
A data dictionary is a structured repository that documents your database’s tables, columns, data types, relationships, and business context – metadata that system views alone can’t capture. You can build one in SQL Server using T-SQL queries against INFORMATION_SCHEMA views and sys.* catalog views, enriched with custom metadata tables for business descriptions, data owners, and change history. The payoff is significant: faster onboarding, better code quality, easier auditing, and automated documentation that maintains itself as your schema evolves.
In this article, we will explore the process of designing, architecting, and implementing a data dictionary. But wait, this is only the beginning! A good data dictionary does not need to be entirely manually maintained. Many aspects of metadata, locating new data elements, and reporting/alerting on unusual changes can be built into a data dictionary. Automation allows a majority of the documentation to maintain itself, allowing it to be more accurate, require less manual updating, and be easier to use.
What is a data dictionary?
A data dictionary can be seen as a repository for information about a database. There are no industry standards that go into a data dictionary. It may be as simple as a list of tables with basic descriptions. Alternatively, it can be an extensive list of properties outlining precisely how data is structured, maintained, and used.
Software applications can be purchased and used to maintain a data dictionary. These applications can inspect a database and create metadata lists using internal database properties or their own proprietary data structures. Third-party applications are convenient and easy to use but may be limited in scope and are typically not free; however, they may have features that would be difficult or impossible for an individual to create.
For this discussion, a data dictionary will be built from the ground up using T-SQL. While this work will be done in SQL Server, a similar process could be written in other database systems to perform the same tasks. The benefits of building a data dictionary from scratch are:
- No monetary costs/licensing/contracts
- No need to share data with third-party organizations (if applicable)
- Can customize as much (or as little) as wanted.
- Can use this data in other applications via APIs or reporting processes
No process is without downsides. Building a data dictionary from scratch (like anything homegrown) entails:
- Time
- Resources
- Maintenance
The larger the project, the more work this will be, and it is quite likely that an exceptionally complex documentation project would benefit from a careful analysis of different approaches to ensure the best one is chosen. Similarly, if the documentation need is modest, then build-your-own will tend to be the most efficient solution.
Generally speaking, these costs will be lower than the time needed to maintain documentation via less organized means. A Word doc or Google Sheet do not represent adequate data documentation. Similarly, having no documentation is the worst-case scenario, and any organized data dictionary would be beneficial when compared to having nothing.
An additional note on lock-in: If a homegrown data dictionary outgrows its environment, then it is always possible to migrate data into another solution (homegrown or 3rd party).
Read also: SSRS ReportServer database structure
Why a data dictionary? Why not system views?
All database systems include a variety of internal tables and views that allow developers to view object names, data types, and other built-in properties. These views are exceptionally useful for operations and the automation of administrative functions (such as index maintenance, backups, ETL, etc.).
The following query retrieves all columns and some related metadata within a database using system views. You can download all code for this article here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT schemas.name AS SchemaName, tables.name AS TableName, columns.name AS ColumnName, types.name AS DataTypeName, columns.max_length, columns.precision, columns.scale, columns.is_nullable FROM sys.tables INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.types ON types.user_type_id = columns.user_type_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id WHERE tables.is_ms_shipped = 0; |
The results are as follows:
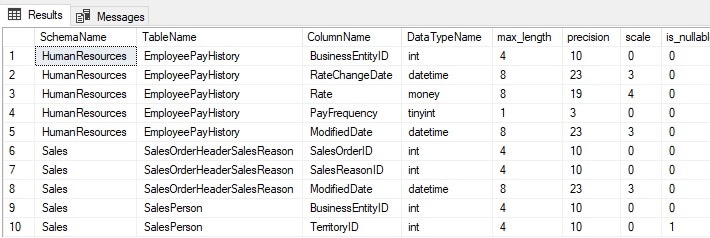
These results are easy for an administrator or developer to consume but have limited use beyond that scope. In addition, there is no human-readable documentation included. Any data dictionary needs to be easily consumable by people in different roles within an organization.
How about extended properties?
Extended properties can provide a way to add metadata inline to objects, like this:
|
1 2 3 4 5 6 |
EXEC sp_addextendedproperty @name = 'Employee Pay History Rate', @value = 'An employees pay rate. This will contain up to 4 decimal places and can never be NULL.', @level0type = 'Schema', @level0name = 'HumanResources', @level1type = 'Table', @level1name = 'EmployeePayHistory', @level2type = 'Column', @level2name = 'Rate'; |
Once added, they can be viewed in the SQL Server Management Studio GUI: 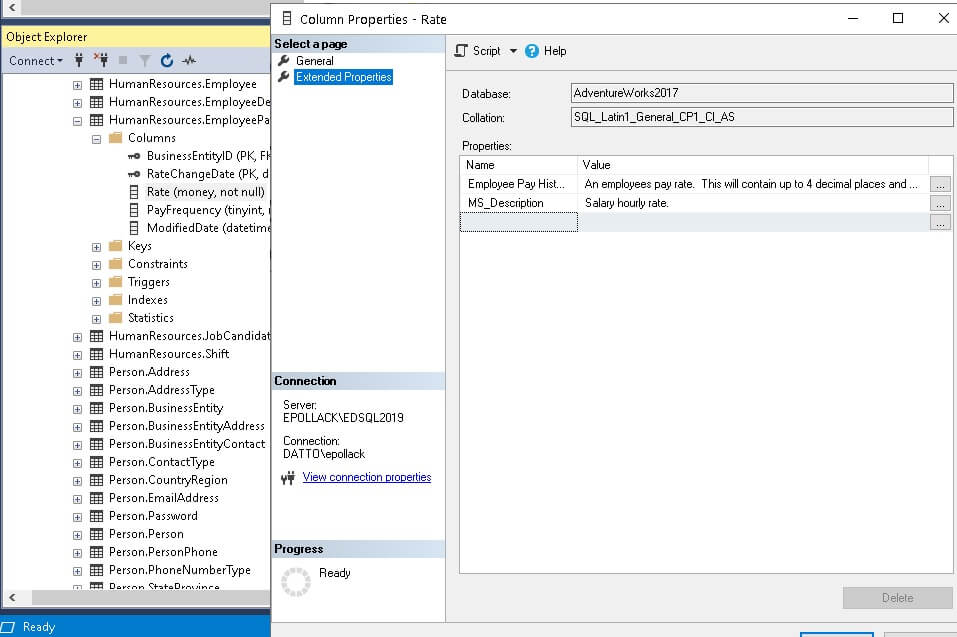
Similarly, they can be queried via T-SQL:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM sys.extended_properties INNER JOIN sys.objects ON extended_properties.major_id = objects.object_id INNER JOIN sys.columns ON columns.object_id = objects.object_id AND columns.column_id = extended_properties.minor_id WHERE objects.name = 'EmployeePayHistory' AND columns.name = 'Rate' |
The results of that query are as follows:

Extended properties are a convenient, built-in way to add descriptions to objects. Their documentation ability is limited, though, as you are restricted to a name and value. Using them in practice is similar to managing system views and requires database access or a report that accesses the objects for you.
For very simple and limited details, extended properties provide an easy and effective solution. For anything more extensive, though, they are inadequate and do not constitute the level of depth required of documentation for most organizations.
Read also: SQL Server Extended Events
Building a data dictionary
Building a customized data dictionary is labor-intensive, but the most time-consuming steps are not designing, architecting, and implementing code but collecting details needed to realize business meaning within this metadata.
The first step in this process is to build a table to store data. For this work, the result will be simplified to a single table and not normalized. The reasons for this are to keep the schema simple and easy to consume and to acknowledge that the table will not be large, and therefore complex dimensions are unlikely to be valuable.
What goes into this table? Anything really. If what is needed is not here, add it. If some columns are unnecessary, then remove them:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
CREATE TABLE dbo.data_element_detail (data_element_id INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_data_element_detail PRIMARY KEY CLUSTERED, data_element_name VARCHAR(100) NOT NULL, data_element_type VARCHAR(25) NOT NULL, data_type VARCHAR(128) NOT NULL, data_purpose VARCHAR(100) NOT NULL, entity_purpose VARCHAR(300) NOT NULL, database_server VARCHAR(128) NOT NULL, database_name VARCHAR(128) NOT NULL, schema_name VARCHAR(128) NOT NULL, table_name VARCHAR(128) NOT NULL, column_name VARCHAR(128) NOT NULL, original_data_source VARCHAR(500) NOT NULL, notes VARCHAR(1000) NOT NULL, foreign_key_to VARCHAR(128) NULL, row_count BIGINT NOT NULL, data_start_time SMALLDATETIME NULL, data_end_time SMALLDATETIME NULL, create_time DATETIME2(3) NULL, last_update_time DATETIME2(3) NOT NULL, is_deleted BIT NOT NULL, is_nullable BIT NOT NULL); |
Each column provides a basic detail about a column that lives in a database somewhere:
data_element_id: A numeric primary key for the table. It can be used to identify a row. The natural key of database_server, database_name, schema_name, table_name, and column_name can also be used as a primary or alternate key.
data_element_name: A informal name for the column. For database objects that are already well named, this may require little effort, but for any that are poorly named, a familiar/casual name can provide great value to anyone using this data.
data_element_type: If OLAP data, then there is value in documenting whether a column represents a fact or dimension. This detail may or not be necessary, depending on the data that is being documented.
data_type: The data type as defined in SQL Server.
data_purpose: The overall purpose of the application that consumes this data. This is something generic to allow a user to understand the over-arching reason that this data exists. This will typically be the same for many tables (or an entire database) that share a common use-case.
entity_purpose: The purpose for this specific table. This will usually be the same for all columns in the table.
database_server, database_name, schema_name, table_name, column_name: These are all taken straight from SQL Server and together describe the unique location and name for the data element.
original_data_source: This is where you can document a data element’s origin if it is not the same as it’s current location. This column is useful for copied, moved, or archived data via ETL or reporting/analytics processes as it can document its original source before it was moved.
notes: A free-form text field for any details about the column, its usage, and its meaning. While anything can go here, it’s worthwhile to maintain a consistent strategy for adding notes so that users of this data know what to expect as they are reading this.
foreign_key_to: If the column references a column in another table, it can be documented here. If a database is relational, then this column can be populated from sys.foreign_keys and sys.foreign_key_columns. If the database is not relational, this will involve some manual or semi-autonomous work to maintain.
row_count: The row count of the table. This value can be collected quickly and easily from sys.dm_db_partition_stats and allows the consumer of this data to understand its size as a table with 1,000 rows will be used differently than a table with 1 billion rows.
data_start_time and data_end_time: If the data has a defined start/end time, it can be provided here. A column for the data retention policy could similarly replace this and provide functionality for columns that undergo regular cleanup or archiving. Essentially, these columns (or something similar) provide detail on when data began to be populated and when (or if) it ends. For a table where columns are added over time but not backfilled, this can be exceptionally useful.
create_time and last_update_time: This documents when a column was added to the data dictionary and when it was last updated.
is_deleted: If data element details will be retained for posterity for deleted columns, then flagging them as deleted is necessary. Additional information could be provided as well, such as the time of deletion and reason.
is_nullable: If data element is a NULLable column, then this will be set to 1.
Once a table is defined, metadata can be inserted. In its most basic usage, data can be inserted manually. This effort would make the table about as efficient as a fully-manual wiki, document, or version-controlled source-code system. For testing, populating data like this is adequate, but long-term, automation is needed.
A fully manual insert would look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
INSERT INTO dbo.data_element_detail (data_element_name, data_element_type, data_type, data_purpose, entity_purpose, database_server, database_name, schema_name, table_name, column_name, original_data_source, notes, foreign_key_to, row_count, data_start_time, data_end_time, create_time, last_update_time, is_deleted, is_nullable) VALUES ( 'Employee Login ID', 'Dimension', 'NVARCHAR(256)', 'AdventureWorks application data', 'Details and login information for all employees.', 'DevServer1', 'AdventureWorks2017', 'HumanResources', 'Employee', 'LoginID', '', 'This is the full login ID for a given employee, including domain + ''\'' as a prefix to the username itself', NULL, 290, '2021-02-02 19:46:54', '2021-02-02 19:46:54', SYSDATETIME(), SYSDATETIME(), 0, 0); |
Effective, but not terribly exciting. Doing this repeatedly for a large database would be torturously slow and error prone. The next step towards making this documentation faster and more reliable is automation.
Read also: SQL Server triggers for change tracking
Automation with a minimalist style
This effort aims to automate as much as possible but not to create a process that is so complex that it requires immense effort to maintain. The primary downside of any do-it-yourself approach is that whatever is created needs to be maintained (potentially forever).
When the DIY solution is 1,000 lines of PowerShell and 5,000 lines of T-SQL, the maintenance becomes very much non-trivial. Therefore, a target of a few hundred lines of T-SQL would be simple enough that maintaining the code, even by someone unfamiliar with it, would not be a complex task.
First, from the column list above, what bits of metadata do not need to be manually entered? These would include any that originate from system views or tables and can be automatically checked into the data dictionary, such as the database server, database name, column name, or row count.
Realistically, the only columns that require manual intervention are those intended to add human-readable detail, such as original data source, data purpose, and notes. Even the data element name can be automated if columns follow a relatively reliable naming convention. Therefore, automation aims to remove as much work as possible and place what work is necessary on a silver platter for review.
Naming data elements
Everyone has slightly different conventions they follow with regards to creating object or element names. There is value in pre-populating a data element name, even if there is a chance it will not be descriptive enough for permanent use. This can reduce future work, especially in databases that already follow naming conventions that are consistent and descriptive.
To accomplish this, a function can be created to take the column name and perform some string manipulation to turn it into a more friendly name. The resulting data element name may not always be the final or best name, but if it is accurate often enough, then it will be a time-saver for anyone entering or maintaining data dictionary data. The following is a simple function that can accomplish this task:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
CREATE FUNCTION dbo.format_entity_name (@input_string VARCHAR(128)) RETURNS VARCHAR(128) AS BEGIN DECLARE @index INT = 1; DECLARE @character CHAR(1); DECLARE @previous_character CHAR(1); SELECT @input_string = LOWER(REPLACE(@input_string, '_', ' ')); DECLARE @output_string VARCHAR(128) = @input_string; WHILE @index <= LEN(@input_string) BEGIN SELECT @character = SUBSTRING(@input_string, @index, 1); SELECT @previous_character = CASE WHEN @index = 1 THEN ' ' ELSE SUBSTRING(@input_string, @index - 1, 1) END; IF @previous_character = ' ' BEGIN SELECT @output_string = STUFF(@output_string, @index, 1, UPPER(@character)); END SELECT @index = @index + 1; END SELECT @output_string = REPLACE(@output_string, 'Api ', 'API '); SELECT @output_string = REPLACE(@output_string, ' Utc', ' UTC'); SELECT @output_string = REPLACE(@output_string, ' Id', ' ID'); SELECT @output_string = REPLACE(@output_string, ' Ip ', ' IP '); SELECT @output_string = REPLACE(@output_string, ' Ms', ' MS '); SELECT @output_string = REPLACE(@output_string, 'Url', 'URL'); RETURN @output_string; END |
When an input string is passed into the function, underscores are replaced with spaces, each word is capitalized, and some common abbreviations are capitalized. These are a handful of examples of how text can be formatted to meet some of the naming needs that may arise. Feel free to customize and extend this to whatever other needs may arise!
Note that since this function contains iteration, it should be used on small sets of data or metadata where row-by-row calculations of this nature are acceptable. A data dictionary where data elements are named once and never again is a perfect use-case.
The following T-SQL will illustrate a few uses of this function:
|
1 2 3 |
SELECT dbo.format_entity_name('primary_account_create_time_utc'); SELECT dbo.format_entity_name('api_call_count'); SELECT dbo.format_entity_name('Employee_Primary_URL_Source'); |
The results show how the column names were formatted to follow a similar naming convention that can form the first step in naming data elements:
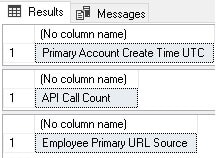
Ultimately, this is a process that is destined to be highly customizable. In some cases, it may be unnecessary. Either way, a scalar function is an easy way to encapsulate the logic needed to format names for use in a data dictionary.
Building the data dictionary update process
With some goals and guidelines in mind, the process of building a stored procedure to populate and maintain a data dictionary can begin.
Ideally, this process would have more value if it could poll a set of databases on a server, removing the need to execute it repeatedly for multiple databases. It would also remove the need to modify the calling code whenever a new database is added.
To simplify this, a table type will be created to store database names:
|
1 2 |
CREATE TYPE dbo.database_list AS TABLE ( database_name SYSNAME NOT NULL PRIMARY KEY CLUSTERED); |
The table type allows a set of databases to be passed into a stored procedure, which is programmatically easier to work with than a comma-separated list or some other text field. Whenever the data dictionary load process runs, a set of database names can be passed in that will be used to filter results to only target those databases. This helps filter out system databases, as well as user databases that are not of interest to the data dictionary.
The following summarizes the steps that this process will follow:
- Create a temporary table to hold database names, as well as if they are processed.
- Create a temporary table to hold table row count data.
- Create a temporary table to hold all other data element metadata.
- Iterate through the database list and:
- Collect row count data from
dm_db_partition_stats - Collect data element metadata
- Flag completed databases so they are only processed once
- Collect row count data from
- Merge the results captured above into
data_element_detail
The goal is a stored procedure that accomplished the basics of what we want and sticks to our ideal of simplicity by doing so in under 200 lines of T-SQL. Please see the attached Data Dictionary creation scripts, which include table creation, the function to format entity names, a table type for use as a table-valued parameter, and the stored procedure
A few collate statements are thrown in when comparing source/target data. Depending on how a given database environment is collated, this may not be necessary. Leaving it causes no harm and does not reduce performance.
Sys.dm_db_partition_stats is used as the source for row count data. The row counts provided here are approximates based on the partition contents, but for data dictionary purposes, are more than accurate. The alternative of selecting counts directly from tables would be expensive and slow enough to not be acceptable for most applications.
Note that many data elements are automatically populated with empty strings or assumptions. These are starting points and can be re-evaluated based on the needs of a data dictionary. The goal is to reduce to an absolute minimum the changes that have to be made directly by a human being. The manual intervention will generally be to review/add/edit human-readable descriptions that otherwise cannot be generated easily from metadata.
Executing the stored procedure requires passing in a set of database names:
|
1 2 3 4 5 6 7 8 |
DECLARE @database_list dbo.database_list; INSERT INTO @database_list (database_name) VALUES ('AdventureWorks2017'), ('WideWorldImporters'), ('WideWorldImportersDW'); EXEC dbo.update_data_dictionary @database_list = @database_list; |
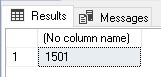
Despite there potentially being many columns to document in these databases, the stored procedure executes in under a second. A quick check of the row count confirms how many data elements were found:
|
1 2 3 |
SELECT COUNT(*) FROM dbo.data_element_detail; |
By selecting * from the table, the detailed data can be reviewed:

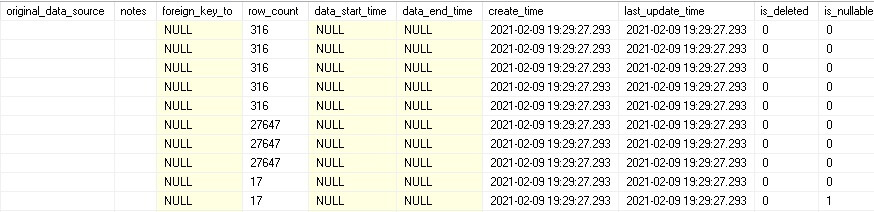
While there are many blanks to potentially be filled in, this provides a great starting point for documenting data elements. Because the create and last update times are maintained, as well as whether a data element is deleted, it is easy to validate change over time and consider how to handle new additions as they arrive.
Data Element Type is populated based on a simplistic formula derived from the column name. If schemas or other conventions are used to determine fact vs. dimension, then adjust to account for it. This is provided as an example of how to handle this data but can be customized to become as useful as possible.
Read also: Automating database scripting with PowerShell
Ignoring data elements
There often are data elements that are not intended for documentation. They may be temporary, flagged for deletion, or internal and not intended for documentation. Either way, exceptions can be added in easily as filters against any of the columns collected above. Most commonly, schema, table, or column names can be filtered to remove anything that should not be documented.
The filters may be managed via an external table that is used to collect metadata about what should not be documented or via filters built into the stored procedure. Which to choose would be based on the number of exceptions to process, how often they change, and who will maintain that list.
A metadata table is easier to maintain for anyone not directly involved in the process, whereas hard-coded exceptions are more permanent and easier to maintain if they are unlikely to ever change.
The manual component
Inevitably, no matter how much effort it put into automation, there will be some amount of data that requires manual data entry or updates. A semi-autonomous data dictionary’s goal is to reduce the volume of manual work as much as possible while making those updates easy and painless.
Of the many fields discussed in this article thus far, some will be seen as required and must be populated for this metadata to be useful. Other data is optional, and some may be unnecessary for some applications.
For example, the foreign_key_to column may not be relevant in tables that are denormalized or that do not use foreign keys. Alternatively, the notes column is universally useful as an opportunity to put human-readable details into documentation
There are two options for mass-updating the manual fields:
- Update directly in T-SQL
- Update via an application, report, or form
Which option is used depends on who is doing the updating and their comfort level with different tools. If a database developer is updating this data, then T-SQL (or a stored procedure or similar) is an acceptable option. If an analyst is maintaining this data, then a form-based app in SSRS, Tableau, Access, or something homegrown is likely a better option. If the person working with this data is non-technical, then an app or web interface would be ideal to avoid confusion as to how to update data.
Identifying data that needs to be updated is not challenging and could be done with a query similar to this:
|
1 2 3 4 5 |
SELECT * FROM dbo.data_element_detail WHERE (notes = '' OR data_element_type = '' OR data_purpose = '' OR entity_purpose = '') |
Nothing fancy here. Simply determine which fields are required and check for any rows that contain blank/NULL where data is expected. The results can be fed into any application where they can be reviewed and updated. The example above is simplistic, but a real-world application of this would not involve much more code.
Frequently repeated data elements
Some applications have rigid naming conventions and therefore have column names that are unique and sacrosanct. In other words, the column account_id in a database like this always means the same thing and, therefore, always has the same definition. If this is the case, then there is an opportunity to simplify the manual update component of a data dictionary. A process to update metadata for columns that match the definitions of other columns that already have their metadata populated could be modelled in a fashion similar to this:
- Has a column been given metadata before?
- If no, then manually populate it.
- If yes, then proceed to step 2.
- Is the column able to copy metadata from a similarly named column that already is complete?
- If no, then populate it manually.
- If yes, then identify this column and automatically copy metadata for it in the future.
Generally, a data element will have a source-of-truth row that is the primary key of a table and other rows that foreign key back to it. If the source-of-truth is populated first by a process, then the same process can subsequently do the same for all rows that reference it.
The process created above did not include the ability to populate foreign key metadata automatically, but this could be done quickly and accurately. The only caveat is that a database needs to use foreign keys to track dependencies. To do this, it is time to upgrade the scripts above to automatically populate the foreign_key_to column with metadata from SQL Server.
First, a new temporary table is created that will store foreign key metadata:
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE #foreign_key_metadata ( database_server VARCHAR(128) NOT NULL, database_name VARCHAR(128) NOT NULL, schema_name VARCHAR(128) NOT NULL, table_name VARCHAR(128) NOT NULL, column_name VARCHAR(128) NOT NULL, foreign_key_column_number INT NOT NULL, foreign_key_to VARCHAR(384) NOT NULL, foreign_key_column_count INT NOT NULL); |
Next, within the dynamic SQL after row counts are collected, a new block of T-SQL is added to the stored procedure that collects all foreign key metadata from the current database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
INSERT INTO #foreign_key_metadata (database_server, database_name, schema_name, table_name, column_name, foreign_key_column_number, foreign_key_to, foreign_key_column_count) SELECT @@SERVERNAME AS database_server, ''' + @current_database_name + ''' AS database_name, REFERENCING_SCHEMA.name AS schema_name, REFERENCING_TABLE.name AS table_name, REFERENCING_COLUMN.name AS column_name, foreign_key_columns.constraint_column_id AS foreign_key_column_number, REFERENCED_SCHEMA.name + ''.'' + REFERENCED_TABLE.name + ''.'' + REFERENCED_COLUMN.name AS foreign_key_to, (SELECT COUNT(*) FROM sys.foreign_key_columns COLUMN_CHECK WHERE COLUMN_CHECK.constraint_object_id = FOREIGN_KEY.object_id) AS column_count FROM [' + @current_database_name + '].sys.foreign_key_columns INNER JOIN [' + @current_database_name + '].sys.objects FOREIGN_KEY ON FOREIGN_KEY.object_id = foreign_key_columns.constraint_object_id INNER JOIN [' + @current_database_name + '].sys.tables REFERENCING_TABLE ON foreign_key_columns.parent_object_id = REFERENCING_TABLE.object_id INNER JOIN [' + @current_database_name + '].sys.schemas REFERENCING_SCHEMA ON REFERENCING_SCHEMA.schema_id = REFERENCING_TABLE.schema_id INNER JOIN [' + @current_database_name + '].sys.columns REFERENCING_COLUMN ON foreign_key_columns.parent_object_id = REFERENCING_COLUMN.object_id AND foreign_key_columns.parent_column_id = REFERENCING_COLUMN.column_id INNER JOIN [' + @current_database_name + '].sys.columns REFERENCED_COLUMN ON foreign_key_columns.referenced_object_id = REFERENCED_COLUMN.object_id AND foreign_key_columns.referenced_column_id = REFERENCED_COLUMN.column_id INNER JOIN [' + @current_database_name + '].sys.tables REFERENCED_TABLE ON REFERENCED_TABLE.object_id = foreign_key_columns.referenced_object_id INNER JOIN [' + @current_database_name + '].sys.schemas REFERENCED_SCHEMA ON REFERENCED_SCHEMA.schema_id = REFERENCED_TABLE.schema_id; |
This query joins a handful of system views to collect and organize details about every foreign key defined in the database, including column numbers, in case it is a multi-column foreign key. Once collected, this data can be joined to the existing data set that is compiled at the end of the dynamic SQL block by adjusting the existing INSERT into #data_element_list_to_process as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
INSERT INTO #data_element_list_to_process (data_type, database_server, database_name, schema_name, table_name, column_name, row_count, is_nullable, foreign_key_to) SELECT CASE WHEN types.name IN (''VARCHAR'', ''CHAR'') THEN types.name + ''('' + CASE WHEN columns.max_length = -1 THEN ''MAX'' ELSE CAST(columns.max_length AS VARCHAR(MAX)) END + '')'' WHEN types.name IN (''NVARCHAR'', ''NCHAR'') THEN types.name + ''('' + CASE WHEN columns.max_length = -1 THEN ''MAX'' ELSE CAST(columns.max_length / 2 AS VARCHAR(MAX)) END + '')'' WHEN types.name IN (''DECIMAL'', ''NUMERIC'') THEN types.name + ''('' + CAST(columns.precision AS VARCHAR(MAX)) + '','' + CAST(columns.scale AS VARCHAR(MAX)) + '')'' WHEN types.name = ''DATETIME2'' THEN types.name + ''('' + CAST(columns.scale AS VARCHAR(MAX)) + '')'' ELSE types.name END AS data_type, @@SERVERNAME AS database_server, ''' + @current_database_name + ''' AS database_name, schemas.name AS schema_name, tables.name AS table_name, columns.name AS column_name, row_count.row_count, columns.is_nullable, foreign_key_metadata.foreign_key_to + CASE WHEN foreign_key_metadata.foreign_key_column_count > 1 THEN '' ('' + CAST(foreign_key_metadata.foreign_key_column_number AS VARCHAR(MAX)) + '' of '' + CAST(foreign_key_metadata.foreign_key_column_count AS VARCHAR(MAX)) + '')'' ELSE '''' END AS foreign_key_to FROM [' + @current_database_name + '].sys.tables INNER JOIN [' + @current_database_name + '].sys.schemas ON schemas.schema_id = tables.schema_id INNER JOIN [' + @current_database_name + '].sys.columns ON tables.object_id = columns.object_id INNER JOIN [' + @current_database_name + '].sys.types ON columns.user_type_id = types.user_type_id INNER JOIN #row_count row_count ON row_count.table_name = tables.name COLLATE DATABASE_DEFAULT AND row_count.schema_name = schemas.name COLLATE DATABASE_DEFAULT AND row_count.database_name = ''' + @current_database_name + ''' AND row_count.database_server = @@SERVERNAME LEFT JOIN #foreign_key_metadata foreign_key_metadata ON foreign_key_metadata.column_name = columns.name COLLATE DATABASE_DEFAULT AND foreign_key_metadata.table_name = tables.name COLLATE DATABASE_DEFAULT AND foreign_key_metadata.schema_name = schemas.name COLLATE DATABASE_DEFAULT AND foreign_key_metadata.database_name = ''' + @current_database_name + ''' AND foreign_key_metadata.database_server = @@SERVERNAME;'; |
Finally, as an added final step, the foreign_key_to column is added to the UPDATE section of the MERGE statement so that changes to it will be reflected in the data dictionary table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
MERGE INTO dbo.data_element_detail AS TARGET USING (SELECT data_type, database_server, database_name, schema_name, table_name, column_name, row_count, is_nullable, dbo.format_entity_name(column_name) AS data_element_name, CASE WHEN column_name LIKE 'dim%' THEN 'Dimension' WHEN column_name LIKE 'fact%' THEN 'Fact' ELSE '' END AS data_element_type, '' AS data_purpose, '' AS entity_purpose, '' AS original_data_source, '' AS notes, data_element_list_to_process.foreign_key_to AS foreign_key_to, NULL AS data_start_time, NULL AS data_end_time FROM #data_element_list_to_process data_element_list_to_process) AS SOURCE ON (SOURCE.table_name = TARGET.table_name AND SOURCE.column_name = TARGET.column_name AND SOURCE.schema_name = TARGET.schema_name AND SOURCE.database_name = TARGET.database_name AND SOURCE.database_server = TARGET.database_server) WHEN NOT MATCHED BY TARGET THEN INSERT (data_element_name, data_element_type, data_type, data_purpose, entity_purpose, database_server, database_name, schema_name, table_name, column_name, original_data_source, notes, foreign_key_to, row_count, data_start_time, data_end_time, create_time, last_update_time, is_deleted, is_nullable) VALUES ( SOURCE.data_element_name, SOURCE.data_element_type, SOURCE.data_type, SOURCE.data_purpose, SOURCE.entity_purpose, SOURCE.database_server, SOURCE.database_name, SOURCE.schema_name, SOURCE.table_name, SOURCE.column_name, SOURCE.original_data_source, SOURCE.notes, SOURCE.foreign_key_to, SOURCE.row_count, SOURCE.data_start_time, SOURCE.data_end_time, GETUTCDATE(), -- create_time GETUTCDATE(), -- last_update_time 0, -- is_deleted SOURCE.is_nullable) WHEN MATCHED AND (SOURCE.data_type <> TARGET.data_type OR SOURCE.row_count <> TARGET.row_count OR SOURCE.is_nullable <> TARGET.is_nullable OR ISNULL(SOURCE.foreign_key_to, '') <> ISNULL(TARGET.foreign_key_to, '') OR TARGET.is_deleted = 1) THEN UPDATE SET data_type = SOURCE.data_type, row_count = SOURCE.row_count, is_nullable = SOURCE.is_nullable, foreign_key_to = SOURCE.foreign_key_to, is_deleted = 0, last_update_time = GETUTCDATE() WHEN NOT MATCHED BY SOURCE THEN UPDATE SET is_deleted = 1, last_update_time = GETUTCDATE(); |
Rerunning the stored procedure with these changes in place results in foreign key metadata being added to the table. The following is a sample of the newly populated data:
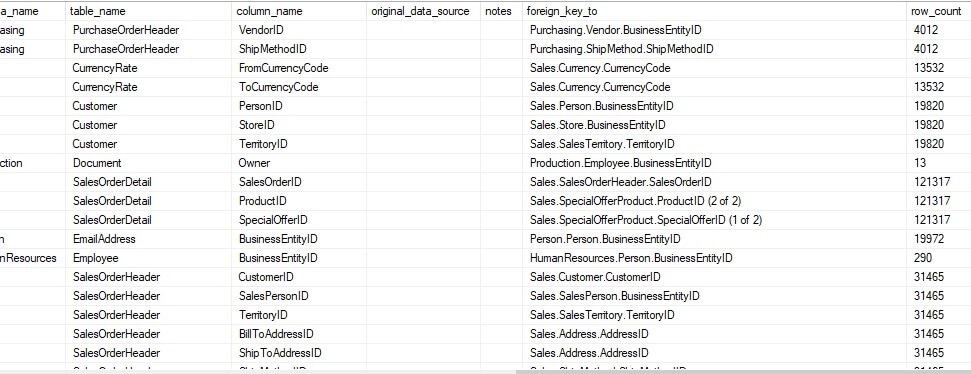
As a bonus, the foreign_key_to column includes notes for multi-column foreign keys, alerting how many columns are in the constraint and the column number for the current column.
With the ability to now automatically populate foreign key metadata, understanding which columns are a “source of truth” and which reference them can be determined programmatically. To test this, sample data will be added to a primary key column:
|
1 2 3 4 5 |
UPDATE data_element_detail set notes = 'The unique ID used to identify a product.' WHERE schema_name = 'Production' and table_name = 'Product' and column_name = 'ProductID'; |
This results in one column being assigned notes describing its meaning.
If desired, a process could be added to the data dictionary population that joins columns that reference a primary key column and copies data elements that are typically manually entered. A list could be made of columns that this feature should be used for, or all columns could be acted on. A sample query that acts on all columns in this fashion would look like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
UPDATE REFERENCING_ELEMENT SET notes = REFERENCED_ELEMENT.notes FROM dbo.data_element_detail REFERENCING_ELEMENT INNER JOIN dbo.data_element_detail REFERENCED_ELEMENT ON REFERENCING_ELEMENT.database_server = REFERENCED_ELEMENT.database_server AND REFERENCING_ELEMENT.database_name = REFERENCED_ELEMENT.database_name AND SUBSTRING(REFERENCING_ELEMENT.foreign_key_to, 1, CHARINDEX('.', REFERENCING_ELEMENT.foreign_key_to) - 1) = REFERENCED_ELEMENT.schema_name AND SUBSTRING(REFERENCING_ELEMENT.foreign_key_to, CHARINDEX('.', REFERENCING_ELEMENT.foreign_key_to) + 1, CHARINDEX('.', REFERENCING_ELEMENT.foreign_key_to, CHARINDEX('.', REFERENCING_ELEMENT.foreign_key_to) + 1) - CHARINDEX('.', REFERENCING_ELEMENT.foreign_key_to) - 1) = REFERENCED_ELEMENT.table_name AND SUBSTRING(REFERENCING_ELEMENT.foreign_key_to, CHARINDEX('.', REFERENCING_ELEMENT.foreign_key_to, CHARINDEX('.', REFERENCING_ELEMENT.foreign_key_to) + 1) + 1, LEN(REFERENCING_ELEMENT.foreign_key_to) - CHARINDEX('.', REFERENCING_ELEMENT.foreign_key_to, CHARINDEX('.', REFERENCING_ELEMENT.foreign_key_to) + 1)) = REFERENCED_ELEMENT.column_name WHERE REFERENCING_ELEMENT.notes = '' AND REFERENCING_ELEMENT.foreign_key_to IS NOT NULL AND REFERENCED_ELEMENT.foreign_key_to IS NULL AND REFERENCED_ELEMENT.notes <> ''; |
This T-SQL parses the foreign key column and updates notes for all data elements that foreign key directly to a primary key column that has notes entered. The following query can validate the results, returning all ProductID columns that now have notes entered in them:
|
1 2 3 4 5 6 |
SELECT * FROM dbo.data_element_detail WHERE data_element_detail.column_name = 'ProductID' AND data_element_detail.table_name <> 'Product' AND data_element_detail.notes <> ''; |
The results show 12 data elements that have been automatically updated from the update query above:
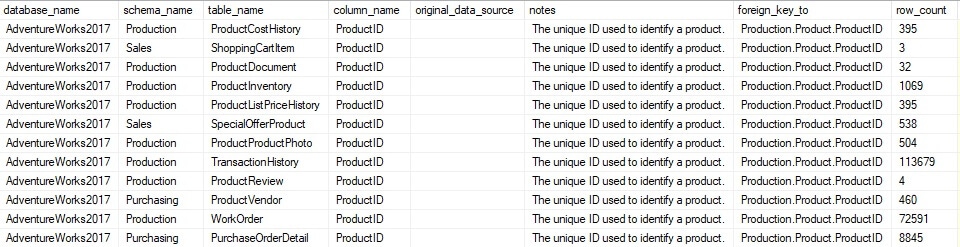
This process is highly customizable and allows for data to systematically be updated in one place and propagated throughout the data dictionary automatically. This example only updated the notes, but the same process could update any other column for which the metadata would be similar or identical to its parent object. The ultimate goal here is to save time by reducing as much as possible the manual steps required to maintain the data dictionary.
Use in documentation
A data dictionary is not a fully-functional documentation system in itself. It contains details about data elements that can fuel documentation, but this is not a system that is friendly to non-engineers. If a sales manager wants to know what metrics could be useful for a new quarterly report, they have one of two options:
- Check the documentation.
- Ask you.
Ideally, when a data dictionary nears completion, taking time to determine how to integrate it into existing (or new) documentation systems is important. This is the step that makes this information readily available to an organization, both for technical and non-technical folks. Moreover, having people ask you day-in and day-out about documentation is tedious and a waste of your time 😊
Customization
This data dictionary is exceptionally flexible, and its user can choose to add, remove, or change the details of any data element. The processes described in this article can be reused to populate any amount of columns, metrics, or metadata. The only limit is the imagination of the person implementing it.
Different systems will have different documentation needs. For example, the application name, service name, or software build a column was introduced could be added for analysts with development-leaning needs. Similarly, for operators interested in performance or server details, metrics such as space used, fragmentation, or reads could add those types of details as well. If the question is asked, “Can I add X to the data dictionary?” the answer will always be yes, and likely the process to do so no more complicated than what has been introduced in this article. Adjusting and adding to the code used here can allow for additions, modifications, or removals to be made with minimal effort or risk of breaking it.
Building a SQL Server data dictionary
A data dictionary is a versatile documentation tool that can save time, resources, and money. It can systematically reduce or remove the need for frequent, error-prone, and manual updates to extensive documentation systems. In addition, a data dictionary can be automated to further reduce the maintenance needed as applications grow and develop.
Because it is stored as a table in a database, this data dictionary can be connected to applications easily and consumed by analysts, documentation, or development teams in need or clarification on what a data element is, where it comes from, or how it works. In addition, an application can be used to update data in the data dictionary, further removing a database administrator, developer, or architect from the manual tasks of maintaining documentation and moving those tasks to the people closest to the documentation itself.
Processes that populate a data dictionary can be run regularly to maintain and update automatically populated fields, such as row counts, foreign key data, or auto-updating metadata.
While a homegrown solution is not right for every organization, it provides an easy starting point to realize the benefits of an organized documentation system and highlights the reasons why good database documentation is critical to the success of any teams that rely on databases for the success of their applications.
Customization allows for a data dictionary to be tailored to fit the needs of any application. The code presented in this article provides a starting point from which a data dictionary can evolve to be as efficient as possible. Feel free to take this code and produce the perfect documentation system for a given organization or application. If you add something new and interesting, please let me know all about it 😊
Fast, reliable and consistent SQL Server development…
FAQs: How to set up a data dictionary in SQL Server
1. What is a data dictionary in SQL Server?
A data dictionary is a documentation repository that describes the structure, meaning, and usage of data in your database. It goes beyond what system views provide – adding business descriptions, data ownership, quality rules, and change history. You can build one as a set of tables in the database itself, populated automatically from SQL Server’s catalog views plus manual enrichment.
2. How do you create a data dictionary in SQL Server?
Query SQL Server’s system catalog views (sys.tables, sys.columns, sys.types, INFORMATION_SCHEMA.COLUMNS) to extract structural metadata, then store the results in custom documentation tables along with fields for business descriptions, data stewards, and classification. Schedule the metadata collection to run periodically so the dictionary stays current as schemas change.
3. Can a SQL Server data dictionary be automated?
Yes. The structural metadata (table names, column names, data types, nullability, indexes) can be collected automatically from system views. Change detection – identifying new tables, dropped columns, or altered data types – can be automated with scheduled jobs that compare current metadata to the previous snapshot and alert on differences.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments