
As organizations grow larger and larger, so does the codebase and its complexity. With growing complexity, it becomes increasingly difficult to deliver code to customers with high confidence and velocity. This problem becomes especially hard in large organizations where the number of commits per day can be in the thousands or more. Here, we discuss the basic principle behind continuous deployment, the problems with continuous deployment at large scale, and define a generalized methodology to think about how to release code at scale.
What are Continuous Integration and Continuous Deployment?
First, it is important to understand the concepts of Continuous Integration and Continuous Deployment. Continuous integration is merely a practice of ensuring that pull requests from multiple developers working on the same codebase are consistently and safely merged into a singular branch to avoid conflicts. Having Continuous Integration (CI) ensures that teams within an organization are building, testing, and merging code with consistency and quality.

As soon as code is merged, we enter the phase of Continuous Deployment or Delivery (CD). While CI revolved around merging code consistently and rapidly, deployment is focused on releasing code with consistency. In theory, the practice of adopting Continuous Deployment means that every code change is deployed as soon as it is merged and goes instantly into the hands of the user. Most development teams have a plethora of tools from which to choose: Jenkins, AWS, CircleCI, Atlassian Bamboo, Travis CI etc. Regardless of the tool a company chooses, it is important to understand the different architectures, benefits, and downsides of adopting and building a Continuous Delivery pipeline at scale.
Problems with Continuous Deployment at large scale
While the ideology of Continuous Deployment makes perfect sense on paper, with scale and the size of organizations, it becomes quite complex and hard to manage. For a team or company shipping a few changes per day, Continuous Deployment in practice is quite beneficial. However, if an organization is pushing upwards of thousands of commits per day, Continuous Deployment can be quite expensive. Close attention needs to be paid towards how it is architected. Two major problems that arise due to large scale are:
Cost
Building, packaging and deploying code requires computational resources. If a Continuous Deployment pipeline is deploying every commit to production continually, it is expected to burn a lot of resources while doing so. In these cases, organizations must balance the need to push code to production along with the cost it incurs. In a small company where the number of commits is relatively small, cost is not a primary concern. However, as soon as the team is writing and shipping code at scale with hundreds of commits per hour, the cost of building and deploying code can easily supersede the benefits of Continuous Delivery. There are only so many meaningful customer commits during a certain time period.
Rollbacks
Regardless of how much testing, pre-merge, and deploy safeguards one can create, there will always be bugs in production. When continually deploying code to production, it can become extremely difficult to find bugs. Tracking back a faulty deploy becomes excruciatingly hard if a bad commit is deployed to production and then multiple commits are deployed after that. In these scenarios, the only option would be to revert the culprit commit and do a hotfix or ad hoc deploy. When deploying around 50 commits an hour and a bug is found in the code a week after deployment, the master branch is already ahead by around 7000 commits and finding the culprit can be quite time consuming and costly.
Solving Continuous Delivery at scale
Regardless of the previously defined drawbacks, we could design and implement a Continuous Delivery platform that can rapidly release code at scale and increase the quality of user experience. There are multiple ways in which one can navigate the problem and the different approaches they can consider
Frequency of meaningful commits
In order to decrease the massive cost of continually building and deploying code, one strategy is to only deploy at a certain cadence and batch commits at certain intervals. These intervals can be different for different microservices. The goal is to have an optimization function to make the cost of deploying acceptable. One way to do it is to find out the number of meaningful commits in a service over time — commits that are bug fixes, feature deploys, configuration changes, or anything an organization deems as meaningful. Small improvements, minor refactors, and other non-significant changes can easily be dismissed. In order to understand, simply calculating the frequency of meaningful commits:
f = M / T
M is the number of occurrences of meaningful commits
T is a unit of time
f is the frequency of meaningful commits
If a service or repository only has meaningful commits once a week, it is worth evaluating if we really need to deploy code every couple of hours or not.
Reduce the external exposure of bugs in the system
A naive approach to implementing Continuous Deployment would be to take every commit and release it to the users. This can work if the user base is small enough or if the number of commits is not large. However, if the organization’s size is large or if there are millions of users, the continuous delivery architecture needs to take that into account and develop a system where the team reduces the potential exposure of bugs to a small surface area. Using a percentage rollout along with emergency triggers to block deploys mid-process can be quite useful. In addition, developing multiple safeguards and checkpoints along the phased rollout are essential. At each checkpoint, or throughout the pipeline, there should be emergency triggers set up that can pause the rollout of a bad commit to production.
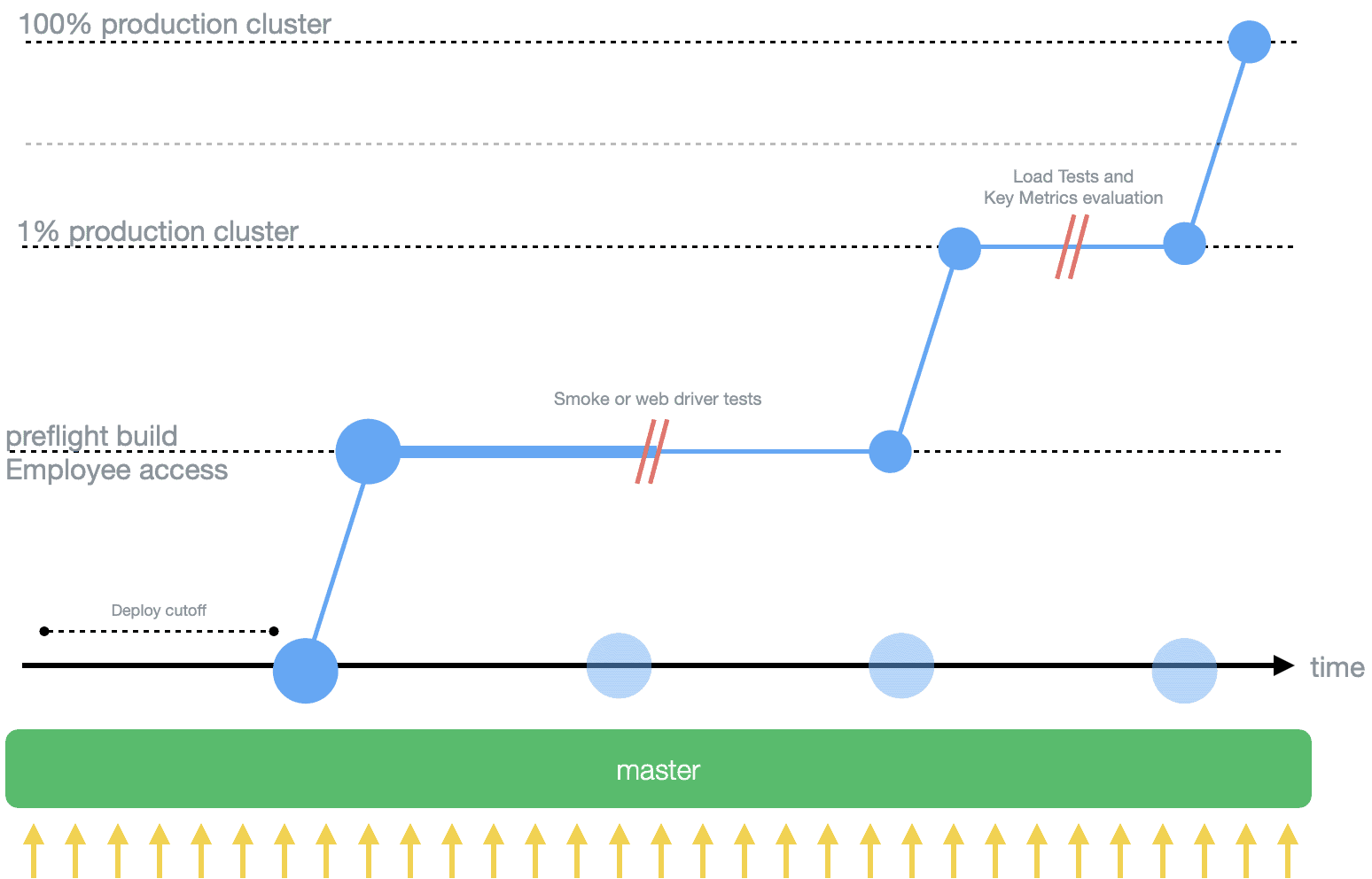
The diagram shows how there is a phased rollout to avoid external exposure to bugs. Additionally, not every commit goes to production, and commits are batched together based on optimizing for maximum meaningful commits with some precision. Each step of the way, we validate the build even during the deployment stage. First, once a preflight or employee build is deployed, smoke or webdriver tests are run to ensure the behavior of the application is expected and there are no major regressions in the new build. Second, after deploying to 1% traffic, several load tests and key metrics evaluation are run. These ensure that before rolling the build to the rest of the fleet, we ensure that the machines running the build for the 1% traffic pass all key metrics evaluation and metrics such as success rate, latency, garbage collection and more.
Conclusion
Continuous Delivery can unlock a lot of potential value for any organization and its customers. It enables reaching customers faster and reduces any human intervention required to deploy systems. It does come with its own complexity, especially with large and growing organizations. However, if architected keeping these concerns in mind, it can be extremely beneficial.
Load comments