
Exchange 2007 Mailbox Server Clustering
In the article ‘High availability in Exchange 2007‘, several options in Exchange Server 2007 were discussed to create a high availability solution. In this article, all Exchange Server 2007 server roles are discussed. I discuss some of the technical challenges that you can expect when deploying clustering technologies, especially on the Exchange 2007 Mailbox Server role.
Exchange 2007 Single Copy Cluster
As explained in the previous article, an Exchange 2007 Single Copy Cluster (SCC) is basically a new name for the ‘traditional’ Exchange clustering. An Exchange 2007 SCC environment is not very different from an Exchange 2003 cluster.
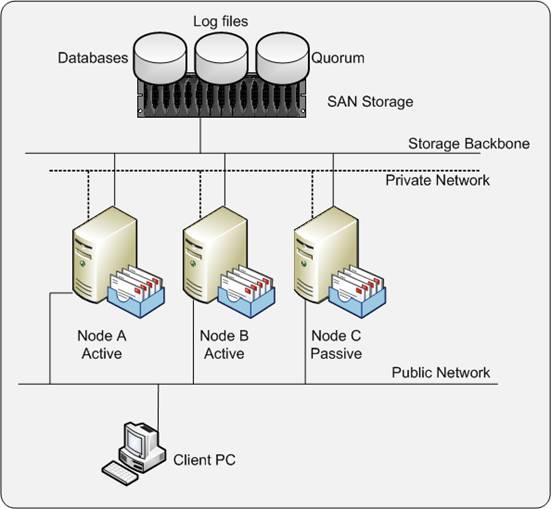
Figure 1. Single Copy Cluster
The most important thing to remember in an SCC environment is regarding ‘shared storage’. Databases and log files are placed on a SAN or other central storage solution. This can be a Fiber Channel solution or an iSCSI solution. Data placed on the SAN is shared by all members of the cluster. Only one node is owner of the data and thus able to process the data at a given time. When this node fails, another node can take over the databases and log files and continue the processing of the data. For the end user, this is a fully transparent process; he or she will hardly notice that something has happened in the background.
Microsoft fully supports a clustered environment, but only if the complete configuration, including the Network Interfaces, host Bus Adapters and even the switches are listed in the Microsoft Logo’d Products List (http://microsoft.com/hcl). If the hardware configuration is listed, the hardware has been fully tested by both Microsoft and the vendor for use in a cluster.
Before installing Exchange, the cluster has to be built. Windows needs to be installed and the hardware needs to be properly configured. All nodes of the cluster need full access to the shared storage locations on the SAN. A special location on the SAN must be reserved for the quorum. This is basically the brains of the cluster, the location where the cluster configuration is actually stored. This is stored on the SAN, but is very limited in size. The smallest unit of allocation within your SAN is sufficient, and normally around 1 GB.
When the hardware is setup correctly you can setup your Windows Server 2003 cluster. This consists of the following steps:
- Create a cluster service account in Active Directory. This account will be used by the cluster service on the Windows Server 2003 cluster nodes. This can be a normal domain user account, but must be a member of the local administrators group on the Windows 2003 cluster node;
- Start the “Cluster Administrator” via the Administrative Tools menu and select “Create New Cluster”;
- Using the New Server Cluster Wizard enter the new cluster name, the service account that you created in step 1, the public IP address of the cluster and the computer name of the first node of the new cluster.
- After verification of the data in the Proposed Cluster Configuration windows you can finish the new cluster configuration. The cluster will now be formed.
- Repeat steps 2 to 5, but instead of “Create New Cluster” select “Add Nodes” to cluster to start the “Add Nodes Wizard”
Please make sure that you have reserved sufficient IP addresses on the public network for your cluster configuration. You need an IP address for every node, an IP address for the Windows Cluster, and an IP address for every Clustered Mailbox Server (CMS) that you create. In figure 1 this means that six public IP addresses are needed.
For internal communication within the cluster a private network is used. This network should not be used for other communications, but only for the cluster. The cluster service uses this network for sending so called “keep alive” messages. Because of sending and receiving these messages a particular node in the cluster is aware of the presence and health of the other nodes.
If the first node in the cluster is configured correctly, you can start adding other nodes to the cluster. Just start the Cluster Administrator in the Administrative Tools menu and select ‘Add node’. The new node contacts the cluster, reads its information, and adds itself to the cluster. Naturally you need to repeat this step for all nodes you want to add to the cluster.
Installing Exchange Server 2007 on the cluster is similar to installing Exchange Server 2007 on a regular server. However you may only install one of two specific clustered mailbox roles. Instead of installing the normal Mailbox Role you have to install the ‘Active Clustered Mailbox Role’. This will install an instance of Exchange Server 2007 in the cluster.
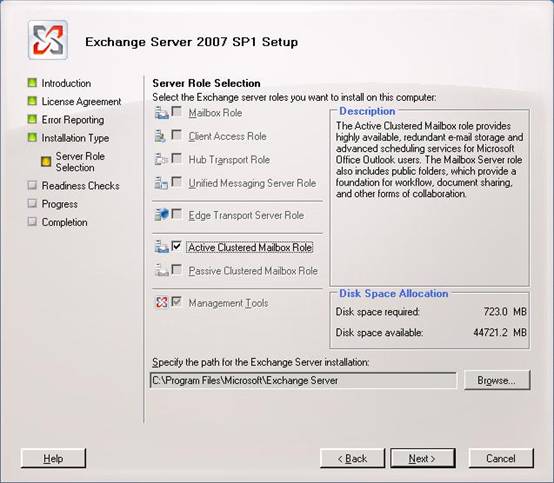
Figure 2. Installing the Active Clustered Mailbox Role
Please be aware that only an Exchange 2007 mailbox server role can be installed on a Windows cluster. For the other roles, such as Client Access Server or Hub Transport Server, you have to install additional non-clustered servers as discussed in the prior article.
When finished installing the Active Node of the cluster, you can continue with the other nodes. In the example shown in Figure 1, you can continue installing another Active Node and finish with installing the Passive Node of the cluster.
Single Point of Failure
An SCC environment works great if a server is lost, but the databases and the log files are still a single point of failure. When the database is corrupt there is the possibility that you won’t get it up and running again in minutes. When this happens there are two options:
- Restore from backup media;
- Repair the database with Microsoft tools;
Whichever you choose, it will most probably be a lengthy operation. Suppose a normal tape backup device will restore at 50 GB/hour and you have a 150 GB database. In that case it will take at least three hours to restore your database from tape. Add to that the time needed to find the right tape, to start the restore itself and maybe to replay log files that are newer than the last backup. There have been situations where an Exchange Server in a clustered environment was out-of-order for more than 24 hours.
Using the Microsoft Exchange tools to repair a corrupt mailbox database can also be a lengthy operation. Tools like Microsoft’s ESEUTIL can process between 5 and 10 GB/hour, depending on the underlying hardware. But 10 GB/hour processing related to the 150 GB database, ESEUTIL will take at least 15 hours to finish processing. And Microsoft PSS would like you to perform an offline defrag with ESEUTIL after you ran a repair with ESEUTIL. So this adds another 15 hours of processing your database. This totals 30 hours when your database and therefore your mailboxes are not available.
Implementing a SCC environment will help you protect against server failure, but since you only have a single copy of your data, it will not protect against database failure. You can lower the risk and possible impact by implementing multiple smaller databases in your environment instead of one large database. If a database failure occurs, only a part of your organization is impacted. But there’s a part still impacted and this part will see an outage of the messaging service.
Replication Techniques
To prevent an outage due to a database failure, Microsoft built some techniques into Exchange Server 2007 that are based on replication techniques. With replication techniques a second copy of the database, or databases are maintained, therefore eliminating this single point of failure.
In Exchange Server 2007 RTM (“Release To Manufacturing”, i.e. the original version of Exchange Server 2007) Microsoft introduced two types of replication:
- Local Continuous Replication
- Clustered Continuous Replication
In Exchange Server 2007 SP1 Microsoft introduced a third type of replication:
- Standby Continuous Replication
Since Standby Continuous Replication is not dependent on any type of Windows Server 2003 clustering it is out-of-scope for this document.
Local Continuous Replication
The first solution from Microsoft for replication is Local Continuous Replication (LCR). As explained in the earlier article, LCR eliminates the single point of failure for the database, but it is still implemented on a single server. It does protect you against a database failure, but it does not protect you against a server failure.
To implement LCR on your Exchange 2007 mailbox server you need an additional disk (or LUN on a SAN) and preferably an additional controller to access this disk or LUN (this is in order to ensure that writing the LCR database copy does not negatively impact production operations). Format this disk with NTFS and give it a drive letter.
One prerequisite for implementing LCR is that a Storage Group can contain only one database. So if you need to implement multiple databases you automatically need to implement multiple Storage Groups.
Although not a hard prerequisite it is a best practice to implement volume mount points for designating where database files and transaction log files are stored. When using volume mount points it is much easier to replace the active copy of the database with the passive copy of the database as explained later in this article.
The next step is to enable LCR on the Storage Group on your Exchange 2007 mailbox server.
Open the Exchange Management Console and select the proper Mailbox Server under Server Configuration. Select the Storage Group you want to enable LCR for and select ‘Enable Local Continuous Replication’ in the tasks pane on the right hand side of the console.
When selected you have to enter the path for the system files, the log files, and the database file. Click finish to have the Exchange Server configure the LCR environment.
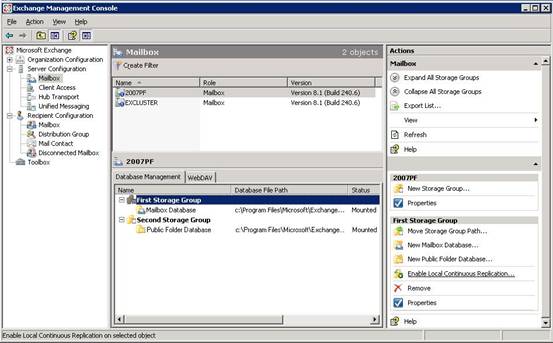
Figure 3. Enable LCR in the Exchange Management Console on the First Storage Group
When finished configuring LCR, Exchange Server 2007 needs some time to replicate the database and the log files to the passive location and have the database duplicate up-and-running. This can be seen in Figure 4. Please note that the files are located on the c:\ drive instead of a different drive. This is configured on a demo system that has no additional disk. In a real world scenario LCR should use a physical separate disk. Depending on the size of the database the this can take a serious amount of time.
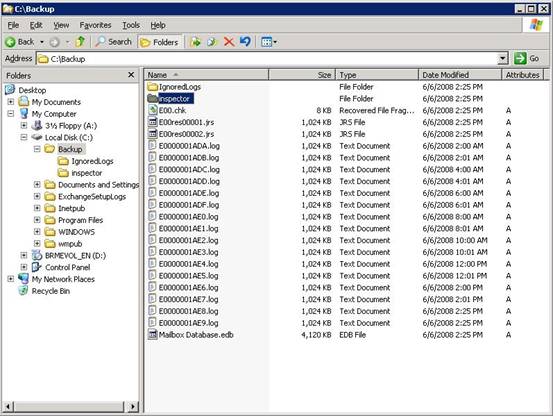
Figure 4. The additional LCR copy as seen in Explorer.
When the Exchange 2007 Mailbox Server role is processing normal message data, all information is flowing through the log files in the active copy. The active copy is the copy of the database that is used for normal operations. When Exchange has filled a log file and the log file is closed it is sent to the passive copy. This is the copy that is in use by LCR. The log file that was received is inspected and replayed into the passive copy of the database.
When the active copy of the database gets corrupt, or the database hardware fails, the end-users will experience an outage of the Exchange service. The messaging administrator now has to replace the active copy of the database, which is the unavailable copy, with the passive copy of the database.
In order to cause this replacement to occur, the following cmdlet should be run in the Exchange Management Shell:
|
1 |
Restore-StorageGroupCopy -Identity "SERVER\First Storage Group" |
Replace the name of the server and the Storage Group with the actual names in your environment.
Using LCR protects you from a database failure by maintaining a copy of the database. Although manual interaction is needed in case of a failure, this works very well. Unfortunately it does not protect you from a server failure like SCC does.
For protecting against a server failure and a database failure, Microsoft combined the cluster technology with the replication technology. This resulted in the Clustered Continuous Replication (CCR).
Clustered Continuous Replication
CCR combines the server protection that the Windows Cluster Service offers in SCC and the database protection that LCR offers. This way your messaging environment is protected against a server failure and a database failure.
When a server failure occurs, the passive node of the cluster automatically takes over the Exchange service. This makes it fully transparent for end-users. Also, when a database failure occurs, the passive copy will take over the Exchange service since the passive copy has its own copy of the database.
A major difference with a traditional cluster is that the CCR environment does not have any shared storage. All data is placed on local storage. This can be just an additional disk or array of disk within your server or an external array attached to your server. This is called Direct Attached Storage or DAS. Naturally, the database can also be placed on a SAN (Fiber Channel or iSCSI) but there’s no need to share this data between the nodes. Using DAS instead of SAN can make a major difference in the investment to make and may keep your messaging environment a lot simpler.
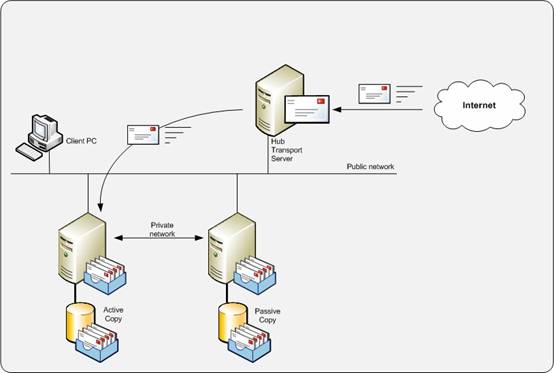
Figure 5. Clustered Continuous Replication
When building a CCR environment, the Windows environment needs to be built first. A CCR environment does not use shared storage, so there’s no quorum resource like in a SCC environment. Yes, there is a quorum, but it is shared between the nodes using normal networking. The cluster technology used for a CCR environment is a special version of clustering available in Server 2003 and Server 2008 called “Majority Node Set” or MNS. This is also a cluster version with an uneven number of nodes. In case of a failure, half of the number of nodes plus one should be available to keep the cluster up-and-running. For CCR, the MNS has changed to support only 2 nodes in a cluster.
A CCR environment can only have 2 nodes. More nodes is not supported and not built in the product.
When implementing a CCR environment, a special Windows share is created outside the cluster. This is normally created on a Hub Transport Server. This share is called the ‘File Share Witness’. In case of cluster problems, the passive node uses this share to determine whether the active node is still alive, or not. In the latter case, the passive node will start up.
Before implementing Exchange Server 2007 in a CCR environment, a cluster needs to be built. This can be using the cluster administrator or using a command line. The command line is useful if you have to build several clusters since you only have to change a couple of variables within a script. In this example we will build a Windows Server 2003 clustering using the command-line.
The first step is to create a cluster service account in your Active Directory. This account will be used by the cluster service on the individual nodes. This can be normal domain user account, but it must be a member of the local administrators group on the individual cluster accounts.
Then create the File Share Witness on the Hub Transport Server. The File Share Witness is used by the Windows 2003 Server cluster to determine which node will form the cluster when the individual nodes cannot communicate with each other anymore. The File Share Witness is created using this script:
|
1 2 3 |
Mkdir c:\MNS_Share1 Net share MNS_Share1=c:\MNS_Share1 /GRANT:Domain\ServiceAccount,Full Cacls c:\MNS_Share1 /G BUILTIN\Administrators:F Domain\ServiceAccount:F |
Note: replace ServiceAccount with the name of the account you created in the first step.
This script creates the directory on the local disk of the Exchange 2007 Hub Transport Server and shares it on the network. It also grants the built-in group Administrators and the cluster service account Full Access on the share and the directory itself.
When the File Share Witness is created we can start building the active node of the cluster.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
::Step 3 - Initiate Cluster service cluster WINCLUSTER /create /ipaddress:10.0.0.101 /User:domain\ServiceAccount /password:<<password>> /verbose /unattended /minimum ::Step 4 - Make the cluster an MNS cluster cluster /cluster:WINCLUSTER resource MNS /create /group:"Cluster Group" /type:"Majority Node Set" /priv MNSFileShare="\\HUBSERVER\MNS_Share1" /online ::Step 5 - Delete the default Local Quorum cluster /quorumResource:MNS cluster /cluster:WINCLUSTER resource "Local Quorum" /Offline cluster /cluster:WINCLUSTER resource "Local Quorum" /delete ::Step 6 - Add nodes to the cluster cluster /cluster:WINCLUSTER /Addnodes:NODE1 /Minimum /Password:<<password>> /verbose cluster /cluster:WINCLUSTER /Addnodes:NODE2 /Minimum /Password:<<password>> /verbose |
This script creates the Windows cluster; you only have to replace the servername, the ServiceAccount and the IP Address according to your own environment. The next steps are to create a new MNS resource and define the File Share Witness on the Hub Transport Server as the MNS File Share within the cluster.
The original MNS quorum that’s automatically created in step 3 is taken offline and deleted in step 5 since we created a new MNS quorum in step 4 based on the File Share Witness.
The last steps are adding the two nodes to the cluster. Only replace the names NODE1 and NODE2 with your own server names.
After creating the Windows cluster, Exchange Server 2007 can be installed and the Exchange 2007 CCR environment can be configured.
|
1 2 3 4 |
:: Step 7 - Install Exchange 2007 binaries and create Exchange cluster <<source>>\setup.com /mode:Install /Roles:Mailbox /targetDir:"%programFiles%\Microsoft\Exchange Server" ::Exchange Activecluster \\<source>\ setup.com /NewCMS /CmsIpAddress:10.0.0.110 /CmsName:EXCLUSTER |
The first step installs the Exchange 2007 software in the appropriate directory. Please replace <<source>> with the location where the Exchange setup files reside, i.e. d:\ or \\anothershare\ if the software is on the network somewhere.
The second step creates the actual Exchange 2007 CCR environment.
The last step is to install the Exchange software on the passive node of the CCR environment using the following script:
|
1 2 |
:: Step 8 - Add Binaries on the Exchange Server 2007 passive node <<source>>\setup.com /mode:Install /Roles:Mailbox /targetDir:"%programFiles%\Microsoft\Exchange Server" |
Your Exchange 2007 cluster is now ready to use and you can start configuring the Exchange 2007 environment using the Exchange Management Console or the Exchange Management Shell and the Windows Cluster Administrator.
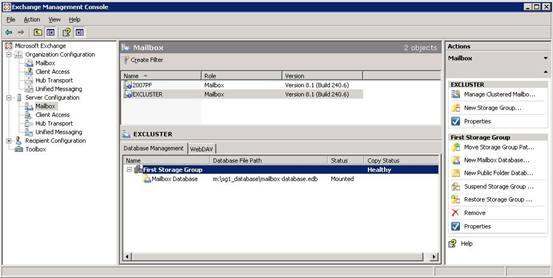
Figure 6. The newly created CCR environment as seen in the Exchange Management Console. Note the healthy state of the Copy Status.
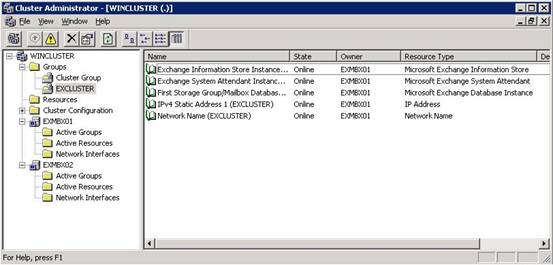
Figure 7. The newly created CCR environment as seen in the Cluster Administrator
In contrast to LCR, where recovery is a fully manual process, recovery in a CCR environment is fully automatic. When the passive node fails, whether it is a server failure or a database failure, the passive node automatically takes over.
The replication process is identical to LCR. When the active node has finished processing an Exchange log file, the log file is replicated to the passive node. After receiving the log file, it is inspected and replayed into the passive copy of the database. There’s a delay however, between the active and the passive copy. Depending on the utilization of the active Exchange 2007 mailbox server this delay can be more than 20 log files.
This means that when a fail-over occurs and the passive node takes over, there is a potential loss of e-mail. To prevent this, the Exchange 2007 Hub Transport server keeps a cache of all messages sent to the active node of the cluster. This cache is called the Transport Dumpster. When a fail-over occurs, the replication service contacts the Transport Dumpster to request a redelivery of the last messages. This way a near zero mail loss fail-over can be achieved.
The health of a Storage Group copy can be retrieved by the following Exchange Management Shell Command:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
Get-StorageGroupCopyStatus -identity "NODE1\First Storage Group" | fl The |fl option gives you detailed output from the commandlet: [PS] C:\Documents and Settings\Administrator>Get-StorageGroupcopystatus |fl Identity : EXCLUSTER\First Storage Group StorageGroupName : First Storage Group SummaryCopyStatus : Healthy NotSupported : False NotConfigured : False Disabled : False ServiceDown : False Failed : False Initializing : False Resynchronizing : False Seeding : False Suspend : False CCRTargetNode : EXMBX02 FailedMessage : SuspendComment : CopyQueueLength : 0 ReplayQueueLength : 0 LatestAvailableLogTime : 6/6/2008 7:55:38 PM LastCopyNotificationedLogTime : 6/6/2008 7:55:38 PM LastCopiedLogTime : 6/6/2008 7:55:38 PM LastInspectedLogTime : 6/6/2008 7:55:38 PM LastReplayedLogTime : 6/6/2008 7:55:38 PM LastLogGenerated : 60102 LastLogCopyNotified : 60102 LastLogCopied : 60102 LastLogInspected : 60102 LastLogReplayed : 60102 LatestFullBackupTime : 6/5/2008 8:01:07 PM LatestIncrementalBackupTime : 6/6/2008 6:00:54 PM LatestDifferentialBackupTime : LatestCopyBackupTime : SnapshotBackup : True SnapshotLatestFullBackup : True SnapshotLatestIncrementalBackup : True SnapshotLatestDifferentialBackup : SnapshotLatestCopyBackup : OutstandingDumpsterRequests : {} DumpsterServersNotAvailable : DumpsterStatistics : IsValid : True ObjectState : Unchanged [PS] C:\Documents and Settings\Administrator> |
It can always happen that for some reason the replication breaks and needs to be repaired. This should be performed on the passive node since this is the location where the replica resides.
The replication can be fixed by entering the following commands in the Exchange Management Shell:
|
1 |
Suspend-StorageGroupCopy -Identity "excluster\second storage group" |
Next step is to delete the passive copy of the database file and the corresponding log files and let the replication process update the passive copy by entering the following command in the Exchange Management Shell:
|
1 |
Update-StorageGroupCopy -Identity "excluster\second storage group" |
A new copy of the database will be created on the passive copy and the log files will be replication again to the passive node. After convergence, both the Exchange Management Console (as can be seen in Figure 6) as well as the output from the Get-StorageGroupCopyStatus commandlet should read ‘healthy’ again.
Conclusion
Exchange clustering techniques can be used to increase the availability of your Exchange Mailbox Server. The traditional clustering technique, now called Single Copy Cluster, does protect you against a server failure but does not protect you against a database failure. Also the requirement of shared storage can make the configuration complex, especially when your cluster hosts a large number of servers.
Replication techniques in Exchange Server 2007 can safeguard you from a database failure. With Local Continuous Replication you are protected against a database failure, but since LCR is built on top of a single server it does not protect against a server failure. Furthermore, recovery from a database failure is a fully manual process.
CCR is a very nice solution, protecting against both a server failure as well as a database failure. Also the combination with the Transport Dumpster will lead to an almost zero mail loss scenario.
Since the CCR solution is not built on shared storage, the CCR solution is far less complex than a SCC environment and it even works well with Direct Attached Storage.
The best option to implement is a CCR solution when you want to achieve a high availability Exchange Sever 2007 environment.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments