
In this article I will describe the basics of Master Data Management and its importance for any organization. After sketching out the concepts of MDM, I will summarize the problems you can solve proactively by keeping your enterprise master data at the highest level of current practice.
I will also explain how MDM is implemented for SQL Server and point out the major services that are provided, and I’ll give a brief overview of how MDM solutions are designed and implemented using MDS, DQS, and SSIS. Since each of these services are quite complex I will tackle a more detailed description of each service in subsequent separate articles.
Context
It is the data flowing through applications that defines the business value of an enterprise systems. All organizations of any size will have a complex set of disparate systems and technologies, including Enterprise Resource Planning (ERP), Human Resource Management (HRM), Customer Relationship Management (CRM), Supply Chain Management (SCM), and Financial system. These systems create a tendency toward data silos. The consequence of this is that data can end up being duplicated, sometimes inconsistent, occasionally incomplete, and sometimes inaccurate. The symptoms of these problems are:
- Fragmented data
Because data is handled by several poorly-connected systems that don’t share a common understanding of the data, it is fragmented across the organization. Even if this data is unambiguously related to a specific customer or product, none of the systems have a complete set of information about that customer or product. - Inconsistent data
Because the organization cannot implement all their systems together at one time, and because data is created by different departments and users, there is no simple automated way to make these data points consistent with other systems. Inconsistent data creates integration problems because the various other systems don’t necessarily understand the data exported by a particular system even if they have data about the same customer or product. - Inaccurate data state
In general, business systems do not provide a way for other systems to retrieve the data as it was at a particular point in time: only the final, current state of the data. There is no way to capture the data state at point in time. This can make even simple business-intelligence questions impossible to answer. - Data Correlation
Business transactions are recorded in various systems for each customer/vendor at a different point in time without a unique, consistent and commonly-held customer ID. Due to absence of common identifier this, or any other, business entity, it becomes hard to analyze customer behavior stored in various systems and opportunity to cross-sell/up-sell is lost. - Domain based data security
Though almost all enterprise-level systems come with security features, most of them neglect to provide any security at domain level. This means that anyone with application-level access will than have access to all data whether it is appropriate to their role and level of responsibility or not. There is often no concept of domain-specific security in most enterprise applications and they often lack granular security controls: In consequence, data is at risk. Security should allow sufficient access to data for the user to perform their role in the organization, but no more than that. - Data-centric ownership
Most enterprise applications do not provide a way of allowing organizations to impose ownership rules on data across applications, identifying business domains like product, customer, etc. thereby allowing domain-based ownership. Anyone with application access can modify any and all data. This makes audit and security far more difficult to impose and track. - No business process
Most systems do not allow the organizations that use them to comply with life-cycle rules and processes for data governance. This means that, even where industry standards and the regulatory framework demands that changes to data require a subsequent approval process, sign-off or quality check. This cannot be done because of the rigidity of the system. - Slow response to changing business need
It’s hard to react quickly to the changing business requirements of most enterprises when change has to be made in many separate systems. Not only is this prone to errors but it is also very time consuming. You have to make changes to each of the systems affected, and manage a coordinated release: This is because there is no mechanism defined for automatically distributing the changed data to all consumers. - Multiple data formats
Businesses handle increasing amounts of data, in more formats and from various sources. Because there is no centralized single standard format for the import of data, the enterprise has to use a lot of resources in converting data to, and from, a variety of formats and then distribute it this data to all the systems that need it. - Mergers and Acquisitions
Mergers and acquisitions happen frequently, and when they do, it means that all the various systems have to be merged together into a single logical entity. Where this process is fudged, more data inconsistency is added and there are then more disparate systems, even for a single business domain, that have somehow to be kept in sync. - Regulatory compliance
When a business has to have an external audit, this can be a very expensive operation where an extra day spent can break a budget. Where an organization has disparate systems, with different ways of handling changes, and where not all support audit capability, external audit can get slowed down to a crawl. Without a centralized system for auditing data, it is hard to collect and merge reports from various systems for the purposes of audit and regulatory compliance.
These are some of the more significant problems that have led to the creation of Master Data Management. This is a solution that aims to help organizations to achieve and maintain a single view of master data across the organization. To handle these difficulties that I’ve outlined, a there must be a reasonable way to consolidate, cleanse, enrich, manage and ultimately distribute this data to downstream systems.
What is Master Data Management
Master data management (MDM), defines a process of collecting enterprise data from various sources, applying standard rules and business processes, building a single view of the data, and finally distributing this ‘golden’ version of data to various systems in the enterprise, thereby making it accessible to all consumers.
This is different from existing data warehousing systems. The purpose of data warehousing is to make it easier to perform analytics and business intelligence on historical data from transactional systems as well as from an MDM system. Master Data Management (MDM) reconciles data from various systems to create a single view of the master data, more usually for operational purposes. MDM stores data about entities: in other words
- People (Customers, Vendors, Employees, Patients, etc.)
- Things (Products, Business Units, Parts, Equipment, etc.)
- Places (Locations, Stores, Geo Areas, etc.)
- Abstractions (Accounts, Contracts, Time, etc.) which is less frequently changed.
MDM provides a way to import data from various sources using different formats into staging tables: It then can map this staged data to domain attributes for standardization and normalization, cleanse data, apply business rules, enrich data, and finally mark it as a ‘named’ version. This named version of data is ready for transferring to downstream systems, usually via web service endpoints, and provide a mechanism for publishing data to subscribed consumers.
MDM creates a new version of data every time changes are made, along with information about who is making the change. You can trace it back and look for differences (delta) between various versions, when it was made and who did it. By having this level of auditing history, your organization is helped to achieve complete regulatory compliance and also to provide an overall enterprise information management program.
Because MDM comes with industry-standard access controls, only authenticated and authorized users can see and make changes to data. MDM doesn’t only capture an organizations master data at one place but it also provides security to data.
Features of a typical MDM system
- Domain
A logical way to keep master data separated by business domains such as Customer, Vendor or Product. - Repository/Entity
A repository defines the structure of your master data. The structure is determined by using pre-defined attributes and user-defined attributes. It is analogous to database tables. - Attributes
Attributes define the structure of a repository. These is best thought of as being like database table columns. Every repository comes with one or more predefined attributes and you can add custom attributes as and when you need them. - Attribute Groups
It’s a way to logically group similar types of attributes together, based on a business area. An example might be having a ‘Tax Info’ attribute group that might include attributes related to taxation USFED, VAT, etc. - Business Processes
A business process models the real-world processes to perform various tasks such as email, approval notification, etc. A well-defined business process can be implemented as a set of procedures to govern the data. - Business Rules
Repository attributes are defined as being of a particular type and with a certain length, but business rules are used for more complex constraints such as where number values should be in range of 5 and 250 or where medicine storage temperature should be between -20F and 80F. - Permissions – Authentication and authorization
Apart from credential-based authentication, most MDM solutions come with role-based security where you can create as many roles as you want based on business domains. Typical roles will be Data steward, approvers, requesters, etc. for data management and Administrator, domain owner, repository owner, deployment, etc. for administration purpose. - User Interface (UI)
A user interface for MDM administrator to create and deploy domains, repositories, etc. and for data stewards to add or update data. - Web Services
Master data is not very useful if you do not make it accessible and web services are one of the better ways to access master data and administrative functions. - Data Publish
This is another way, other than Web Services, of making data available for consumption by various current and future consumers in bulk. The difference is that, compared to a pull-based web service approach, this is a push mechanism where MDM systems can publish modified data and interested parties can subscribe to channels. - Data Quality
Data Quality is a tool to profile, cleanse and masks data, while monitoring data quality over time regardless of format or size. By using data de-duplication, validation, standardization, and enrichment you create clean data for access. Data Quality System (DQS) is totally separate from MDM systems and can be used with and without MDM. Because data sources and data formats for MDM are increasing day-by-day, we will be exploring DQS as part of this MDM solution series.
MDM architecture
Here are the various components of typical MDM systems. Components can differ from vendor to vendor.
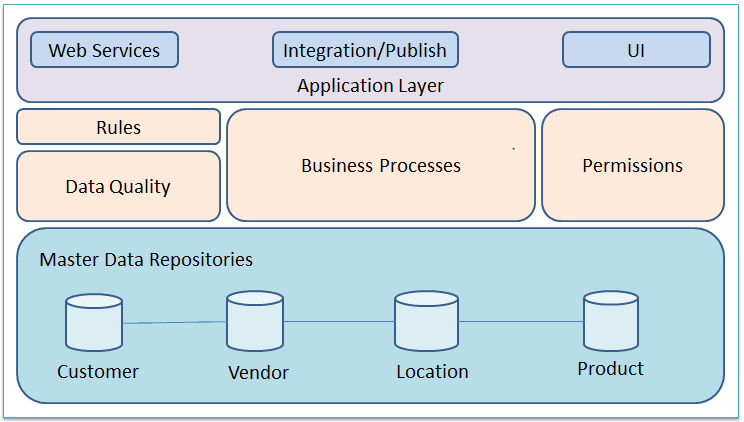
MDM in the context of SQL Server
Different vendors implement the MDM concepts that I’ve already explained. They use a range of different technologies such as java, .NET, database, etc. Microsoft implemented MDM concepts with a SQL Server approach using Master Data Services (MDS), Data Quality Service (DQS), and Integration Services (SSIS). Although MDS is a core service to implement MDM, both DQS and SSIS can supplement MDS if required. SQL Server 2008 R2 was the first release with MDS. This was drastically improved in 2012 and improvements have been continuing since then.
This image depicts an example where data is stored in various systems across the enterprise where data quality leaves a lot to be desired. Data is managed using MDS before making available for consumption.
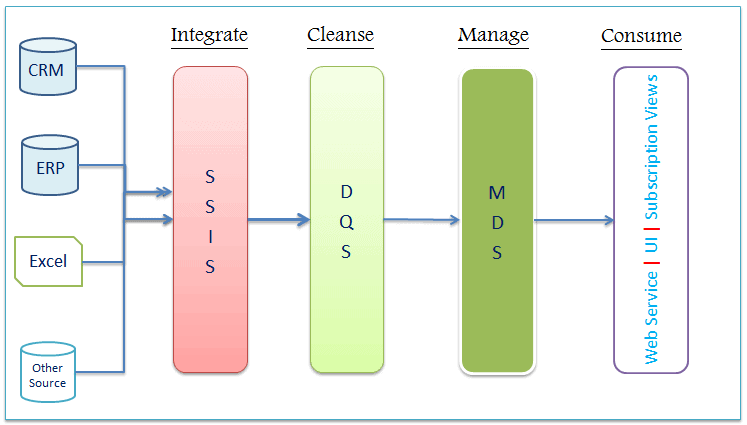
Master Data Services (MDS)
Master Data Services is a Microsoft product for developing MDM solutions, it is built on top of SQL Server database technology for back-end processing and provides service-oriented architecture endpoints using Windows Communication Foundation (WCF). You can implement hub architecture using MDS to create centralized and synchronized data sources to reduce data redundancies across systems.
MDS provides following tools and components to implement MDM solutions:
Configuration Manager
This is the starting point to configure Master Data Services and you can create and configure databases using Configuration Manager. This database comes with lots of stored procedures, database tables, and functions which collectively support back-end processing. You can also create a web application called ‘Master Data Manager’. You can associate the database and web application into a single MDM solution.
Master Data Manager
A web application used to perform administrative tasks such creating models, entities, business rules, hierarchies, users, and roles for authorized access. Users can access Master Data Manager to update data. You can also create versions, subscription views, and enable DQS and SSIS integration.
MDSModelDeploy.exe
The typical database lifecycle for any enterprise solution requires several server environments for such activities as development, testing and production. MDSModelDeploy.exe utility is a tool to use to create packages of your model objects and data so you can deploy them to other environments.
MDS Web Service
Service-Oriented Architecture (SOA) is a standard way to tackle an enterprise solution with disparate tools and technologies. MDS provides a web service, which can be used to extend MDS capabilities or develop custom solutions.
Add-in for Excel
Microsoft Excel is powerful tool: Business users understand it well as they use it quite often for day-to-day tasks. Master Data Services Add-in for Excel, allows business users to manage data while also allowing administrators to create new entities and attributes with ease. Most of the features available via Master Data Manager are also possible using the Excel plugin.
Data Quality Services (DQS)
Due to an exponential increase in data sources, it’s highly likely that the data from them is incomplete, inaccurate, duplicate, and possibly missing important business attributes as well. The reasons could be anything from user entry error, by way of corruption in transmission or storage to the use of different data standard by different sources.
Data Quality Services (DQS) provides a way to build a knowledge-base using various data points over time and then it can be used for data correction, enrichment, standardization, and de-duplication of data coming from various data sources. DQS maintains a knowledge base in various domains and each domain is specific for data fields. DQS also supports cloud-based reference data services to cleanse enterprise data using this external knowledge bases.
SQL Server Data Quality Service (DQS) provides following features:
- Knowledge base creation
- Data Cleansing
- Data Matching
- Data De-duplication
- Data Profiling
Conclusions
Over many years, organizations have been beset with problems that come from the fact that there is no overall organization-wide control and supervision of data and its progress through the various parts of the organization. The problems are made worse by the increasing ‘commoditization’ of organizational functions such as payroll, stock control, and accounting. This has inevitably let to a tendency toward data silos. On top of this, there is the trend towards Service-oriented architectures and micro-service architectures that require far greater coordination of data and a far better self-service data-broking system. To cap these pressures, the legislative overhead within which organizations must operate mean that audit must not only be possible but must be extremely efficient. By adopting Master Data Management, organizations can tackle these three major problems, and also provide way of managing data that is far more appropriate for the changing needs of organizations.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments