

Have you ever surfed the internet and felt overwhelmed by personalized advertisements that appear to know your every desire? Have you ever been amazed at how accurate some weather forecasts can be? These actions are based on data processing. EsProc SPL and SQL (note, SPL stands for Structured Processing Language and SQL stands for Structured Query Language). SQL is a major language widely encountered and used for data manipulation within relational databases. While EsProc SPL is another effective tool for data processing, especially suited for complex computations and in-memory operations, it is less commonly encountered. Both languages can serve different purposes and may be complementary, depending on specific data processing needs and sources. The programming language used for examples in this article is called SPL, and the development environment is called EsProc.
EsProc SPL and SQL meet the increasing need for efficient data processing and analysis. Whether you’re a data analyst, a researcher, or just working with large datasets, data processing is important. EsProc SPL and SQL are two programming languages specifically developed for data manipulation and analysis. Consider these tools in your data toolbox, each with strengths and drawbacks. Understanding these differences will allow you to select the best tool for the job, saving you time and effort. If you use tools like Apache Spark, Flink, or Alibaba AnalyticDB for data analysis, then EsProc SPL might be a language worth exploring. On the other hand, if you’re familiar with platforms like MySQL, PostgreSQL, or Microsoft SQL Server, then SQL is likely already in your toolkit.
EsProc SPL
For data scientists and analysts looking to take on challenging computations and work with large datasets, EsProc SPL (Structured Processing Language) proves to be an effective tool. EsProc SPL operates in memory. It means that instead of using the slower method of getting data from physical storage media, it loads your data straight into the RAM of the computer. EsProc SPL initially retrieves data from physical storage media, just like SQL-based systems, but it then loads this data directly into the computer’s RAM for faster processing.
This allows EsProc SPL to perform complex data manipulations more efficiently by leveraging the speed of in-memory computing. SQL systems also use in-memory processing, but they typically rely on the DBMS to manage data retrieval and memory usage. EsProc SPL is designed specifically for procedural data manipulation, making it particularly effective for handling intricate computational tasks in-memory. This in-memory method results in significant performance, particularly for complex computations involving huge datasets. Its extensive library of built-in operations enables you to carry out a wide range of data manipulation activities.
Consider these functions as pre-written instruments that you can easily incorporate into your scripts for data processing. Envision building machine learning models? This language provides the necessary tools to prepare and transform your data for analysis. Similar to programming languages like Python or Java, EsProc SPL uses a procedural approach to data processing. This implies that you, the user, provide a set of detailed instructions that guide the language’s manipulation of your data.
With this degree of control, you can modify the data processing pipeline to meet your unique requirements. Consider that the dataset you’re dealing with includes client purchase history. One possible use for an EsProc SPL script would be to filter purchases from the previous quarter, figure out how much each customer spent overall, and then classify clients based on their budget. You can accomplish complex data transformations with this level of granular control.
Key Features
Here are some key features of EsProc SPL:
Grid-Style Code: In EsProc, code is written in a grid, which offers several advantages:
- Intermediate Variable Names: Unlike traditional programming languages, you don’t need to name variables explicitly. You can directly reference the name of a previous cell in subsequent steps. For example: =A2.align@a(A6:~,date(Datetime)).
- Neat and intuitive: The grid-style code naturally aligns, making it easy to read. Indentation of cells indicates code blocks, and there’s no need for additional modifiers.
- Cell Name Handling: EsProc’s IDE automatically adjusts cell names when you insert or delete rows, ensuring consistency.
- Compact Code: Even for complex tasks, code in a cell occupies only one cell, maintaining the overall structure.
Calculation Functions: EsProc provides various functions for structured data processing:
- Sorting: =
Orders.sort(Amount) - Filtering: =
Orders.select(Amount*Quantity>3000 && like(Client,"*S*")) - Grouping: =
Orders.groups(Client; sum(Amount)) - Distinct Values: =
Orders.id(Client)
Symbolic References: EsProc uses symbols like ~, #, and [] to represent the current member, sequence number, and relative position. For instance, to reference the previous record, you can write [A1].
Installation process:
EsProc SPL is an external data processing tool. It’s not tied to any specific DBMS, which gives it flexibility but requires a separate installation:
- Download: Visit the EsProc SPL Official website » EsProc Download – Open-source SPL | SPL Official Website (raqsoft.com). There, you can download the latest release.
- Prerequisites: Ensure you have Java (JDK) installed on your system, as EsProc SPL is Java-based. You can download it from Here.
- After downloading, run it and click “Next” continuously to complete the installation.
At this point, EsProc SPL is ready to use
Click the “New” button in the upper left corner to create a new file.
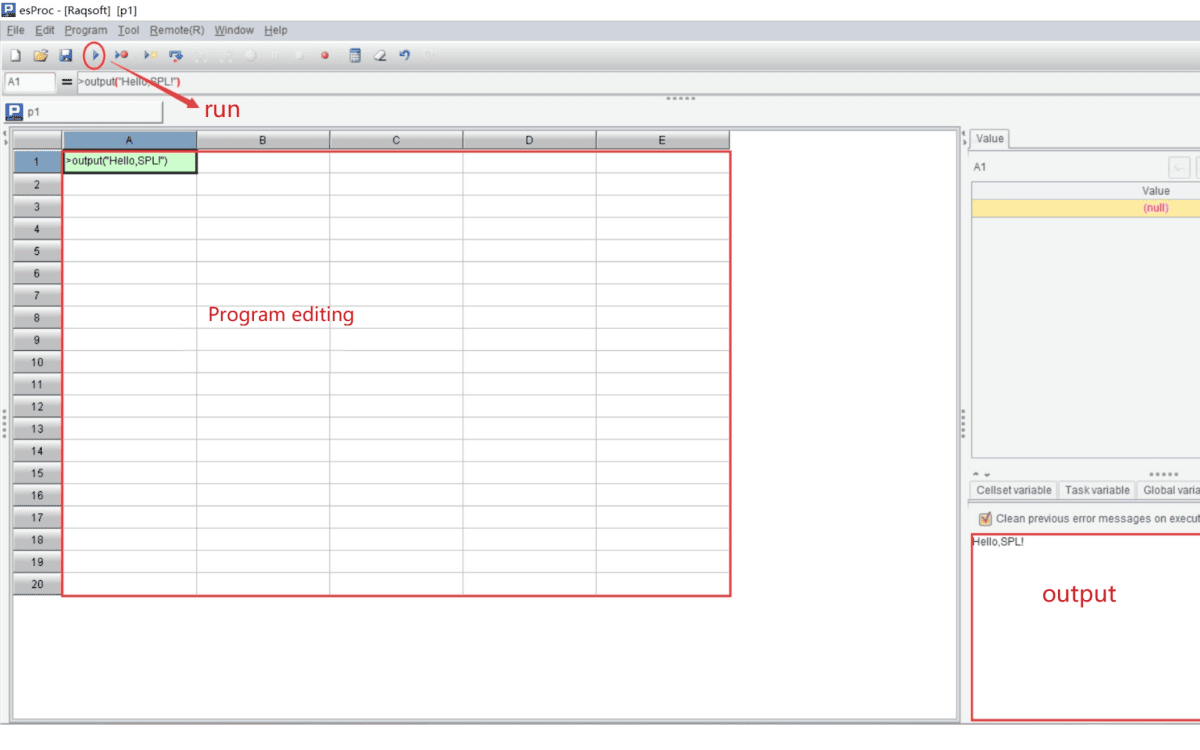
Then run the newly created “p1” file.
EsProc SPL can also connect to various data sources (JDBC for databases, files, and APIs). For databases, you’ll need the appropriate JDBC driver.
SQL
SQL, or Structured Query Language, has been the go-to language for interacting with relational databases for about 30 years. Because of its declarative nature, which makes data management and analysis easier, it is a widely used language for querying and manipulating data in relational databases. Because SQL operates on the fundamental principle of sets, users can perform operations on large datasets instead of individual entries.
You can describe the data you need using English-like commands, and the database engine will figure out the most efficient way to retrieve it. SQL excels at extracting specific data from relational databases. You can use commands like SELECT to pick out relevant columns and rows that meet your criteria.
SQL isn’t just about reading data; it also allows you to modify existing information. It provides commands like UPDATE and DELETE to perform these tasks efficiently. It offers tools for creating and managing the structure of your relational database. You can use statements and commands like CREATE TABLE to define new tables with specific columns and data types, ensuring your data is organized in a way that facilitates efficient storage and retrieval. SQL’s capacity to efficiently carry out intricate data retrieval and aggregation tasks is one of its main advantages. It allows users to easily extract significant insights from massive databases using capabilities like joins, subqueries, and window functions.
Moreover, SQL (or perhaps more appropriately, the RDBMS’ that support for transaction management ensures data integrity and consistency.
Installing SQL
SQL (Structured Query Language) is typically part of a Relational Database Management System (RDBMS) such as MySQL, PostgreSQL, Oracle, or SQL Server. The installation process varies slightly depending on the specific DBMS, but the general steps are similar:
- Download the DBMS: Go to the official website of the chosen DBMS (e.g., MySQL, PostgreSQL, Oracle, SQL Server).
- Select the version: Choose the appropriate version for your operating system and download the installer.
- Run the Installer: Execute the downloaded installer file and follow the on-screen instructions. This usually involves agreeing to the license terms, selecting the installation directory, and configuring initial settings.
- Set Up the Database: After installation, you may need to set up a new database instance, create user accounts, and configure network settings.
- Access the SQL Interface: Most DBMSs come with a command-line interface (CLI) and a graphical user interface (GUI) for interacting with the database using SQL.
Key Differences in Installation
- Integration vs. Standalone: SQL is part of your DBMS, while EsProc SPL is a standalone tool. This means EsProc SPL can work with data from multiple sources without being tied to one.
- Performance: SQL, being integrated, can offer better performance for queries within its DBMS. EsProc SPL, being external, might have more overhead but offers more flexibility.
- Portability: If you switch DBMSs, your SQL might need adjustments (different DBMSs have SQL dialects). EsProc SPL code is more portable since it’s not tied to a specific DBMS.
Comparison of EsProc SPL and SQL
EsProc SPL and SQL are used for data analysis but differ significantly in syntax and capabilities, understanding their differences and similarities helps you choose the right tool for the job.
Data Retrieval and Connection Methods
EsProc SPL establishes data connections using a driver class and connection URL, where users provide the necessary details such as the database location, user credentials, and password. After establishing the connection, the SPL script retrieves data using the query function, allowing for SQL-like queries to fetch specific columns from the database. In contrast, SQL retrieves data by writing queries directly, which fetch all rows and columns from the specified table. This method shows the differences in how each tool handles data connection and retrieval.
Let’s consider an EsProc SPL script to retrieve columns in a dataset. First, you start with the connection. Relational databases are not the only source of data for an EsProc SPL query, but they are very common. Directly connect to the database manually using the data source tool in the EsProc desktop or the MySQL driver class to connect to the connection URL in an SPL script:
|
1 2 3 |
=connect("com.mysql.jdbc.Driver", "hostname/database?user=username&password=your_passsword") =A1.query("SELECT column1, column2 FROM table_name") |
This will execute the following (assuming you have a server to connect to.)
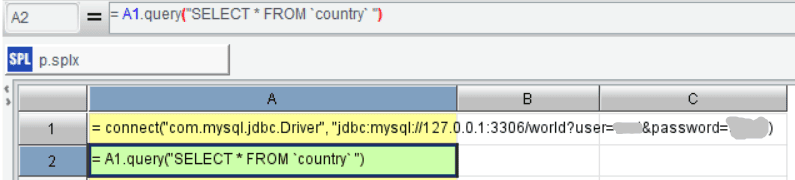
The SPL script establishes a quick and direct connection to the database. This connection is made by invoking the ‘connect’ function with the specified parameters, including the driver class and the URL containing the necessary connection details, such as the database location, user credentials, and password.
Following the connection, the script retrieves data from a different table (Country) within the database. (Note that in lines 1 and 2, the query fetches data from a relational database using an SQL query).
1. Connect to Database (A1): Connect to your MySQL database.
2. Retrieve Data (A2): Execute a query to fetch the relevant data from the database.
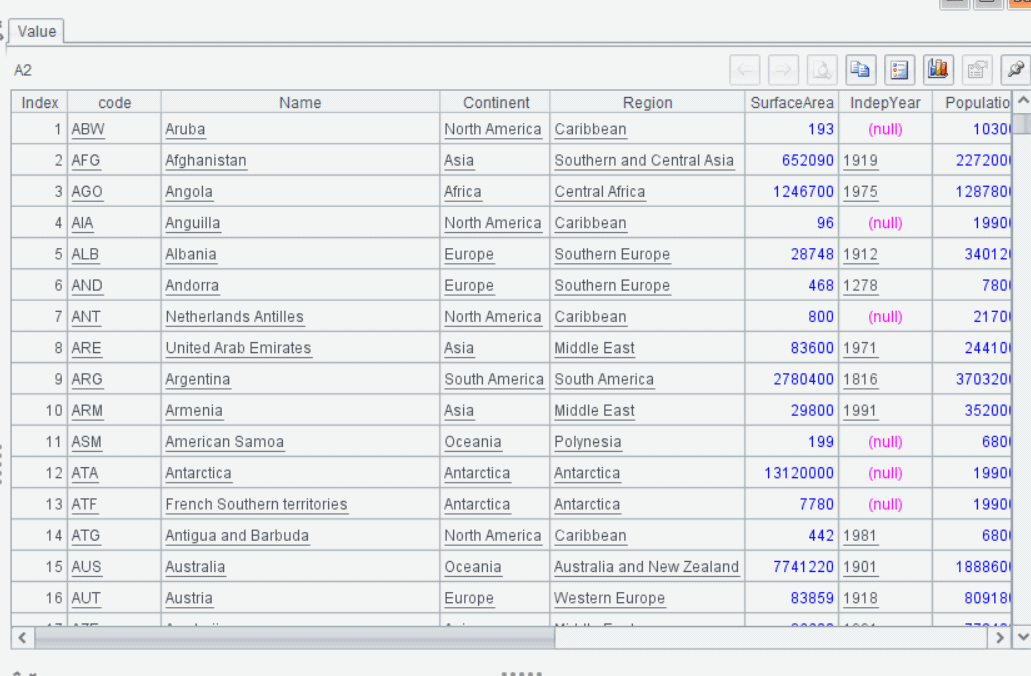
The result will be a grid showing the result of your query, in this case country details.
SQL, conversely, adopts a declarative syntax focused on specifying desired outcomes rather than the steps to achieve them. For instance, to retrieve data of a table in SQL:
|
1 |
SELECT * FROM `world`.`country`; |
Assuming you have a world.country table, most SQL tools will return something similar:
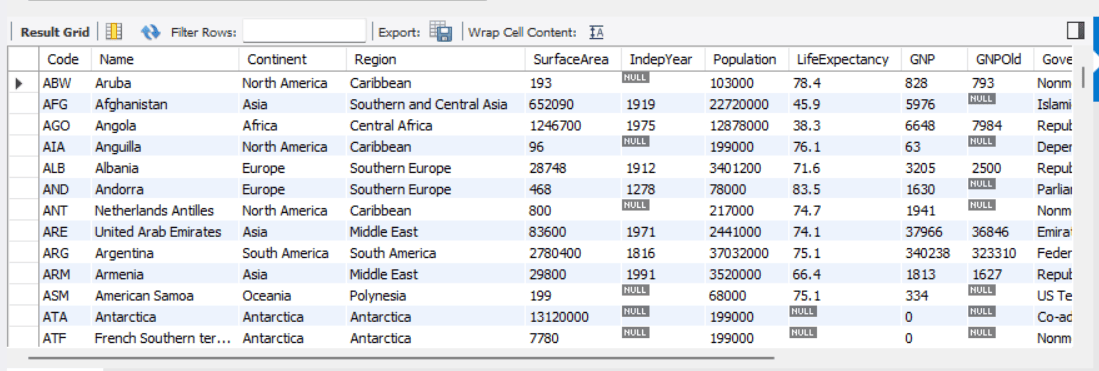
The query as written will retrieve all rows and columns from the country table in the world database. Each column represents a specific attribute of a country, and the result set will include the data for all countries in the table. SQL syntax is concise and intuitive, particularly for querying relational databases.
Approach to Data Manipulation
A key difference between EsProc SPL and SQL lies in their approach to data manipulation: user-guided instructions versus query optimization. When you use EsProc SPL, you provide a set of detailed instructions that guide the language’s manipulation of your data. This procedural approach means you explicitly define each step of the data processing sequence, allowing for intricate control over how data is handled. For instance, you can write scripts that perform specific operations like filtering, sorting, and transforming data in a particular order. This level of detail is advantageous for complex computations and customized data transformations that require a step-by-step process.
In contrast, SQL operates on a declarative structure. With SQL, you specify the desired outcome, and the database’s query optimizer determines the most efficient way to achieve it. You do not need to instruct SQL on how to perform the operations; instead, you describe what you want the result to look like. The procedural nature of EsProc SPL offers flexibility and precision, which is ideal for tasks that involve detailed, multi-step processes. However, this also means that users need to be more familiar with programming concepts to effectively utilize EsProc SPL.
Consider a scenario of processing data in stages, applying different transformations in each stage based on intermediate results.
In SQL
You will write one or more statements to execute. That statement might be quite complex (as is the following statement), and are sent to the server to be executed wholly on the server:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
WITH RankedLanguages AS ( SELECT cl.CountryCode, cl.Language, cl.Percentage, ROW_NUMBER() OVER (PARTITION BY cl.CountryCode ORDER BY cl.Percentage DESC) AS LanguageRank FROM CountryLanguage cl ), TopThreeLanguages AS ( SELECT rl.CountryCode, rl.Language, rl.Percentage FROM RankedLanguages rl WHERE rl.LanguageRank <= 3 ) SELECT c.Name AS Country, ttl.Language AS TopLanguage, ttl.Percentage AS PercentageOfSpeakers FROM TopThreeLanguages ttl JOIN Country c ON ttl.CountryCode = c.Code; |
This could might return something similar to:
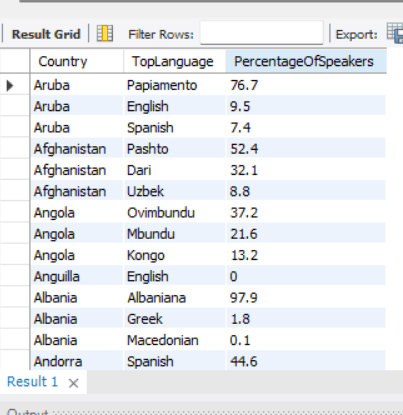
This SQL query first ranks the languages within each country based on the percentage of speakers using the ROW_NUMBER() function. Then, it selects only the top three languages for each country. Finally, it joins the results with the country table to retrieve the country’s names.
EsProc SPL solution
In SPL, this can be done in fewer lines of code, making it more concise and potentially easier to manage than SQL.
| A | |
| 1 | =connect@l("MySQL") |
| 2 | =A1.query("select * from countrylanguage") |
| 3 | =A2.groups(countrycode;top(-3;percentage):top3).conj(top3) |
| 4 | =A1.query("SELECT code, name AS country FROM country") |
| 5 | =A3.switch(countrycode,A4:code).new(countrycode.country,language,percentage) |
A1: Connects to a MySQL database.
A2: Retrieves all data from the countrylanguage table in the database.
A3: Groups the data from A2 by country code and calculates the top 3 languages spoken in each country, along with their respective percentages of speakers.
A4: Retrieves the country code and name from the country table in the database.
A5: Combines the results from A3 and A4, replacing the country code with the corresponding country name and arranging the data into columns for country, language, and the percentage of speakers. This would return something similar to the following:
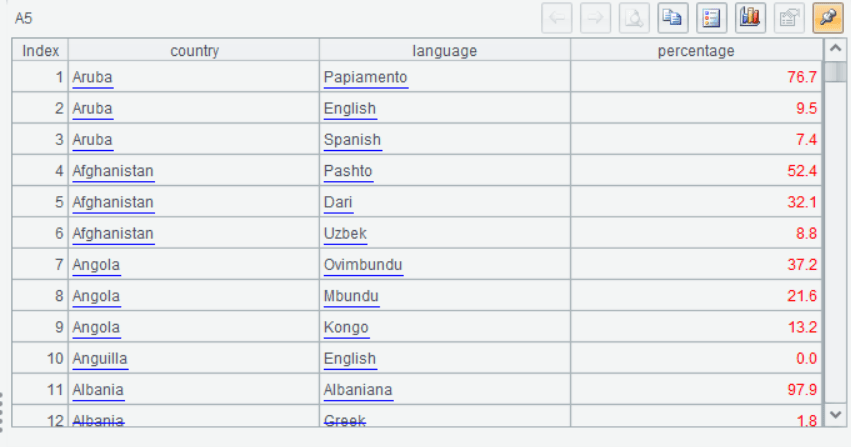
SPL’s approach emphasizes a step-by-step process, making it easier to understand the logic behind each transformation. The concise nature and flexibility of SPL make it a powerful tool for data transformation tasks, offering a streamlined and efficient approach compared to SQL in certain scenarios.
Cell-based Computational Model
EsProc SPL’s cell-based computational model allows users to execute individual statements or blocks of code independently. This feature enables rapid prototyping and iterative analysis. Users can modify queries, view intermediate results, and refine their analysis in real time without rerunning entire scripts. This approach significantly speeds up the data exploration process.
EsProc Implementation
To demonstrate an Ad Hoc Data Exploration with EsProc SP, you might run something like the following:
| A | |
| 1 | = MySQL.query("SELECT * FROM Country") |
| 2 | = A1.select(Population > 10000000) |
| 3 | = A2.groups(Continent; avg(LifeExpectancy):AvgLifeExpectancy) |
| 4 | = A3.select(AvgLifeExpectancy < 70) |
Intermediate results can be viewed and adjusted as needed in each step without rerunning the entire script. This modular approach is especially useful for exploratory data analysis.
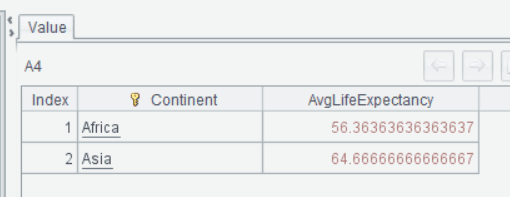
Analysts can leverage the strengths of this language for more advanced analytics while using SPL for fast, intuitive data preparation and initial exploration.
SQL Solution
SQL requires users to write complete queries before seeing results. Making changes often means rewriting and rerunning the entire query, which can slow the exploratory process, especially with large datasets or complex queries.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
WITH FilteredCountries AS ( SELECT * FROM Country WHERE Population > 10000000 ), AvgLifeExpectancy AS ( SELECT Continent, AVG(LifeExpectancy) AS AvgLifeExpectancy FROM FilteredCountries GROUP BY Continent ) SELECT * FROM AvgLifeExpectancy WHERE AvgLifeExpectancy < 70; |
This would return something similar to:
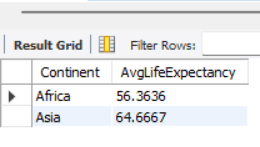
The task requires writing a complete query using common table expressions (CTEs) or subqueries. Each change necessitates rewriting parts of the query and rerunning it from scratch, which can be time-consuming with large datasets or complex queries.
Performance Tuning
EsProc SPL gives developers flexibility in optimizing performance through various techniques tailored to procedural programming. Performance tuning in EsProc SPL often involves optimizing individual script components, such as loops, conditional statements, and function calls, to minimize computational overhead and improve efficiency. Developers can employ optimization strategies like loop unrolling, where loops are manually expanded to reduce loop overhead, or loop fusion, where multiple loops are combined to eliminate redundant iterations.
Additionally, developers can use EsProc SPL’s support for parallel processing to distribute computational tasks across multiple cores or servers, thereby achieving faster execution times for data-intensive operations. By fine-tuning script logic and leveraging parallel processing capabilities, developers can optimize EsProc SPL scripts for improved performance across various data processing tasks. Using EsProc SPL for in-memory processing requires adequate RAM to handle large datasets effectively. Developers need to ensure sufficient memory is available to fully leverage the tool’s capabilities, especially when dealing with data-intensive operations. By optimizing script logic and utilizing parallel processing, EsProc SPL can distribute tasks across multiple cores or servers, which improves execution times and overall performance. However, to maximize these benefits, it’s important to have enough RAM to accommodate the data being processed, ensuring smooth and efficient operations.
SQL databases provide comprehensive tools and techniques for optimizing query performance, ensuring efficient data retrieval and manipulation. Performance tuning in SQL typically involves optimizing query execution plans, indexing strategies, and database configuration settings to improve overall system performance.
Database administrators and developers can use tools like query optimizers to analyze query execution plans and identify opportunities for optimization, such as selecting optimal join algorithms or index usage. Additionally, developers can employ indexing strategies like creating appropriate indexes on frequently queried columns to expedite data retrieval and minimize disk I/O operations.
Furthermore, SQL databases are typically optimized for multi-user environments, which involves managing concurrent access and ensuring data consistency and integrity. Database administrators can adjust configuration settings such as memory allocation and buffer pool size to optimize system performance and resource utilization. Techniques like indexing, partitioning, and query optimization are employed to handle large volumes of data and complex queries efficiently. SQL databases use these methods to maintain high performance and reliability, even when multiple users are accessing and modifying the data simultaneously. This multi-user optimization contrasts with tools like EsProc SPL, which, while powerful for single-user in-memory processing, may require additional considerations, such as increased RAM, for handling extensive, data-intensive tasks efficiently.
In comparing performance tuning capabilities, EsProc SPL and SQL offer different approaches tailored to their respective programming paradigms. EsProc SPL provides developers with granular control over script logic and execution, allowing for optimization at the procedural level. Techniques like loop optimization and parallel processing enable developers to fine-tune EsProc SPL scripts for improved performance across diverse data processing tasks.
On the other hand, SQL databases offer a comprehensive set of tools and techniques for optimizing query performance and database configurations. Query optimizers, indexing strategies, and configuration settings empower administrators and developers to enhance SQL database performance for efficient data retrieval and manipulation. In scenarios where the dataset is too large to fit into memory, EsProc SPL may face limitations or require additional hardware resources to handle the processing efficiently. On the other hand, SQL databases are optimized to handle data sets that exceed available memory through techniques like disk-based sorting and indexing, ensuring efficient data retrieval and manipulation even with massive datasets. Ultimately, the choice between EsProc SPL and SQL for performance tuning depends on factors such as the nature of the data processing tasks, the complexity of the data structures, and the available resources for optimization.
Learning Curve
EsProc SPL and SQL may seem like interchangeable tools for data manipulation, but their learning curves differ significantly. Choosing the right language depends on your programming experience and the complexity of the tasks you want to accomplish.
EsProc SPL operates similarly to languages like Python or Java. It utilizes keywords for data manipulation but offers more flexibility within scripts to define processing steps. This flexibility requires grasping programming concepts like loops, conditional statements, and functions, which can be a hurdle for beginners. While EsProc SPL boasts a growing community, it doesn’t have the same wealth of readily available learning resources as SQL. Finding tutorials, documentation, and online forums geared towards EsProc SPL might require more effort. If you’re already familiar with programming concepts in other languages, picking up EsProc SPL might be easier. The core logic of manipulating data through code structures can translate well from other programming experiences.
SQL takes a declarative approach. You describe the data you need using clear commands, and the database engine determines how to retrieve it. This eliminates the need to write complex logic within scripts like you would in EsProc SPL, making it easier for beginners to grasp. Its widespread adoption translates to a vast array of learning resources. Online tutorials, documentation, video courses, and even in-person training options are readily available to help you climb the SQL learning curve. Many spreadsheet programs incorporate basic SQL functionalities. If you’re comfortable using formulas and filtering data in spreadsheets, you’ve already taken the first step toward learning SQL. While SQL is beginner-friendly, complex data manipulation tasks might require a deeper understanding of relational database concepts and advanced SQL functionalities. While it simplifies writing queries, it can also create a layer of abstraction between you and the underlying processing logic. This can make troubleshooting performance issues or understanding complex queries more challenging.
The ideal learning path depends on your needs. If you’re comfortable with programming and prioritize raw processing speed, EsProc SPL might be worth the steeper initial learning curve. However, for beginners with no programming experience or those working with existing relational databases, SQL’s gentler slope and abundant resources make it a compelling choice. Ultimately, the best approach might be to start with SQL and explore EsProc SPL later if your data processing needs evolve. Remember, the journey of data mastery is a continuous learning process, and both EsProc SPL and SQL offer valuable tools.
Integration and Compatibility
EsProc SPL offers integration capabilities, allowing seamless interaction with various data sources, including databases, files, and web services. Its flexibility in data handling and input/output operations makes it suitable for integrating with diverse data pipelines and workflows. EsProc SPL supports a wide range of data formats, including CSV, Excel, JSON, and XML, enabling users to process data from disparate sources with ease. Additionally, EsProc SPL provides built-in functions and methods for interacting with databases, facilitating integration with relational and non-relational data stores. This versatility in data integration makes EsProc SPL a valuable tool for building end-to-end data processing solutions and analytical applications.
SQL offers broad compatibility across different database platforms and environments. SQL queries written for one database system can often be executed on other systems with minimal modifications, ensuring portability and interoperability. Moreover, SQL databases support standard data exchange formats such as CSV, JSON, and XML, enabling seamless integration with external data sources and applications. SQL’s compatibility extends to various programming languages and frameworks, allowing developers to incorporate SQL queries into their applications for data retrieval and manipulation tasks. This interoperability and compatibility make SQL a preferred choice for integrating with existing database infrastructures and applications.
Regarding integration and compatibility, EsProc SPL and SQL are similar in certain aspects but differ in others. EsProc SPL is incredibly adaptable and versatile, allowing for smooth integration with a wide range of data sources and formats. It is ideal for developing sophisticated data processing pipelines and analytical workflows since it supports custom data processing logic and input/output actions. In contrast, SQL’s compatibility across database platforms and computer languages makes it suitable for integrating with existing database infrastructures and applications.
Security
EsProc SPL does not have built-in security mechanisms like SQL databases. Since EsProc SPL is primarily used for data processing and manipulation, it does not inherently handle authentication, authorization, or data encryption. As a result, the responsibility for implementing security measures lies with the systems where EsProc SPL scripts are deployed (and the developers and administrators managing those systems) and on the systems where data is being retrieved from.
Security considerations may include securing access to EsProc SPL scripts, implementing proper authentication mechanisms for users accessing the scripts, and ensuring data confidentiality and integrity through encryption and access control measures. Developers utilizing EsProc SPL in sensitive environments must adhere to best practices and integrate EsProc SPL scripts into secure application architectures to mitigate potential security risks.
SQL databases typically offer robust security features to safeguard data and protect against unauthorized access and malicious activities. SQL databases support user authentication and authorization mechanisms, allowing administrators to control access privileges at the database, table, and column levels. Additionally, SQL databases provide data encryption capabilities to ensure confidentiality during transmission and storage. Security features such as role-based access control (RBAC), auditing, and encryption help organizations comply with regulatory requirements and industry standards for data protection. SQL databases also offer built-in mechanisms for securing sensitive data, such as masking and redaction, to prevent unauthorized exposure of confidential information.
In terms of security, SQL databases offer more comprehensive features and capabilities than EsProc SPL. SQL databases provide built-in mechanisms for user authentication, authorization, data encryption, and access control, ensuring robust security for sensitive data. On the other hand, EsProc SPL relies on external security measures implemented at the system level, making it less equipped to handle security requirements independently. Organizations utilizing EsProc SPL must implement additional security measures and integrate EsProc SPL scripts into secure application architectures to mitigate potential security risks effectively. Understanding the differences in security features is crucial for selecting the appropriate tool and implementing robust security measures to protect data assets in enterprise environments.
Conclusion
EsProc SPL and SQL offer data processing and manipulation, each with strengths and considerations. Choosing between EsProc SPL and SQL depends on the users’ specific requirements, preferences, and skill sets. For users who prioritize procedural control and flexibility in data processing tasks, EsProc SPL is an excellent choice. EsProc SPL’s procedural architecture allows for granular control over script logic, enabling developers to implement custom algorithms and optimizations tailored to specific data processing requirements. Developers and data analysts comfortable with procedural programming languages and requiring fine-grained control over data processing tasks will find EsProc SPL a valuable tool for building complex data processing pipelines and analytical workflows.
On the other hand, SQL is well-suited for users who prioritize simplicity, standardization, and broad compatibility. SQL’s declarative syntax simplifies query writing and allows users to specify desired outcomes without detailing the steps to achieve them. SQL databases offer comprehensive tools and techniques for optimizing query performance, ensuring efficient data retrieval and manipulation. Organizations with existing SQL databases, or those requiring seamless integration with standard relational database systems, will benefit from leveraging SQL for their data processing needs.
In the end, the choice between EsProc SPL and SQL depends on factors such as the nature of the data processing tasks, the familiarity and expertise of the users, and the compatibility requirements with existing systems and infrastructure. Both EsProc SPL and SQL offer data processing and analysis capabilities, and understanding each tool’s unique strengths and considerations is essential for selecting the most suitable option for achieving specific data processing goals.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved





Load comments