
This article discusses three common problems DBAs are likely to encounter when columns have the identity property, which is defined as an attribute of int, smallint, bigint, decimal, numeric or tinyint columns that will auto-increment their value when data is inserted. These problems are humorously referred to as the identity crisis.
Consider a table that looks like this:
|
1 |
CREATE TABLE test (PK INT NOT NULL IDENTITY(1,1) CONSTRAINT PrimaryKey PRIMARY KEY, CharCol CHAR(20)) |
To insert a row you do not have to specify a value for the PK, or identity, column like this:
|
1 |
INSERT INTO test (CharCol) VALUES ('test')GO |
The following query…
|
1 |
SELECT * FROM test |
…will yield:
|
1 2 |
PK CharCol-----------1 test (1 row(s) affected) |
You cannot supply a value for an identity column; trying to do so will result in an error as the following example illustrates:
|
1 |
INSERT INTO test (PK, Charcol) VALUES (1,'test')GOServer: Msg 544, Level 16, State 1, Line 1Cannot insert explicit value for identity column in table 'test' when IDENTITY_INSERT is set to OFF. |
If you need to assign a value to the identity column, you will have to use the SET option IDENTITY_INSERT as illustrated below:
|
1 2 3 4 5 |
SET IDENTITY_INSERT test ON GO INSERT INTO test (PK, CharCol) VALUES (2, 'test') GOSET IDENTITY_INSERT test OFF GO |
Columns with the identity property-or, as they are more familiarly known, identity columns-are most frequently used to ensure uniqueness, generally as a primary key. While GUIDs, also know as unique identifiers, can also be used to ensure uniqueness, they have their own set of problems.
When you create an identity column, you can specify a start value called a seed and an increment value called an increment. By default the identity seed and increment are 1. There are three caveats associated with identity columns:
You can use any real number as a seed or increment; positive and negative numbers are valid, but fractional, decimal or imaginary numbers are not.
- You cannot alter a column to add the identity property to it.
- You can only have one column per table with the identity property.
- You can assign the identity property to columns when creating them by using the Create and Alter table predicates.
Here are some examples of creating columns with the identity property.
|
1 2 |
CREATE TABLE test (pk INT NOT NULL IDENTITY) |
|
1 2 |
CREATE TABLE test1 (pk INT NOT NULL IDENTITY (1,1)) |
These two tables above are equivalent.
|
1 2 3 4 |
CREATE TABLE test2 (pk INT NOT NULL) ALTER TABLE test2 ADD Ident INT NOT NULL IDENTITY(-1,-1) |
DBAs face several problems when replicating columns that contain the identity property. Immediate updating subscribers do not have these replication difficulties as we will see shortly, but first let’s look at some common problems.
Triple threat: common problems
There are three problems-the identity crisis-you will likely face when replicating identity columns:
- A replication process inserts an identity value into a column with the identity property on it, and the insert fails.
- When both sides of a replication solution assign the same identity value on their side, and when the replication process carries the value to the other side, a conflict arises.
- Updates may fail even when you are not updating the identity column in transactional replication solutions.
The first problem above is illustrated in Script 1 in the code download. It occurs when you have bi-directional replication such as merge, bi-directional transactional, or one of the subscriber variants (transactional or snapshot) that can be updated using queued updating or immediate updating with queued failover. Note that immediate updating subscribers with queued failover will only be problematic when you have modified your subscription agents for queued failover.
The second problem, known as a primary key collision, is illustrated in Script 2 in the code download. In this example we will be using bi-directional transactional replication, but the results you see here are applicable to any replication method. When an insert is replicated, Script 2 will generate the error message:
|
1 2 |
Violation of PRIMARY KEY constraint 'primarykey'. Cannot insert duplicate key in object 'script2'. |
The third problem is typically caused when all of the columns in a row are updated by the application, including the identity column. To resolve the problem, edit your update replication stored procedure and comment the update of your identity column in the second part of the update procedure. An alternative is to use sp_scriptdynamicupdproc (only in SQL Server SP3) to create a “corrected” update proc.
The reason the updatable subscribers using immediate updating are immune to primary key collisions is because an insert on the subscriber is performed first on the publisher and then on the subscriber using a two-phase commit process coordinated by MS DTC.
So consider the case with transactional replication with immediate updating subscribers. In our hypothetical case you run DBCC CHECKIDENT(‘TableName’) in the publication database and get a value of 100. Then you run DBCC CHECKIDENT(‘TableName’) in your subscription database and get a value of 50. This means that there are 50 inserts that have occurred in the table TableName in the publication database that have not yet been replicated to the subscription database. Consider the case where TableName looks like this:
|
1 2 3 |
CREATE TABLE TableName (pk INT NOT NULL IDENTITY CONSTRAINT PrimaryKey PRIMARY KEY, Charcol CHAR(200)) |
If you were to insert a row in TableName on the subscription database like this…
|
1 |
INSERT INTO TableName (charcoal) VALUES ('test') |
…the insert would be performed on the publication database first and then be applied to the subscription database. Therefore, the newly inserted row on publication and subscription databases would have a value for the PK of 101. Script 3 in the code download illustrates this.
Not for replication
The first problem is easily fixed by adding the Not For Replication clause to the identity column. Script 4 in the code download illustrates how to implement this on pre-existing tables.
The Not For Replication clause will prevent the identity property from being enforced when a replication process performs the identity insert. In other words, replication processes will not generate this message when they try to replicate the identity value from the publisher to the subscriber or vice versa:
|
1 2 |
Cannot insert explicit value for identity column in table 'Table1' when IDENTITY_INSERT is set to OFF. |
The Not For Replication property can also be applied to triggers and constraints.
Avoiding primary key collisions
The problem of avoiding primary key collisions is more difficult to solve. Typically solutions to this second problem revolve around some form of partitioning or extending your primary key to include a location-specific element.
Partitioning
: Partitioning is where a column is identified that has location-specific data in it and your primary key is extended to include this column. In other words, there is something about the data in this column that enables you to tell at a glance from which server the row originated. Sometimes you will have to resort to extending your schema to include such a column.
In the example in Script 2, we could add another column with a default of db_name(), and then extend our primary key to include this column. This is enough to ensure uniqueness as Script 5 illustrates. In most real-world replication solutions, the default for this location identifier will not be the database name; ideally you will choose a numeric identifier (or small char column), since keeping your primary key as narrow as possible offers the best indexing performance, especially for clustered PKs.
Manual identity range management solutions
: Partitioning is the best approach to avoiding primary key collisions. There are times, however, when you simply don’t have the luxury of extending the schema to include an additional key, or even extending the PK to include another existing column, as it might break the application that overlies the schema. You could have the application talk to views and then modify the tables underlying the views to include these location identifier columns, or use indexed views to insulate your underlying schema. Another option is to use a GUID column instead of an identity column. Such solutions are frequently not scalable, however, and there are other issues with using a GUID column as well.
In situations like this you can use manual identity range management, in which you use different seeds on the publisher and subscribers. Immediate updating subscribers is often not an option either, as it requires a well-connected link between the publisher and subscriber, or transactions originating on the subscriber will fail and be rolled back if the publisher is off-line. Immediate updating also adds latency to transactions origination on the subscriber, which can make it an unacceptable solution.
For two nodes, you could use odd and even seeds as illustrated in Table 1.
|
Server |
Seed |
Increment |
|
Publisher |
1 |
2 |
|
Subscriber |
0 |
2 |
Table 1 – Identity configuration for a publisher with a single subscriber
Typical values for the publisher would be 1, 3, 5, 7 and so on. Typical values for the subscriber would be 0, 2, 4, etc.
For three nodes you could use an increment of three as illustrated in Table 2. This configuration was first suggested by Kestutis Adomavicius (kicker.lt@nospaamm_tut.by).
|
Server |
Seed |
Increment |
|
Publisher |
1 |
3 |
|
Subscriber1 |
2 |
3 |
|
Subscriber 2 |
3 |
3 |
Table 2 – Identity configuration for a publisher with two subscribers
Typical values for the publisher would be 1, 4, 7, 10, etc. Typical values for the first subscriber would be 2, 5, 8, 11 and so on, and typical values for the second subscriber would be 3, 6, 9, 12, etc.
For four nodes you could use a combination of odd, even, positive and negative seeds and increments as Table 3 illustrates.
|
Server |
Seed |
Increment |
|
Publisher |
0 |
2 |
|
Subscriber1 |
1 |
2 |
|
Subscriber2 |
-1 |
-2 |
|
Subscriber3 |
-2 |
-2 |
Table 3 – Identity configuration for a publisher with three subscribers
As you can see, the more subscribers you have the more difficult it gets to develop a scheme to segregate your identity values. Another problem is that once you have implemented such a solution it becomes very difficult to modify it to add new subscribers. There are also inefficiencies with identity range consumption, since the bulk of inserts may occur at publisher or on one subscriber, and you may find that this node exhausts the data type before the other nodes. This is not generally problematic with the int data type, but it can be problematic with smallint.
Another approach is to manually adjust the identity ranges on the publisher or subscriber(s) on an as-needed basis.
Consider a publisher with three subscribers. On the publisher you could create an identity seed of 1 and an increment of 1. Let replication deploy the snapshots to the subscribers, and then before any database activity occurs on the publisher, change the seeds on each subscriber by using DBCC CHECKIDENT. Table 4 illustrates what this would look like.
|
Server |
Original Seed |
Original Incr |
DBCC |
New Seed |
New Incr |
|
Publisher |
1 |
1 |
1 |
1 |
|
|
Subscriber1 |
1 |
1 |
DBCC CHECKIDENT(‘TableName’,RESEED,100) |
100 |
1 |
|
Subscriber2 |
1 |
1 |
DBCC CHECKIDENT(‘TableName’,RESEED,200) |
200 |
1 |
|
Subscriber3 |
1 |
1 |
DBCC CHECKIDENT(‘TableName’,RESEED,300) |
300 |
1 |
Table 4 – Using DBCC CHECKIDENT to implement a manual identity range management solution
Suppose that in your first week the majority of the new rows originate on the publisher, and you run SELECT IDENT_CURRENT(‘TableName’) and discover to your horror that this returns a value of 99. You quickly run DBCC CHECKIDENT(‘TableName’, RESEED, 400) and you are fine until more than 100 rows are inserted at Subscriber1, Subscriber2 or Subscriber3.
The 100th row entered in Subscriber1 will have an identity value of 200, which will cause a PK violation with rows inserted on Subscriber2; the 100th row entered on Subscriber2 will cause a PK violation with rows inserted on Subscriber3; and the 100th row entered on Subscriber3 will cause a PK violation with the new rows entered on the publisher.
If you did choose to implement such a scheme, you would have to set an alerting threshold of perhaps 80 percent full range that would give you time to run over to the publisher or subscriber and run your DBCC CHECKIDENT reseed command. You would also want to size your reseed range for something that represents your largest batch update.
Consider the example illustrated in Table 4. Suppose the application that uses Subscriber1 generated 10,000 inserts; these inserts would have PKs from 100 to 10,100. When Subscriber1 syncs with the publisher, it is entirely possible that there will be a series of PK collisions with data originating from Subscriber2 and Subscriber3. The result will be that some of the inserts are rolled back depending on who syncs last.
With merge replication, if the publisher generates a PK value first, the publisher’s row will stay; later subscribers merging with the same PK value for their row will have their insert replaced by the publisher’s insert for that PK value. If a subscriber generates the PK value first and the row with this PK value is merged to the publisher, all other subscribers merging with the same PK value will have the row with that PK value replaced with the row for the PK value from the first merged subscriber. These PK violations will be recorded in the conflict tables and you may have the ability to roll them back.
You might, therefore, want to take preventive action by sizing your ranges (the value you put in for your RESEED) to a value that represents the largest set of inserts you might ever have between syncs of a single subscriber and the publisher. You might also want to put in a check constraint that will prevent any of the ranges from colliding with other ranges. So consider Subscriber1. We might want to put a check constraint that would limit that maximum value that the identity value could have so that inserts on Subscriber1 would not overrun Subscriber2’s range.
Let’s have a quick look at what this check constraint would look like for Subscriber1:
|
1 2 |
ALTER TABLE TableName ADD CHECK NOT FOR REPLICATION ([PK] > 100 and [PK] < 200) |
Notice how I have the Not For Replication clause on here, which means that this check constraint will not be enforced by any replication process.
There is one caveat for using a constraint like this. The check constraint will cause the insert to be rolled back, but the identity value will be incremented with each failed insert.
Script 6 in the code download illustrates this. Note how in Script 6 our check constraint is for 101 to 199. We attempted to insert 300 rows; the first 100 are kicked back by the check constraint, the next 99 make it in, and the final 101 are kicked back by the check constraint. Our current identity value would be 300. If instead we attempted to insert 500 rows instead of 300 in Script 6, our identity value would end up as 500.
Now suppose that we changed our constraint so that it is 400 to 500, which is the next free range. Any inserts on this table would fail since the current identity value would be 500. This would continue until we reseeded our identity value back to 401. Table 1.1 illustrates this. This is an important point to note as DBAs are frequently bewildered when they encounter this problem in SQL Server 2000 automatic identity range management.
|
Row |
Successfully |
Select @@IDENTITY |
Select max(PK) from TableName |
|
1 |
No, check constraint refuses it |
1 |
0 |
|
2 |
No, check constraint refuses it |
2 |
0 |
|
3 |
No, check constraint refuses it |
3 |
0 |
|
. |
0 |
||
|
. |
0 |
||
|
. |
0 |
||
|
99 |
No, check constraint refuses it |
99 |
0 |
|
100 |
No, check constraint refuses it |
100 |
0 |
|
101 |
Yes! |
101 |
101 |
|
102 |
Yes! |
102 |
102 |
|
. |
|||
|
. |
|||
|
. |
|||
|
198 |
Yes! |
198 |
198 |
|
199 |
Yes! |
199 |
199 |
|
200 |
No, check constraint refuses it |
200 |
199 |
|
201 |
No, check constraint refuses it |
201 |
199 |
Table 1.1
If you choose to implement a manual identity range management solution, you will need a tracking table on your publisher to know what ranges are currently in use by all subscribers so the new ranges you assign will not tread on any other subscribers. All you need to know is the last assigned identity range. You can use this max value as a basis for assigning the next range.
This manual identity range management solution is actually an implementation of how Microsoft does automatic identity range management, which is the third method for avoiding primary key collisions.
SQL Server 2000 automatic identity range management: A better solution for avoiding primary key collisions is to use Microsoft’s automatic identity range management feature, which incorporates the methodology discussed above in the manual identity range management section. To use this feature you must click on the browse button to the right of your table in the specify article dialog when you are creating your merge publication. This is illustrated in Figure 1.
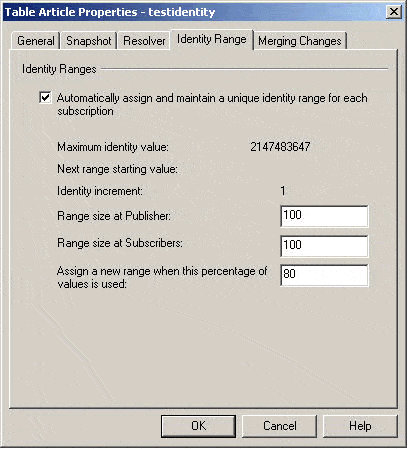
Figure 1
Note that if the identity range management tab is disabled, chances are the table to which you are trying to add automatic identity range management is already part of an existing merge publication that does not use automatic identity range management. You will have to drop this table from the existing merge publication(s), enable it for automatic identity range management, and then add it back.
Notice the options for range size at the publisher and subscriber as well as the threshold. These options are symmetrical with what was discussed earlier in the section on manual identity range management.
Many DBAs will assign a range size for the publisher and subscriber for what they anticipate will be the life of their replication solution. DBAs might be tempted to assign a value of 100,000,000 or more, for example, for both the range size at publisher and range size at subscribers. The problem with this set-it-and-forget-it approach is that it is not scalable-there is not a lot of room for growth because with 100,000,000 there is room for only two subscribers. You may find that if the number of subscribers grows and there are a lot of inserts in one node, you may exhaust your range quickly and have plenty of room left over in ranges at other nodes.
A better approach is to size your ranges for the largest number of inserts that could occur when a subscriber or publisher is off-line (and then multiply by 10 or another safety factor).
If you don’t size these ranges adequately, or if you don’t run your merge agent frequently enough, you will run into the infamous error message:
|
1 2 3 4 5 6 7 |
Server: Msg 548, Level 16, State 2, Line 1 The identity range managed by replication is full and must be updated by a replication agent. The INSERT conflict occurred in database 'pubs', table 'testidentity', column 'pk'. sp_adjustpublisheridentityrange can be called to get a new identity range. The statement has been terminated. |
If you do get this message, run DBCC CHECKIDENT(‘tablename’,RESEED,100) to set your identity back to one more than the value of the identity that was inserted. In other words, do a select max(IdentityCol) from TableName. Then run sp_adjustpublisheridentityrange in the publication database. Sometimes rerunning the merge agent will solve the problem.
If you encounter this problem frequently, you may want to run your merge agent more often. If this is not possible, rebuild your publication to adjust your ranges to higher values.
Summary
In this article we looked at ways to implement identity management solutions in replication to avoid primary key conflicts. We looked at partitioning and manual and automatic identity range management solutions. Solutions using automatic identity range management can work well with careful planning.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments