
The series so far:
- How to Linux for SQL Server DBAs — Part 1
- How to Linux for SQL Server DBAs — Part 2
- How to Linux for SQL Server DBAs — Part 3
- Navigate Linux for SQL Server DBAs
The series has covered a great breadth of technical concepts and, hopefully, you, the reader has had a chance to work along with the areas I’ve covered. I’ve attempted to create translations from database terms and concepts to the Operating System level, hoping to ease the transition to Linux for the SQL Server DBA. This shift is both a wish and a need. With the metamorphosis of Azure on Linux, along with DevOps fueling a single OS for ease of deployments, the day is coming when everything will run on Linux, with pods and containers housing whatever is needed, making it easier to lift and shift whenever required. As I’ve stressed in previous articles, the biggest hurdle for the Microsoft Data Platform specialist is that, unlike other database technologists, you’ll be less likely to have a Linux professional to refer to for assistance. Knowing how to perform tasks that commonly fell to those individuals will be pertinent to your future role in the industry. This article covers how to navigate Linux for SQL Server DBAs.
In this article, I’m going to discuss advanced navigation and processes in Linux. Although moving from one directory tree to another within the command line is common, knowing how to execute a command to navigate a complex tree or locate something that isn’t in the current directory is essential to administration, just as walking is essential for a child to go from crawling to running.
Advanced Navigation
In the previous articles, I discussed how Linux interprets certain characters to signify where you are referring to in the directory tree.
|
. |
Current directory |
|
.. |
One directory up from the current location |
|
./ |
Inside current directory |
|
../ |
Inside one directory above the current one |
|
~/. |
Home directory from any location |
|
pwd |
Display current location path |
You can also create environment variables to common, deep, and complex directory paths that you regularly use to lessen the amount of typing at the command line. This can be done as part of your profile, so it is set as soon as you log in or you can set it during your session. Your Linux admin may also set some aliases globally for any user that logs in, and some are set by the OS. The OS identifies them by the precursor symbol $. For the following example, my preferred method of listing files is to list them to include “all files, with listed permissions and information”. I don’t want to type out ls -la all the time and would prefer Linux to default to this whenever I use the ls command to list out files. This is a standard example of when you would use an alias and to create an alias at the session level I’d type in the following:
|
1 |
>alias ls=“ls -la” |
If I would like to set this for my session every time I login, I can set this in my .bashrc, (bash remote command) file or secondary profile. The alias can be added, (without the $ prompt) to an empty line in either of those files and once executed either by logging in or executing, the alias is set for the session. As was discussed in earlier articles, this is similar to the environment variables and parameters in Windows and is specific to the unique user that is logged in at the time. When you switch from one user to another, you have the choice to set up the environment for the new user, too.
|
1 |
>. ~/.bashrc |
The command above requests the following:
- post the prompt, (>) uses the “.” Signalling to execute the file immediately following the period.
- “~” is the symbol for the home directory of the current user, (which may be different than the original user that has logged in and then switched over to the current user).
- .bashrc is the remote command file which resides in the home directory for the current user.
Where environment variables are set or exported, depending on the Linux distribution, aliases don’t require any other command than “alias” the command or term you would like to use for your alias and then the command(s) and filters to execute when the alias is entered at the command line.
Take care not to use reserved words or an executable that is needed for something else. Consider the following poor choice in alias:
|
1 |
>alias sqlcmd=“ps -ef | grep sqlservr” |
If I created the above, the sqlcmd command line utility to query the database would no longer refer to the executable.
Aliases can be set up in multiple ways, along with setting at the .bashrc or the .profile, aliases can also be set in a separate file to ease management for more complex environments, often named .bash_aliases. To view the aliases, (if any have been set for your current host and login) open your .bashrc file in your home directory and inspect them.
|
1 2 |
>cd . >view .bashrc |

To get out of the vi editor without saving, type :q! (colon q exclamation point).
|
1 |
>alias <alias name> = <full path to directory or executable needed for variable> |
Environment Variables
Environment variables, may appear to be redundant after working with aliases, but they are much more robust and have more uses.
- Variables, either set at the session or environment level can be used by sub processes using the getenv function, unlike aliases, which are only available to the parent.
- Variables can be used anywhere in the command line, by simply calling them with the
$before the variable name, where an alias only works in an interactive mode.
An example of this would be:
|
1 2 |
>export ls_sql=“ps -ef | grep SQL” >echo $ls_sql |
This command would return all running SQL processes. While an alias:
|
1 2 |
>alias ls_sql=“ps -ef | grep SQL” >echo ls_sql |
The above would return ls_sql, as there isn’t a redirect that echo can retrieve. An example of a common environment variable would be similar to the following:
|
1 |
>export SQL_HOME = /opt/mssql/bin |
To add it to the profile, change to the home directory and edit the .profile, (or add a .profile if you don’t already have one.) It’s a best practice to create a .profile file vs editing the host level .bash_rc file. This way, if you have more than one database or application environment that requires a unique configuration, you aren’t left with a set global file that must be updated each time.
|
1 |
>vi ~/.profile |
Using the vi editor, proceed to the bottom line of the file and type o to go into INSERT mode. If environment variables are already listed, it’s a good idea to group them together and add headers and comments into the file to help ease the management of the file.
For this example, I’ve added three environment variables to ease managing my SQL database server:
- SQL_HOME for the bin directory, (SQL Executables)
- SQL_TOOLS for the shortcut to take me to sqlcmd
- SQL_DATA for my data directory
I’ve added the option to export the environment variables. It’s not always required, but exporting vs just setting the variable ensures that this is set at the session level, even after you’ve exited out. Note this profile executes the .bashrc beforehand and post the execution, sets the environment. If there are any conflicting settings in the previous file, it will be overwritten by this one, (previous SQL_HOME, etc.)
|
1 2 3 |
export SQL_HOME=/opt/mssql/bin export SQL_TOOLS=/opt/mssql-tools/bin export SQL_DATA=/var/opt/mssql/data |
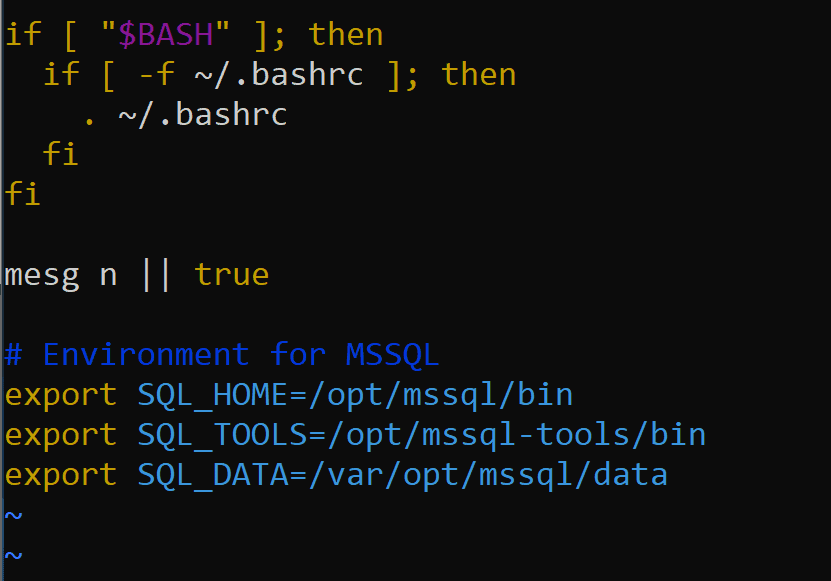
Once you add these three lines, save your changes and exit the .profile in vi by typing ESC :x (escape colon x). To execute this profile, just as you did with the alias and once logged in, run this:
|
1 |
>. .profile |
If you are in another directory and need to run the .profile, you can make one simple change:
|
1 |
>. ~/.profile |
You can now verify if your environment is properly set by echoing the environment variable(s). Each of the variables can be placed on the same line with the single echo statement, a space between each one and no commas required:
|
1 |
> echo $SQL_HOME $SQL_TOOLS $SQL_DATA |
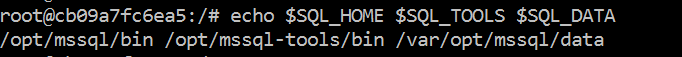
You can now use these environment variables for navigations and processing:
|
1 2 |
>cd $SQL_DATA >ls |

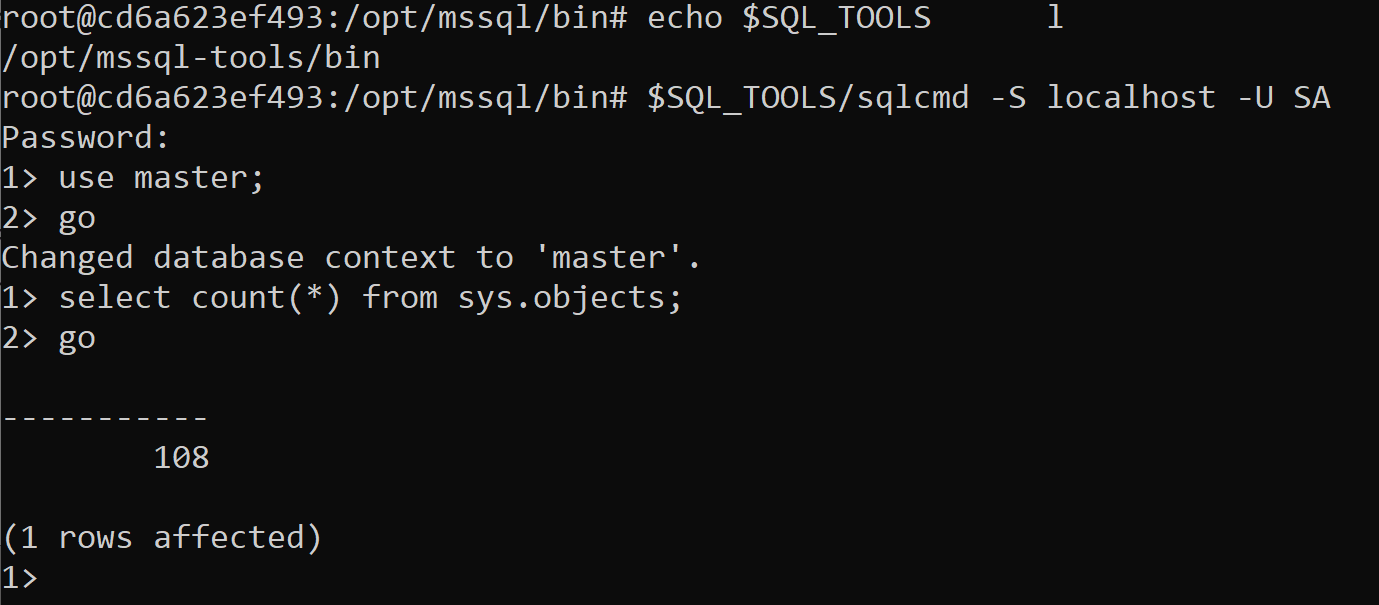
You no longer need to type in the full path to the data files but can use the variable to achieve the same thing. When you use these environment variables, the difference in keystrokes is quite evident. Without the environment parameter, you would need to type in the full path. This doesn’t just work for navigation, but also executables. Using the example of logging into the SQL database, instead of typing in the full path to the SQL Tools directory, you can instead substitute $SQL_TOOLS for the path to sqlcmd:
|
1 2 3 4 5 6 7 |
Echo $SQL_TOOLS $SQL_TOOLS/sqlcmd -S localhost -U SA use master; GO select count(*) from sysobjects; go exit |
This eliminates more of the work that may seem tedious for those used to a GUI and contending with more command line than to what they’re accustomed.
Knowing What is What
As you begin to work with Linux, as I’ve noted previously, you will have Microsoft technologists that may be new to Linux. They won’t have the decades of experience with Unix environments that many database platforms were able to rely on. You should expect less mature host designs to be offered to you for your databases. With this, you may discover that some of the required libraries are missing or hosts are misconfigured.
When I first began with Unix, this was a common case. Many of the tools for administrators working with databases still hadn’t matured, so DBAs needed to know how to locate what was misconfigured, what was needed, and how to find what was what. The following utilities are incredibly valuable in solving those challenges. As with those missing libraries and modules, these utilities might be missing, so I will also include how to install each one of them.
|
1 2 3 |
>apt-get install findutils >cd $SQL_HOME >find sqlservr |
Or, use a wildcard to locate it if you aren’t sure of the executable name:
|
1 |
>find sql* |

This will search the current and all child tree directories for any file/directory/executable starting with sql. It’s case-sensitive, so ensure if you’re looking for SQL, you change how you perform your search.
As a Windows database administrator, you may have spent time reviewing the Windows environment path to discover that it was using the wrong version of installed software vs what your database required, (think ODBC driver, etc.). There is a similar utility that can assist you in Linux called WHICH. It will tell you which application is currently set to be used by the user and profile in the session where you’re working.
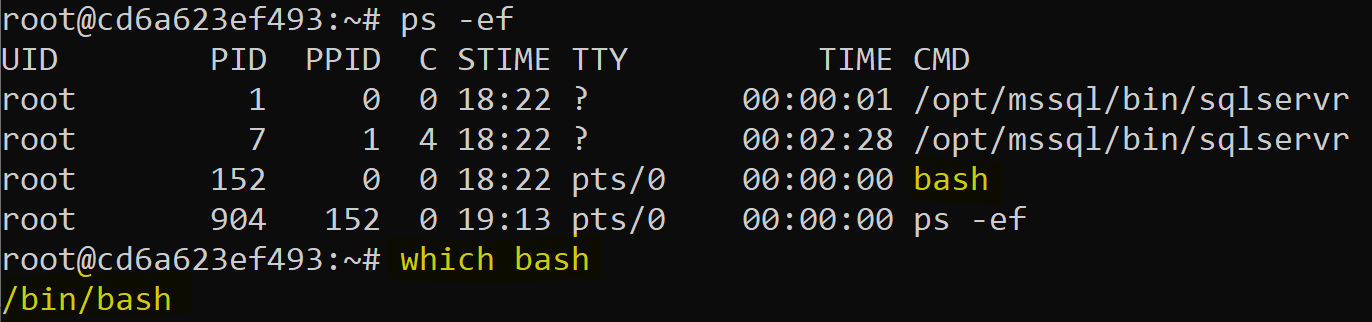
For this example, note in the process list that bash is showing in the list, but you forgot where it’s installed, (you are still new to Linux, so this is plausible…) By using the WHICH utility, you can find out it’s in the /bin directory:
|
1 2 |
>ps -ef >which bash |
If you are missing the which utility, you can install it by running the following commands, displayed for the two most popular flavors of Linux installation utilities.
|
1 2 |
>apt-get install system-tools >yum install sysnet-tools |
Processes
For each and every process that runs inside of the database on a Linux host, there is a separate program instruction, read or write on file on input from a system user behind it. Understanding how SQL Server on Linux is different than Windows is a critical first step in working with Linux processes.
As multi-threaded processing in Windows is normal for SQL Server, it’s also been ported over as part of the codebase that was migrated to Linux. This architecture is foreign to the Oracle DBA, where each foreground and background process has its own process in Linux, the SQL Server has two main processes with multi-threading underneath. find the value in the individual process power for the database administrator.
While SQL Server is multi-threaded, every allocation of memory is attached to a process in Linux. These threads are separated along clear boundaries in the application to ease the management between critical and non-critical processing for the application. There is still a significant difference between Windows services and Linux processes. Windows depends on a service, when started, to bring up multiple processes to an active state, making it fully functional. A process in Linux, on the other hand, can very often be stopped and restarted, with only a percentage of those processes critical to the overall application, allowing with silo’d management of application stacks.
This may critically change the way that SQL Server will run on Linux in the future. Consider the following challenge:
You’re experiencing a memory leak that is coming from SQL Server that performs the archiving of the transaction log. What if you could log into the Linux host and stop, (i.e. kill) only the process connected to the thread that writes data to the transaction log and have the rest of the database continue to operate as normal? For many database platforms, the process attached to the logging process would restart transparently, subsequently solving the issue. This is a benefit of having separate processes over multi-threaded as part of a service, as you see in the Windows operating system.
Just as you stop the SQL Server service on a Windows server, you can locate and “kill” the SQL Server main process on Linux to stop the SQL Server. This is similar to an “end task” command in the Task Manager, but you understand the implications. With many database platforms that have run on Linux/Unix for an extensive time, the DBA learns that there is a specific process that can be killed to force a shutdown, (as a last resort) such as with Oracle (where the PMON or SMON process will suffice) or with PostgreSQL.
With this type of process architecture in place, along with understanding the Linux kernel, which was covered in previous articles, it’s easier to understand why Linux servers rarely require a reboot. Processes are only loosely connected to the kernel and can be disconnected just as easy with a kill command. I’ve experienced only one time where a Linux host required a cycle because a kill would not suffice and it was due to an application issuing tens of thousands of processes to a single host, overwhelming the host, resulting in an inability to log into the host.
The Process Command
The process status utility is issued with the first letters of the two words (ps) and displays the running processes on the host where it’s executed. It’s native to both Linux and Unix, can be run from any directory from the command line and is essential for many when monitoring processes. It is a host-level executable and is available to any user who has privileges to the /usr/bin directory of applications that come standard with a Linux, (or Unix) server.
Similar utilities that provide information like PS are:
|
Lost |
List of Files |
|
Top |
Lists resource usage and top processes |
|
Strace |
Trace that will include processes |
From the command line, you can view processes with the PS command:
|
1 |
>ps |
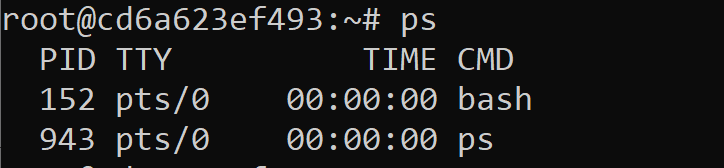
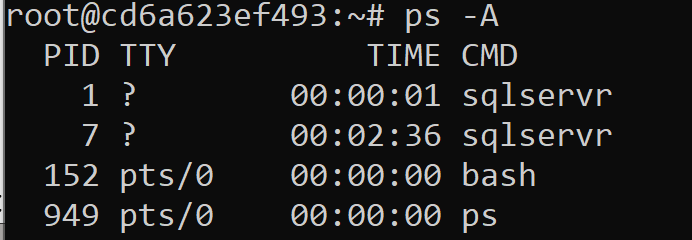
There are numerous arguments, but if you wished to print to screen all the active processes in a generic format, you could use the -A argument. In this example, note that now the SQL Server processes show up, where before, they were hidden as an application:
|
1 |
>ps -A |
If you prefer the BSD format, you could use one of the following variations instead:
|
1 2 |
>ps au >ps axu |

The most common argument combination for DBAs is the -ef, which is the full format argument. This format provides added information about resource usage. The format argument is case-sensitive, so you can use the full format, (-f) for the long list format, (-F).
|
1 2 |
>ps -ef >ps -eF |
It displays the most common information that’s important to DBAs:
- User ID
- Process ID
- Parent Process ID
- CPU Usage
- Start Time
- Time Running, (unless it has completed.)
- Command
It’s a clear view of what DBAs need 95% of the time, so they prefer this set of arguments more often than any other.
To display processes that are currently running, (not just active, but running) you can use the -x argument. The output will look very similar to the examples above, but it’s important to know the difference when you’re working on a heavily utilized host that requires more advanced arguments.
|
1 |
>ps -x |
What if this were a very busy host and there was a significant amount of process running on it? Filtering is an essential part of cutting through the information returned to the screen, and that’s where the GREP utility comes in. If you wanted to query the processes and only return those with “sql” in the name, then the following command would return this:
|
1 |
>ps -ef | grep sql |
You could also use this as part of logging by rerouting the output to a file instead of the screen:
|
1 2 |
>ps -ef | grep sql > /tmp/logfile.txt >ls -la /tmp/logfile.txt |

You can now view this file, and the output from the ps command will be present:
|
1 |
>view /tmp/logfile.txt |

Note how the ps command has changed in the last line to the grep. This is because the grep that was the second utility executed after the ps is what was captured in the output.
As there may be a user that has switched over to another user, (covered in part III of this series of articles) you may want to see the original user that is running the command instead of who they are currently running the command as. You can do this with the -U argument. You must add the user, (name or user ID) that you wish to see if they are a switched user after the argument:
|
1 |
>ps -fU <username> |
Using these commands grant you the first insight to shell scripting, something I’ll write about in future articles.
Process Monitoring
Process information can be used not just to identify what is running, but the resources that are used by any given process. This command can also be used as a diagnostic tool when behavior isn’t as expected.
Although SQL Server is still multi-threaded, requiring the user to go into the database to view allocation of resources, there is still value to understanding how to identify what processes are connected to the parent process on a Linux server for the SQL Server, both database and executable.
There are a few ways that this can be done and I’ll cover each one of them and why.
The first one sources from the correct installation by user and group of SQL Server. The recommendation is to create a MSSQL user and an MSINSTALL or MSDBA group. This provides an isolated and secure environment for a database installation on Linux. If this is done, it also provides a means of identifying what processes are connect to a running SQL Server.
You can search for all processes owned by the group name or group number. In the following example, you can inspect the processes owned by the MSINSTALL group:
|
1 |
>ps -fG MSINSTALL |
If you use the current container installation you’ve been working with, the SQL Server is owned by root. This doesn’t stop you from identifying all processes owned by the database; it just requires you to perform an extra step.
First, identify the SQL parent ID:
|
1 |
>ps -ef | grep MSSQL |
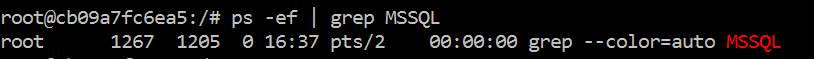
Use the parent ID, which is the Top ID before root that displayed in the tree of processes and use it to identify everything owned by it:
|
1 |
>ps -f --ppid <pid> |
Before you begin to use the Process Status Utility as a diagnostic utility, there are important aspects of it to understand. You can print out a process tree that provides a more physical view of the process hierarchy.
|
1 |
>ps -e --forest |
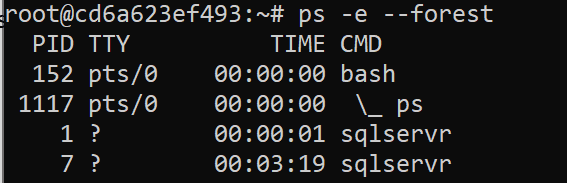
The output clearly displays the parent ID followed by each child in descending order. This can also be done for an individual process. You can do this for the SQL Server database like this:
|
1 |
>ps -ef --forest | grep -v grep |grep sqlservr |
This command displays a very clean visual of how the processes are connected in SQL Server when running in Linux.
Navigate Linux for SQL Server DBAs
This article covered some more deep level investigation of how to set up an environment for easier support and use, along with advanced navigation. It also demonstrated how to dig into the process utility and how to find what processes are running and where. The next article in this series will take you on an introduction to BASH scripting. The Linux DBA can’t survive on Power Shell alone, and there are a lot of cool utilities built into Linux and available via BASH to empower you to do more with less in Linux.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments