
This article should give an overview and understanding of how the translation mechanism that is built-in to Oracle APEX works, and how you should handle it. It is based on Oracle Application Express 4.0.2.00.07 and applies also to Oracle APEX 3.x.
Why even translate my Application?
If you are working on a small in-house application, there is a good chance that you can go with just one language in the user-interface; yours. In this case you could stop reading this article and have a nice cup of tea instead.
In bigger companies, even in-house applications might reach users who speak different languages. Sometimes it’s good enough to go with just the one language that is standard within your company.
However, if you have end-users that are distributed internationally, you will probably end up supporting many languages or at least the most widely-used ones.
In some countries there is a requirement to translate official websites into all languages officially spoken within the country. Switzerland, for example, has four official languages: German, Italian, French and Romansh. So, in Switzerland, you might end up supporting at least these four languages; or perhaps five if you include English.
There are lots of reasons for Applications to be multilingual. Whatever your reason is, you really want to make sure that you have as little overhead as possible with managing all these languages.
Considerations for multilingual Applications
You should think about translating your Application from the very beginning on, because it is easier to know it from the start than to change your code once you are finished.
“Why? I thought Oracle APEX would handle all that for me.”
Well, yes; up to a point. APEX can handle all the User-Interface Texts, but it can’t help you in translating your data.
If you need your Data to also be multilingual, then you will need to take care of it in your data-model and your application code.
There is also a lot more to take into consideration when deploying your application in various languages, such as date- and number-formats or languages printed right-to-left. This won’t be covered in this article, but there are some good books on the market that cover these topics.
Now we’ll focus on the User-Interfece (UI). If you have text that needs to be translated then you need to do no more than to use the regular APEX Attributes.
If, for example, you want to set a label for an item, then use the Attribute “Label” of the item. I know, this sounds obvious, but still it is important.
Avoid using substitutions (that would be something like this: “&P23_SOME_ITEM.” ), because you would need to add some application code to ensure that the item’s value is using the currently active language and gets refreshed when user changes the display language.
To be able to translate the attributes of such things as items or regions, there are two more things APEX supports for multilingual Applications: Text Messages and Dynamic Translations.
A “Text Message” is something like a text module and consists of a name, a language and a value. With the name and the APEX_LANG.Message function you can use these text modules within your PL/SQL Code, e.g. for constructing an error message which should be displayed in the users language.
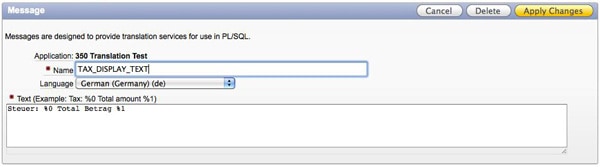
You can have up to 10 placeholders in a text message using the format %0 to %9 which are also handled by the APEX_LANG.Message function.
“Dynamic Translations” work more like a glossary. You define word-to-word translations, which can be used with the APEX_LANG.Lang function within SELECT Statements.
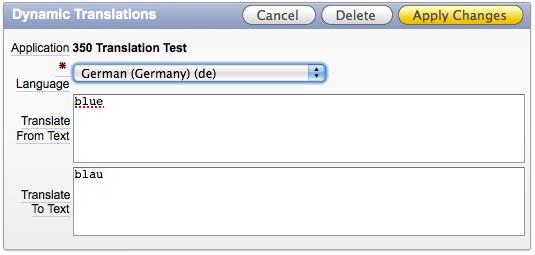
The Downside is obvious; you can have only one translation per term. This may be fine for most cases, but sometimes you’ll come across a requirement to translate a little differently depending on the context.
Overview on the Oracle APEX Translation Concept
Oracle APEX handles Translations as a copy of the main Application. That means that, for every language your Application supports, or in other words is translated to, APEX internally creates a “Shadow Application”. These Shadow Applications aren’t listed in Application Builder, but they are exact copies of the main Application.
When you run your Application in a translated language the Shadow Applications code is executed.
The following pictures shows the “Application Builder”-Application (yes, APEX is written in APEX), which has the Application ID 4000.
The first translation (Spanish) has the Application ID 4001, English 4002, German 4003 and so on.
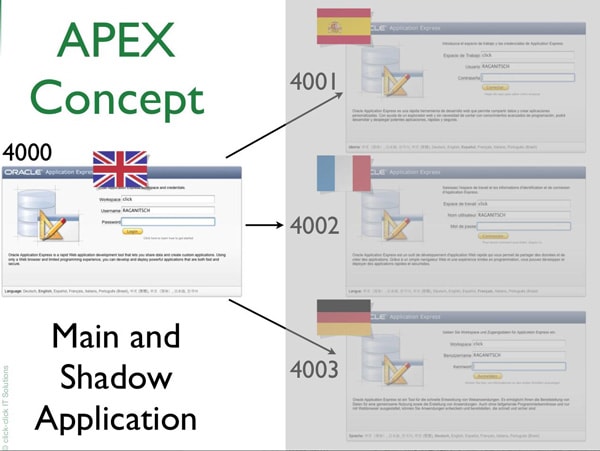
Application IDs for the translations can be specified and just need to be in the NUMBER-Range and can’t end in 0 (zero), because they are internally used on the right side of the decimal point.
I normally suggest using the Main-Application-ID multiplied by 100 and a consecutive number, so that, for example, when your Application-ID is 350 then the first Translation would be 35001, the second 35002 and so on. That makes it easier later on to know which Translation-Application-ID belongs to which “Main”-Application.
When you create your translation Applications, you will not see them in the Application Builder but they exist in the APEX Dictionary Tables. They are hidden in the Application Builder so that you cannot edit them directly.
All code changes are done in the Main Application which are then rolled out to the translated Shadow Applications with the “Seed” and “Publish” Operations. So whenever you need to roll out code-changes you need to Seed and Publish all Translations.
This is it. The main step in understanding Translations in Oracle APEX is to realize that there is always a copy of the full Application (every page, every process, and every single line of code) for each Language you want to support.
Translation Workflow
The Translation Workflow consists of a couple of steps, which may be repeated each time you roll out a new version of your Application.

‘Mapping Languages’ is a configuration step where you specify which languages you want to support and which (internal) Application-ID each language uses. This is a one-time action you don’t need to repeat (except you want to introduce a new supported language).
Oracle APEX included a fallback mechanism in its translation concept, which uses the next “best” language if yours isn’t found.
That means if the user requests language “en-us” (US English) APEX checks if this language is supported. If it isn’t supported APEX checks if “en” (plain English) is supported. If this still isn’t supported it uses the primary language of your application.
This is interesting if your Application uses the Browser settings to determine which language should be displayed.
The translation workflow starts with seeding . With this step all translatable text strings are copied from the Main Application to a single internal translation table. After the seeding process you get statistical information about how many text strings you need to translate and how many in this seeding process where added.
Now you have all the translatable UI-Text strings in the internal table you then have to decide if you want to edit them directly using the “Manually edit Translations” function or if you want to export the entire collection as an XLIFF File.
The facility to manually edit the translations is there to correct a typo or two, but not to translate a whole Application. If you try it you’ll know why.
XLIFF is a special XML Format used widely in the Translation Business. If you give a XLIFF File to a Translation bureau, they will probably know what to do with it.
An APEX XLIFF File consists of many, many blocks like this:
|
1 2 3 4 |
<trans-unit id="S-2-799066865292682042-124""> <source>Print</source> <target>Print</target> </trans-unit> |
Basically there is a source and a target text per Text String (Item Label, Region Title, Window Title, …) in this File.
Good (as in “cost money”) XLIFF Editors include all kinds of rules and translation memories which aim to ensure that your Translation is consistent throughout your application (English “Print” should always translate to German “Drucken”).
Once you have finished editing the XLIFF File, you will need to upload it to APEX and apply it to the internal translation table.
Whichever way you did the translation, or typo correction, it is now the time to re-create those Translation Shadow Applications. This is done with the step “Publish Translated Application”.
What happens here is that APEX deletes the Shadow Application, copies the Main Application to the Shadow-Application-ID and then updates all Text Strings stored in the internal Translation Table.
Whatever you change in the Translation Table is then copied to the Shadow Application.
What you need to keep in mind
The Oracle APEX Translation mechanism is well designed and implemented, but the APEX Team clearly had bigger companies and projects in mind when they designed it.
Don’t get me wrong; it works well, as long as you stick strictly to the workflow and never leave the path.
In bigger projects, it should be simple to develop the application in the main language and then test it. After finishing the tests you seed the translations, export the XLIFF-File and hand it over to the translation office.
They do their magic and return you a perfectly translated XLIFF which you can easily import into APEX and then publish the translated shadow applications.
Now you bundle your main-application with the translated applications and all other stuff you may need (scripts for data model, packages, and so on) and ship it to the customer.
They install it and live forever happy with it…
But real life often looks a little different. You may not have so long and such well-planned development cycles. You may not have access to a translation service, and instead hire some exchange students. You could be using an agile development approach and your customer expects a new version of your application (and all translations) every other week.
Sounds familiar?
Ok, now we can talk about the pitfalls and the internals you need to know to avoid any problems and side-effects.
Let’s take the Seeding process. It should extract only the translatable strings from the main application and write them into the translation table.
What it actually does is to write far too many strings into this translation table, even code-snippets (e.g. Report Region Source). When creating the XLIFF Export File later on, these unnecessary strings are filtered and only translatable strings are exported via the XLIFF file.
For the XLIFF we are on the safe side, but when you use the function “Manually Edit Translation Repository” you can change all those unnecessary strings. This can lead to code differences between your main application and the translations!
Another thing that Seed does is to update your already-translated text if the source-text has changed. Now imagine that you have an HTML Region with a full paragraph of static text. You translate this text into all those languages that you want to support. Then you change a typo in the main-application and issue a Seed again. Whoops, your translations are gone, just because of one single typo.
When you use Dynamic Translations you need to create those Dynamic Translations in all the languages that you need, otherwise they won’t be added to the XLIFF File.
The last step, “Publish”, can be problematic as well. If there is too much time between the ‘Seed’ and the ‘Publish’ and there have been changes in the APEX Application, they might not get into the translated Applications.
Whilst it’s true that ‘Publish’ copies the main-application and then applies the translations, it’s also true that, because of the ‘Seed’, there are code-snippets in the translation table. This way, a code-change can be reversed in the translated application.
So it is better to do a ‘Seed’ before every ‘Publish’ (that would you leave with some translations being overwritten, but that’s better than wrong code, isn’t it?).
Alternatives
Alternatives to the APEX built in functions can be seen as two groups:
- Stick to the APEX mechanism of shadow Applications and only change the translation part
- Don’t use anything from APEX at all and develop your own translation concept
1) change the translation part
If you aren’t satisfied with the given XLIFF-Files and the function to manually edit the translation repository, you could create an APEX Application to provide a better interface to edit the translation Table. This is pretty straightforward and needs only minimum changes in the translation workflow.
Instead of exporting a XLIFF File you simply would run your Application and do the translations.
Another alternative is the ApexLib XLIFF Export Tool that is currently in alpha testing stage and due to be released in the near future. This gives you a XLIFF File similar to the one generated by APEX, but with many more information in it. The ApexLib XLIFF Export writes all the Application structure Information to the XLIFF File and can give you important context info for the translator.
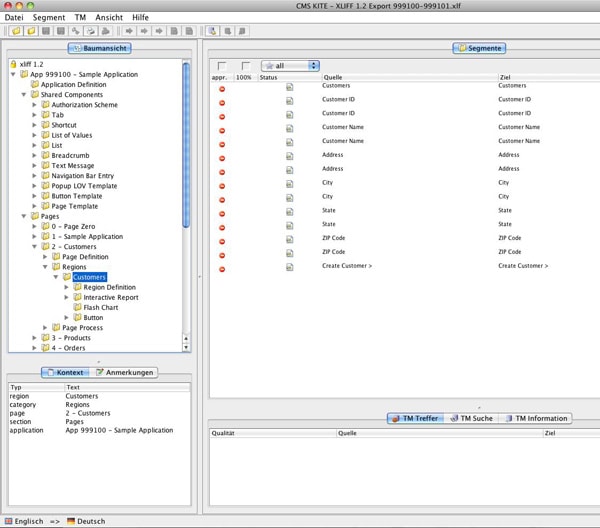
This way the translating person knows what kind of text they are translating, because often it does make a difference if it is a button or an item label.
2) create your own translation concept
Creating your own translation concept requires not only storing those translation-strings in the database, but also reading it from there and displaying it instead of the original text. This can only be done by using substitution strings, which roughly doubles the number of items that you need.
For example, you might have a simple login form displaying a username item and a password item. Both items have a label. To make this label dynamic, so that it can be changed at runtime, you would create two more (hidden) items holding the label of the two displayed fields. The label of P101_USERNAME would then be “&P101_USERNAME_LABEL.”.
This is tricky and needs a lot of thought and a good plan, it also takes more development effort, which thereby increases development costs.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments