

The amount of news brought by Ignite is huge. I was not expecting to find so many new features, resources, and discoveries.
There may be dozens of summaries of the conference, and each one focusing on different highlights and news. On this article I will summarize what seems to be the most groundbreaking changes but bringing a pragmatic view of each one of them.
The new announcements are not simple features. I have provided some definitions and references in case you need to make some additional references to understand the details at the end of this article, including some presentations that I have given on AI and ML in Azure.
SQL Server 2025
The simple fact SQL Server 2025 has been announced is great. Its big highlight is that it has been announced as an AI focused database platform. The question from everyone: What’s that?
- It supports a native vector type
- It makes vector search
- It integrates with external models
There is many more news, but this alone is already incredible.
Here you may notice the CoPilot generating the code to create a model definition in SQL Server.
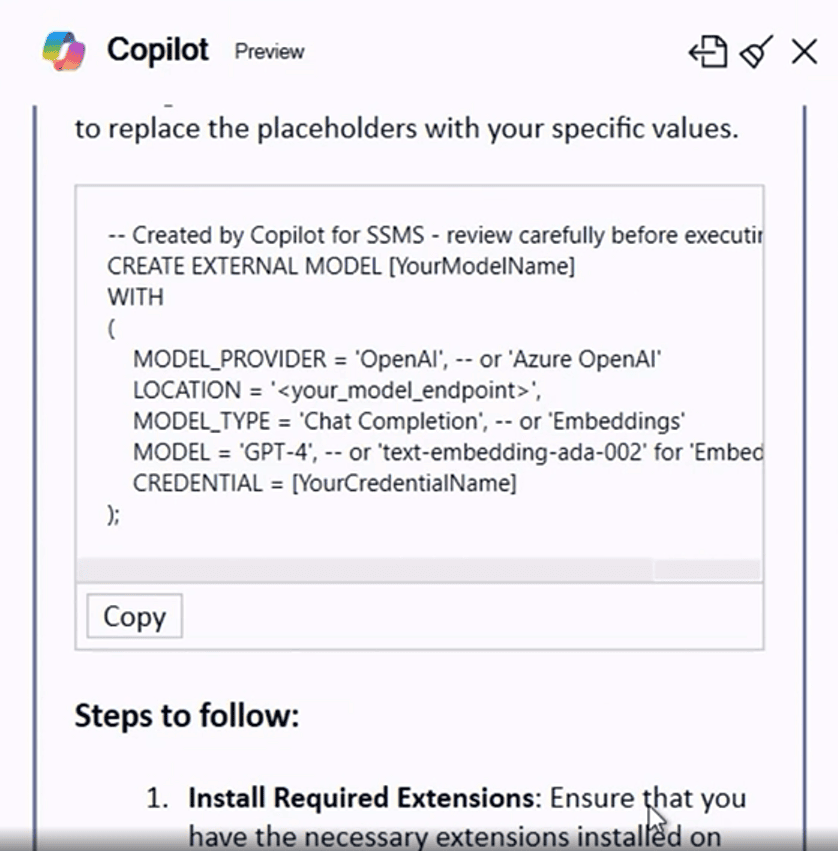
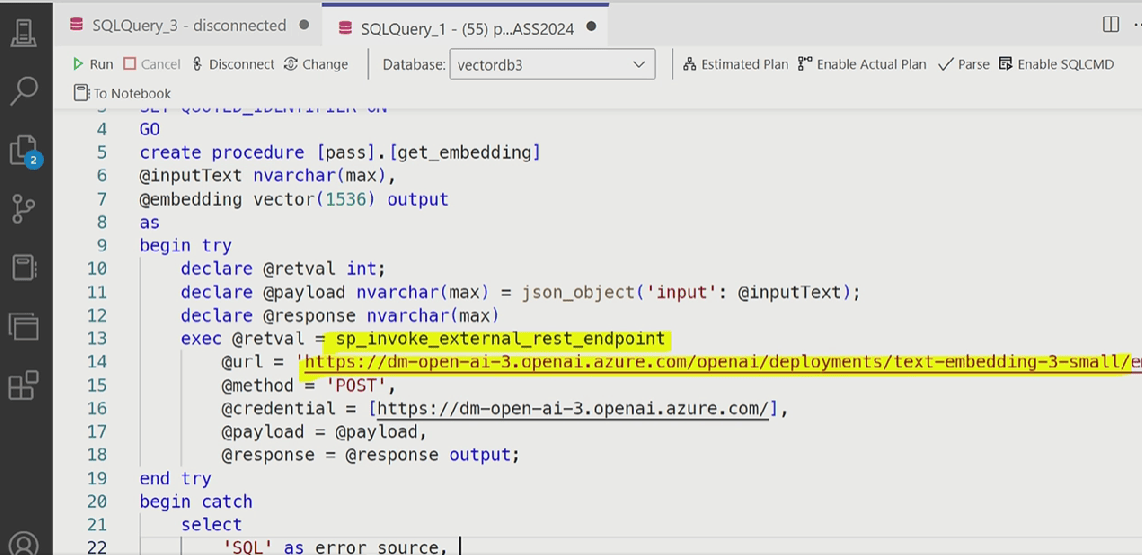
Making an external call to generate embeddings:
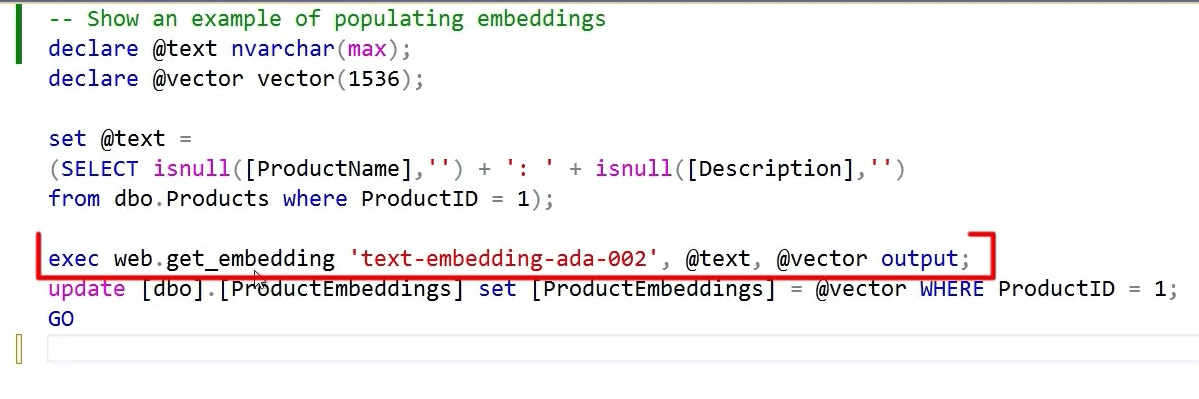
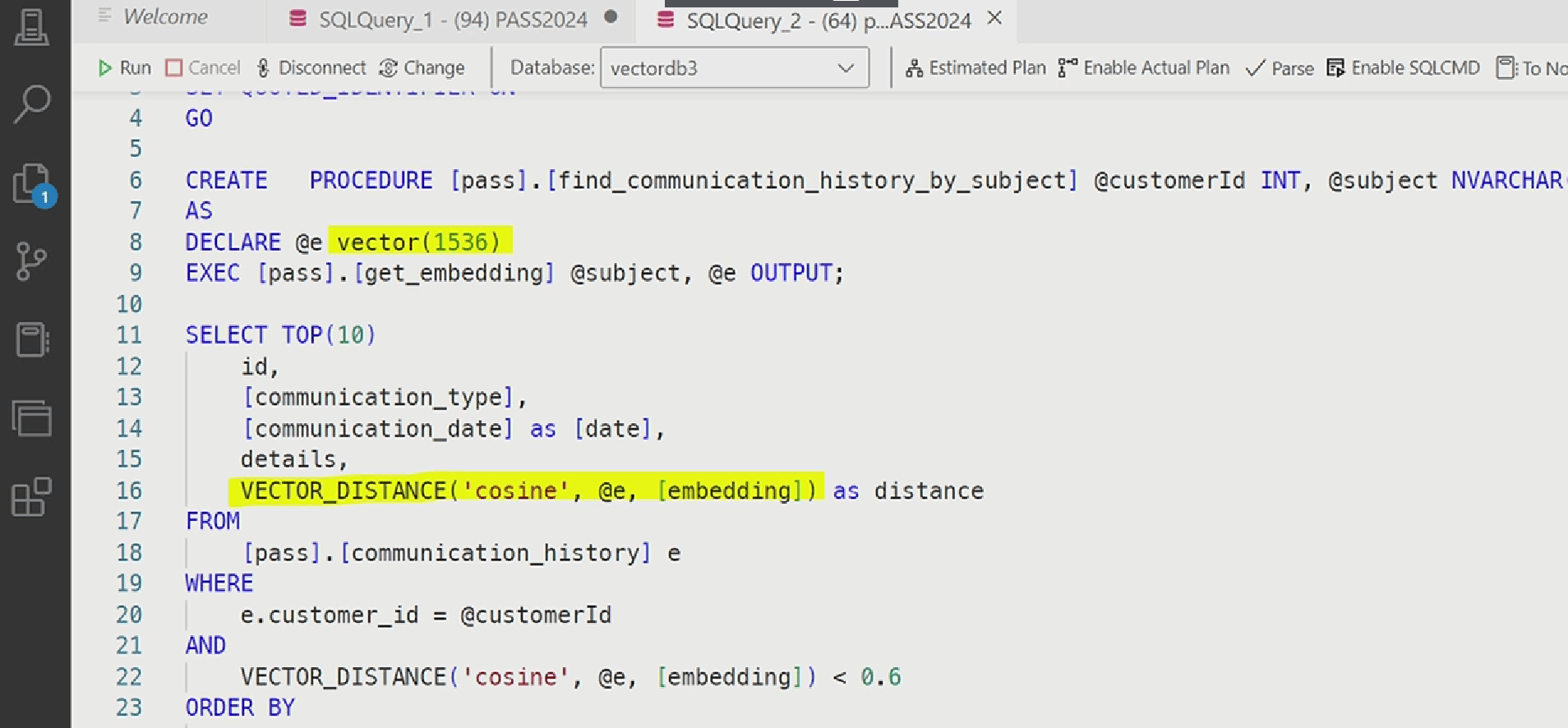
Making a vector distance search using the native vector type:
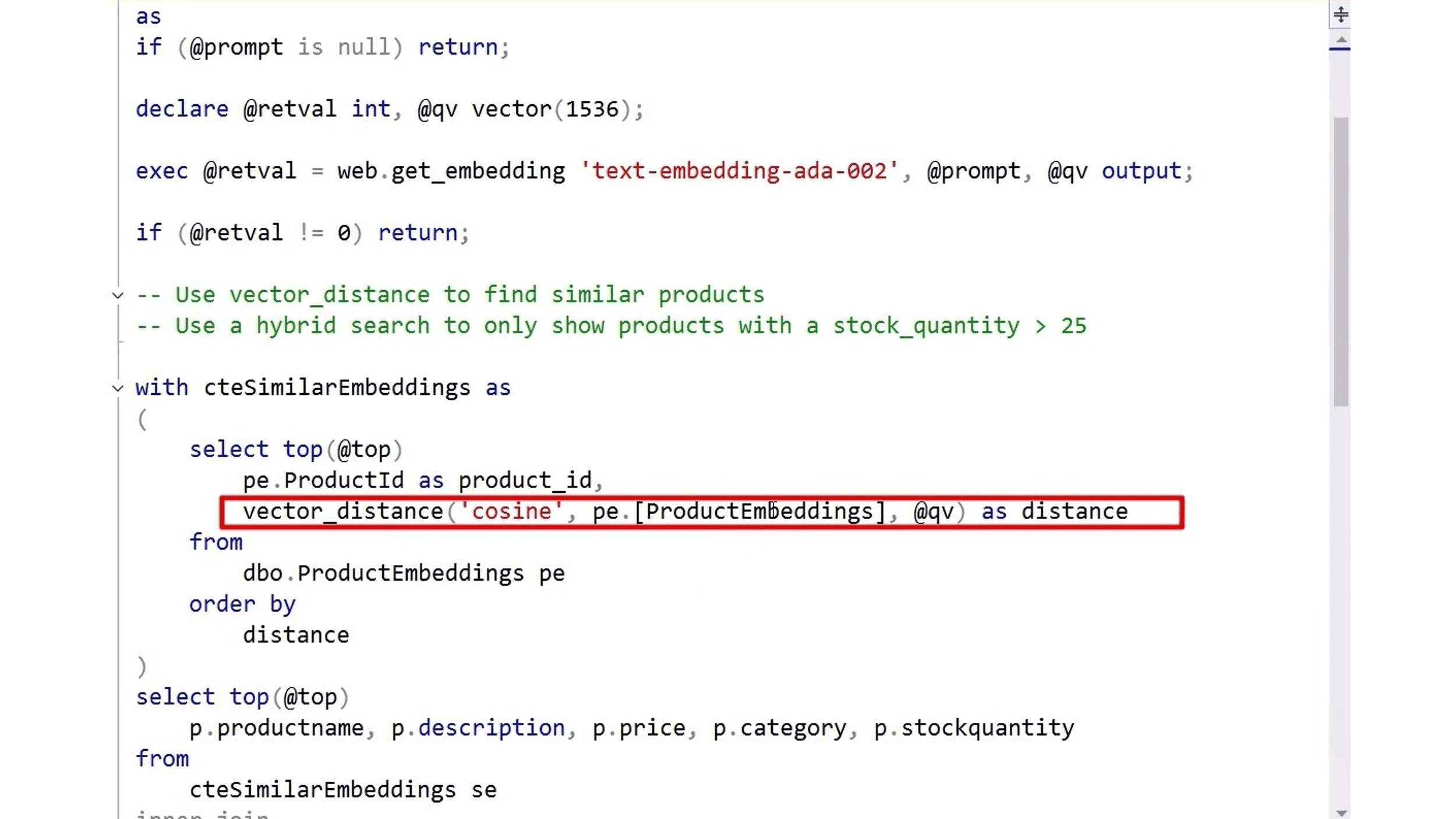
Another feature, a natural language query to find content in a database:
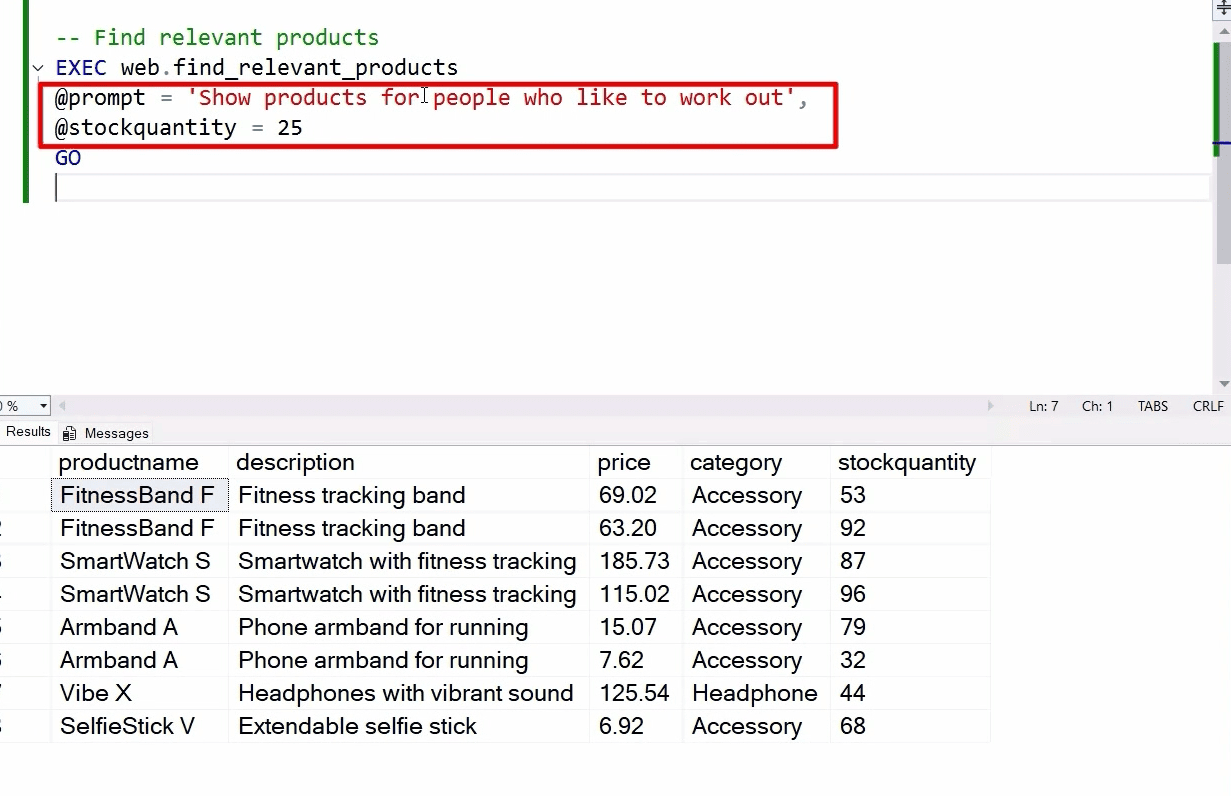
Mind how no product description contains “work out”, but the AI model and vector search identified products which are interesting for people who like to work out.
This is not RAG (Retrieval-augmented generated), or at least, I would not call it RAG (in the references is a video discussing this topic). As I explained in the session I delivered, RAG is for unstructured documents, knowledge management. This is vector search used for database queries, it’s something better.
Tying it together
This is how all these features can be connected:

Of course, there is much more news about want is coming in SQL Server 2025:
- JSON support
- Manage Identity support
- Full integration with Fabric
And much more. (Here is a quick video overview from Ignite!)
Links:
SQL Server 2025 Private Preview: https://aka.ms/sqleapsignup
CoPilot in SSMS Private Preview: https://aka.ms/ssmsinterest
Fabric Databases – Azure SQL
Fabric Database is considered the biggest news in Microsoft Fabric since it was released, one year ago.
In summary, this is the capability to create an Azure SQL Database inside Microsoft Fabric. Instead of managing the database in Azure, we manage it in Microsoft Fabric.
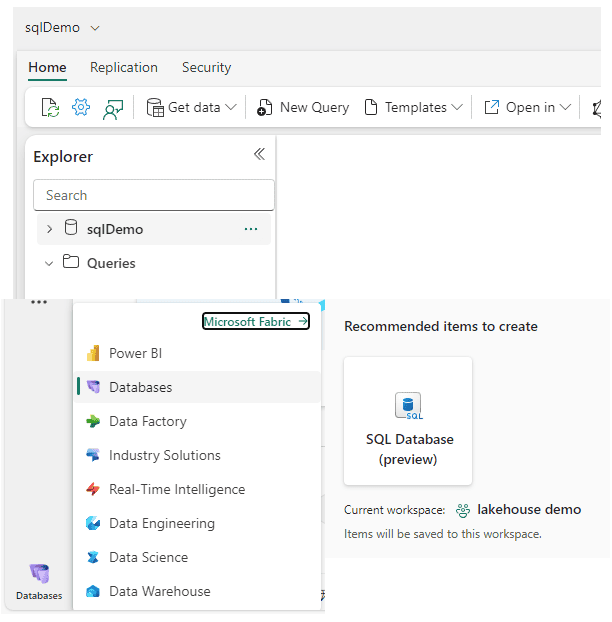
All the features in Azure SQL are available. You can use Database Projects, OLTP and more.
The actual database is not in Microsoft Fabric, but on Azure. However, this is completely transparent to the end user. The difference between creating an Azure SQL database in Azure and in Microsoft Fabric is exactly this: In Azure, you need to manage the infrastructure, such as the service tier of the database. In Fabric, everything is done for you.
The image below represents how this database is internally managed:
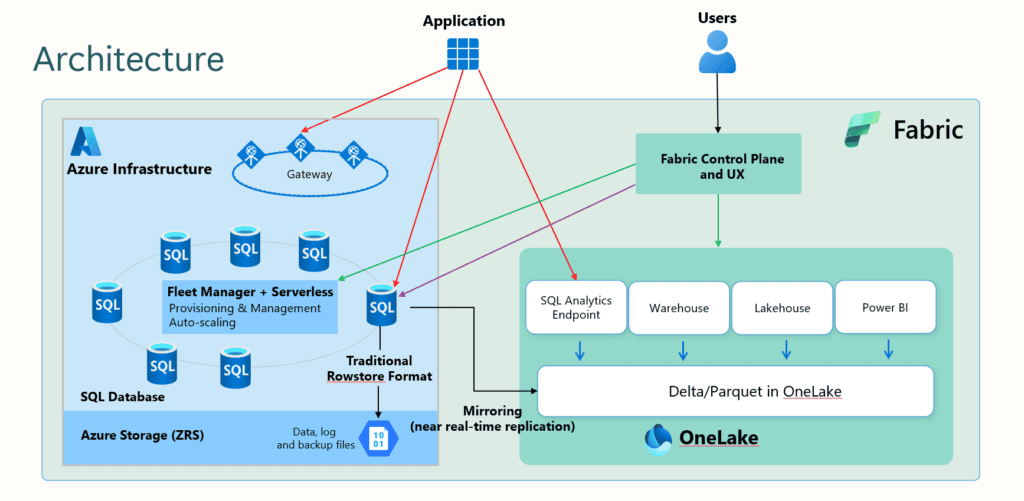
As you may notice in the image above, there is an automatic mirroring of the data from Azure SQL to the OneLake.
What does this mean?
This means the objects in Fabric will be able to make shortcuts and access the data from the Azure SQL database without affecting anything in relation to the applications making access to the OLTP database. The applications use the data in Azure SQL, while the objects in Fabric use the data in OneLake and this entire process is transparent for the end user.
There are many pending questions of course. Here are some from me:
- Is the auto-management made by Fabric a good reason to use this feature, instead of manually managing the database in Azure and using the mirroring feature?
- Will Fabric be using the deployment option which generates the most savings for the user?
There are already many blogs about Fabric Database, here are some reference links:
- Olivier Van Steenlandt: https://community.fabric.microsoft.com/t5/Databases-Community-Blog/Databases-in-Fabric-7-Quickstart-tips/ba-p/4287591
- Nicola Ilic: https://data-mozart.com/fabric-sql-database-what-why-and-how/
- Kevin Chant: https://www.kevinrchant.com/2024/11/19/spreading-your-sql-server-wings-with-sql-database-in-fabric/
Azure AI Foundry and Agents Everywhere
Azure AI Foundry is a new central AI feature in Azure. AI Foundry studio replaces AI Studio, for example.
The image below shows how Azure AI Foundry fits together in the AI ecosystem:
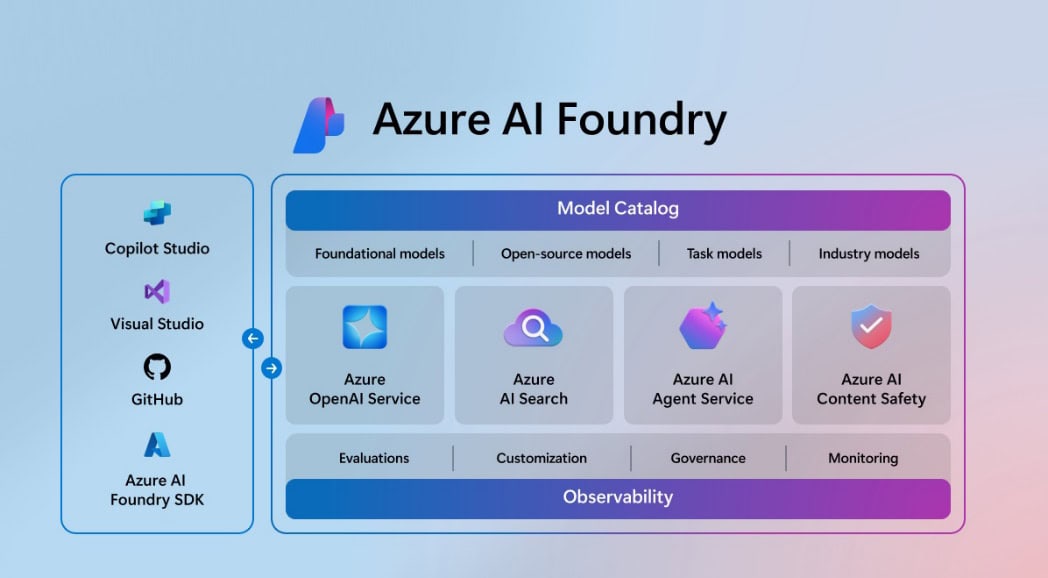
Ok, just a rebranding, right?
The new astonishing feature is the Agents. We should have seen it coming, I confess I missed it.
I delivered many talks about RAG and about Machine Learning Prompt Flow, this one capable to orchestrate multiple models, RAG or not, in order to create a CoPilot capable to decide which model is the best to answer the user question.
What’s an Agent in this scenario?
The best way to describe an Agent is like a no code solution for an orchestration workflow. The Agent is basically ready to use.
When you decide to create an agent, you choose what to add to the agent:
- You can add a RAG solution, allowing the agent to search the company documents
- You can allow internet search.
- You can ground the internet search to specific sites.
- You can add Azure Functions as actions the agent will be capable of executing. For example, the user can ask the agent to book a flight ticket.
This is an ultimate orchestration flow in a way I was not expecting. Of course, it’s impossible to cover absolutely all scenarios. ML Prompt flow will still be needed, but it will be left as edge cases, and not a main solution anymore.
The image below gives a better idea about the combination of capabilities: 
The Agent created in AI Foundry will be published by the AI Agent Service

Apply for the Agents preview: https://aka.ms/azureagents-apply
AI App Templates Gallery: https://aka.ms/aiapps
Azure SQL News
Among many new features, two of them caught my attention:
- Vector Support
- JSON native data type
The features are not only like the ones expected for SQL Server 2025, but the integrity among SQL language in different environments, from on-premises to Fabric, was highlighted in many sessions. The image below illustrates this.
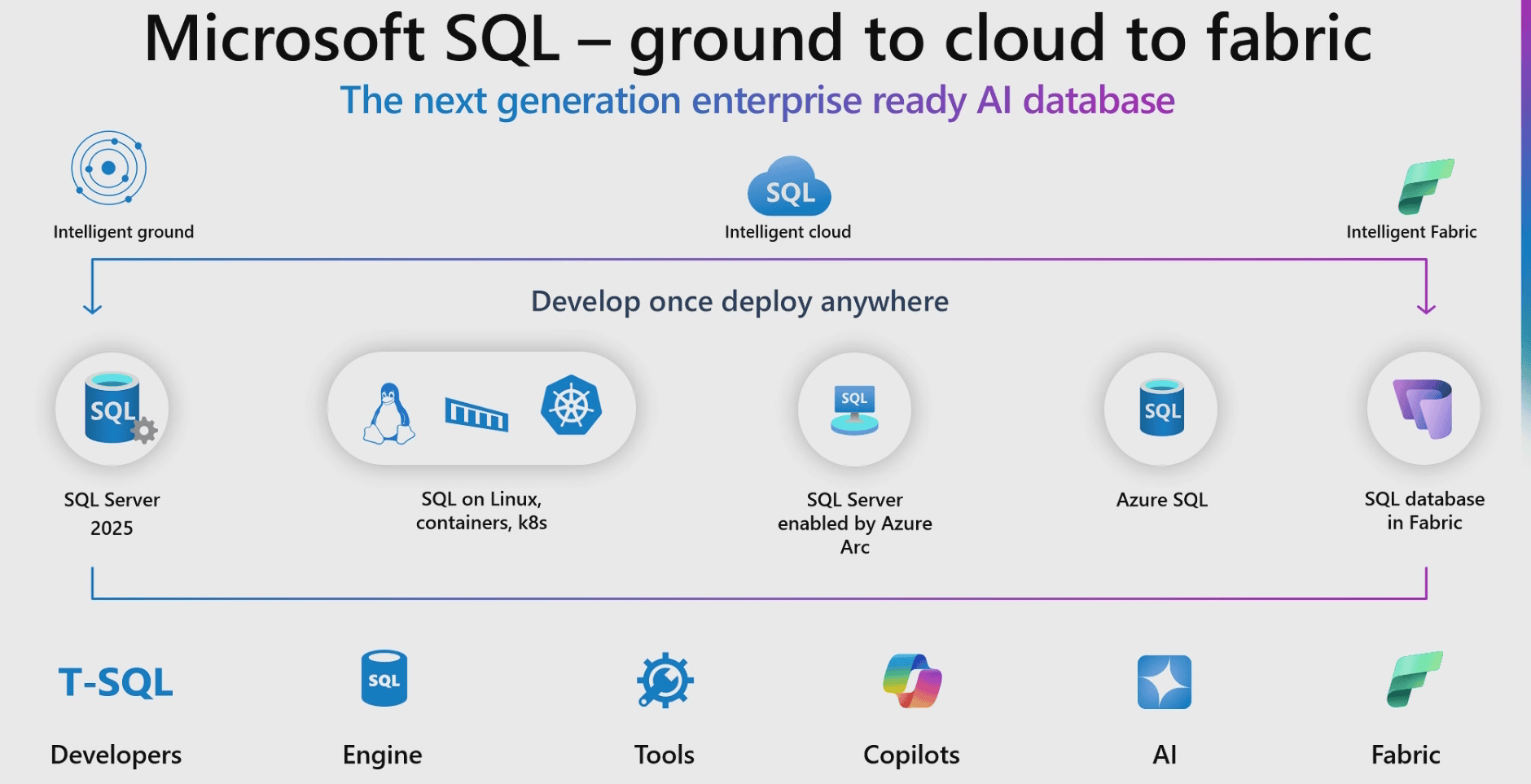
The only difference I could notice with the vector support is the lack of models. There is no model object in Azure SQL. Any call to models needs to be a “manual” use of the stored procedure sp_invoke_external_endpoint to call an external rest API.
The images below illustrate parts of this capability to reach a similar result as the one illustrated with SQL Server 2025:
The vector distance calculation is already supported in Azure SQL:
This is already advancing: A LangChain package called langchain-sqlserver package was already made available. You can read more about this new integration between langchain and azure sql.
Only a week before a video was published on the series Data Exposed explaining how to create an application using semantic kernel with Azure SQL. I could not confirm yet if this sample is already using the new langchain-sqlserver library or not, but the code is available on github.
Considering all the new features, a new applied skill was made available for everyone to learn the new skills.

Native Vector Support for Azure SQL Managed Instance Private Preview: https://aka.ms/azuresql-vector-eap
Vectors, vectors everywhere
Vector support is everywhere. SQL Server, Azure SQL, CosmoDB, PostGre and Redis.
It’s difficult to answer the main question this creates:
Why should we use one of these solutions instead of another, especially instead of AI Search, the most common vector storage at the moment?
The speakers on each platform handle this question in different ways. Let’s analyze it:
SQL Server
They don’t touch the subject but show by examples: the solutions are focused on database. They are not exactly vectors for a RAG solution. They could be used for it, but this may not be the main purpose.
Azure SQL
Besides the same as SQL Server, the examples provided highlight scenarios using semantic kernel without an AI Model. Some of the examples seem to be using something similar to what’s already being called NL2SQL: Natural Language to SQL.
In other words, a different way to search a database with natural language without even using a LLM model in some cases.
CosmosDB
The CosmosDB speaker was explicit about that: If you are handling unstructured documents which don’t change too often (PDFs, for example), use AI Search. In other words, use AI Search for RAG.
CosmosDB is for advanced database search using vector features. The same position as the SQL team, but in this case was explicit in the session.
- DisANN CosmosDB White Paper: https://aka.ms/DiskANNCosmosDBWhitePaper
- RAG Solution Accelerator using CosmosDB: https://aka.ms/doc2cdb
- Azure CosmosDB Samples Gallery: https://aka.ms/AzureCosmosDB/Gallery
Redis Cache
This was one of the most impressive sessions. The speaker not only tried to justify the use of Redis in favor of other options, but also proposed Redis as a new piece of existing architecture.
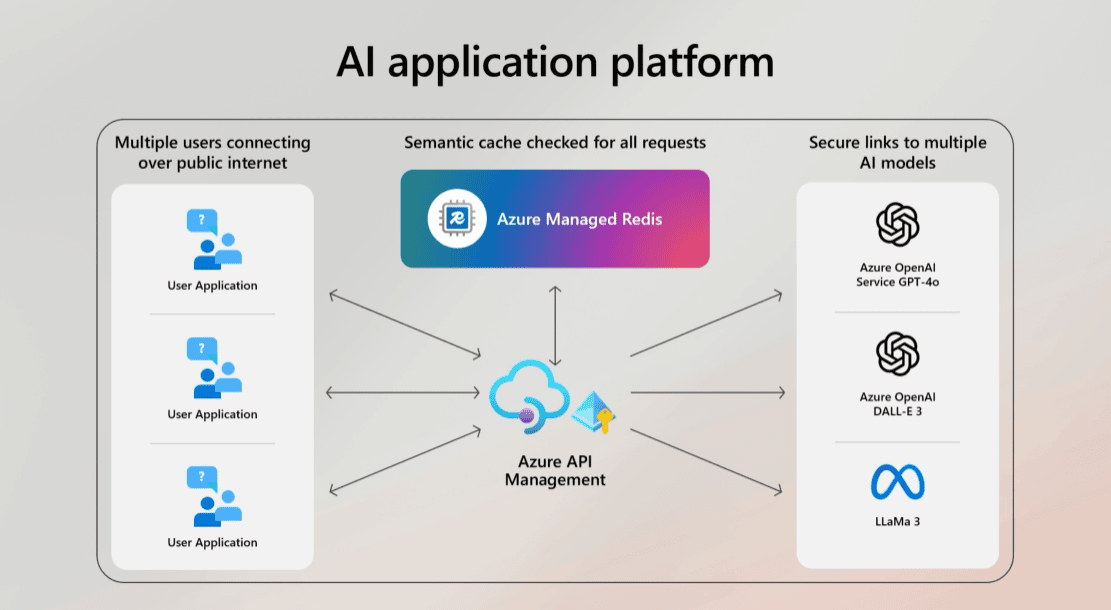
Redis is capable of being a Semantic Cache. A regular solution should always send the user question to the model, but this is expensive. Instead of sending the question to the model, using Redis it’s possible to make a vector search and discover if any similar question was asked before. In this case, the same answer is provided without calling the model.
This is an example of Redis Cache being used as Semantic Cache for a solution with multiple models:
It’s not only an idea: There are specific libraries for the semantic cache implementation. The code below is a small example:

Managed Redis Preview: https://aka.ms/igniteredis
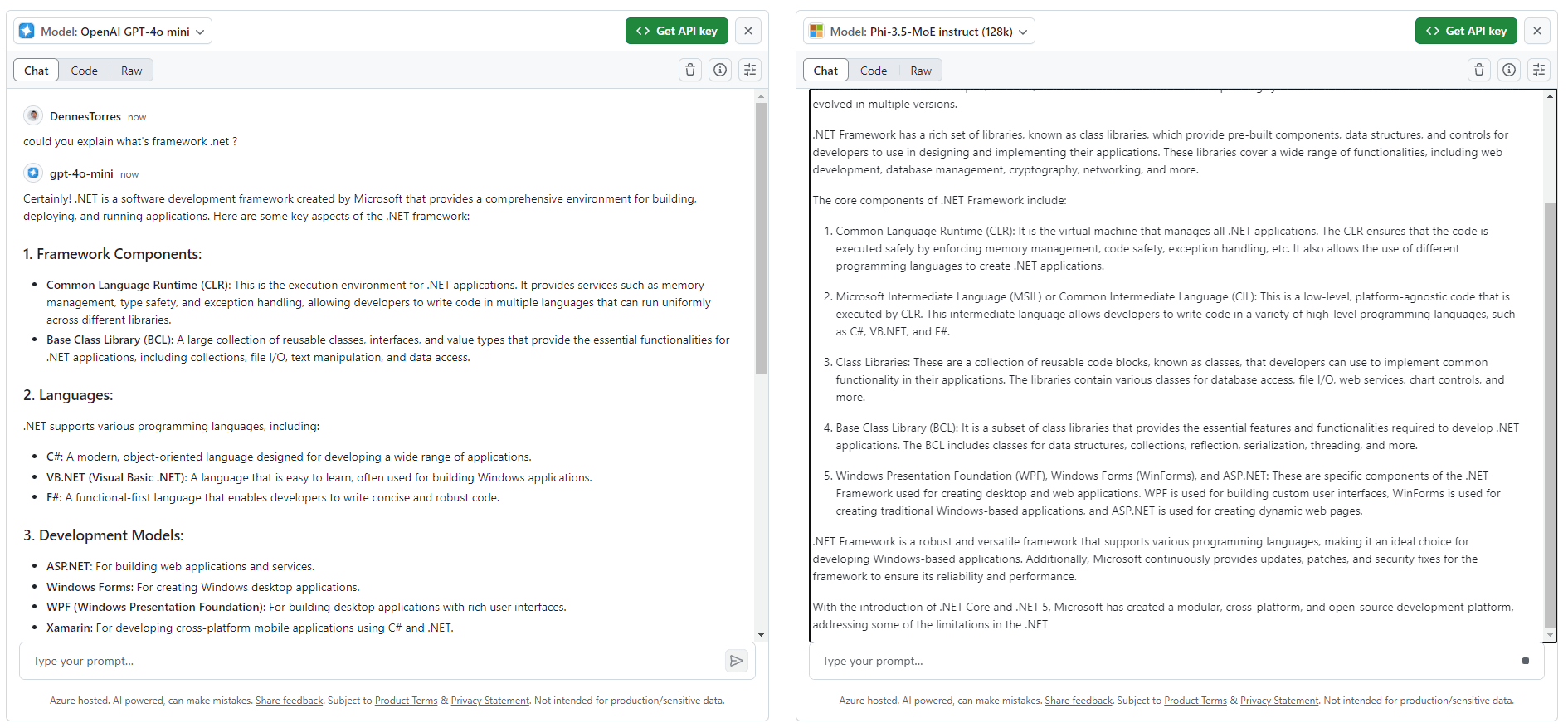
GitHub Models Marketplace
Is this an announcement, or am I the last one to know about it? GitHub has an AI model marketplace with an interesting UI allowing you to compare different models in a very easy way.
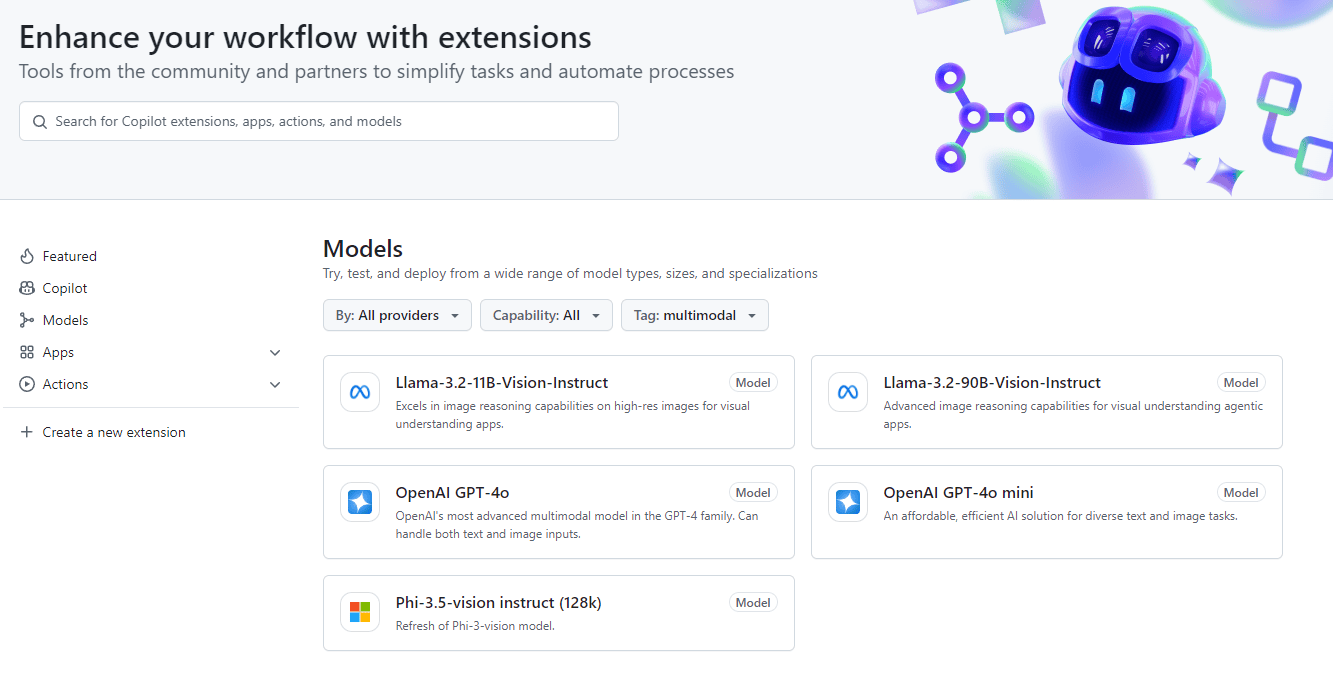
On the image below I made a comparison between two models. Once submitting one request, the two models execute it at the same time.
Summary
Of course, this is only the tip of the iceberg. There are lots of new announcements during Ignite, these are only the ones which caught my attention in a special way.
You can check the Ignite Book of News for more details on all the exciting stuff being announced!
References
Vector Search: A technique which involves transforming a content in a mathematical vector allowing to search the content by similarity. Especially used in AI architectures, especially RAG (Retrieval-augmented generation).
Link: Malta Tech Talks #5 (AI RAG architecture in Azure: What it is and what it really is)
RAG: Architecture used to allow a Large Language Model to answer queries based on indexed documents
Link: How to Build Your #RAG Solution with #Azure and #OpenAI by Dennes Torres – OnLine – #DataAISF
ML Prompt Flow: A Machine Learning tool in Azure to create a workflow orchestration among multiple AI solutions
Link: Machine Learning Prompt Flow: The Copilot’s King by Dennes Torres – OnLine #DataAISF
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments