and the possible need for a full reload. This may be a separate process with different staging tables, or it may be a configuration-based option. A configuration-based option is nice considering that you don’t need to create extra database objects, the load path is clear, and you don’t have the redundancy of maintaining two code bases. The advantage of a separate process is simplicity. You just copy the ETL and change a few items such as source table or file and change the staging table, but as mentioned, this must be maintained and any bugs or logic changes must be updated in both ETL.
Full reloads can also be planned on a regular cadence. I have had to do this with very volatile or untrustworthy sources. This has primarily been with external sources and very dirty data with changing keys. A full reload was the only way to ensure we had the best version of the data available. If you need to do a full reload on a regular basis, consider the Minimal Downtime pattern presented at the end of this. It allows data to be used in the table the entire time new data is loaded. You may not need to copy the existing data, but the table rename and archival process can be useful.
Security items
Data compliance / restricted data
This is another area that may fall into the data governance department, it may fall under the responsibility of the business unit, or it may be controlled solely by the security department and IT. New laws and restrictions are enacted every year and they may impact your security requirements too. It is standard for the data governance team or the business to manage these requirements, but you will need to be sure your solution conforms to the new demands.
The easy answer, from a compliance standpoint, is to make everything as restricted as possible. This could include encryption at the database and column level, restricting connections to the database, row level security, data masking, or using mock data for non-production environments. Any or all of these may be appropriate, but security requires balance. Each piece of added security requires additional maintenance and coordination and can degrade the user experience.
For example, if you need to use mock data, it will impact the testing process, especially with external systems. This needs to be coordinated with the business and testing team. Each added piece of security will have special requirements and administration considerations.
During requirements gathering, determine what is actually required from a security perspective. Consider how these requirements interact with the ETL, final table design, testing, business acceptance, and administration. It is best to do this early in the process to minimize refactoring and also helps to ensure you don’t have security gaps during testing or the initial deployment.
Security defined and special considerations
Security can have a direct impact on your ETL pattern. The source system will dictate some of the design and available options. If security differs by account (e.g., RLS or masking is defined on the source tables), this must be accounted for in the design patterns. It will likely not impact the columns used, but it must be defined an analyzed. It also places additional burdens on the test team.
The same is true for any encryption or even just data masking. If dynamic data masking is used, you will likely need a service account with permission to see the unmasked data, and then be sure masking functionality is in place in the destination system.
There are additional issues that must be taken into consideration when creating ETL solutions in an enterprise, such as firewalls and NSGs in a cloud solution. These items can be bypassed with the appropriate rules, and don’t impact the design of the ETL pattern as strongly. But you must work with the appropriate teams to get rules in place and be sure you have enough lead time for those external teams to do their work.
The type of login must also be defined and created. You should also have a plan for updating the password on a regular cadence if not using a managed identity. Refer to the Microsoft documentation on managed identities and use them if possible as they make this process much easier and nearly transparent.
Table / column provenance / lineage
Table and column lineage (or provenance) isn’t an absolute requirement for defining the ETL pattern, but it will make things much easier as you move toward a data centric business. Lineage is simply documenting the origin, transformations, and destinations for a particular piece of data. This also helps when defining how aggregates are defined. Even for single-source data it is very useful.
Documenting column lineage is easiest to do in an automated fashion. Check if your data governance team has a solution in place. It’s easier to use an existing solution than to build your own. Commercial solutions exist that will scan source systems, traverse ETL, and document destination columns as well as transformations performed. This is much easier than doing it manually. Another benefit of using an automated solution is that scans can be rerun to capture any changes. Doing this on a regular cadence ensures that you are always up-to-date with your documentation.
Transformations defined
Defining all transformations and data manipulations isn’t usually required for defining the general ETL pattern. It is necessary for each ETL story, but usually won’t impact the generic pattern used.
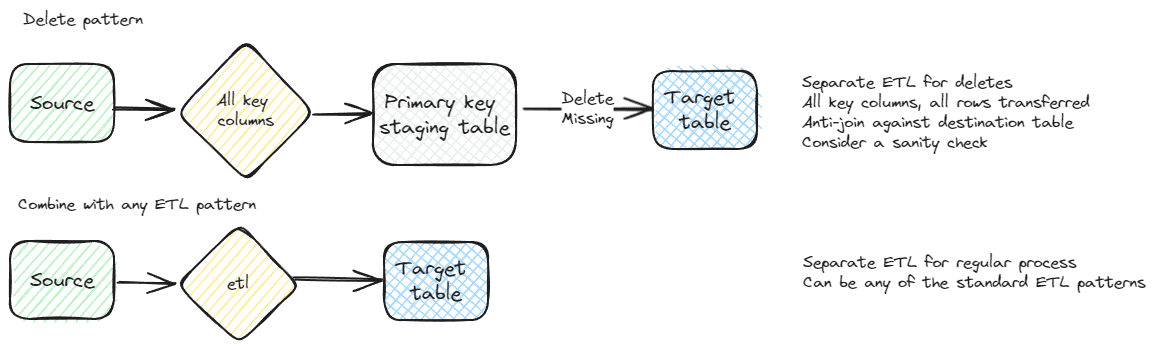
Delete pattern
Another prerequisite is determining if records are deleted and the pattern for deletes. If the entire dataset is loaded each time, this isn’t a concern.
A very handy pattern for datasets with a small set of key columns is managing deletes separately from the new and modified data. All rows are sent, but only the key columns, and put into a separate staging table. This decreases the change of mistakes and missing columns to delete or deleting too many columns. The best case for this pattern is a single integer key column. Refer to the general delete pattern later in this article for a detailed explanation.
Logging
Basic logging should be part of every ETL solution. If the business or enterprise has additional requirements, they should be defined during this phase. This would include successful runs and times, failures, rows transferred, and transfer times.
Logging will also help find issues with ETL packages and quality. It provides a sense of confidence in the data and processes for end users too. Trust is important for any data system. Transparency, even with errors, fosters that trust and helps ensure issues are addressed quickly. In ETL systems, many errors are due to problems in the source system. Logging errors and exposing them enables these external teams to fix errors.
Performance Requirements / NFR
Performance expectations should be gathered during this phase as well. It has a direct impact on the pattern implementation. Most patterns can be made to perform well, but some are faster than others.
The non-functional requirements (NFR) for a project can have an impact on the hardware or performance tier selected, and the ETL pattern selected. Start with a general set of requirements and adjust based on business input and requirements. This is often difficult for the business to define. Giving them a head start with a template can help. It lets the team know what type of items you expect and also acts as guiderails, keeping the NFR reasonable and possible.
Priority
I’m sure this is obvious, but priority of creating the ETL should be determined. Ideally, it will go through a review process with the business before it gets to the technical team, but that isn’t always the case. If everything is top priority, nothing is top priority and the technical team is left to decode the most important projects based on cues that may not be accurate. The loudest and most persistent requests usually get worked on first.
General Patterns
No matter the specific ETL pattern used, there are some general patterns that can enhance the process. This section covers a few of these patterns that I have found useful and can be added to most patterns.
General delete pattern – complete comparison
This is a generic delete pattern for transferring data between systems. It is presented here rather than in the next article covering specific scenarios since it can be used in conjunction with many, if not all, of the patterns.
One of the key work products created during the requirements phase is the key column or set of columns. This is the natural or artificial key used to compare rows in the source system to the destination. This key is also used for deletes. An important part of the design phase of a database project is choosing a good key. This will usually be seen in the physical design of the database as the primary key or a unique index / constraint.
The first step for this pattern is to pull all of the key columns. I generally like to put them into a staging table in the destination system, but that isn’t a requirement. This is one of the reasons why a small key helps with system design. There are additional reasons for having a small key, but it helps with ETL. I want to emphasize that with this pattern, you pull all rows every time you want to run the delete. It can be combined with additional delete strategies, but this is a good cleanup strategy.
The only step left is to delete rows in the destination that aren’t present in the source / ETL dataset. If using a staging table, it’s a simple anti-join.
|
1 2 3 4 5 6 7 |
--Example showing using an anti-join --to perform the delete DELETE dbo.Destination FROM dbo.Destination D LEFT JOIN etl.Source_Staging S ON D.KeyColumn = S.KeyColumn WHERE S.KeyColumn IS NULL |
ETL systems have functionality to perform lookup operations. If you choose to use this for your pattern, you can use the lookup on the key dataset and delete any rows in the destination not present in the lookup. It takes longer but is preferred in some settings.
Be consistent and use the same method for all ETL when you can. I prefer the staging table since it is easier to troubleshoot and it is usually much faster. The delete staging table can be used for other purposes. It is also a method to look for missing rows. In less reliable systems or quickly changing systems, this can be a good verification step. Knowing all of the rows in the source system, even without the detailed data is very useful for troubleshooting. It also is very fast. You can pull millions of rows very quickly, with very little impact to the source system.
The other strength of this pattern is that it can be run at any time. If the natural key list is up-to-date, it is safe to run and doesn’t need any complicated logic.
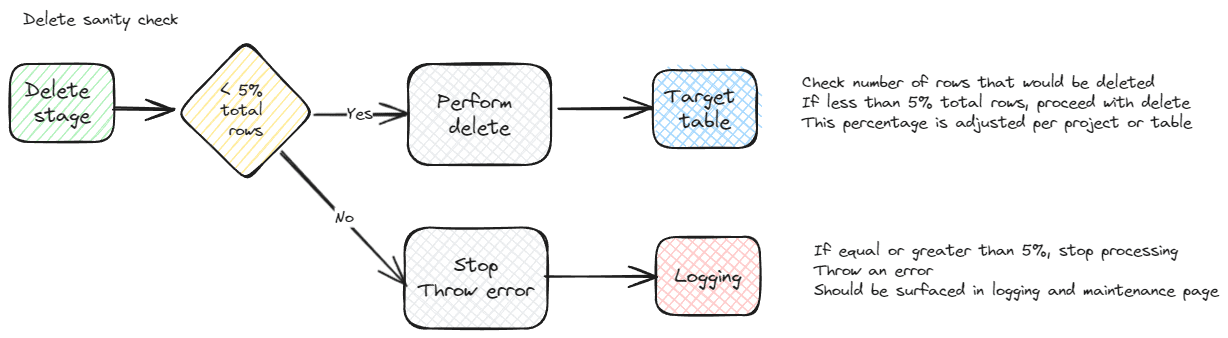
A caveat with using an anti-join for deletes, any deletes and not just this pattern, is that you must be sure the staging table or dataset populated correctly. If the table is empty, all rows in the destination system will be deleted. This can be trivial to fix or a major outage, depending on your system. It is a good idea to put a check into place before you run your delete. A sanity check can be placed on the query that ensures deletes only happen if it will impact less than X percent of rows. The elaborateness of your solution should correspond to the importance and size of the dataset.
General source view pattern
For efficient ETL, it is often best to create a view on the source system that combines tables, limits rows, and may also perform some calculations. Performing calculations at the source, especially if multiple tables and columns are required, can greatly minimize the data transferred and maintained on the destination system.
Even if transformations aren’t needed on the base data, a view layer has additional benefits. I’m a proponent of using schemas for security and organization. Creating a separate schema for each connected system makes it easier to determine the purpose of the view and provides a logical grouping. This makes it easy to see how changes will impact various groups. There can be some redundancy with this. That’s where data governance can help limit the duplication of effort.
Assigning security at a schema level simplifies design and maintenance efforts. This is a good addition to the view layer. No security is assigned directly to the views, only to the schema. Refer to my SQL Server Security Primer post for additional details about using schemas for security.
Using views in the source system also places the maintenance costs on the source system team, so consider if this fits your development pattern. This fits with a data mesh philosophy. It is typical for the developers of the source system to have a deeper understanding of the data. If these developers create the views, they will understand the nuances of the data and hopefully produce a better product.
Fast, reliable and consistent SQL Server development…
Staging database
A staging database has several advantages over importing directly to the target table or even to a staging table in the same database. It is usually much easier to have a landing area for data when transferring between systems. This allows the initial export process to be tested before major transformations happen. It also opens the types of transformations that can be used and can improve performance of the transformations.
The staging system isn’t restricted to a database. It can also be blob storage, a data lake, file storage, or any valid landing zone. This flexibility allows you to fit it to your current standards and future, cloud standards or virtualization standards. The stating system is a location where your uncurated, raw data, is placed during your processing.
Putting unprocessed data into a separate database also helps when security is critical. Raw data won’t have the same security applied to it. Having the data in a separate, locked down, database makes it very easy to control and audit the user base for the raw data. If you are using dynamic data masking or row level security (RLS), data may need to be transformed first. Restricting the users with access to the staging database largely removes this concern.
A staging database will also have decreased backup requirements. It shouldn’t be the source of truth for any data, so the worst-case scenario is a reload from the source systems. Usually, a recent restore and re-import of the most recent ETL is all that’s needed for the staging database. You can also potentially decrease costs by putting the staging database on a lower performance tier. You will want to be sure it isn’t too much of a bottleneck though. This is a good use-case for a serverless tier, especially when imports are infrequent.
Staging schema
If a separate staging database or area isn’t possible, a staging schema is recommended to segregate data. This makes administration much easier from several perspectives.
A separate schema makes it much easier to lock down security. I like to assign security at a schema level. Having staging data in a designated schema helps ensure regular users aren’t able to access data before it has been processed. This is especially important for sensitive data. If RLS is applied to the data, it won’t be assigned to the staging schema. Not having RLS on the staging table makes ETL easier to troubleshoot. This makes it even more important to exclude general users from this schema since the raw data contains the sensitive data but is only locked down at a schema level.
Clarity of intention is always a goal of any good architecture. Having a separate staging schema helps provide that clarity. It is very easy to determine the use of the tables in the staging schema. It also makes it easier to create validation scripts when the staging data is in a separate schema.
A separate schema and tables also make some administrative tasks easier. I like to design ETL so that the staging tables can be truncated with no impact. The next time the ETL runs, the table will be populated. You also don’t need to do much index or table maintenance if the tables are getting truncated on a regular basis.
This applies to all ETL, but use caution with staging tables and ensure that multiple ETL pipelines aren’t running at the same time modifying these tables. It can result in missing rows, and extra deletes. The best-case scenario is excessive blocking, so make sure only a single ETL is hitting each staging table.
Delete sanity check
If you’ve ever worked in big data systems, you know how much processing is involved and how long it can take to scrub and prepare the data. The last thing you want to do is restore from a backup or re-run a large process. Checking the rows that will be deleted before actually running the delete, a sanity check, can help ensure data integrity. This can also be useful for smaller datasets and projects.
It’s best to tailor each sanity check to the specific dataset and parameterize the check so it can be easily adjusted as the data is better understood.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
DECLARE @DeleteCheck int SELECT @DeleteCheck = CONVERT(decimal(23,2), (SELECT COUNT(*) FROM etl.StagingSampleTable SRC )) / NULLIF(CONVERT(decimal(23,2), (SELECT COUNT(*) FROM dbo.SampleTable )),0) * 100.0 IF @DeleteCheck >= 95 BEGIN DELETE dbo.SampleTable FROM dbo.SampleTable ST LEFT JOIN etl.StagingSampleTable STS ON ST.SampleTableID = STS.SampleTableID WHERE STS.SampleTableID IS NULL END |
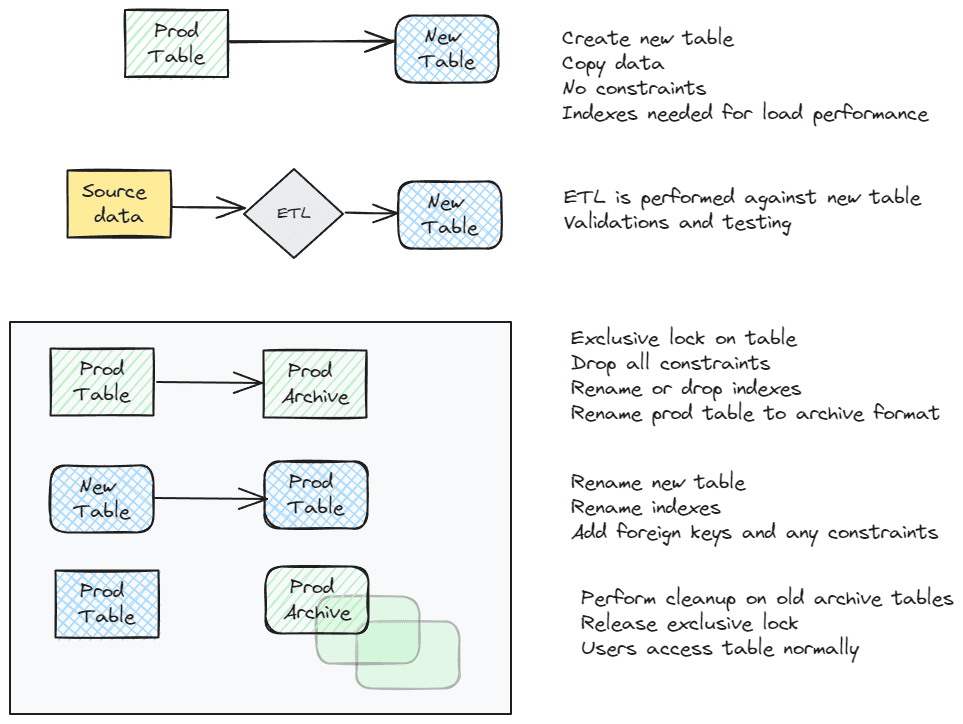
Minimal downtime
Any of the ETL patterns presented in the next section can be combined with this addition. This is a fairly standard pattern that involves virtually no downtime from a user perspective. It isn’t used for every table due to the extra work involved. It requires extra space in the database and extra processing. For large tables, this can be cumbersome, but performing the load on a copy of the table allows additional testing. For extremely complex tables, the extra overhead is well worth the trouble. If any problems are found, they aren’t introduced into your production environment. For extremely large tables, it is a nice safety net.
This is also the method I use to maintain history tables if not using SQL temporal tables. It doesn’t show each individual change, instead it shows the state of the table at a given point in time. This is easier for some teams. Dropping the old tables is also a fast process.
If you do use this method, be sure to consider security. If you need RLS on the table, it may not be a good fit. Using schema level security helps maintain the integrity of your security architecture. You may want to put the archive table(s) in a different schema, or you may allow the same users to access to access the history data.
The pattern is simple in concept and works well once everything is in place. In a transactional system that is actively getting developed it may not be a good fit. New indexes and foreign keys that need to be renamed are an administrative burden. In a warehouse scenario with few or no constraints, it is easier to automate. Indexes still need to be maintained, but that is generally easier to script and maintain.
The basic pattern is to create a new table, copy the existing data to this table, perform ETL operations and validations, then rename the production table to an archive name and the new table to the production name. At that point, all indexes and constraints should also be renamed. The following illustrates the flow. Usually, this will all be managed via the same ETL importing the data. It is also difficult to do if you import data from multiple sources. If this is the case, they all need to be coordinated.
Summary
Choosing the correct ETL pattern starts with understanding the needs for the ETL, existing processes, following enterprise standards, and many other details. Virtualization platforms, data mesh strategies, and data governance will shape your patterns and efforts, as well as the source system specifics.
ETL is a very technical project, but requires a deep understanding of the business and cooperation with many teams. This covered many of the items that need to be considered before defining your ETL pattern. The next part of this series shows common patterns, considerations for their use, and potential downsides to each.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments