
TL; DR Your JavaScript code is single-threaded in the same context, but all other stuff which is done by browser (AJAX request, rendering, event triggers etc.) is not.
The execution of any JavaScript program can be divided into two separate parts:
- The Initial execution of the code that takes place during page load
- The subsequent event-handling
Initial code execution
We have, for example, a web page with some inline JavaScript code and a few references to JavaScript libraries. How JS code executed on this page? The browser loads the web page and ‘sees’ a reference to a JavaScript file. When this file is loaded, we could imagine that this JS code is wrapped within an anonymous function. This imaginary function has a global scope as its own function scope and is self-executing. We could imagine it as the following piece of code:
|
1 2 3 |
(function () { // JS file content goes here })(); |
The next example shows us that JavaScript code is executed as soon as possible after the inline element or file reference is found, and so it doesn’t wait for the creation of the DOM tree to be completed (JSFiddle link):Inline JavaScript code is executed in the same manner, but without the file loading phase. It is important to know that, during this code execution both the creation of the DOM and the rendering of the page is paused. As a result, the user sees a blank page and needs to wait.
|
1 2 3 4 5 |
<script> var divElement = document.getElementById('someId'); divElement.innerText = 'Hello, world!' </script> <div id="someId"></div> |
Another way to handle JS file loading is to use “async” and “defer” attributes for the script element. If you don’t know about these attributes or want to know a little bit more about how to load external scripts, please read this great article.As you can see, we are trying to access a division element (DIV) that is placed after the script block. In this example we will get an exception because the divElement variable is null. To avoid JavaScript code trying to access unreachable DOM elements, you will definitely need to place your code at the end of the page or at least execute it after page is loaded.
Event loop
Initial code execution ends once the page is loaded and the initial JavaScript code has run, all event handlers are attached, all AJAX requests are sent and our observables are observing. Why then shouldn’t we just handle all the events we are subscribed to in old-fashioned parallel way? The reason is that we don’t want to change the DOM in parallel: this is because the DOM tree is not thread-safe and it would be a mess if we tried to do it. Because of this limitation, all our JavaScript code should be executed in single thread, while at the same time ensuring that it handles all the events and doesn’t lose any callback. For these reasons we come to the Event loop.
The event loop can be imagined as the following process flow:
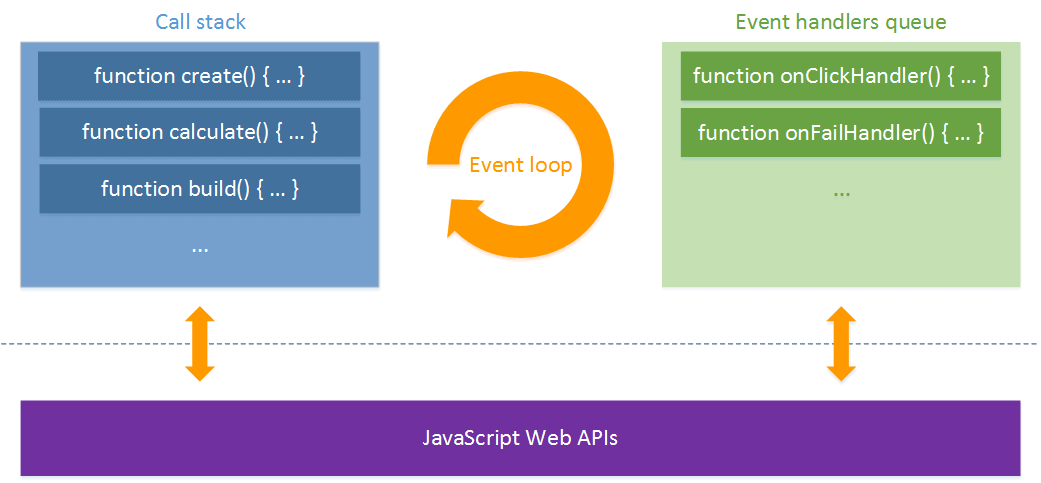
As described in the picture, the main parts of JavaScript Event loop are:
- The Call stack, which is a usual call stack that contains all called functions.
- The Event handlers queue, a queue of event handlers that are waiting to be executed.
- The Event loop, which is a process that checks whether events handlers queue is not empty and if it is – calls top event handler and removes it from queue.
- The JavaScript Web APIs: those APIs that are provided by the browser that are responsible for filling the Event handlers queue, providing many features such as the ability to make an AJAX request and e.g. the implementation of Mozilla has a great documentation about Web APIs and it could be found by the link.
Each window or WebWorker has its own event loop. We could imagine that each JS context wraps all code with the following piece of code:
|
1 2 3 4 5 |
while (true) { if (eventHandlersQueue.isNotEmpty()) { eventHandlersQueue.processTopEventHandler(); } } |
But why isn’t the page responding during JavaScript execution?Of course, the Event loop model as described is a very simplified abstraction of what is actually happening under the hood of a browser. The real implementation could vary from browser to browser, but the main principle is the same. If you want to get more precise information about the Event loop, you could read the corresponding section of WHATWG HTML specification, which you can find by the link.
So far, I’ve described how our JavaScript code is executed during page load, and how the different events are handled by the Event loop. Also we know that we don’t want to change DOM tree in different threads. But what about this piece of code (JSFiddle link):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
function calculatePi(numberOfIterations) { var pi = 0, n = 1; for (var i = 1; i < numberOfIterations; i++) { pi = pi + (4 / n) - (4 / (n + 2)); n += 4 } return pi; }; blockUIButton.onclick = function () { calculationResult.innerHTML = calculatePi(1000000000); } |
This is all because of reflows. Reflow is a process of recalculation of each element position, style and any other characteristic that is required for proper rendering of the page. It is triggered by adding new DOM element, doing a window resize or making changes in element styles from JavaScript. This reflow process is complex and could significantly slow page render. But it would be even worse if, after each reflow, we had to render the page. In this case, the user would have seen all the steps of page building till the final result but we don’t want such behavior. I have created a small test to show how reflows are causing bad performance, which you can find it by this link.During this code execution, the page is blocked so that the user cannot interact with the page. Some browsers even ask the user to either wait until the page ends its calculation or just kill the process.
One more thing worth mentioning is that page render has higher priority than any handler waiting in the Event handler queue. The Browser tends to render page 60 frames per second or, in other words, one frame approximately each 16 milliseconds. When the call stack is cleared, the browser checks whether it is time to render the page: only then does it check the Event handler queue. Taking into account this new information our, abstractly-coded Event loop is extended with a render-related check:
|
1 2 3 4 5 6 7 8 9 |
while(true){ if(renderEngine.isItTimeToRender(){ renderEngine.render(); } if(eventHandlersQueue.isNotEmpty()){ eventHandlersQueue.processTopEventHandler(); } } |
On desktops, it is hard to notice the render part of the event loop, but it could be noticeable on mobile devices where resources are more limited.
What about asynchronous code in JavaScript?
All asynchronous code in JavaScript is based on Web APIs that are provided by the browser. These vary on functionality and purpose, but all of them provide the possibility of executing a callback function. We could distinguish two groups of such APIs.
The first big group comprises the APIs that fires a callback after some work is done. It could be handling AJAX request, an onload handler within the DOM or maybe a web worker response. The callback is fired as when something changes, and the purpose of this callback is to react on this changes. When a callback must be executed, it is added to the Event handlers queue.
The second group includes the setTimeout(callback, time) and setInterval(callback, time) functions. For those who never faced these function I should explain:
- setTimeout – runs a callback once after specified amount of time
- setInterval – runs a callback at a specified time interval
These functions are not reacting to changes, but just running our code. One of their main purpose is to provide us the means of breaking synchronous execution into asynchronous parts. It is important to remember that these functions don’t guarantee that callback will be executed after the amount of time that you specify. They do guarantee that callback will be added to the Event handlers queue, but, as we know, it could already have handlers waiting for execution. So, “time” argument should be treated as “not earlier than, but after the specified time”.
How to achieve parallelism in JavaScript
I’ve already mentioned that JavaScript is single-threaded in the same execution context. Because of that we have two options to achieve parallelism in JavaScript.
The first one option is pseudo-parallelism based on setTimeout function. Its main idea is to unblock user interaction with the interface, but, at the same time, execute logic that is needed to be executed. This approach is based on breaking execution into parts. The following code demonstrates an implementation of this approach (JSFiddle link):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
function appendResult(result) { var div = document.createElement('div'); div.innerText = result; results.appendChild(div); } function calculatePi(pi, n) { for (; ; n += 4) { pi = pi + (4 / n) - (4 / (n + 2)); if ((n - 1) % 20000000 == 0) { appendResult(pi); setTimeout(function () { calculatePi(pi, n + 4); }); return; } } } startCalculation.onclick = function () { calculatePi(0, 1); } |
The second option is to use WebWorkers. WebWorkers represent the concept of parallel threads in JavaScript, but with some limitations:In this example, the calculation is divided into separate blocks so that the user could interact with the interface between the executions of these blocks.
- It isn’t possible to access DOM elements inside the web worker instance. Actually you are forbidden to pass any kind of reference to the DOM structure and its related functions.
- Communication with the worker is based on messages via the postMessage() method and “message” event.
- There are no window, document and parent objects inside the worker.
All these limitations are added to block any possibility of changing the DOM, which isn’t thread-safe, from inside the workers. The main usage of workers is for heavy background calculations. The following example shows how to use a worker for π calculation (JSFiddle link):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
// Some magic to run function as WebWorker var workerBlob = new Blob(["(" + worker.toString() + ")()"], { type: 'text/javascript' }), workerInstance; startButton.onclick = function () { if (workerInstance) { workerInstance.terminate(); } output.innerHTML = ""; workerInstance = new Worker(URL.createObjectURL(workerBlob)); workerInstance.onmessage = function (e) { output.innerHTML += "<div>" + e.data + '</div>'; }; workerInstance.postMessage(null); }; function worker() { onmessage = function (e) { var pi = 0, n = 1; for (var n = 1; ; n += 4) { pi = pi + (4 / n) - (4 / (n + 2)); if ((n - 1) % 200000000 == 0) { postMessage(pi); } } }; } |
If you need to process a big amount of data or to make some heavy calculations and there is no need to support the old versions of browsers, then I would recommend you to use WebWorkers, because of their performance and real implementation of parallelism. But, if you just need to handle a collection of objects and you can sacrifice some time to unlock interface for user interaction, then you can use pseudo-parallelism based on setTimeout. I have prepared a small performance comparison that you can play with by the link.During worker execution, the main Event loop is never blocked; it is only handling message results.
Conclusion
Answering the question, JavaScript is single-threaded in the same context, but browser Web APIs are not. Also we have possibility of simulating parallelism by using setTimeout function or, with some limitations, by the use of the real parallelism provided by WebWorkers.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments