
Data lineage is a component of modern data management that helps organizations understand the origins, transformations, and movement of their data. It is like a road map that shows us where our data has been, how it has changed, and where it is going, just like tracking the journey of a package: from the person who sent it (the source) to the places it passes through, and finally to the person who receives it.
The concept of data lineage has been around for many years, but it has become increasingly important in recent years due to the growth of big data and the increasing complexity of data processing systems.
One of the earliest examples of data lineage can be found in the work of Dr. Donald Knuth, who developed a system called TeX in the 1970s. TeX is a typesetting system that uses a complex set of rules to generate high-quality printed output. Knuth developed a system called Metafont to track the flow of data through TeX. Metafont allowed Knuth to identify and fix errors in his typesetting rules.
In the 1980s, data lineage began to be used in the financial services industry to track the flow of financial transactions. This was due to the increasing need for financial institutions to comply with regulations such as the Gramm-Leach-Bliley Act.
In the 1990s, data lineage began to be used in the healthcare industry to track the flow of patient data. This was due to the increasing need for healthcare providers to comply with regulations such as the Health Insurance Portability and Accountability Act (HIPAA).
In today’s data-driven world, organizations are collecting and storing more data than ever before. This data is important for making informed business decisions, fueling innovation, and enabling organizations to better understand their customers and markets.
It provides a detailed record of data’s path, showcasing how it is created, modified, used, and transformed throughout various processes within an organization. Data lineage helps understand the data’s quality, lineage, and business relevance. It can be represented in graphical or tabular formats, allowing stakeholders to comprehend complex data relationships and dependencies easily.
Data lineage has three main components that help us understand how it works. They include:
- Data Source: The journey of data commences at a data source. Data sources serve as the birthplaces or points of origin where data is either generated or acquired. These sources encompass various forms, including databases, spreadsheets, files, APIs (application programming interfaces) and even streaming platforms. To illustrate, when a customer places an order on an e-commerce website, the details of that order constitute the data generated at the source, which in this case is the website’s database. Data sources are important for understanding the context and quality of the data, essentially laying the foundation for subsequent stages in the data journey. At this initial stage, data can exist in its raw, unprocessed form, or it may have already undergone some level of transformation. However, while databases, spreadsheets, and files themselves can’t be considered the absolute start of data (since data inherently represents something), they can indeed serve as the source of data within a specific system’s perspective.
- Data Transformation and Processes: The journey of data is rarely a direct path from source to destination. Data often undergoes transformations and processes, changing its structure, format, or even meaning. These transformations can be as simple as converting data from one format to another or as complex as predictive analytics and machine learning algorithms altering and enhancing the data.
Transformations can occur at various stages during the data’s journey, and they significantly impact how the data is perceived and utilized. These transformations and processes are key components of data lineage, as they shape the data, turning it into an asset for decision-making and insights. - Data Destination: The final stop on the data journey is its destination—where it is consumed, stored, or used for decision-making. Data destinations can be databases where data is stored for future reference, visualization tools where it is used for creating reports, or other systems where it is utilized for various purposes. Data destinations complete the cycle of data lineage, providing a clear picture of where the data ends up and how it contributes to organizational goals.
A data lineage map is a visual representation of the flow of data through an organization’s systems. It shows how data is extracted from source systems, transformed, and loaded into target systems. Data lineage maps can be used to track the movement of data through complex data processing pipelines, identify dependencies between data assets, and troubleshoot data quality issues.
Here is a small example of a data lineage map broadening the context with business term lineage:
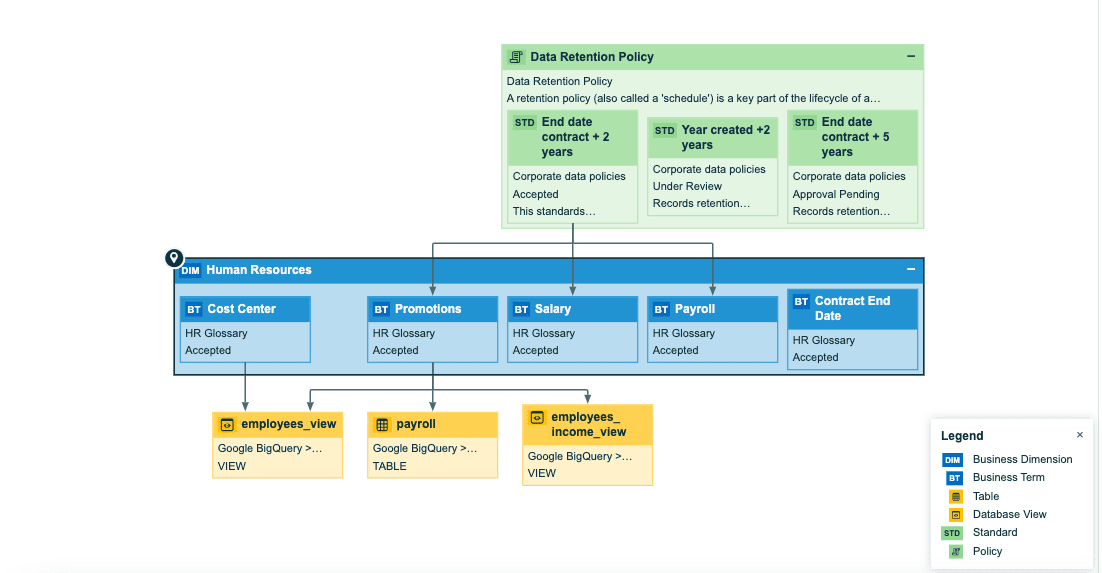
Image created with Collibra
The picture above shows a complete data lineage. The user is interested in very specific data: human resources. Such columns will have a proper business term—something like “salary” or “promotions”—assigned. With Collibra, you can see the lineage for that glossary term and find the best quality assets in every system. It shows the lineage retention policy data.
Types of Data Lineage
Data lineage manifests in various forms, each offering a distinct perspective on how data evolves and is utilized within an organization. Understanding these types of data lineage is essential for organizations aiming to glean comprehensive insights into their data landscape. The primary types of data lineage are covered in this section:
Forward Data Lineage
Forward data lineage, also known as “upstream” or “inbound” data lineage, traces the path of data from its origins to its current state. It follows the data as it progresses through different stages of processing, transformations, and storage, eventually reaching its peak in consumption. It provides insights into the data’s journey, including the different stages of the data pipeline where data is processed and transformed, the specific data transformations that are applied to the data, the storage locations where the data is stored, and the downstream applications and analytics that consume the data.
This type of lineage is essential for understanding how data is created, transformed, and utilized within an organization. If a company collects customer data, forward data lineage would trace it from the moment it is gathered through various transformations until it is used in generating reports or analytics, providing insights into data quality and integrity. Forward data lineage can trace a certain part of data, or it can start at all the starting endpoints and go forward. It depends on the specific needs of the organization and the use case for the data lineage.
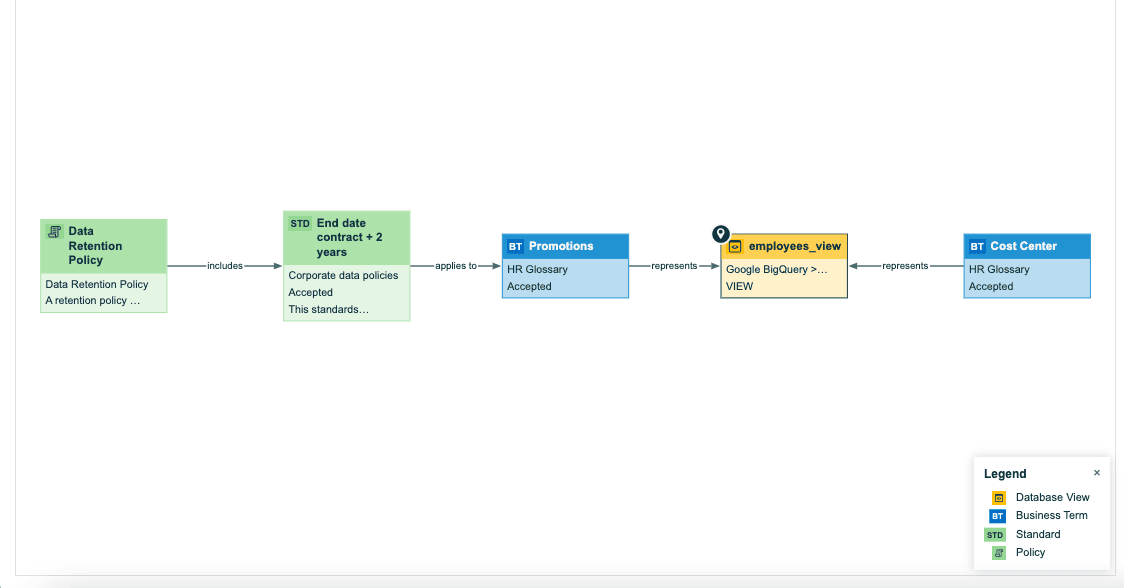
Image created in: Collibra
This scenario shows how the “Promotions” column in the “employees_view” table is derived from data in the “HR Glossary” and “employees” tables. This is an example of forward data lineage.
Backward Data Lineage
Contrary to forward data lineage, backward data lineage, also termed “downstream” or “outbound” data lineage, follows the data in the reverse direction. It starts from where the data is consumed or used and traces its path backward to its source. It is instrumental in understanding the impact of data on downstream processes and in identifying the origin and quality of the data. For instance, if an organization discovers discrepancies in the results of a specific analysis, backward data lineage can help pinpoint the source of the issue by retracing the data’s journey and revealing transformations or discrepancies that occurred along the way. It can be used to identify the root cause of data quality issues, track data lineage for compliance purposes, support data security and risk management, and enable data lineage-driven optimization of data pipelines.
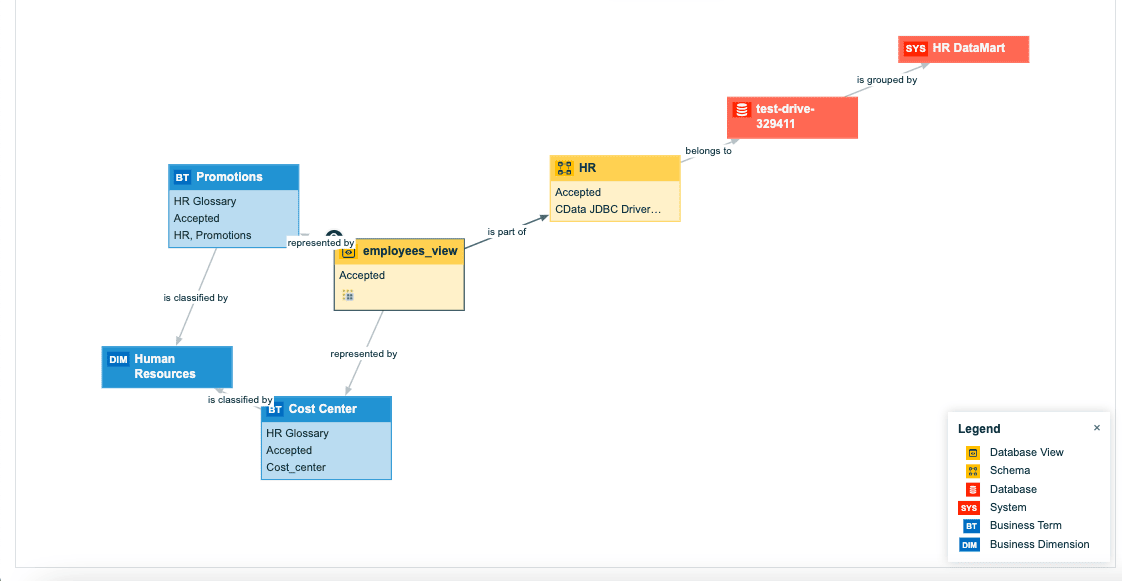
Image Source: Collibra
In the scenario above, the user can use backward data lineage to understand how the data in the “Promotions” column was derived and what other data sources it depends on. This information can be used to understand the data quality and to identify potential risks.
Mixed Data Lineage
As the name suggests, mixed data lineage combines elements of both forward and backward data lineage. It provides a comprehensive view of how data flows in both directions, from its source to consumption and vice versa. Mixed data lineage fully explains data flow and its interplay between creation, transformation, storage, and utilization. In a complex data ecosystem, mixed data lineage is vital for data governance, as it ensures that all aspects of data flow, whether upstream or downstream, are well documented and understood.
Impact Analysis Data Lineage
The impact analysis data lineage delves into the effects and influence of changes to data or processes. It helps organizations understand how a modification to a data source, transformation, or storage system can impact downstream processes, applications, or analytics. Impact analysis data lineage can be used to assess the risk of proposed changes to the data pipeline, develop mitigation strategies for potential impact, and make informed decisions about data pipeline changes. If a company plans to upgrade its database system, impact analysis data lineage can help predict how this change will affect various departments, ensuring a smoother transition. Impact analysis data lineage is particularly important for organizations that are heavily reliant on data-driven applications and analytics.
Business Data Lineage
The business data lineage focuses on the business context and relevance of the data. It maps the data flow in a way that aligns with business processes, enabling stakeholders to comprehend how data supports business objectives. It helps bridge the gap between technical aspects of data lineage and business requirements, fostering a more comprehensive understanding of data utility. For instance, in a retail company, business data lineage could illustrate how customer purchase data feeds into inventory management and informs restocking decisions. It can be used to identify the key data assets that drive business value, understand the data flows that support key business processes, assess the impact of data quality issues on business outcomes, and make informed decisions about data investments. It is essential for bridging the gap between technical aspects of data lineage and business requirements.
Operational Data Lineage
Operational data lineage emphasizes the technical aspects of data flow, encompassing the detailed processing steps and transformations involved. It is essential for data engineers, data architects, and technical teams to optimize data pipelines for performance and reliability, troubleshoot data quality issues, ensure data quality compliance, and measure the impact of data pipelines. It provides a view of data flow that is essential for maintaining the efficiency and effectiveness of data pipelines.
Each type of data lineage provides insights into the data’s journey and usage, catering to specific needs within an organization. Organizations can thoroughly understand their data ecosystem by leveraging a combination of these types based on their objectives and requirements. This understanding, in turn, facilitates better decision-making, improved data management, and the effective utilization of data to drive business growth and innovation.
Importance of Data Lineage in Modern Data Management
Understanding the importance of data lineage is necessary. Data lineage serves as a guiding beacon, illuminating the complex paths traversed by data from its inception to its utilization. Here is why understanding data lineage is important for modern data management:
- Enhanced Data Quality and Reliability: Understanding data lineage allows organizations to carefully examine and validate the quality and reliability of the data. By tracing the transformations and processes the data undergoes, any anomalies, errors, or inconsistencies can be identified and rectified, ensuring data integrity and reliability.
- Facilitates Regulatory Compliance: Compliance with regulatory frameworks and data privacy laws is a concern for modern organizations. Data lineage provides a robust mechanism for demonstrating compliance by offering a clear and auditable trail of how data is sourced, manipulated, stored, and consumed. This transparency is necessary in regulatory audits and ensuring adherence to legal requirements.
- Effective Data Governance and Management: Data governance is a fundamental aspect of modern data management. Data lineage supports effective data governance by providing a comprehensive understanding of data flows and dependencies. This knowledge enables organizations to establish data governance policies, ensuring data quality, security, privacy, and compliance with organizational guidelines.
- Efficient Troubleshooting and Issue Resolution: In the data ecosystem, issues are inevitable. Data lineage aids in efficient troubleshooting by enabling quick identification and isolation of problems in the data pipeline. Whether it’s an error in a transformation or an inconsistency in the data source, understanding the lineage helps in swiftly resolving issues, minimizing downtimes, and enhancing operational efficiency.
- Optimized Data Transformation Processes: Understanding the transformations data undergoes is essential for optimizing data transformation processes. Data lineage provides insights into how data is transformed, which transformations are important, and where efficiency improvements can be made. This optimization is vital for streamlining data processing, reducing processing times, and enhancing resource utilization.
- Facilitates Data Impact Analysis: Data lineage facilitates impact analysis, allowing organizations to predict the effects of changes to data sources, transformations, or destinations. This foresight is invaluable in risk assessment and change management, ensuring that modifications to the data pipeline are thoroughly evaluated before implementation, minimizing potential disruptions.
- Supports Data Lineage Governance: Implementing data lineage governance ensures that the data lineage remains accurate, consistent, and up-to-date. It involves establishing processes and roles responsible for maintaining and validating the lineage. Effective governance ensures that the data lineage remains a reliable and trustworthy source of truth for stakeholders.
Ways for Establishing Data Lineage
Establishing an effective data lineage is an important initiative for organizations aiming to gain comprehensive insights into their data flow, usage, and transformation processes. While it may seem daunting, there are several strategic approaches and methods that organizations can adopt to establish a robust data lineage. Here are some key strategies to achieve this:
Documentation of Data Sources and Processes
Begin by documenting all data sources and processes within the organization. This involves identifying the systems, applications, and devices that generate or capture data and the various processes through which data passes during its lifecycle. Comprehensive documentation serves as the foundation for creating data lineage.
Collaborative Workshops and Interviews
Conduct collaborative workshops and interviews involving relevant stakeholders, including data engineers, data analysts, business users, and subject matter experts. Engage these stakeholders to gather insights into the data flow, transformations, and consumption patterns. Collaborative discussions often unveil data pathways and dependencies that might not be evident initially.
Utilizing Automated Data Lineage Tools
Leverage automated data lineage tools and platforms designed to capture and maintain data lineage automatically. These tools analyze metadata, logs, and system interactions to map out the data flow, providing a real-time view of how data moves through the organization. Automation accelerates the process and reduces the likelihood of errors associated with manual documentation.
Implementing Metadata Management Systems
Invest in metadata management systems that catalog metadata associated with various data assets, including data sources, transformations, and consumption points. Metadata management facilitates the tracking and organization of data lineage, ensuring that accurate and up-to-date metadata is available for lineage construction.
Data Lineage Governance and Policies
Establish governance policies and processes specific to data lineage. Define roles and responsibilities for managing, updating, and validating data lineage. Implement checks and balances to ensure that data lineage remains consistent, accurate, and aligned with organizational data management objectives.
Continuous Monitoring and Updates
Data lineage is not a one-time effort but an ongoing process. Establish mechanisms for continuous monitoring and updates to reflect any changes in data sources, transformations, or consumption patterns. Regularly review and validate the accuracy and relevance of the documented lineage to keep it up-to-date and reflective of the current data landscape.
Standardized Data Naming Conventions and Metadata Tags
Enforce standardized data naming conventions and metadata tagging. Consistent naming conventions and metadata tags simplify the mapping of data lineage, making it easier to track and trace data as it moves through different stages and processes.
Training and Education Programs
Conduct training and education programs for employees to enhance their understanding of the importance of data lineage. Train individuals involved in data management on how to capture, interpret, and utilize data lineage effectively. An informed workforce is essential for the successful establishment and maintenance of data lineage.
Regular Data Lineage Audits and Validation
Conduct periodic data lineage audits to validate the accuracy and completeness of the documented lineage. Audits help identify discrepancies, errors, or missing links in the lineage, allowing for timely corrections and improvements. The insights gained from audits also contribute to refining the data lineage documentation process.
Integration with Data Lineage Visualization Tools
Utilize data lineage visualization tools to create graphical representations of the data flow. Visualization aids in understanding complex data relationships and dependencies. Integrating these visualizations with data lineage documentation enhances comprehension and usage of the lineage information.
Organizations can construct an accurate, comprehensive, and dynamic data lineage that forms the cornerstone of effective data management by implementing these strategies and maintaining a diligent approach.
Capturing and Visualizing Data Lineage
Capturing and visualizing data lineage is also an important aspect of modern data management, empowering organizations to understand, monitor, and optimize their data flows.
Techniques for Capturing Data Lineage:
Here, we look at different techniques that facilitate the accurate capture of data lineage:
Automated Metadata Harvesting
Automated metadata harvesting is a pivotal technique in data lineage capture. This technique focuses on continuously and automatically extracting metadata from various data sources and processes. Organizations deploy sophisticated software tools designed to traverse through their vast data ecosystems, which can include databases, data lakes, and ETL (Extract, Transform, Load) processes. These tools, often referred to as metadata crawlers, automatically extract a wealth of information from these sources. This information typically includes details about data sources, schema structures, data transformations, and storage mechanisms. By compiling this metadata, organizations gain a comprehensive view of their data landscape. This technique not only simplifies lineage tracking but also aids in data governance, compliance, and quality assurance. The automation aspect is in the regular and systematic harvesting of metadata without being triggered by specific events. It provides a comprehensive, continuous view of the data landscape, making it easier to track lineage and manage data.
Metadata Ingestion and Parsing
When it comes to metadata ingestion, extracting data attributes from various sources is just the beginning. Organizations employ metadata parsers or custom scripts to transform this raw metadata into a standardized format. For instance, details about data source origins, transformation steps, and storage locations are parsed into a consistent structure. This standardized metadata format is important for effective lineage tracking and analysis. It ensures that lineage information remains uniform and can be easily correlated across different data elements, even if they originate from disparate systems or formats.
Event-Based Tracking
In event-based tracking, data lineage is captured through monitoring events, actions, or triggers within data processing systems. Whenever a significant event occurs, such as data transformation or storage, metadata is captured to track the lineage. Real-time monitoring allows organizations to maintain an up-to-date and accurate lineage map. Some events that can be tracked include data extraction from a source system, data loading into a target system, data transformation, such as cleansing, aggregating, or joining, data movement between systems, and data deletion or archival. Event-based tracking can also be automated in the sense that it captures lineage information when specific events occur. However, the key difference between it and automated metadata harvesting is that it’s event triggered. Metadata is captured in response to significant events or actions in data processing, such as data transformations, data loading, or data movement. This approach focuses on capturing lineage data at precise moments rather than continuously scanning the entire ecosystem. Event-based tracking ensures that lineage information is recorded as data flows through the system.
Data Lineage by Design
Data lineage by design is a technique for capturing data lineage as an integral part of the data architecture and integration processes. During the development phase, architects and developers consciously design systems to generate metadata and lineage information, ensuring seamless and automatic lineage capture during data processing. One example of data lineage by design is to use a data catalog to store and manage metadata about data assets. The data catalog can be configured to track the lineage of data as it flows through the system. Another example is to use a data pipeline management tool to automate the data processing process. The data pipeline management tool can be configured to capture lineage information at each stage of the pipeline.
Why is it Difficult to Capture Data Lineage Later?
Capturing data lineage later can be difficult because it requires organizations to track down and document all the different systems and processes that data flows through. This can be a complex and time-consuming task, especially for large and complex organizations. In addition, data lineage information may be scattered across different systems and tools. This can make it difficult to get a complete view of the data lineage. Finally, organizations may not have the necessary expertise to capture and manage data lineage. This can lead to incomplete or inaccurate lineage information.
Tools for capturing data lineage
Several tools and techniques are available to facilitate the capture and visualization of data lineage effectively. Here are some tools for capturing and visualizing data lineage:
- Talend Data Fabric is an integration platform that provides capabilities for capturing and visualizing data lineage. It allows users to document metadata, transformations, and lineage in an automated and centralized manner. The tool offers graphical lineage representations, simplifying the understanding of data flow and transformations.
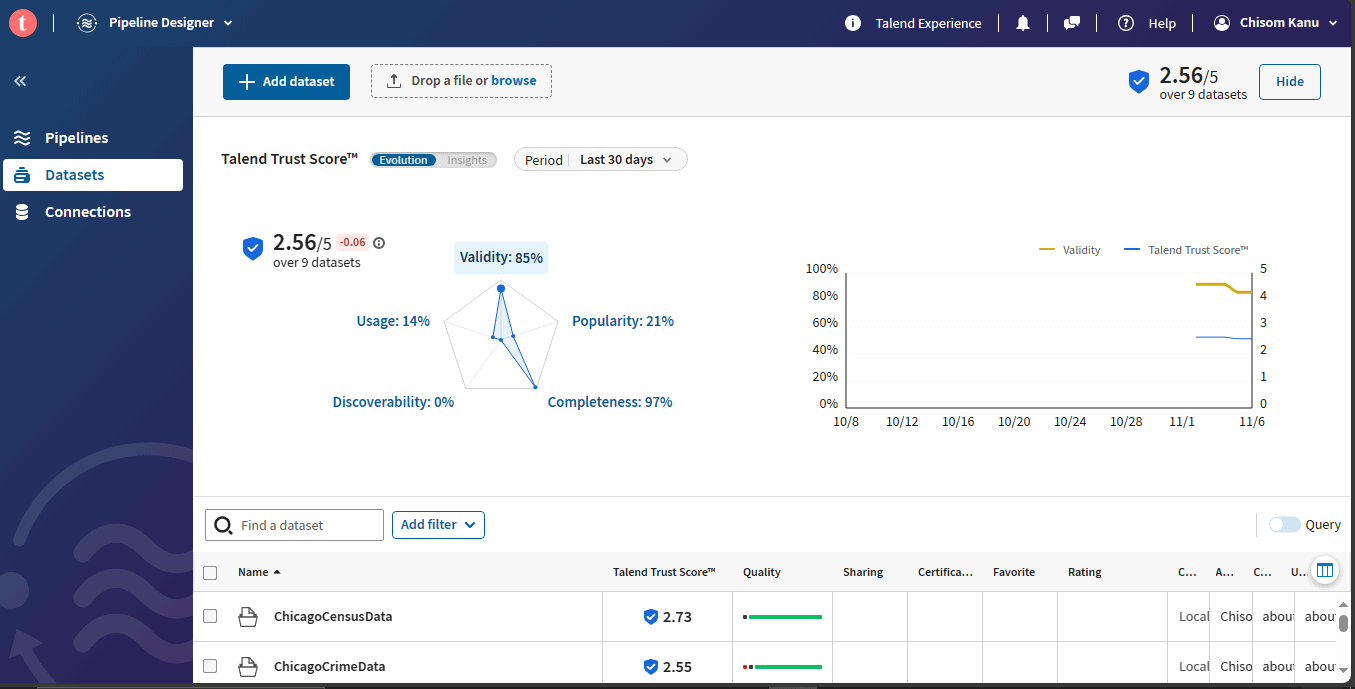
- Collibra Catalog is a data governance and cataloging tool that includes capabilities for capturing and visualizing data lineage. It allows users to define and capture metadata, relationships, and lineage information. The tool provides a user-friendly interface to visualize the flow of data and understand how it is transformed and utilized across various processes and systems. It is not only an asset for data lineage capture but also a valuable tool for overall data governance.
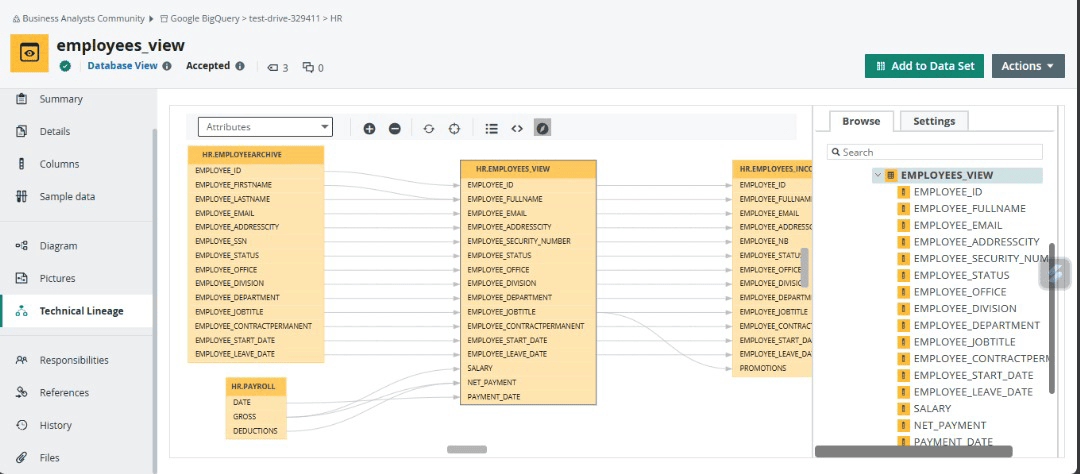
- Talend Data Fabric is an integration platform that provides capabilities for capturing and visualizing data lineage. It allows users to document metadata, transformations, and lineage in an automated and centralized manner. The tool offers graphical lineage representations, simplifying the understanding of data flow and transformations.
- Apache Atlas is an open-source tool that was first released in 2013. It is widely used for metadata management and governance. It allows organizations to capture and manage metadata, including lineage information. By integrating with various data processing and storage platforms, Apache Atlas offers a centralized repository for metadata, facilitating efficient lineage tracking and visualization, making it easier to trace data origins and understand how data flows through the organization’s infrastructure.
- Informatica Metadata Manager is a powerful tool that has been around for over 20 years, it assists organizations in capturing and documenting metadata, including data lineage. It seamlessly integrates with diverse data sources and provides a unified view of metadata, making it easy to trace data transformations and dependencies. The tool offers the ability to capture and manage metadata from a variety of data sources, including relational databases, data warehouses, data lakes, and big data platforms, the ability to visualize lineage information in a variety of ways, including interactive dashboards and reports.
- IBM’s Information Governance Catalog is a robust tool that enables organizations to capture, manage, and analyze metadata, including data lineage. It integrates with different data sources and applications to collect metadata, providing a comprehensive view of how data moves and transforms within the organization. The tool offers visualization features to represent lineage effectively, including interactive dashboards, reports, and graphs.
- The Alation Data Catalog is a cloud-native data catalog that facilitates capturing and visualizing data lineage. It automatically captures metadata and lineage information from various data assets, including relational databases, data warehouses, data lakes, and big data platforms, and presents it in a visually intuitive manner. Users can explore data flows, transformations, and dependencies through interactive visualizations, enhancing their understanding of the data lineage.
Techniques for Visualizing Data Lineage:
Here, we explore few techniques that facilitate the visualization of data lineage:
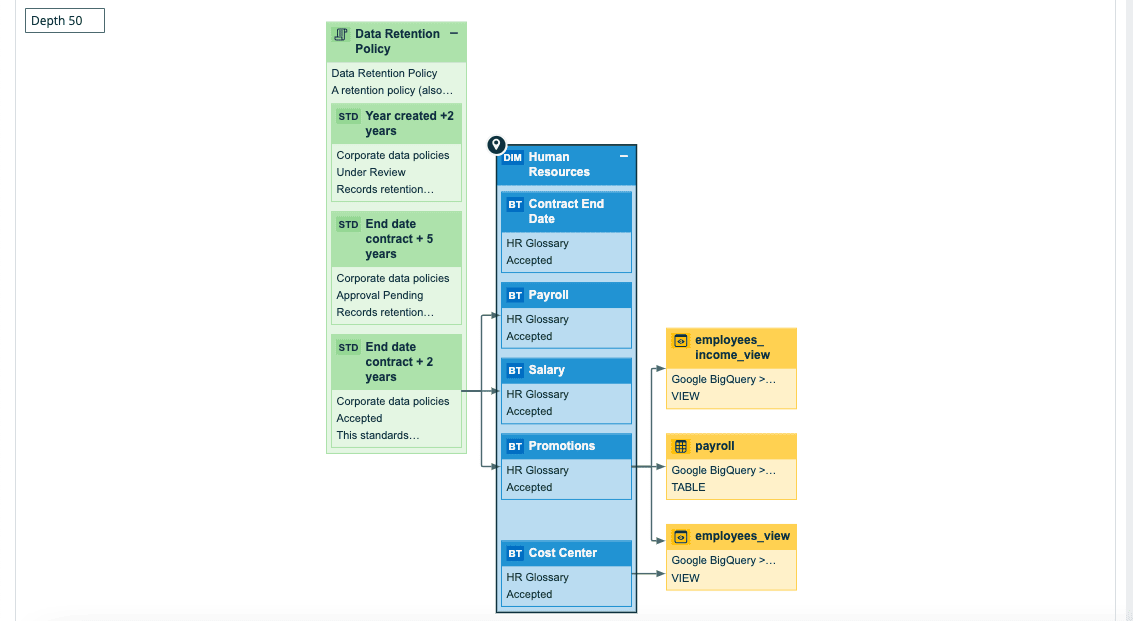
Graphical representation is a widely adopted technique for visualizing data lineage. Graphs, flowcharts, and diagrams are utilized to depict the flow of data from source to destination, along with the transformations and processes that data undergoes. Nodes represent data elements, while edges illustrate the connections and transformations.
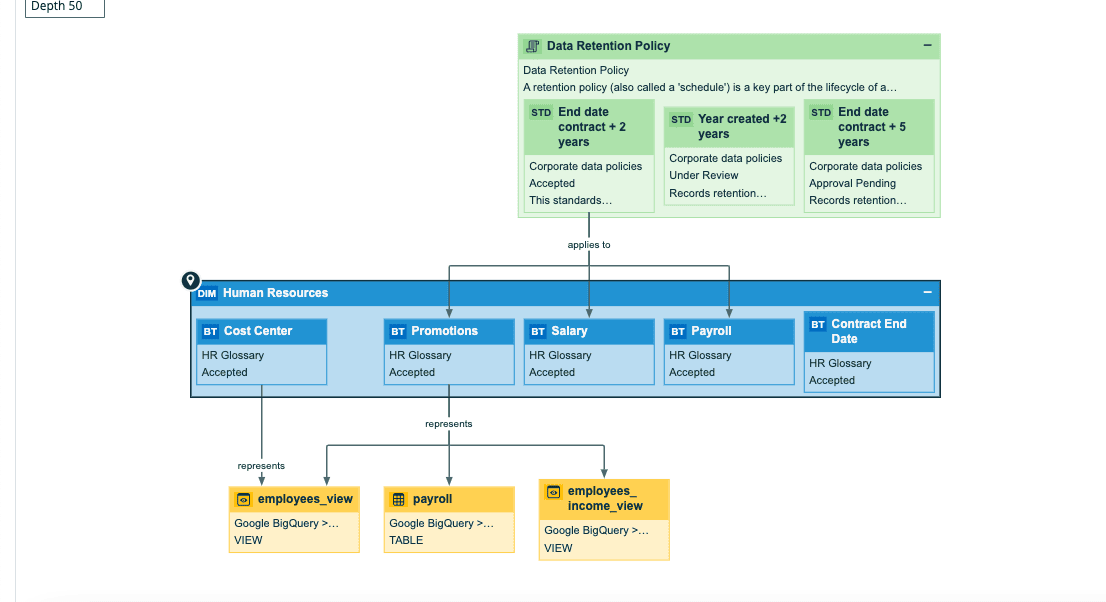
A hierarchical tree view of data lineage
The hierarchical tree view technique organizes data lineage in a tree-like structure, presenting a clear hierarchy of data sources, transformations, and destinations. Users can navigate through the tree, expanding or collapsing nodes to visualize the data flow and understand the lineage in a structured and organized manner.
The specific tools and techniques that you use to capture and visualize data lineage will depend on your specific needs and resources. However, here are some general tips:
- Start by identifying the data lineage that you want to capture. Do you want to capture the lineage of all your data or just a specific data set or flow?
- Choose the right tools and techniques for your needs. If you have a complex data environment, you may want to use an automated data lineage tool. If you have a smaller data environment, you may be able to capture data lineage manually using spreadsheets or other documentation tools.
- Use a variety of tools and techniques. There is no one-size-fits-all approach to capturing and visualizing data lineage. The best approach will vary depending on the specific data lineage that you want to capture and the tools and resources that you have available.
- Make sure that your data lineage is accurate and up to date. Data lineage is only useful if it is accurate and up to date. Be sure to review and update your data lineage regularly as your data environment changes.
Conclusion
Data lineage is an important component of modern data management. By tracking the flow of data over time, organizations can gain a deeper understanding of their data and how it is used. This information is essential for improving data quality, compliance, security, and business intelligence.
There are several ways to establish and maintain data lineage. The best approach for an organization will depend on its specific needs and resources. However, all organizations should follow certain best practices to maintain an accurate and comprehensive data lineage. Overall, data lineage is an essential tool for any organization that wants to get the most out of its data. By tracking the flow of data, organizations can improve data quality, enhance compliance, increase security, reduce costs, improve efficiency, and increase agility.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments