
Exchange Database Technologies
In this article I’ll explain some of the fundamentals of the Exchange Server database technology. The primary focus is on Exchange Server 2007, but when appropriate I’ll refer to Exchange Server 2003. This article is the first in a series about Exchange database technologies, backup, restore and disaster recovery.
What’s on the disk?
When you’ve installed Exchange Server 2007 you will find some database files on the C:\ drive, typically in “C:\Program Files\Microsoft\Exchange Server\Mailbox\First Storage Group\” as can be seen in figure 1.
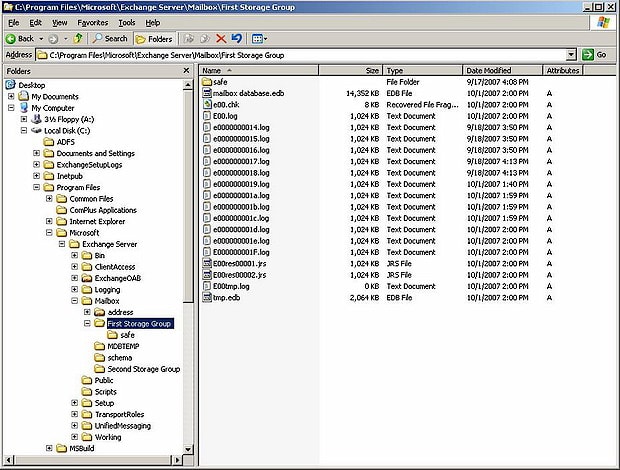
Figure 1. Database files in a standard Exchange setup
We can see several files in this directory:
- mailbox database.edb – this is the actual mailbox database where all the mailboxes are hosted. One or more mailbox databases can be hosted in one directory;
- E00.log and subsequent log files – these are log files that are used by Exchange server for transactional processing of all information;
- e00.chk – a checkpoint file that keeps track of the relation between the information in the log files and in the database;
- E00tmp.log – a temporary log file;
- E00res00001.jrs and E00res00002.jrs – temporary reserved log files used by Exchange server in case a disk full situation occurs.
These files belong together and create a so-called “Storage Group”. During the installation of Exchange Server one database is created in a Storage Group. In Exchange 2007 the Public Folder database is created in a second Storage Group. When replication technology (like LCR, CCR or SCR) in Exchange 2007 is used than only one database per Storage Group can exist. If no replication technology is used, up to five databases can be created in each Storage Group.
So, a Storage Group is a set of one or more database files that share a common set of log files.
ESE – Extensible Storage Engine
The underlying technology used in Exchange Server is the Extensible Storage Engine, or ESE. ESE is a low-level database technology, sometimes referred to as JET database. ESE has been used for Exchange since the first version of Exchange, version 4.0 in 1997. But Active Directory, WINS, and DHCP also use a form of ESE.
The ESE database follows the ACID principle. ACID stands for:
- Atomic - A transaction is all or nothing, there is no “unknown state” for a transaction;
- Consistent – the transaction preserves the consistency of the data being processed;
- Isolated – a transaction is the only transaction on this data, even when multiple transaction occur at the same time;
- Durable – the committed transactions are preserved in the database.
Transactions can be seen in normal life as well. Suppose you go to the bank to transfer money from your savings account to your normal account. The money is withdrawn from your savings account and then added to your normal account and both actions are recorded and maybe printed on paper. This can be seen as one transaction. You don’t want it to end in an unknown state, where the money is withdrawn from your savings account but not added to your normal account.
The same principle goes for Exchange Server. Suppose you move a message from your inbox to a folder named “Simple Talk”. From a transaction point of view it starts by adding the message to the “Simple Talk” folder, then it updates the message count from this folder, it deletes the message from the Inbox and updates the message count for the Inbox. All these actions can be seen as one transaction.
The mailbox database
The mailbox database is the primary repository of the Exchange Server information. This is where all the Exchange Server data is stored. On disk it is normally referred to as “mailbox database.edb”; in older versions of Exchange Server it is called Priv1.edb, but it can have any name you want.
In Exchange Server 2000 there was also a file called Priv1.stm, referred to as the streaming file. It was meant to store Internet messages like SMTP. These messages were saved in the streaming file and a pointer was set in the .edb file. An .edb file and a .stm file belong together and cannot exist without each other. The streaming file was removed from Exchange 2007, which was possible because of the improvements to ESE, though Exchange 5.5 also had no .stm file. ,
In theory the mailbox database can be 16 TB in size, but it is normally limited to a size you can handle within the constraints of your Service Level Agreement or SLA. The recommend maximum database size of a normal Exchange Server 2007 (or earlier) is 50 GB, for an Exchange Server 2007 using Local Continuous Replication it is 100 GB, and for an Exchange Server 2007 using Continuous Cluster Replication it is 200 GB. These are sizes that can readily be used in a normal backup cycle and can be restored in an appropriate timeframe when needed.
The data within a database is organized in a Binary Tree, or B+ Tree. A Binary Tree can be seen as an upside down tree where the leaves are in the lower part. The actual mail data is stored in the leaves. The other pages only contain pointers. This is a very efficient way of storing data since it requires only two or three lookups to find a particular piece of data and all pointers can be kept in memory.
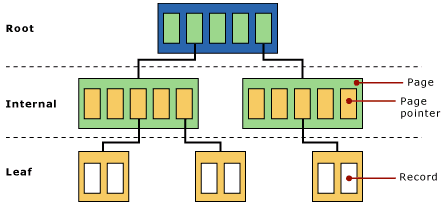
Figure 2. A Binary Tree used in Exchange Server. The actual data is stored in the leafs
One or more Trees in a database make a table. There are several kinds of tables in an Exchange server:
- Folders table;
- Message table;
- Multiple Message Folder tables;
- Attachment table;
The tables hold the information we can see in Outlook (Web Access). The tables consist of columns and records, the columns are identified as MAPI properties, the records contain the actual information.
Multiple Trees exist in one database and sometimes Trees need to be split when the Tree fills up. Exchange Server’s internal processes will reorganize all information from one Tree into two Trees. This is called a “split”. It is not possible to predict how many Trees will be in a particular database, but it will be hundreds or thousands of Trees. This can be seen in the header of the database which will be explained later in this article.
Database pages
A page is the smallest unit of data in an Exchange Server environment. For Exchange Server 2007 a page is 8KB in size, all earlier versions use a 4KB page size. Increasing the page size from 4KB to 8KB results in a dramatic increase in performance of the database technology. There are also several hardware storage solutions that perform much better with a page size of 8KB.
A page consists of a header, pointers to other pages, checksum information and the actual data from Exchange Server regarding messages, attachments or folders for example. A database file can consist of millions of pages. The total number of database pages can easily be calculated by dividing the total size of the database by the page size 8KB. If a database for example is 100 GB in size, it consists of 100 GB/8KB = approximately 13.1 million pages. Each page is sequentially numbered. Whenever a new page is created it gets a new incremented number. When pages are read from the database and altered, they get a new number before being written to the log file and flushed to the database file. Needless to say, this sequential number must be a very large number. It’s a 64-bit number which means 18 quintillion changes can be made to a database.
How does it fit together
There are four parts that are import with respect to Exchange Server data:
- The internal server memory – this is the location where all the processing of data takes place. Exchange server creates new database pages when needed and processes them. When a database page is needed from the database file it is read from the disk into memory.
- The log files – as soon as Exchange Server has finished processing the database pages for a transaction they are immediately written to the log file in use at that moment. This is the log file called E00.log, or E01.log, E02.log etc. depending on the Storage Group. Please remember that every Storage Group has its own set of log files starting with its own prefix like E00, E01, E02 etc. The database pages are kept in memory though because the pages might be needed in the near future. If so and it is still in memory it saves the Exchange Server a disk read. A disk read is a valuable disk action that is much slower that a page read from memory. When a log file is filled it is closed and renamed to a different name. This name consists of the prefix, followed by a sequential number which is incremented every time the log file is saved. This is way you can see files like E0000001.log, E0000002.log, E0000003.log etc. Be aware that the sequence use HEX numbering – the log file that follows E0000009.log is going to be E000000A.log, not E0000010.log. The sequence number in Exchange terms is called the lGeneration number. This process is called the log file roll-over.
- The database file, the part where the database pages are stored eventually. As stated before, a transaction is written to the log file first but it is kept in memory. When Exchange needs more memory the database pages are flushed to the database file. They are flushed from memory to the database file, they are not read from the log files and then written to the database. This is a common misunderstanding! Flushing data to the database file also occurs when pages are kept too long in memory and the gap between the log files and the database file become too large.
The difference between the transactions in the log file and the transactions in the database is monitored by the checkpoint file, E00.chk (for the first storage group). The checkpoint file records the location of the last transaction written to the database file. As soon as a new transaction is written to the database file the checkpoint file location is advanced to the next location.
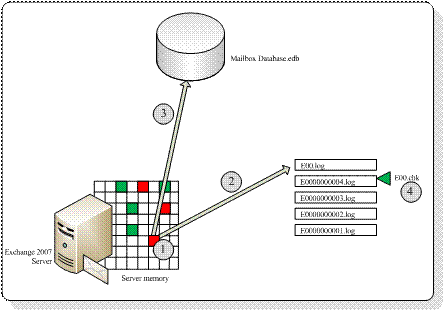
Figure 3. Schematic overview of the working of the Exchange Server database
The above mentioned process is the same in all versions of Exchange Server.
Note. One serious constraint in Exchange 2003 and earlier is the 32-bit platform which is limited to only 4 GB of memory. All processes will run in this 4 GB memory, separated into 2 GB of system and 2 GB of user space. This is relatively tight for caching purposes, especially when a large number of mailboxes are consolidated on one Exchange 2003 server. It can be tweaked using the /3GB and the /USERVA switch in the boot.ini file of the Exchange Server, but it still isn’t an optimal situation.
Memory constraints will always result in a higher disk IO, and when the storage is not designed properly this will result in a bad performance. Most of the Exchange 2003 performance issues are related to bad storage design. Exchange 2007 is a 64-bit platform and memory usage on a 64-bit server is only limited by your budget. Exchange 2007 will use as much memory as possible for caching, which will result in fewer IO operations on the disk. So, the more memory in your Exchange 2007 server, the less disk IO you will see on your storage.
All transactions in an Exchange server flow through the log files. This is the only way to achieve a consistent environment. This includes everything – new messages as they arrive, the creation of new folders, moving messages between folders, deleting messages, appointments, notes etc. All information in the mailbox goes through the log files. The creation of the mailbox (not the mailbox properties in Active Directory though!) is recorded in the log files, and even the creation of a mailbox database is recorded in the log files. This automatically means that if you lose your database and you still have all your log files available (maybe in combination with your last backup set) you can reconstruct everything up to the point you lost your database!
Note. It is very important to separate your log files and your database files. Separate them on multiple disks or multiple LUNs. If you separate them on multiple LUNs on your SAN, make sure that under the hood multiple, separated disks are used. This will have a positive impact on your performance and it will make sure you have a recovery path when either one of the disks is lost!
One important point to remember is that the log files are always in advance of the database, so there’s always data not yet written into the database. This data can cover a number of log files and this number of log files or amount of data is called the “checkpoint depth”. This automatically means the database in a running state is always in a non-consistent state. To get it in a consistent state all log files in this range are needed. This is because data is already written to the log files, but not yet to the database file.
In Exchange Server this is called a “dirty shutdown” state. When a database is dismounted it is brought into a consistent state. All data not yet written to disk is flushed to the database and all files are closed. All information is now written into the database. This is called a “clean shutdown” state of the database.
The log files needed to get the database into a consistent state or ” clean shutdown” is recorded in the header of the database. The header of a database is written into the first page of the database file and contains information regarding the database. The header information can be retrieved using the ESEUTIL tool. Just enter the following command in the directory where the database file resides:
|
1 |
ESEUTIL /MH "Mailbox Database.edb" |
Which will result in an output like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
F:\SG2>eseutil /mh mbx2.edb Extensible Storage Engine Utilities for Microsoft(R) Exchange Server Version 08.01 Copyright (C) Microsoft Corporation. All Rights Reserved. Initiating FILE DUMP mode... Database: mbx2.edb File Type: Database Format ulMagic: 0x89abcdef Engine ulMagic: 0x89abcdef Format ulVersion: 0x620,12 Engine ulVersion: 0x620,12 Created ulVersion: 0x620,12 DB Signature: Create time:07/03/2008 21:44:30 Rand:136947877 Computer: cbDbPage: 8192 dbtime: 8851359 (0x870f9f) State: Dirty Shutdown Log Required: 14647-14658 (0x3937-0x3942) Log Committed: 0-14659 (0x0-0x3943) Streaming File: No Shadowed: Yes Last Objid: 6345 Scrub Dbtime: 0 (0x0) Scrub Date: 00/00/1900 00:00:00 Repair Count: 0 Repair Date: 00/00/1900 00:00:00 Old Repair Count: 0 Last Consistent: (0x2F16,2D,181) 07/29/2008 19:34:29 Last Attach: (0x2F17,9,86) 07/29/2008 19:34:29 Last Detach: (0x0,0,0) 00/00/1900 00:00:00 Dbid: 1 Log Signature: Create time:07/03/2008 21:44:29 Rand:136951962 Computer: OS Version: (5.2.3790 SP 2) Previous Full Backup: Log Gen: 8697-8722 (0x21f9-0x2212) Mark: (0x220D,1EC,162) Mark: 07/19/2008 22:57:43 Previous Incremental Backup: Log Gen: 0-0 (0x0-0x0) Mark: (0x0,0,0) Mark: 00/00/1900 00:00:00 Previous Copy Backup: Log Gen: 0-0 (0x0-0x0) Mark: (0x0,0,0) Mark: 00/00/1900 00:00:00 Previous Differential Backup: Log Gen: 0-0 (0x0-0x0) Mark: (0x0,0,0) Mark: 00/00/1900 00:00:00 Current Full Backup: Log Gen: 0-0 (0x0-0x0) Mark: (0x0,0,0) Mark: 00/00/1900 00:00:00 Current Shadow copy backup: Log Gen: 0-0 (0x0-0x0) Mark: (0x0,0,0) Mark: 00/00/1900 00:00:00 cpgUpgrade55Format: 0 cpgUpgradeFreePages: 0 cpgUpgradeSpaceMapPages: 0 ECC Fix Success Count: none Old ECC Fix Success Count: none ECC Fix Error Count: none Old ECC Fix Error Count: none Bad Checksum Error Count: none Old bad Checksum Error Count: none Operation completed successfully in 0.578 seconds. F:\SG2> |
Plenty of interesting information regarding the database can be found in this output:
- DB Signature – a unique value of date, time and an integer that identifies this particular database. This value is also recorded in the log files and the checkpoint files and this ties them together;
- cbDbPage – the size of the pages used in this database. In Exchange 2007 this is 8KB, in earlier versions of Exchange Server this is 4KB;
- Dbtime – (part of) the number of changes made to this database;
- State – this files shows the state of the database, i.e. is it in a consistent state or not. The database in this example is in a “dirty shutdown” state (I crashed it to get the information) and it needs a certain amount of log files to get in a “clean shutdown” state;
- Log Required – If it is not in a consistent state, these log files are needed to bring it into a consistent state. To make this database a consistent state again, the log files E000003937.log through E000003942.log are needed. Exchange Server will perform the recovery process when mounting a database, so under normal circumstances no Exchange Administrator action is needed.
- Log Committed -This entry is for a new feature in Exchange 2007 called “Lost Log Resiliency” or LLR. Under normal operation the E00.log is just an open file. When the Exchange Server crashes there is the possibility that the E00.log will be corrupted. When this happens it is no longer possible to recover the database to a consistent state because E00.log is in the “Logs Required” range. The LLR feature takes the E00.log out of the “Logs Required” range, making it possible to do a recovery even if the E00.log is lost. One important thing to note is that all information already contained in the E00.log will be lost!
- Last ObjID – the number of B+ Trees in this particular database. In this example there are 6345 B+ trees in the database;
- Log Signature – a unique value of date, time and an integer that uniquely identifies a series of log files. As with the database signature this ties the database file, the log files and the checkpoint file together.
- Backup information – Entries used by Exchange Server to keep track of the last full or incremental (or VSS) backup that was made on this particular database.
The same kind of information is logged in the header of the log files (ESEUTIL /ML E00.LOG) and in the header of the checkpoint file (ESEUTIL /MK E00.CHK). As these file are grouped together you can match these files using the header information.
Conclusion
A Storage Group in an Exchange Server is one or more database files, a set of log files and a checkpoint file. These files belong together and have a tight relationship. But if you understand the basic principles of transactional logging it isn’t too difficult. All information in a database is first recorded in the log files for recovery purposes, so deleting “unneeded” log files to create additional space is a bad idea since it will break the recovery process. Don’t just delete these log files, but have them purged by a backup application. This way you have a recovery process using this backup and the log files that are generated after the last backup.
Bad things can happen to databases and log files in recovery scenarios. These bad things are not normally caused by Exchange Server itself, but by administrators that do not know what they are doing and the implications of their actions.
Install a test server, create some storage groups and mailboxes and start playing around with the databases. See for yourself what happens during a crash and discover the databases and the header information. It will be the first step in a solid disaster recovery plan!
In my next article I will explain what happens during recovery, replay of log files, and offline backups
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments