

Or: How to make magic tricks with T-SQL
Starting our magic show, let’s first set the stage:
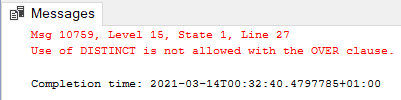
Count Distinct doesn’t work with Window Partition
Preparing the example
In order to reach the conclusion above and solve it, let’s first build a scenario. Using Azure SQL Database, we can create a sample database called AdventureWorksLT, a small version of the old sample AdventureWorks databases.
Let’s use the tables Product and SalesOrderDetail, both in SalesLT schema. Each order detail row is part of an order and is related to a product included in the order. The product has a category and color.
One interesting query to start is this one:
Count(*) AS ItemsPerOrder,
Sum(unitprice * orderqty) AS Total
FROM saleslt.product p
INNER JOIN saleslt.salesorderdetail s
ON p.productid = s.productid
GROUP BY salesorderid
This query results in the count of items on each order and the total value of the order.
Let’s add some more calculations to the query, none of them poses a challenge:
Count(*) AS ItemsPerOrder,
Sum(unitprice * orderqty) AS Total,
Count(DISTINCT productcategoryid) CategoriesPerOrder,
Count(DISTINCT color) ColorPerOrder
FROM saleslt.product p
INNER JOIN saleslt.salesorderdetail s
ON p.productid = s.productid
GROUP BY salesorderid
I included the total of different categories and colours on each order.
Identifying the Problem
Now, let’s imagine that, together this information, we also would like to know the number of distinct colours by category there are in this order.
The group by only has the SalesOrderId. Due to that, our first natural conclusion is to try a window partition, like this one:
Count(*) AS ItemsPerOrder,
Sum(unitprice * orderqty) AS Total,
Count(DISTINCT productcategoryid) CategoriesPerOrder,
Count(DISTINCT color) ColorPerOrder,
Count(DISTINCT color)
OVER (
partition BY productcategoryid) ColorPerCategory
FROM saleslt.product p
INNER JOIN saleslt.salesorderdetail s
ON p.productid = s.productid
GROUP BY salesorderid
Our problem starts with this query. Count Distinct is not supported by window partitioning, we need to find a different way to achieve the same result.
Planning the Solution
We are counting the rows, so we can use DENSE_RANK to achieve the same result, extracting the last value in the end, we can use a MAX for that. This works in a similar way as the distinct count because all the ties, the records with the same value, receive the same rank value, so the biggest value will be the same as the distinct count.
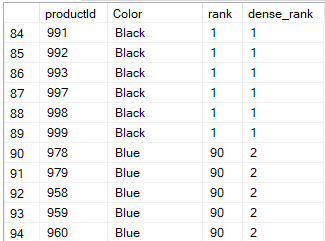
There are two ranking functions: RANK and DENSE_RANK. The difference is how they deal with ties.
RANK: After a tie, the count jumps the number of tied items, leaving a hole.
DENSE_RANK: No jump after a tie, the count continues sequentially
The following query makes an example of the difference:
color,
Rank()
OVER (
ORDER BY color) [rank],
Dense_rank()
OVER (
ORDER BY color) [dense_rank]
FROM saleslt.product
WHERE color IS NOT NULL
The new query using DENSE_RANK will be like this:
Count(*) AS ItemsPerOrder,
Sum(unitprice * orderqty) AS Total,
Count(DISTINCT productcategoryid) CategoriesPerOrder,
Count(DISTINCT color) ColorPerOrder,
Dense_rank()
OVER (
partition BY productcategoryid
ORDER BY color ) ColorPerCategory
FROM saleslt.product p
INNER JOIN saleslt.salesorderdetail s
ON p.productid = s.productid
GROUP BY salesorderid
However, the result is not what we would expect:

The groupby and the over clause don’t work perfectly together. The fields used on the over clause need to be included in the group by as well, so the query doesn’t work.
Solving the Solution
The first step to solve the problem is to add more fields to the group by. Of course, this will affect the entire result, it will not be what we really expect. The query will be like this:
productcategoryid,
Count(*) AS ItemsPerOrder,
Sum(unitprice * orderqty) AS Total,
1 ColorPerOrder,
Dense_rank()
OVER (
partition BY salesorderid, productcategoryid
ORDER BY color) ColorPerCategory
FROM saleslt.product p
INNER JOIN saleslt.salesorderdetail s
ON p.productid = s.productid
GROUP BY salesorderid,
productcategoryid,
color
There are two interesting changes on the calculation:
- CategoriesPerOrder was removed, because the group by is some levels below this calculation, we can leave this for later.
- ColorPerOrder is a fixed value, because we are grouping by colour.
We need to make further calculations over the result of this query, the best solution for this is the use of CTE – Common Table Expressions.
2nd Query Level
The 2nd level of calculations will aggregate the data by ProductCategoryId, removing one of the aggregation levels.
AS (SELECT salesorderid,
productcategoryid,
Count(*) AS ItemsPerOrder,
Sum(unitprice * orderqty) AS Total,
Count(DISTINCT color) ColorPerOrder,
Dense_rank()
OVER (
partition BY salesorderid, productcategoryid
ORDER BY color) ColorPerCategory
FROM saleslt.product p
INNER JOIN saleslt.salesorderdetail s
ON p.productid = s.productid
GROUP BY salesorderid,
productcategoryid,
color)
SELECT salesorderid,
Sum(itemsperorder) ItemsPerOrder,
Sum(total) Total,
1 CategoriesPerOrder,
Sum(colorperorder) ColorPerOrder,
Max(colorpercategory) ColorPerCategory
FROM ranking
GROUP BY salesorderid,
productcategoryid
The calculations on the 2nd query are defined by how the aggregations were made on the first query:
- ItemsPerOrder: We make a SUM on the results of the COUNT, this will aggregate the different counts.
- Total: A simple SUM over the SUM already made.
- CategoriesPerOrder: It can have a fixed number of 1, since we are still aggregating per category
- ColorPerOrder: We make a SUM over the already existing COUNT from the previous query
- ColorPerCategory: After making the DENSE_RANK, now we need to extract the MAX value to have the same effect as the COUNT DISTINCT
3rd Query Level
On the 3rd step we reduce the aggregation, achieving our final result, the aggregation by SalesOrderId
AS (SELECT salesorderid,
productcategoryid,
Count(*) AS ItemsPerOrder,
Sum(unitprice * orderqty) AS Total,
Count(DISTINCT color) ColorPerOrder,
Dense_rank()
OVER (
partition BY salesorderid, productcategoryid
ORDER BY color) ColorPerCategory
FROM saleslt.product p
INNER JOIN saleslt.salesorderdetail s
ON p.productid = s.productid
GROUP BY salesorderid,
productcategoryid,
color),
cte2
AS (SELECT salesorderid,
Sum(itemsperorder) ItemsPerOrder,
Sum(total) Total,
1 CategoriesPerOrder,
Sum(colorperorder) ColorPerOrder,
Max(colorpercategory) ColorPerCategory
FROM cte
GROUP BY salesorderid,
productcategoryid)
SELECT salesorderid,
Sum(itemsperorder) ItemsPerOrder,
Sum(total) Total,
Sum(categoriesperorder) CategoriesPerOrder,
Sum(colorperorder) ColorPerOrder,
Sum(colorpercategory) ColorPerCategory
FROM cte
GROUP BY salesorderid
Once again, the calculations are based on the previous queries. Some of them are the same of the 2nd query, aggregating more the rows. However, there are some different calculations:
- CategoriesPerOrder: It becomes a SUM to achieve the result we would like
- ColorPerCategory: It becomes a SUM, adding all the distinct count results of each category
The Execution Plan
The execution plan generated by this query is not too bad as we could imagine. This query could benefit from additional indexes and improve the JOIN, but besides that, the plan seems quite ok.
There are other options to achieve the same result, but after trying them the query plan generated was way more complex.

The join is made by the field ProductId, so an index on SalesOrderDetail table by ProductId and covering the additional used fields will help the query
We can create the index with this statement:
ON saleslt.salesorderdetail (productid)
include (orderqty, unitprice)
You may notice on the new query plan the join is converted to a merge join, but the Clustered Index Scan still takes 70% of the query

The secret is that a covering index for the query will be a smaller number of pages than the clustered index, improving even more the query. The statement for the new index will be like this:
ON saleslt.product(productid)
include (productcategoryid, color)

What’s interesting to notice on this query plan is the SORT, now taking 50% of the query. This doesn’t mean the execution time of the SORT changed, this means the execution time for the entire query reduced and the SORT became a higher percentage of the total execution time.
Further Learning
There will be T-SQL sessions on the Malta Data Saturday Conference, on April 24, register now
Describe SQL Server Query Plans
Optimize Query Performance in SQL Server
Conclusion
Mastering modern T-SQL syntaxes, such as CTE’s and Windowing can lead us to interesting magic tricks and improve our productivity
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments