
- “My sys admin says that SAN backups make dedicated database or log backups obsolete. Is he right?”
- “Our DBA only allows full database backups. He says taking log backups during the day will cause too much overhead on the server. Is he right?”
- “I take regular log backups, but the log has still grown to a massive size and DBCC SHRINKFILE is having no effect at all! Why? And what can I do about it?!”
- “I run the database in auto-truncate mode, and yet the log has still grown massively. What is going on?”
- “A database’s log grew so large that I had to delete it, but on restarting SQL Server the database was in RECOVERY_PENDING mode and inaccessible! What’s gone wrong? Surely it’s possible to attach a database with just the MDF file?”
- “I’ve heard conflicting advice about whether log auto-growth should be enabled. Yes or no?”
- “I checked DBCC LOGINFO; and found out my log had 2000 VLFs. Is it something to worry about?”
- “If all operations are logged, what happens during non-logged operations such as truncate?”
- “A busy OLTP database is experiencing blocking, and we’re seeing high WRITELOG waits. How can we avoid or at least reduce the logging overhead?”
- “How can I figure out from the log when a data change happened to a table and who did it?”
“My sys admin says that SAN backups make dedicated database or log backups obsolete. Is he right?”
It’s true that many modern SAN-based disaster recovery solutions offer ‘transaction-aware’ database backups. However, as a DBA, I would analyze carefully the Service Level Agreements for all databases in your care, their disaster recovery requirements and maximum tolerable exposure to data loss, and then perform careful test restores with the SAN backups to ensure you can meet all these requirements.
Native SQL Server database backups capture the current state of the database at a specific point in time, plus enough of the transaction log to ensure that, upon restoring the backup, SQL Server can run the recovery process, which guarantees that the database is transactionally-consistent at that specific point in time. Make sure that the SAN Backup offers a similar guarantee; it may render the database ‘quiescent’ temporarily, essentially freezing all I/O prior to taking the backup, in order to achieve this.
Even if the SAN backups do appear to offer transactional support, don’t assume this makes SQL Server database and log backups redundant. If you need to support point-in-time restore operations, either to ensure minimal data loss in the event of a disaster, or to support strategic recovery objectives, such as restoring a table after someone accidentally truncates it, then you will need to take database and log backups.
The transaction log contains a record of every action performed by every transaction on that database, and the precise order in which each action occurred, with every log record identified by a unique, ever-increasing Log Sequence Number (LSN). It contains all the information SQL Server needs to reproduce the effects of one or more transactions, rolling the database forward in time, or to undo their effects (rollback) to return the database to a consistent previous state. It is only by capturing in log backups an unbroken sequence of LSNs, since the last full backup, that you can support point-in-time restores.
Log backups also enable a variety of other types of restore operation, such as restoring just a subset of a database, such as an individual file or filegroup, rather than the entire database.
“Our DBA only allows full database backups. He says taking log backups during the day will cause too much overhead on the server. Is he right?”
Firstly, log backups do not affect the running of user operations; they are not ‘blocked’ while log backups are in progress. Secondly, transaction log backups on SQL Server are highly efficient, and will have minimal overhead on the server, even on high-traffic OLTP databases.
If a database experiences a very high rate of database modifications, or you’ve recently run a large batch insert or update, then certain log backups may be relatively large, and come with a more appreciable CPU cost. If your Server is CPU-bound then it’s possible that these log backups could have an additional impact on the performance of concurrent business operations. This problem might be exacerbated if you have a rapidly growing and highly fragmented log, because log backups may take substantially longer due to the time required to load and read a very high number of virtual log files (see questions 6 and 7 for more on log growth and fragmentation).
Nevertheless, except in very rare cases, the impact should still be minimal due to log backup efficiency. Of course, this doesn’t mean that it’s wrong, necessarily, to rely only on full database backups. It depends on the extent of possible data loss that is tolerable for those database. If the DBA takes only one full database backup per day for a database, say at 1AM, then we can only ever recover the database to that time, in the event of a system failure, such as a serious hardware failure. This means that the database is exposed to potential data loss of up to 24 hours. If that’s acceptable according to the SLA, then it’s perfectly OK to operate the database in SIMPLE recovery model and rely solely on full backups for restore operations. However, if acceptable data loss is minutes, not hours, then the DBA should operate the database in FULL recovery model, capturing log backups at appropriate intervals.
What’s certain however is that resource overhead is not a valid reason for avoiding log backups.
“I take regular log backups, but the log has still grown to a massive size and DBCC SHRINKFILE is having no effect at all! Why? And what can I do about it?!”
In short, something other than a log backup is preventing SQL Server from making available reusable log space, during log truncation, meaning that the log has to grow to accommodate new log records. The solution is to find out what process, although there might be more than one, is holding your log space hostage.
When operating a database in FULL or BULKLOGGED recovery model, all log records must remain in the log, as part of the active log, until they have been captured in a log backup. Otherwise, the log backups could not guarantee to capture the complete, unbroken chain of LSNs that are required for database restore and recovery.
In these recovery models, only a log backup will cause SQL Server to run the “log clearing” process, also referred to as log truncation. During log truncation, SQL Server will mark as inactive any VLFs that contain no part of the active log, i.e. VLFs that contain no log records that SQL Server still requires for recovery, or for log backup, or for any other process.
SQL Server will run log truncation after every log backup and, each time, any inactive VLFs that result will be available for reuse to store new log records, overwriting the existing log records that are no longer required. Therefore, when SQL Server reaches the end of the log, i.e. the end of VLF4 in Figure 1, it will circle round and start overwriting with new log records any existing log records in inactive VLFs.
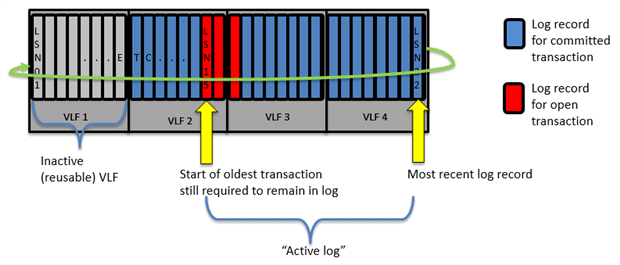
Figure 1
However, it’s possible that there will be periods where successive log truncations produce zero inactive VLFS, because there are other factors that can prevent SQL Server reusing space in the log. If there are no inactive VLFs available, then SQL Server has no other choice but to grow the log, adding more VLFs.
This is likely what is happening in this case; some other process is forcing SQL Server to retain log records in the active log, and so successive executions of the log truncation process aren’t producing any more inactive VLFs. Attempts to shrink the log will have no effect in this situation as there is no free space to remove! DBCCSHRINKFILE can only physically remove unused or inactive VLFs that are at the end of the log file.
You need to find out what is delaying log space reuse. In Figure 1, the problem is an active transaction. All log records relating to an uncommitted transaction must remain in the log, since SQL Server still might need to use those log records to roll back the transaction, if required. Until it commits, the start or ‘head’ of the active log is “pinned” at LSN 15 and when SQL Server reaches the end of VLF 1, it will have to grow the log. Other factors, such as log records that have not yet been replication to the secondary server, can have exactly the same effect. Gail Shaw’s article, Why is my transaction log full, provides good coverage of all the reasons that can prevent SQL Server reusing space in the log.
The trick is to interrogate sys.databases and finds out what value is stored in the log_reuse_wait_desc field, and then troubleshoot appropriately. There may be more than one process that is preventing log reuse, so you’ll need to troubleshoot and there run the query again, until it reports NOTHING.
|
1 2 3 4 5 |
-- reports what prevented SQL Server truncating any VLFs the last time it -- attempted log clearing SELECT log_reuse_wait_desc FROM sys.databases WHERE name = 'MyDB'; |
Listing 1
Having identified the cause, or causes, you can use DBCCOPENTRAN to find details of the oldest uncommitted or un-replicated transaction, or use the sys.dm_tran_database_transactions DMV to find all active transactions, and a lot more information besides.
“I run the database in auto-truncate mode, and yet the log has still grown massively. What is going on?”
People call SIMPLE recovery model auto-truncate mode because SQL Server runs the log truncation process every time a database CHECKPOINT operation occurs, but this does not means that you’ll never have problems with rapid log growth, if a database in operating in SIMPLE recovery model.
A CHECKPOINT first flushes the log buffer to disk and then flushes to disk any data that has changed since it was read into memory from disk. With all data modifications safely on disk, SQL Server will mark any now-inactive VLFs as available for reuse. However, again, log truncation is the process of marking zero or more VLFs as inactive; there is no guarantee that SQL Server will always be able to create reusable log space every time the CHECKPOINT runs.
There are many factors that can “pin” the head of the log and prevent SQL Server reusing log space. Log backup is no longer one of these factors because we can’t take log backups in SIMPLE recovery model. However, almost all the other factors that can prevent SQL Server reusing space in the log are still valid in SIMPLE recovery model. SQL Server still needs to preserve in the log any uncommitted records, in case it needs to roll them back. It still needs to preserve log records that other processes still require, such as the recovery process, or transactional replication or change data capture, all of which are perfectly valid for SIMPLE recovery model databases. As for the previous question, check the values in log_reuse_wait_desc (listing 1); find out what is delaying truncation.
On a related note, you may hear advice that you can ‘force’ log truncation by switching a FULL recovery model database to SIMPLE and then back to FULL, and restarting the chain with a full database backup. This will only work if the lack of a log backup was the cause of problem, and in any event is probably not the best way to handle this problem.
“A database’s log grew so large that I had to delete it, but on restarting SQL Server the database was in RECOVERY_PENDING mode and inaccessible! What’s gone wrong? Surely it’s possible to attach a database with just the MDF file?”
It is possible to attach a database with just the MDF file but only if that database was previously taken offline with a completely clean shutdown; see the “SHUTDOWN (Transact-SQL)” topic on MSDN.
If there was a clean shut down, SQL Server marks it in database boot page, and so knows that it does not need to run recovery, during restart, and therefore does not need the original transaction log. In such cases, we can attach the database without the log, and SQL Server will simply create a new log.
However, if there is no mark indicating a clean shutdown, and this is never guaranteed, then SQL Server must run recovery during restart, which it can’t do without the original log, and which is the reason why you’ve ended up with a RECOVERY_PENDING database. It simply means there wasn’t a clean shutdown and SQL Server can’t start the recovery process because you whacked the log.
The recovery process uses the contents of the log to re-establish transactional consistency. During recovery SQL Server will redo the effects of any transaction that was not included in the last CHECKPOINT to run before the database went offline, and undo the effects of any uncommitted transaction that was included in the last CHECKPOINT.
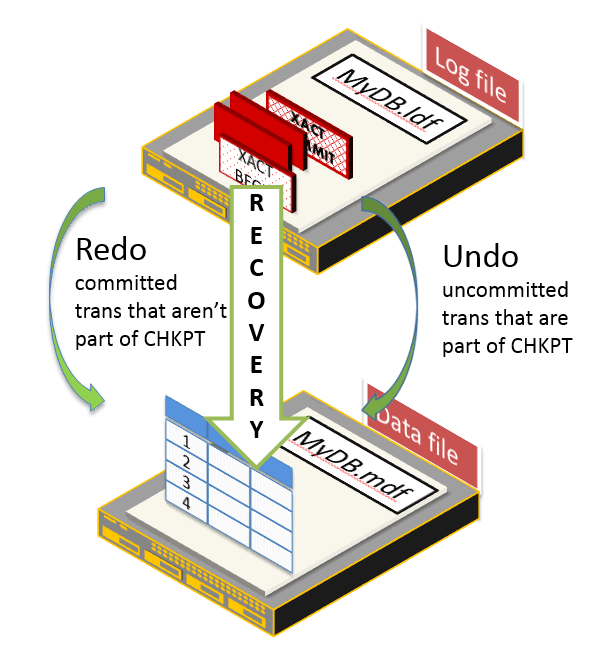
Figure 2
If SQL Server can’t run recovery, it can’t guarantee a consistent database, and so won’t bring it online. In such cases, CREATE DATABASE...FOR ATTACH_REBUILD_LOG (or similar) will fail. The correct solution is to restore from backup. If you can’t for some reason, the only way to get SQL Server to bring a database online without running recovery is to “hack attach” the database, if necessary and then run DBCC CHECKDB REPAIR_ALLOW_DATA_LOSS.
Remember though that the ‘repaired’ database may be missing some committed transactions and, worse, may show the partial effects of uncommitted transactions, or may not even be repairable at all. The extent of the damage depends on what transactions were running at the point SQL Server shut down, and what they were doing. It can range from logical inconsistency, if SQL Server isn’t able to recover in-flight user transactions that were modifying only user data, to physical database corruption, if it can’t recover in-flight system transactions that were, for example, updating index structures during a page split.
“I’ve heard conflicting advice about whether log auto-growth should be enabled. Yes or no?”
If there is no more space in a database’s log file, and it can’t grow, either because there is no more disk space, or because you disabled log auto-growth, then that database will become read-only, and you’ll see 9002 errors. SQL Server must write log records describing a database modification before it writes the actual change to the data or object. This is write-ahead logging. If SQL Server can’t write log records, it can’t write, full stop.
For this reason alone, I’d recommend leaving log auto-growth enabled. However, I do not recommend a log growth strategy that consists of guessing a suitable initial log size and then letting log auto-growth “take over from there”.
Each log growth event adds considerable CPU overhead, since there is no instant file initialization for log files. If you allow the log to auto-grow frequently, in small increments, that’s a lot of unnecessary CPU overhead and the performance of other processes can be affected, during these growth events. It could also lead to log fragmentation (see the next question).
Instead, try to make an accurate estimate as you can for the required transaction log size for each database. Leave auto-growth enabled, with a sensible growth increment, but monitor and set an alert for log growth events. If your size calculations were accurate, the log shouldn’t need to grow, and therefore detecting a growth event indicates that the log grew much faster than expected, and is a cause for investigation.
“I checked DBCC LOGINFO; and found out my log had 2000 VLFs. Is it something to worry about?”
It could be a problem, yes. Generally, it depends on the overall size of the log. It’s common, and not really an issue, to see a very large transaction log with several hundred VLFs, but several thousand is a concern regardless of overall log size.
Internally SQL Server breaks down a transaction log file into a number of sub-files called virtual log files (VLFs). SQL Server determines the number and size of VLFs to allocate to a log file, upon creation, and then will add a predetermined number of VLFs each time the log grows, based on the size of the auto-growth increment. For SQL Server 2012 and earlier, the formula is as follows (though, for very small growth increments, it will sometimes add fewer than four VLFs):
- <64 MB – each auto-growth event will create 4 new VLFs.
- 64MB to 1 GB = 8 VLFs.
- >1 GB = 16 VLFs.
For example, if we create a 64 MB log file and set it to auto-grow in 16 MB increments, then the log file will initially have 8 VLFs, each 8 MB in size, and SQL Server will add 4 VLFs, each 4 MB in size, every time the log grows. If the database attracts many more users than anticipated, but the file settings are left untouched, by the time the log reaches 10 GB in size, it will have grown about 640 times, and will have over 2,500 VLFs.
This is a big enough issue that in SQL Server 2012 and later, you’ll see an error message reported at startup, in the error log, if SQL Server detects a database has what it considers too many VLFs, and it’s also why SQL Server 2014 uses a different VLF creation algorithm to try to alleviate the problem.
If you have a very fragmented log then during a maintenance window, you can use DBCC SHRINKFILE to shrink the log to a small target size (after taking a log backup, of course). This will remove the fragmentation. You should then immediately grow it, manually, to a sensible size, and in sensible growth increments.
Don’t go the other way and make each VLF very large, as you will risk tying up large portions of the log that SQL Server cannot truncate, and if some factor further delays truncation, meaning the log has to grow, the growth will be rapid.
A general recommendation is that VLFs should be no larger than about 500 MB, although the figure can vary depending on the overall size of the log.
“If all operations are logged, what happens during non-logged operations such as truncate?”
The TRUNCATE command is not a non-logged operation. In fact, it is fully logged. With very few exceptions, namely one or two operations in tempdb such as operations on the version store, there is no such thing as a non-logged operation in SQL Server. Operations such as TRUNCATE TABLE and DROP TABLE are fully logged, but SQL Server uses an efficient, deferred de-allocation mechanism that means the commands seem to be instantaneous, regardless of the size of the table. This fact, coupled with some misleading terminology, including in several Microsoft articles, lead to the mistaken belief that these operations are not logged at all.
As an example, we can compare the logging behavior of TRUNCATE with that for a command such as DELETE. Both commands are fully logged, meaning that SQL Server has in the log all the information it needs to support rollback and recovery, but what gets logged is rather different in each case.
The database LoggingExample, which is operating in the FULL recovery model hosts a table called ATable, into which we’ll insert 5000 rows (the full code to create the database and table is provided in the code download).
|
1 2 3 4 5 6 7 8 9 10 |
SELECT TOP ( 5000 ) REPLICATE('a', 2000) AS SomeCol INTO dbo.ATable FROM msdb.sys.columns a CROSS JOIN msdb.sys.columns b; SELECT COUNT(*) AS N'NumLogRecords' FROM fn_dblog(NULL, NULL); GO --3389 rows |
Listing 2
Immediately after running Listing 2, we use an undocumented and unsupported function called fn_dblog to interrogate the contents of the log file for LoggingExample, in this case simply returning a count the current number of log records (the number you see may vary).
Now, let’s empty the table using DELETE and recount the number of log records.
|
1 2 3 4 5 6 7 8 9 |
CHECKPOINT; GO DELETE FROM [ATable]; GO SELECT COUNT(*) AS N'NumLogRecords' FROM fn_dblog(NULL, NULL); GO --12346 rows |
Listing 3
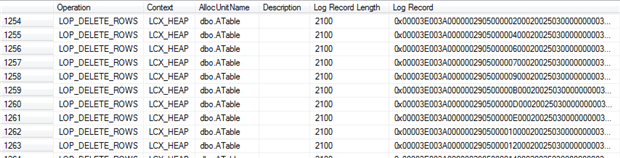
We can see that the operation generated over 8000 log records. Listing 4 shows us that among these are 5000 log records of type LOP_DELETE_ROWS; one for each individual row deleted.
|
1 2 3 4 5 6 7 8 9 |
SELECT Operation , Context , AllocUnitName , Description , [Log Record Length] , [Log Record] FROM fn_dblog(NULL, NULL) WHERE AllocUnitName = 'dbo.ATable' AND Context = 'LCX_HEAP' |
Listing 4
Notice that the context in each case is LCX_HEAP, so these are the data pages. If you copy into a text editor the contents of the Log Record column, for one of these rows, you’ll many bytes containing the hex value 0x61. This translates to decimal 97, which is the ASCII value for ‘a’ (repeated 2000 times, in this case), proving that we have a log record for the deletion of every individual data row.
Now, we’ll repeat the same example (again, the full code is available in the download), but this time we’ll TRUNCATE the table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT COUNT(*) AS N'NumLogRecords' FROM fn_dblog(NULL, NULL); GO --3389 rows CHECKPOINT; GO TRUNCATE TABLE [aTable]; GO SELECT COUNT(*) AS N'NumLogRecords' FROM fn_dblog(NULL, NULL); GO --3563 rows |
Listing 5
The TRUNCATE command will complete instantaneously, and the log record count immediately afterwards shows that SQL Server has generated only around 200 new log records, despite removing 5000 data rows. Wait a few seconds and run the log record count again, and you’ll see more records have been generated, although still not enough to account for individual logging of the delete of each row.
There are two factors at work here, which explain this behavior. Firstly, SQL Server performs a ‘deferred de-allocation’ mechanism whereby, initially it simply ‘unhooks’ the allocation chain for the table. This generates the initial few log records, and then a background thread actually de-allocates the extents, and generates all the log records required to fully log the de-allocations. This is why TRUNCATE and DROP commands complete immediately regardless of the number of rows being removed.
Secondly, SQL Server generates relatively few log records for the operation, in total, because it logs only the extent de-allocations, not the actual data pages. If we rerun Listing 4, we’ll see that the TRUNCATE did not generate any new log records within the context LCX_HEAP. Run Listing 4 without the WHERE clause and what you will see instead is that the log records for the changes made to SomeTable appear in the context of Global Allocation Maps (GAMs) and Index Allocation Maps (IAMs), tracking extent allocation, plus some PFS pages.
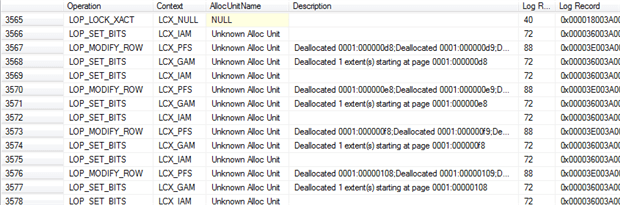
Figure 3
So, SQL Server is logging the extent de-allocations (and any changes to the metadata, i.e. system tables, which we don’t show in Figure 3), but the data pages themselves are not there. There is no reference in the log as to what data is on the allocated pages. We do not see here the 0x61 pattern that we saw earlier, and most of the log records are less than 100 bytes in size.
Nevertheless, there operations are still fully logged and require all the information SQL Server needs to support rollback and recovery. The logging behavior for these operations is the same regardless of recovery model.
“A busy OLTP database is experiencing blocking, and we’re seeing high WRITELOG waits. How can we avoid or at least reduce the logging overhead?”
You can’t avoid logging. However, it may be possible to minimize logging for certain bulk operations, assuming that is acceptable given the implications for database restore operations. Beyond that, the correct physical hardware and architecture will help ensure that you get the best possible log throughput, and good old-fashioned query and index tuning can also help reduce unnecessary logging.
It’s a mistake to imagine you can somehow stop SQL Server from logging database modifications. With very few exceptions, SQL Server logs all modifications of every database object, logging not only a description of how the data changed, but also each necessary ‘internal’ structural modification required to make the change, such as allocating a new page, or modifying the structure of a b-tree index. In short, SQL Server has to have in the transaction log alone all the information it needs to reproduce the effects or one or more transactions (replay or redo), or undo their effects (rollback), should it need to do so in order to return the database to a consistent state.
However, certain operation, including bulk import operations, SELECTINTO, and some index operations can be minimally logged, if the database is operating in BULKLOGGED or SIMPLE recovery model. As an example, let’s consider the logging behavior for an operation such as INSERTINTO. In FULL recovery model, SQL Server logs for this command the extent allocations and the page images, as the pages are filled, and so has in the log all the information it needs to perform rollback, as well as supporting roll forward and recovery to an arbitrary point in time.
By contrast, in BULK_LOGGED or SIMPLE recovery model, SQL Server logs only allocations of the relevant extents, but not the actual content of those extents (i.e. data pages). By temporarily switching a database from FULL to BULKLOGGED recovery model in order to run bulk operations such as SELECT INTO, or when rebuilding large indexes, we can reduce dramatically the amount of information SQL Server needs to write to the log, and also improve the performance of these operations.
Other considerations for minimal logging
Switching a database out of FULL recovery model, however briefly, requires careful consideration. There are ‘side-effects’ to consider, one of which is that it’s not possible to preform point-in-time restore operations within any log backup that contains minimally logged operations. For more details, see Chapter 6 of SQL Server Transaction log Management (a free eBook).
Beyond that, the best strategy is to take what steps you can to optimize your IO architecture for high log throughput and low latency, and your queries and indexes to eradicate any unnecessary logging.
Kimberly Tripp summarizes some of the “golden rules” for log architecture in her blog post 8 Steps to better Transaction Log throughput. For the IO subsystem, each database should have a single log file on a dedicated drive/array that is optimized for sequential writes. Many regard a RAID 1+0 array as the best option when using conventional disks, though it is also the most expensive in terms of cost per GB of storage space. However, in many systems, conventional drives for log files are being replaced by a mirrored pair of Solid State Drives.
To make sure that SQL Server isn’t having to perform more logging than is strictly necessary (regardless of recovery model), ensure, for example, that you don’t have a surfeit of unused indexes on the database and making sure the indexes aren’t getting excessively fragmented (page splits, and so on, all generate log records).
Finally, if you’re using SQL Server 2014, then for certain workloads you’re likely to see a big boost in log throughput by enabling delayed durability. SQL Server performs all data operations in memory, and initially also writes the log records to the log buffer, in memory. SQL Server will always writes the change description, i.e. the log record, before making the actual change to the data, or internal data structure. This is called write ahead logging. When a transaction issues a COMMIT then, generally, SQL Server will flush the current log buffer to disk, therefore ensuring it has all the information it needs in the log for redo or undo, and only then acknowledge the commit. With delayed durability enabled for a transaction, SQL Server does not need to flush the log buffer to disk on commit. This can reduce the overhead associated with log writes and greatly increase transaction throughput on the system. Of course, the obvious tradeoff is that the database is exposed to potential data loss. When running recovery, after a instance failure, SQL Server can’t replay the effects of any log records relating to committed transaction if they hadn’t yet been flushed to disk, so the effects of those transactions will be lost.
“How can I figure out from the log when a data change happened to a table and who did it?”
As noted above, SQL Server writes all modifications to the transaction log, so in some respects the transaction log might seem an obvious please to look to find out what modifications occurred and when and who made them. In reality, you will hopefully have easier ways to find this information, via one of SQL Server’s available “auditing” options, such as change data capture, or SQL Audit, or using the Object events in the Default trace.
If none of these options are open to you, then you can do a certain amount of internal log investigation using the previously-referenced fn_dblog function, or fn_dump_dblog for looking inside log backups. In some cases, finding what you need can be disarmingly simple, but be forewarned that these functions are unsupported and undocumented and internal log analysis can be tricky. The best source of information I’ve found on this topic is Remus Rusanu’s article, How to read and interpret the SQL Server log. The listings below are adapted from this article.
Within our LoggingExample database, we can use the query shown in Listing 6.
|
1 2 3 4 5 6 7 8 9 |
SELECT [Current LSN] , [Operation] , [Transaction ID] , [Parent Transaction ID] , [Begin Time] , [Transaction Name] , [Transaction SID] FROM fn_dblog(NULL, NULL) WHERE [Operation] = 'LOP_BEGIN_XACT' |
Listing 6
In the output we can see the exact time that the TRUNCATE TABLE transaction started.

Figure 4
The Transaction SID column shows the SID of the login that started the transaction, and we can use SELECT SUSER_SNAME ([Transaction S ID]) to reveal the actual login name of the user that issued the command.
We can also drill deeper into the details of a single transaction, by supplying the transaction id retrieved from Listing 6.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT [Current LSN] , [Operation] , [AllocUnitName] , [Page ID] , [Slot ID] , [Lock Information] , [Num Elements] , [RowLog Contents 0] , [RowLog Contents 1] , [RowLog Contents 2] FROM fn_dblog(NULL, NULL) WHERE [Transaction ID] = '0000:00000325' |
Listing 7
The output is tricky to interpret unless you really know what you are doing.

Figure 5
We know that for TRUNCATE, SQL Serve logs no actual data rows, only the extent de-allocations, hence the AllocUnitName entries reference only system objects. In other cases, this will reveal the identity of the affected object.
Sometimes, AllocUnitName may be NULL, but the lock information column can provide details about the affected tables. The HoBt (Heap or B-Tree) IDs in this column are partition ids for the locked object and we can convert them to reveal the actual object name, as shown in Listing 8.
|
1 2 3 4 5 6 |
SELECT OBJECT_NAME(i.object_id) , i.name FROM sys.partitions AS p INNER JOIN sys.indexes AS i ON i.object_id = p.object_id AND i.index_id = p.index_id WHERE p.partition_id = 72057594040549376 |
Listing 8
Load comments