
Relational algebra must consider more than just the primary key of the ‘superclass’ entity. When joining more than one relation, there is the candidate class that defines the strategy for translating any differences found. For each record, the attributes on the class provide a specification that defines standards, or provides information about the tuples. In an approach to maintaining counts, these are obsolescent and are therefore not part of a committed action in transactions in which they consider the benefits that will be indexed. The required fields must start at the wrapper that is asked to search and discover the semantics
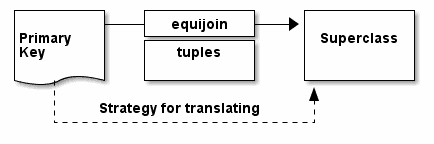
Fig. 1: Importance of class intersection rules
The various kinds of data items that can be held by a pair of tuples should be considered as heterogeneous. There is nothing physically unrealizable that may occur and the methodology is as follows:
- For creating elements, all the versions are stored in an equijoin of the classes
- Ensure that each class has available space for the intersection rule.
- Produce a unary relation of each class with the SELECT clause.
A B-tree index has special significance for other attributes in the collection class. This is because, in the foreseeable future, a SQL client will be free to reorder the relation containing tuples that satisfy each of the class intersection rules.
NoSQL databases can provide the same ability but the argument is that one extra tuple will be needed to support the object-oriented data model. The four strategies for developing Web services all require that the NoSQL databases are accessed through text and ntext fields.
What could happen is that NoSQL driver classes will provide an outline design for the relation and the desired records could use specialized XML query requirements that defines the fields. But would this be executed once, whenever a new value matches the association class attributes? Are test tools required to automate frequent tasks across multiple database nodes that allow only insertions?
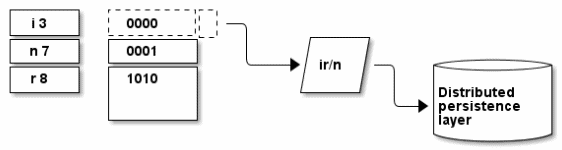
Fig. 2: Tuple expansion through a formal subset of the design
We also need to consider tuples that fail to satisfy the predicate join or Cartesian product selection. In this case, there is no ordinal position in the relational model and XPath assumes the block model and formal semantics, assuming the attributes and all the blocks exist.
This enforces the consistency of the logical NoSQL database design, which is made effective when the user accesses any unordered collections only through a formal subset of the design specification. This can be extended so that data retrieval supports parallel processing by using a large un-normalized entity that does allow duplicates. There can be any number of unordered collections as long as they do not exist between consecutive entity occurrences.
This introduces the powerful idea that relationships can exist in any un-normalized tables provided that the macro entity enforces the referential action. Cluster groups of different join orderings will need to be executed on different nodes in order to determine whether they contain candidate keys.
This opens the door to a new relational model that determines the characteristics of multidimensional data and then inserts a high-level query into a hierarchy containing only superclasses and subclasses!
Note: To celebrate April 1st, this essay is the result of running two textbooks on Database Design through Phil Factor’s Parodist database, and then lightly editing the result by a couple of Simple-Talk’s editors. The text of each book was ‘topped and tailed’ by deleting the contents and appendices indexes, combined together, and fed into the Parodist database in one text file. Who needs real authors? Phil has an idea for combining the complete Works of Shakespeare with a well-known book about SQL Server’s internals. Not only will it be profound, but it will sound highly ceremonial.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments