

Since its introduction in 2013, Docker and containerization has grown in importance as a technology. This is primarily because of the growth of the popularity of agile methodology and microservices architecture.
There are several examples in the industries where the Docker is leveraged for the deployment of the micro-services within a micro-services architecture. Any rapid change to the functionality becomes easier and faster to deploy due to the small unit of services and due to Continuous Integration (CI) tools such as Jenkins or Atlassian Bamboo. Continuous Integration tools can build and deploy Docker images across the application environments very easily. Builds can be automated and also can be monitored efficiently using CI administrator console.
This article is about the how an enterprise can leverage containerization and container management solutions, especially the deployment of micro-services. In this paper, we cover the “What, Why and How” questions about Docker design, implementation and governance. In Section 2, we discuss the problems solved by Docker. Section 3 explains the overall Docker architecture. In Section 4, we highlight the key parts of Docker solution:
- Micro-services based architecture and design
- Cloud based deployment
- Docker-based containerization for micro-services
- Docker Container orchestration solutions
- Governance
In Section 5, we give an account of our own experience in implementing Docker for an enterprise in detail. In Section 6, we describe the key business and technical challenges in the implementation and Section 7 summarizes the best practices to overcome these challenges followed by conclusion of the document.
Why Docker?
Docker solves the problems of rapid dynamic scaling, testing the image of the application across multiple test environments, hosting micro-services and rapid development environment set-up and infrastructure optimization. The points are illustrated below.
- Dynamic scaling – The architectures for many of the well-established sites are no longer fit for scaling dynamically and rapidly to meet the needs of sudden surges in demand. Ideally, the architecture must support being able to scale-up or scale-down within seconds. Whereas Virtualization allows rapid scaling out by adding new Virtual Machines in minutes, a Docker-based Virtual Machine can be scaled out in a matter of seconds. As we have already mentioned, many companies such as gilt.com have shown that it is possible to use Docker for achieving dynamic scaling.
- Seamless Testing – A Docker image has the layers of application image plus the server image. The same exact Docker image will be tested in dev, functional test and non-functional test (pre-production) environments. Because the Docker image has the server image as well, there is no question of having different server versions in dev and test environments. It solves the problems of “it is working in dev server but not in test servers” because the Docker image holds not only the exact same server image but also the application image, thereby avoiding any version mismatch problems.
- Hosting micro-services – The micro-services architecture works well with lightweight containers. It promotes the stateless services. The micro-services can be hosted in lightweight servers such as Tomcat or Jetty, and can be hosted in the Docker container.
- Rapid Development Environment Set-up –A DevOps team can create Docker images of the standard development environment (Eclipse, Tomcat, MySQL database for example) and developers can quickly set up the development environment in few hours by downloading the Docker images from the Docker hub.
- Infrastructure Optimization – Docker has much less overhead than a full-fledged Virtual Machine. Though Docker can be deployed on bare metal with Linux OS, many of the consumers already have adopted Virtualization technologies and already have Virtual Machines for deploying the applications. Docker containers complement Virtual Machines technology and can even be hosted inside Virtual Machines. Bu using Docker containers, one can create an optimized infrastructure with fewer VMs to manage, with more Docker containers for every VM. Because Docker is based on the design of the Linux container, the same operating system on the VM can be shared by the Docker containers thereby increasing the density of the infrastructure.
A successful Implementation
Gilt.com, an online retailer in the USA, has adopted Docker and has used it successfully to handle the dynamic growth in its customer base. The Gilt.com website used to be monolithic Ruby-on-Rails application in 2007. When the online traffic to the site increased, the site started to face problems of scaling. The site was also fragile: any software crash resulted in the entire site experiencing failure resulting in considerable business loss. In 2011, Gilt.com changed the solution to a Java/Scala based architecture that was loosely coupled. In 2015, Gilt.com then re-factored the services into numerous micro-services and automated their deployment process by using Docker containers on AWS cloud. Gilt.com specializes in flash-sales of its brands and the traffic has sudden spikes due to the customers grabbing sales. The Docker-based deployment allows Gilt.com to change the number of containers (application images) dynamically to cater to the spikes in the load.
Docker Architecture
Docker follows client-server architecture. Docker architecture has 2 tiers – client and host (server) as shown in the diagram below. The Docker client issues Docker commands to pull, build and run Docker images. Docker images are stored in a Docker registry for an enterprise. The images are downloaded by Docker daemon from the registry into the host. Docker daemon runs the images by creating the Docker containers in the host.
Docker Client Definition
Docker client is a client process that talks with Docker daemon (or container/server) process. Docker client can reside on the same machine or can reside on some other machine with network connectivity to Docker daemon. Docker client sends various Docker commands lsuch as pull, build, run to the Docker daemon or Docker container process.
Docker Server (Container) Definition
Docker container is the server process that does all the heavy lifting, and is also known as Docker daemon. The main tasks of the Docker daemon are as follows-
- Downloads Docker images from Docker Registry (or Hub)
- Creates Docker Containers
- Manages Docker Containers (Start, stop, remove)
Deploying micro-service using Docker Container
Micro-services are built using a tool such as Docker maven plugin. The Docker image is pushed to Docker Trusted Registry (DTR).
Architecture for Docker platform for Web based Solution
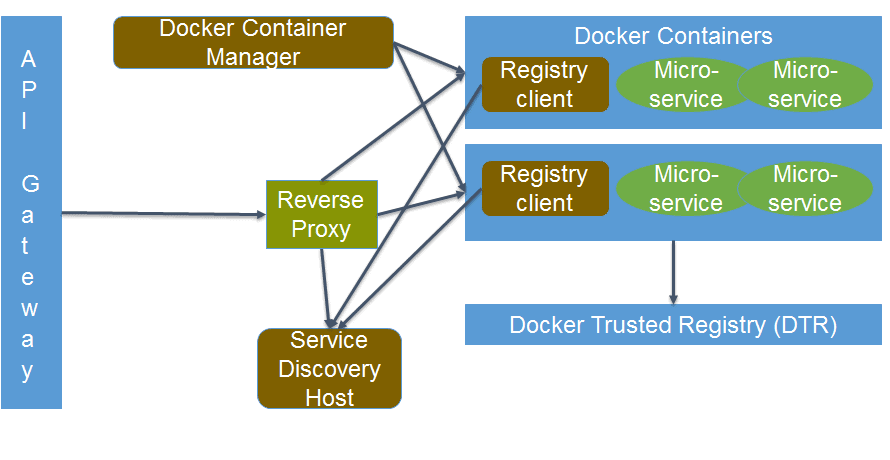
Architecture for Docker for Web based Solution
Docker Trusted Registry – Repository of images
Docker Hub stores the Docker images. Many enterprises hold Docker Trusted Registry or Docker Hub privately for enterprise security. Because many Docker images contain application logic that contains business logic that is proprietary to the enterprise and hence needs to be kept inside the enterprise hub. The registry maintains various versions of the images thus aiding the version management for the services.
API Gateway
The API Gateway acts as the central point of entry for all REST services for the enterprise. It can act as a first-line of defense to offer security for the containers. It also audits and routes the requests to the reverse proxy. It helps in the API management and governance of the Docker-based solution.
Reverse Proxy
Server such as Nginx or HAProxy can be used as a reverse proxy. It can be easily configured to discover the services dynamically and route the requests to the services.
Service Registration
The services need to be registered. Because new instances of the service can be started, the service needs to register it using a service-registration tool such as ETCD or Consul. Container Management tools such as Kubernetes have the ETCD in-built service registry component. The separate service registry component like Eureka can be used for service registration with Amazon Web Services (AWS) cloud.
Service-discovery
In Docker-based micro-services deployment, there has to be a service-discovery mechanism. Due to containerized deployment, the location (host and port) of the service can change dynamically and hence the clients need to discover the services running dynamically. There are plugins available for service-discovery in the market. There are two discovery mechanisms available as stated below-
- Client side discovery – Clients need to have a service-discovery component that discovers the location of the service from the service registry. Ribbon client from Netflix is a client discovery component that queries the service registry using a remote procedure calls (RPC) mechanism and it has a built-in load balancer as well in order to balance the load amongst the service instances.
Pros:
- It reduces the network hops because the client directly discovers the services.
Cons:
- Every client (Java, non-Java) needs to have a service-discovery mechanism, which increases the client code.
- It also couples the client to the service registry.
- Server-side discovery – The clients sends the request to a common service-side discovery component that discovers the services dynamically, and routes the calls balancing the load. AWS Elastic Load Balancer (ELB) is an example of service-side discovery component.
Pros:
- The client code is simpler to maintain as it does not have its own discovery mechanism.
- The centralized code for discovery at server-side is easier to maintain.
Cons:
- It causes more network hops because the client component needs to talk with the server router for discovery.
- The service-discovery component must be replicated for high availability and scalability with other components.
Container Management tools
The containers can be orchestrated using the tools like Kubernetes or Docker Swarm. Container management tools are extremely important in the world of containers. The containers can be started, stopped and scaled up and down using these tools. For the sake of brevity, this paper discussed only Kubernetes and Docker Swarm, although there are many more container managers such as Rancher and Mesos that are available in the market. Docker Swarm has evolved rapidly in 2016, making it a competitive choice to Kubernetes. Below is the brief comparison of Kubernetes and Swarm.
|
Criteria |
Kubernetes (k8s) |
Docker Swarm |
|
Simplicity |
Complex to install and configure as it has many moving parts (Replication Controller, Kubectl, Kubeproxy, pod etc.) |
Simpler installation process using Docker commands. It has fewer moving parts and load balancing, TLS security for authentication, authorization and encryption. |
|
Coupling with a range of container technology for orchestration and scheduling |
Generic cluster management solution works with Docker, rocket etc. |
Tightly coupled with Docker container only |
|
Learning curve |
Moderate to High |
Low to medium with familiarity with Docker |
Security
Trusted Container Images and Deployment
Since Docker 1.8 there has existed a concept called Content Trust[7] . It uses the developer’s private key to sign the images and when the images are downloaded they are checked against the developer’s public key to ensure authenticity. It is a good idea to integrate this mechanism into the continuous build and deployment process.
Encrypt secrets
Secrets include any information that you would not want to leak out to unauthorized agents, but are required by the container to access external resources. Secrets can be bundled in the manifest or can be injected into the containers as runtime environment variables.
The secrets could be optionally encrypted using some encryption libraries such as EJSON, Keywhiz, Vault and similar libraries.
Enhance container security
A compromised container can make the host equally vulnerable to security breaches, so we suggest that you need to enable Security Enhanced Linux (SELinux) or SVirt. Alternatively, you can use the “cap-drop” switch while running Docker containers [6] to restrict the capabilities of the container. Also there are products such as Twistlock for maintaining container security.
Secure Container Deployments
A Standard benchmark – CIS Docker Benchmark [8] can validate whether the Docker containers follow the best possible security guidelines. Docker Bench is an automated program that can be used to validate against this benchmark.
The Docker security deployment guidelines [9] will provide the information to secure the Docker container host and is a useful resource to secure the environment running Docker containers.
Infrastructure and Operations Management
Docker stats command
Docker provides a rudimentary command-line utility to get some basic statistics of a running container. You can run Docker stats command with the name of the containers and it returns the memory, CPU and network usage by the containers.
Pros:
- It is free
- Built into Docker process itself
- It also has a remote API that be accessed via a REST GET call. /containers/[CONTAINER_NAME]/stats. It is very handy in basic situations
Cons:
- It needs additional scripting in case you need detailed analysis
- No aggregation is provided by default
- There is no alerting facility
CAdvisor
If the resource-consumption statistics are needed in a good graphical representation, the CAdvisor tool comes in handy.
Pros:
- It is free and trivial to set up
- CAdvisor has a slick browser interface that provides basic drill-down facility. Additionally, it also shows any limits placed on the container
- There is no need to SSH in to the servers
Cons:
- This offers very basic aggregation
- Good for single Docker host and difficult to synchronize with multiple Docker hosts
- There is no way to raise alerts or to monitor non-Docker resources
Prometheus.io
This is an open source framework for system monitoring and alerting. It can ingest data from a large spectrum of sources, one of which is Docker containers.
Pros:
- Free open source.
- Can monitoring various number of Docker and non-Docker resources.
- A highly configurable and functional inbuilt alerting system.
- Great visualization user interface.
- Provides a rich functional query language.
Cons:
- It is complex to deploy and configure Proemetheus in a cluster.
- There are lot of configuration options and takes some learning to get acquainted with it.
Sematext
Monitoring services runs a separate container and is capable of monitoring multiple servers.
Pros:
- Capable of co-relating metrics and identifying anomalies.
- Large set of out-of-the-box dashboards and graphs.
- Built-in anomaly detection, threshold limit configuration and heartbeat alerts.
- Integration available with Slack, Chatbot etc.
Cons:
- Paid/Licensed tool.
- It Needs a bit of learning to get used to its configuration options.
Case Study
This section provides a real-world example of an application. The application was developed as an on-premise solution in early months of 2016 and was being marketed as such. Later there was a need from multiple prospective customers to make this application available on cloud and also make it such that it should be easy to create an on-premise version deploying the application in several instances for different departments within their business
The following is a pictorial representation of the requirement matrix that was created for the deployment requirements of the application.

Since the application was already developed, and it would have taken enormous effort in terms of time and money to rewrite it to satisfy the above requirements, the decision was taken to architect the deployment of the application by using containerized approach. Docker, being the de-facto standard when using containers, was chosen as the container technology to be used for packaging and deploying the application.
Application Deployment View Prior to Containerization
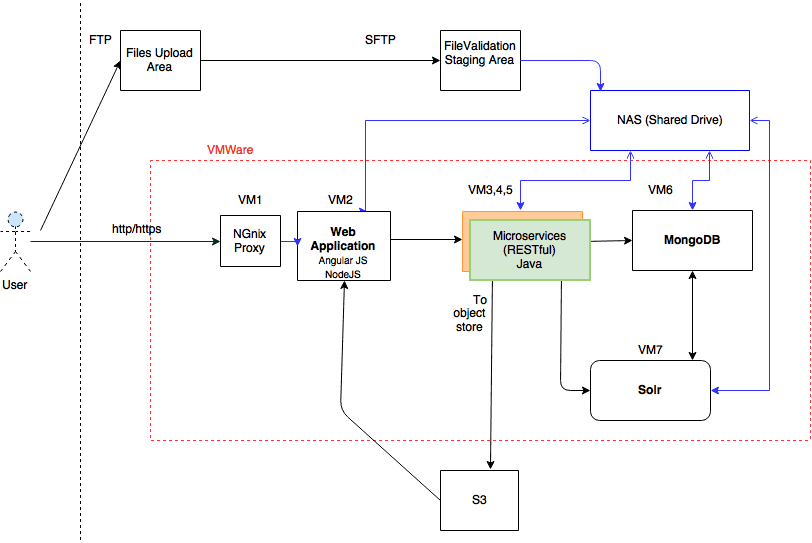
The following process was followed to re-architect the application to a containerized stack for deployment.
- All the application components shown above were converted to Docker containers using new build scripts. Docker’s traditional Dockerfile syntax was used to package all the application components into separate Docker containers.
- A local Docker registry was created to store the Docker images that were built locally.
- Jenkins nightly-build pipeline was updated to use the new Dockerfile build scripts and push the generated images to the local Docker registry.
Here is a pictorial representation of this new process
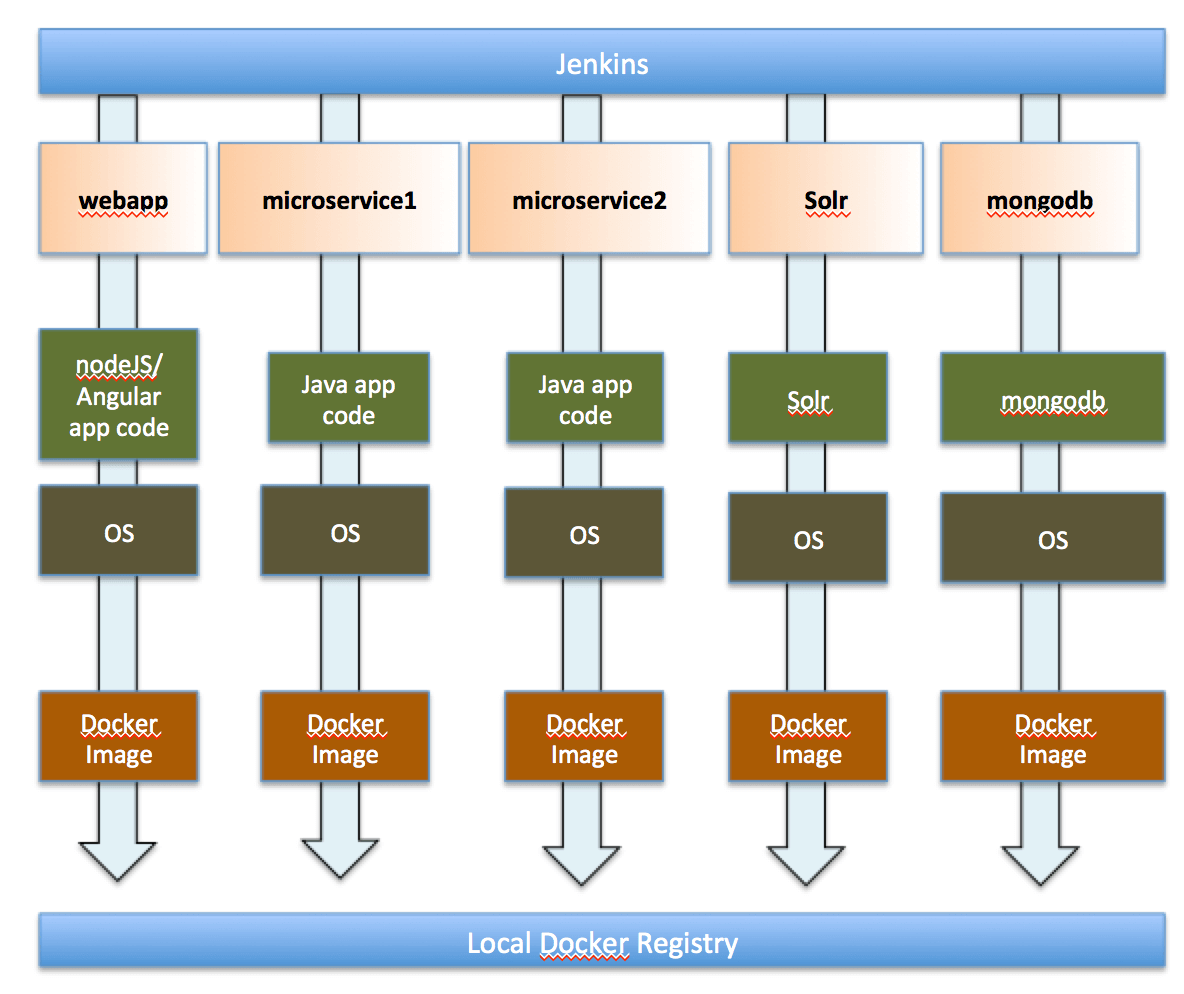
The changes to allow the creating and storing the application components as Docker containers was completed in the first phase of the re-architecting.
The next part that we had to handle was inter-container communication and other requirements listed above seamlessly. Though Docker allows us to isolate the process to different nodes and makes it easier to upgrade/deploy the application, it is tricky to make multiple Docker containers talk to each other. There needs to be some amount of configuration overhead required.
This was a good time to start thinking of using some container management framework. At the time this was being done, two container-orchestration frameworks were being evaluated viz. Docker Swarm and Kubernetes. Due to the proven production stability in early months of 2016, Kubernetes was chosen as the container orchestration framework. The following few top features of Kubernetes satisfy most of the requirements in the matrix above.
- Kubernetes Cluster – It facilitates the high availability of the containerized applications. Master acts as coordinator and the nodes (or VMs) where the application is deployed act as workers.
- Namespaces – this is a logical group of elements in Kubernetes. This allows us to logically separate the whole application from another instance of the same application, thereby making multi-tenancy easily achievable.
- Persistent Volumes – Kubernetes allows us to abstract the actual data storage from the running application via Persistent Volumes. The administrator can decide on the actual provider for data storage (NFS etc.) and Kubernetes will mount the required volumes to the containers.
- Services – This is a logical abstraction to the actual physical service running on a node. This allows the clients to seamlessly connect to the service without being aware of the actual node or port where the service runs.
- Service-discovery via KubeDNS – KubeDNS plugin allows service-discovery based on Fully Qualified Domain Name (FQDN). An application component can look-up another application component using a FQDN without actually knowing the IP address of the nodes.
- Pod – This is a group of tightly coupled Docker containers that will be deployed as a single unit on the host. Scaling is enforced at the Pod level.
- Replication Controller – This is an entity in Kubernetes which is responsible for ensuring that the application components can be scaled individually and are always available as needed.
- Rolling Upgrades – Kubernetes allows for rolling upgrades with a zero downtime for the services.
The application deployment architecture after using Kubernetes/Docker was as below
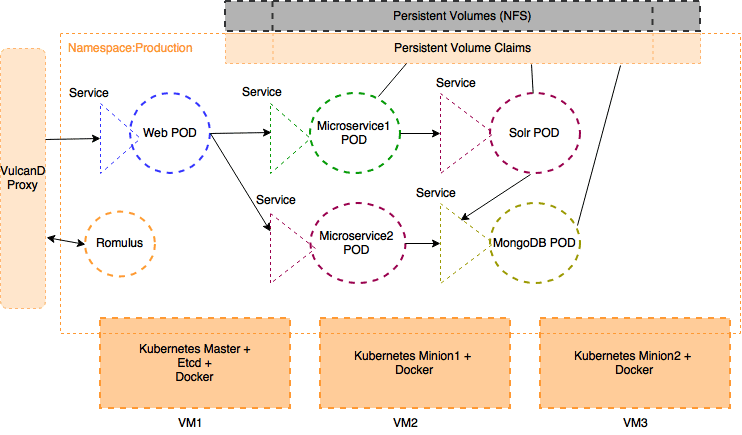
Some highlights of the application after the new deployment architecture
- The application components now run as Docker containers. Kubernetes decides which nodes those components would run on. All components run on an internal Docker private network not accessible by anyone outside this private network thereby securing the whole application in one go.
- All components are exposed by defining Kubernetes services. Routing between components was handled by Kubernetes via the KubeDNS and KubeProxy services.
- Vulcand was chosen as a reverse proxy as it integrates nicely with Kubernetes in an on-premise situation. Romulus is freeware which will auto update entries in Vulcand to route the external requests to the correct service.
- We could now easily deploy another instance of the application in a different namespace but using the same hardware (provided that the hardware has enough resources). So even if the application code is not multi-tenant, the deployment made it easier to deploy it in a “pseudo” multi-tenant fashion by using the same code base, same hardware and same point of access. Vulcand took care of routing the requests looking at the FQDN to the correct tenant.
- It became extremely easy to scale individual application components on-demand. The Replication Controller associated with each Pod allowed us to scale individual components in no time.
- Via the user of Persistent Volumes, all of the state of the applications was stored on the shared storage. So, in the case of a container crash, the data could still be recovered from the shared storage and be provided to another instance of the container.
This is a list of components used in the new deployment architecture.
- Docker 1.9
- Kubernetes 1.2 with all its required services (etcd,proxy,controller etc)
- KubeDNS
- Vulcand
- Romulus – To auto-update frontend proxy entries based on application components services
- Docker Trusted Registry (DTR) – to store Docker images
Challenges of implementing Docker
Implementing Docker is faced with many challenges which all stakeholders including business users and technical IT team should be aware of.
Business Challenges
- It may be hard to quantify the benefits of Docker from the perspective of the business users. If the site needs continuous integration and faster delivery, Docker, together with orchestration, will be justified; but there must be strong business case to justify the adoption of Docker.
Technological Challenges
- Docker containers provide lesser isolation than a VM-only solution. Since containers share the same OS kernel, any malware that affects one container can affect the host VM, and other containers running on the same VM.
- It is difficult to make suggestions about appropriate implementation to the customers because the Docker ecosystem is evolving so rapidly.
- Docker Monitoring tools (Docker Log Collector with basic facilities, Dynatrace, Datadog etc.) are available in the market and it involves a degree of learning to compare and leverage a right tool for your IT estate.
Best practices for implementing Docker-based solution
These suggestions need to be considered in the light of the needs of the enterprise.
Keep Docker Containers simple
- Keep the container image simple by minimizing the number of file layers for each container. The containers should be easy to start and stop, or to create and delete. Also, DevOps administrators should try to keep the size of the image small by including only the required dependencies in the Docker image.
- Architect the solution to run only single process per container. E.g., for typical n-tier web application, it is prudent to have separate Docker containers for User Interface, business services and database for better scalability and maintainability
Leverage Clustering tool like Docker Swarm/Kubernetes with Service-discovery
- A Docker container by itself is not much use for an enterprise. It should be used with the clustering tools like Docker Swarm or Kubernetes along with service-discovery tools to harness the full benefits of the Docker solution
Secure Docker Images
- Follow infrastructure security best-practices to harden the host on which container is running.
- Docker containers holding the application image should be shielded from the external world.
- Container hardening products such as Twistlock Trust can be leveraged. These products scan the images and registries to detect code vulnerabilities and configuration errors based on the CIS Docker benchmark.
Monitor containers using tools
- Label containers with proper names to organize the containers by the purpose
- Set resource limits on the Docker containers
- Leverage Docker monitoring tools like Google cAdvisor or Prometheus.io for production monitoring
Enhance builds and deployment scripts
- Builds should not only build the code but also create Docker images for the application
- Build scripts should use a base Docker image from a standard local registry and build new Docker images taking that as the base image
- All built Docker images should be appropriately tagged with the build number and uploaded to the registry. This way it becomes easier to deploy any version of the build without doing a rebuild for that particular tag
Take a “container first” approach to development
- This means that all projects must build and release software as container images
- It is highly recommended to even use the containers to do a local deployment on development machines for individual testing needs
- Using Docker containers for the whole development setup drastically simplifies the development setup for any new team member. Additionally, there is no special need for documenting the detailed steps of how and what to setup for getting the development environment up and running. Just provide a link to the Docker registry and a couple of commands to download the Docker images and run them. The development environment will be up and running in very less time
Standardize base images
- Docker images should not be created from scratch. All projects should utilize the base Docker images available on the public Docker registry if possible and use them as standardized base images
- However, if required, organizations should create images as per their needs and tag them as base images to be used by all development teams. It is mandatory for the reliability of the containers that all containers start with a standard base image
Consider using Micro OSes
- It would not be a bad idea to think of using the upcoming container-centric OS as your host OS for deploying containerized applications. The footprint of Micro OS is considerably small than the traditional OSes, thereby making the Docker deployment even more lightweight. Ubuntu Snappy, Core OS, Rancher OS are some of the examples of Micro OSes
Leverage the famous IoC principle even with containers
- The Inversion of Control principle plays a very important role on containerized environments
- Supply the configurations needed to run the application as an input to the container during runtime instead of pre-baking it in the container image. This will help the application to adapt to a different configuration
Conclusion
Containers are becoming the de-facto standard for the deployments for many types of applications. However, up-front planning is important before taking the container-centric route for development and builds in any application development project. Without this planning. the process of building and deploying applications using Docker containers can become very complex.
Although it is possible to use Docker containers without a container management framework, you will lose some of the advantages of using both together. Securing Docker containers is an important task for the enterprise. Dev and Ops are slowly inching towards each other with the use of containers in the real world.
Appendix – Technology and vocabulary of Docker Ecosystem
- Orchestration refers to the clustering achieved by Docker tools for spawning containers
- Micro OS refers to the tiny Linux distribution (or micro Operating System) tailored to host Docker containers.
References
- http://www.javaworld.com/article/2685223/java-app-dev/four-ways-docker-fundamentally-changes-application-development.html/
- https://www.infoq.com/news/2015/04/scaling-microservices-gilt/
- https://www.infoq.com/news/2015/12/dockercon-docker-monitoring/
- https://railsadventures.wordpress.com/2015/11/15/docker-orchestration-the-full-story/
- http://kubernetes.io/docs/user-guide/
- https://docs.docker.com/engine/reference/run/
- https://blog.docker.com/2015/08/content-trust-docker-1-8/
- https://benchmarks.cisecurity.org/tools2/docker/CIS_Docker_1.11.0_Benchmark_v1.0.0.pdf
- https://github.com/GDSSecurity/Docker-Secure-Deployment-Guidelines
- http://microservices.io/patterns/client-side-discovery.html
- http://logz.io/blog/docker-monitoring-dockercon-2016/
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments