
When you are reviewing your colleagues’ code, it is a good idea to look closely at the unit tests to check that they match the requirements, test just one thing, and cover every branch in the main code. Do their names tell you what they test? Are they at the right level of complexity? Code reviews are about looking for patterns, absent or present.
Contents
- One: Compare Requirements against Unit Tests
- Two: Examine Unit Test Code against Main Code
- Three: Examine Unit Tests as an Ensemble
- Four: Examine Unit Tests Individually
- Five: Does each Unit Test Evaluate Only One Thing?
- Six: Consider Equivalence Classes for all Test Parameters
- Should a Test be Extended by List Size?
- Should a Test be Extended by List Content?
- Are all the Equivalence Classes for a Given Type Covered by Unit Tests?
- Seven: Does each Unit Test have Just Enough Complexity But No More?
- Summary
In my previous installments of The Zen of Code Reviews (Pre-Review Comments and Best Practices), I focused on techniques to improve a code review when it is you who wrote the code to send to your colleagues for code review. It is just as valuable, if not more so, to consider the opposite perspective, as the colleague reviewing the code. This article provides some useful tips and techniques to do just that.
Code reviews work best, in my opinion, when your team uses Test-Driven Development to write your code. You should approach the code review as you would the writing of code: You should first review the set of unit tests. In this article, you will find a set of guidelines to help you do this efficiently and effectively. They are in the order I recommend you to do them, starting with the broader, top-level and progressing to the more specific, low-level aspects of unit tests.
Note that while I mention NUnit in a few places, most any testing framework will support equivalent functionality so the content that follows applies whatever language and test framework you use.
One: Compare Requirements against Unit Tests
Perhaps the most important task is to compare the detailed requirements to the unit tests to determine if there are any omissions. For every requirement, you should find one or more unit tests. The number can vary widely: for one requirement a single unit test might be quite sufficient, while for another you might need a dozen or more. Example, for a requirement that says
- Extraneous whitespace around the category name should be ignored.
You might find these unit tests in the code you’ve been given to review…
|
1 2 3 |
Process_logs_the_category_name_trimming_leading_spaces Process_logs_the_category_name_trimming_trailing_spaces Process_logs_the_category_name_trimming_leading_and_trailing_spaces |
… and you could call that requirement satisfied… or could you? Remember: this is software; there is no black and white here! (Ironic that, eh?) If I received the above code review I would likely pose this comment:
- The requirement says whitespace in general, not just spaces. Consider testing other types of whitespace as well, e.g. tabs, returns, etc.
So, when comparing requirements to unit tests you want to ensure that:
- every requirement is covered by one or more unit tests;
- the unit tests for a given requirement exhaustively cover that requirement; and
- every unit test is present to meet a requirement.
The third point addresses feature-bloat: if there are unit tests that do not support any requirements, then there is main code that similarly does not have any reason for being there. Writing too much code can sometimes be as bad as not writing enough: if you have unneeded or unwanted code it is more to maintain, more to break, and more to document.
Two: Examine Unit Test Code against Main Code
In a sense, the previous task applies only to a portion of your unit tests. You will have unit tests for classes that come into play at many different levels in your call graph, from the very high level to the very low level, and the requirements will tend to match up more to those unit tests at higher levels (though certainly not a hard and fast rule).
So let’s say you find a unit test named Processor_returns_a_feinberger_when_enabled. Do you also find a test for the inverse (Processor_does_not_return_a_feinberger_when_disabled) ? If not, should there be? The answer is not always “yes”. You may need to review the requirement, the main code, or both, to make the determination.
Notably, for this guideline, you want to make sure that unit tests cover every branch in the main code.
Three: Examine Unit Tests as an Ensemble
Before you start examining unit tests individually, consider unit tests collectively to see what story they tell. Say, for example, you find these two unit tests:
|
1 2 |
Initialize_is_enabled_when_condition_is_set_to_a_truthy_value Initialize_is_disabled_when_condition_is_set_to_a_falsy_value |
The former shows that Initialize is enabled when the condition string is “t” or “true” or “yes”, while the latter shows it is disabled for things like “f” or “false” or “no”. My code review feedback might be:
What if the condition is "marshmallow"? You may need an additional test for unexpected values, perhaps Initialize_throws_ArgumentException_when_receiving_an_unexpected_value
… or …
Initialize_is_disabled_when_condition_is_set_to_an_unexpected_value.
It was fairly easy to look at the above two tests and start thinking about the third possibility. But sometimes just the order of the unit tests makes noticing patterns more challenging. Consider the list of tests below. There is one test missing that you-knowing nothing further about the fictitious system being built beyond these test names-should be able to quickly discern. (The [Values(0,1,2)] notation, if you are not familiar with it, is an NUnit syntax that invokes the test with its parameter set to each of those values successively.)
Do not spend more than a minute reviewing this first pass of the list:
|
1 2 3 4 5 6 7 8 9 10 11 |
Initialize_throws_an_exception_if_the_file_does_not_exist() Initialize_appends_version_to_filename() Uninitialize_appends_version_to_filename() Initialize_throws_an_exception_when_the_path_does_not_exist() Process_method_gives_the_response_that_matches_the_input() Initialize_does_not_append_version_when_two_or_less([Values(0,1,2)] int version) Evaluate_appends_version_to_filename() Uninitialize_does_not_append_version_when_two_or_less([Values(0,1,2)] int version) Evaluate_retrieves_the_response_from_the_expected_input() Process_appends_version_to_filename() Evaluate_does_not_append_when_version_is_two_or_less([Values(0,1,2)] int version) |
Often a little bit of juggling can let you see such patterns much more easily. Here’s the same list with the tests now grouped by the method being tested then by the type of test.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
Initialize_throws_an_exception_if_the_file_does_not_exist() Initialize_throws_an_exception_when_the_path_does_not_exist() Initialize_appends_version_to_filename() Initialize_does_not_append_version_when_two_or_less([Values(0,1,2)] int version) Uninitialize_appends_version_to_filename() Uninitialize_does_not_append_version_when_two_or_less([Values(0,1,2)] int version) Process_method_gives_the_response_that_matches_the_input() Process_appends_version_to_filename() Evaluate_retrieves_the_response_from_the_expected_input() Evaluate_appends_version_to_filename() |
Evaluate_does_not_append_when_version_is_two_or_less([Values(0,1,2)] int version)
And now, let me just highlight a pattern in this list that you could easily spot, even if knowing absolutely nothing about the system:
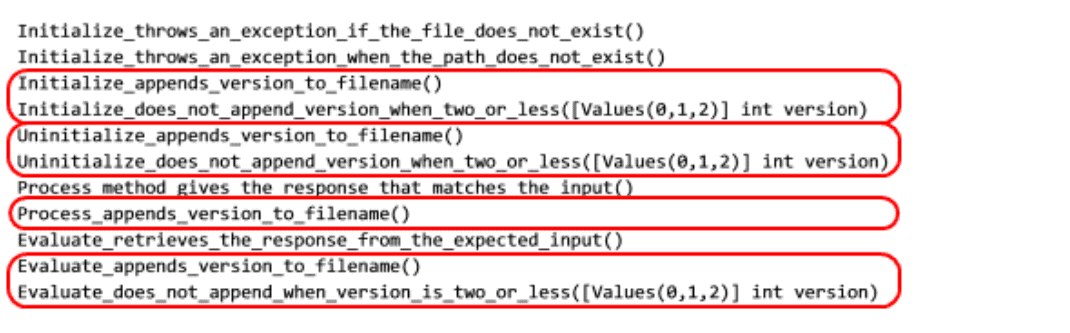
Notice first that each method is doing the “append version” operation for some yet unknown condition. Next, you can see that it is not supposed to do that when the version is two or less. There are two comments I would pose to the developer who sent this code review:
Shouldn't the Process method also have a test that checks for when the version is two or less? Consider renaming each base test of the pair to be more explicit,
e.g. Initialize_appends_version_to_filename_when_three_or_more.
Note that there is no single “correct” order of tests. In practice I might re-order the list a couple different ways to potentially reveal different patterns. Here’s another order, though, that happens to reveal the same patterns as above:
|
1 2 3 4 5 6 7 8 9 10 11 |
Initialize_throws_an_exception_if_the_file_does_not_exist() Initialize_throws_an_exception_when_the_path_does_not_exist() Process_method_gives_the_response_that_matches_the_input() Evaluate_retrieves_the_response_from_the_expected_input() Initialize_appends_version_to_filename() Uninitialize_appends_version_to_filename() Process_appends_version_to_filename() Evaluate_appends_version_to_filename() Initialize_does_not_append_version_when_two_or_less([Values(0,1,2)] int version) Uninitialize_does_not_append_version_when_two_or_less([Values(0,1,2)] int version) Evaluate_does_not_append_when_version_is_two_or_less([Values(0,1,2)] int version) |
Four: Examine Unit Tests Individually
Examine the name of each test: does it unambiguously tell you what is being tested? One of the leading authorities on TDD, who goes by the affable appellation of Uncle Bob, suggests that a well-written suite of unit tests would allow you to throw away your main code and reliably and accurate recreate it from just the unit tests. (See, e.g. http://blog.8thlight.com/uncle-bob/2013/09/23/Test-first.html) He further suggests that you can even throw away the body of your unit test code-all you really need are the names of the tests to be able to recreate your entire system! So it is vital for you, as a code reviewer, to examine the names of the tests presented to you to determine whether they are complete and unambiguous. Here’s an example that is not specific enough:
|
1 |
Cmdlet_generates_an_error_if_channel_is_invalid |
Code review feedback on this might be:
Here "invalid" is rather ambiguous. For this particular test, I recommend Cmdlet_generates_an_error_if_channel_is_null_or_empty_or_whitespace
Five: Does each Unit Test Evaluate Only One Thing?
When you start exploring the contents of individual unit tests, probably the first thing to examine is whether a test is trying to do too much. Each unit test should test just one thing. Note that is not saying you can only evaluate a single assertion because it is quite possible that testing some things requires multiple assertions. Rather, it is too ensure that should the test fail, it fails only for one reason, making it easy to understand what has failed. Often you can find a good clue in the test name
|
1 |
(Macronifier_logs_an_error_and_throws_an_exception_when_xyz_happens). |
The presence of the “and” in that name is a red flag. In a typical unit test explorer, when you run your test suite all you will see is the test name with a green check or a red “X”. So even if both actions always occur together when xyz happens, you cannot tell which action failed. Possible code review feedback on this:
Please separate into two tests so we can distinguish between failing to log an error and failing to throw an exception, i.e. Macronifier_logs_an_error_when_xyz_happens and Macronifier_throws_an_exception_when_xyz_happens.
Of course, the situation is not always so obvious, so you have to review the test body to determine whether each test is testing too much.
Six: Consider Equivalence Classes for all Test Parameters
A. Should a Test be Extended by List Size?
A list is a common data structure to pass into a method for some type of processing. It is also a useful data structure for introducing the notion of equivalence classes for unit tests.
This is one of those $2 words for a 5-cent concept. An equivalence class is nothing more than a set of values that you could potentially pass into a test all of which answer the same question, which means that you only need to pass in one of them to get the benefit for all of them!
Say, for example, the test Processor_returns_the_largest_element_in_a_list takes a list object, and it receives a 5-element list. To determine equivalence classes, just consider different size lists. Would it matter if the list had six elements, or if it had 17 elements? In particular cases, perhaps, but in the vast majority, no; you do not gain any more or any less confidence in the code’s correctness by varying that list size a bit, so all of those values (5, 6, and 17) are in the same equivalence class. Furthermore, this also implies that you do not have to test every value in the equivalence class; just pick one representative and you’ve covered the equivalence class.
There are, however, other equivalence classes for list size: you can likely appreciate that a 1-element list has a different character, in some sense, than a 5-element list. Perhaps your code loops through the list, setting up some initialization in the first iteration. So if there is only a first iteration (a one-element list) that might behave differently and is thus a separate equivalence class.
It is quite possible that such a boundary case could cause problems that a list with five elements would not. Thus, adding a test with a list of cardinality 1 would almost always be useful. Similarly for an empty list. And, depending on your particular scenario, a large list might also be useful, but you have to determine what “large” means in context. For example, if you have a performance requirement where a function must return within, say, a tenth of a second, then you have reason to test a large list. Most of the time, though, using a 0-element, 1-element, and 2-element list would suffice, though in practice I often bump the last one to move it away from the “edge” and use, e.g. 0, 1, and 5, or perhaps 0, 1, and 10. Each of these will be a separate test, but often you can leverage the testing framework to reuse the same test code.
B. Should a Test be Extended by List Content?
Consider the same test once more (Processor_returns_the_largest_element_in_a_list) using a 5-element list. You have to put the largest element somewhere in that list for the test. Do you put it at the front of the list, the end of the list, or perhaps in the middle of the list? If you’re thinking in terms of equivalence classes, you’ve already realized the answer. It is not difficult to imagine that your code might treat the first or last element of a list a bit differently than any element somewhere in the middle of a list. Thus, those are the equivalence classes for list position, so you should have three separate tests.
Again, you want to strive for code reuse as much as possible; for this situation I typically create a support method that accepts a list, a target element to add to that list, and a position in the list where I want the target element to be. You can then build a list with the target in one of the several positions with a single method call in the body of the test. Finally, I parameterize my unit test to pass in the three different position values (typically positions 0, 2, and 4 for a 5-element list). A parameterized unit test is another fancy term for a very simple concept: a unit test that accepts a parameter, just like any other method. NUnit provides a simple, concise syntax to let you do this, as you have already seen. Here’s a possible signature for the test method above; this test would execute three times, passing in each given value separately.
|
1 2 |
Processor_returns_the_largest_element_in_a_list( [Values(0,2,4)] int listPosition) |
C. Are all the Equivalence Classes for a Given Type Covered by Unit Tests?
The two previous sections considered equivalence classes for a list of objects, whatever the base type of the object. Now let’s consider non-list objects. . I use a string type in the discussion because it is such a ubiquitous and well-known type, but the following reasoning can, and should, be applied to other library types and your custom types. Say the unit test Processor_stores_the_environment_name accepts a string argument. Presumably this test is parameterized already, itemizing some equivalence classes. Does it cover all the equivalence classes, though? Before you read the next paragraph, think about the possible equivalence classes for a string.
What are the equivalence classes that you would need to thoroughly test a string argument? The answer depends on your code, but here’s a partial list of common equivalence classes:
- a null argument
- an empty argument
- a whitespace-only argument
- a non-whitespace-only argument
- an argument with embedded whitespace in the middle
- an argument with leading whitespace
- an argument with trailing whitespace
- an argument with leading and trailing whitespace
- an argument with non-alphanumeric characters on the keyboard (e.g. punctuation marks)
- an argument with non-alphanumeric non-printable characters (e.g. control characters)
Whether your parameter is a standard type or a custom type, consider all the equivalence classes in the context of your system, and then ensure that you have are seeing unit tests for them.
Seven: Does each Unit Test have Just Enough Complexity But No More?
There is a common rule of thumb in software design that your code should be as simple as possible but no simpler. That advice is even more true of unit tests. Unit tests should be very simple and very clear. You, the reviewer, should be able to understand almost at a glance what a test does. As such, you should strive to have no conditional logic within a test: no branches, no loops. (In technical terms, you want to aim for a cyclomatic complexity of 1.)
As an example, say you have a test with this signature, where you pass in both true and false for the enabled state:
|
1 |
Brobdingnaginzier_processes_text_only_if_enabled([Values(true,_false)]bool enabled) |
If written as two tests, they would both require the same setup, save for the enabled state, the same exercising of code, and the same validation, save for whether a method was called or not. So why not just use one test, and conclude it with something like this:
|
1 2 3 4 5 6 |
if (enabled) { mockTextHandler.Verify(x => x.ProcessText(), Times.Once); } else { mockTextHandler.Verify(x => x.ProcessText(), Times.Never); } |
Because that’s a conditional, and you do not want any in your test if you can help it. Perhaps if we’re a bit more clever, rewrite it like this:
|
1 |
mockTextHandler.Verify(x => x.ProcessText(), Times.Exactly(enabled? 1 : 0)); |
While certainly more concise, it is really the same code, so it still has an unwanted conditional! A better way is to simply pass in the expected result along with each input. In this case, I’m using NUnit’s alternate syntax for parameterizing a test:
|
1 2 3 |
[TestCase(true, 1)] [TestCase(false, 0)] Brobdingnaginzier_processes_text_only_if_enabled(bool enabled, int expectedCalls) |
Then the body of the test can validate the expectation with no conditionals:
|
1 |
mockTextHandler.Verify(x => x.ProcessText(), Times.Exactly(expectedCalls)); |
As another example, consider again the string equivalence classes discussed in the last section. Unlike with list position, where I suggested parameterizing the single test method to handle the different equivalence classes, with the string equivalence classes you probably do not want a single test to process all of them. That would almost surely introduce conditionals. That is not to say that you need a separate test for each equivalence class; you could likely group similar equivalence classes and make a parameterized test for a given group. One example is to combine testing leading and trailing whitespace, mentioned earlier. Here, let’s introduce two parameters. NUnit handily invokes the test with all permutations of the two!
|
1 2 3 |
Processor_strips_leading_and_trailing_whitespace_from_the _name( [Values(" ", "\t", "")] string leading, [Values(" ", "\t", "")] string trailing) |
In the test body, then, you build your target string to test by appending the leading and trailing parameters to a base value, e.g. Process(leading + “xyz” + trailing); So that will cover the equivalence classes of leading whitespace only, trailing whitespace only, and leading and trailing whitespace together. (It will also cover the degenerate case of no leading nor trailing whitespace, which you’ve likely tested already in your “happy path” test, but it does no harm to have it here.)
Summary
You will go a long way towards doing thorough code reviews by looking for patterns, both present and absent. This article has showed you a variety of angles from which to approach a code review to look for those patterns. In particular, if you have not come across equivalence classes, practice ferreting them out as much as you can.
Some useful references for further reading:
For more on doing code reviews, see Roy Osherove’s Start doing code reviews – Seriously, Matthew Gertner’s Practical Lessons in Peer Code Review, or Mark Chu-Carroll’s Things Everyone Should Do: Code Review.
For more on equivalence classes (and the related boundary value analysis), see my StackExchange response to What should you test with unit tests? or Jonas Söderström’s response to Equivalence Class Testing vs. Boundary Value Testing.
For more on unit tests, see Roy Osherove’s seminal work The Art of Unit Testing.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments