
In this article, I’ll describe six principles and patterns I use when building applications that use Entity Framework (EF). All six approaches are based on software principles and patterns that many of you will be familiar with. This article shows how I applied these principles and patterns in real-world applications that use EF. The six principles and patterns are:
- Separation of concerns – building the right architecture.
- The Service Layer – separating data actions from presentation action.
- Building business logic – using Domain-Driven Design with EF.
- Repositories – picking the right sort of database access pattern.
- Dependency injection – turning your database code into services.
- Performance tuning EF – get it working, but be ready to make it faster if you need to.
The code used in this article uses new .NET Core frameworks: EF Core and ASP.NET Core. However, these software principles and patterns apply equally well to the older Entity Framework, version 6 (EF6.x) framework and ASP.NET MVC5.
Note: I have built a full example application as part of a book I am writing, and the code is available in a GitHub repository. You can also see the working application on live site at http://efcoreinaction.com/.
The approaches I show are my way of implementing these principles and patterns. There are plenty of other ways to implement each of six topics, mine are just one of them. Have fun yourself developing your own techniques and libraries that will improve and accelerate your development.
Principle: Separation of concerns – building on the right architecture
There is a software principal called Separation of Concerns (SoC), which says that you should:
- Put code that has a similar, or strongly-related functions should be grouped together – in .NET terms – put in separate projects/assemblies. This called cohesion.
- Make each group/project as self-contained as possible. Each piece of code should have a clear interface and scope of work that is unlikely to change to because of other callers changing what they do. This is called low coupling.
Note: Here is a more in-depth article on Separation of Concerns if you want to look into SoC some more.
For simplicity, most examples of EF code on the web tend to show EF Core database commands being called directly from whatever application type they are using; for instance, having EF code inside a ASP.NET Controller action. This doesn’t follow SoC and nor does it really represent how real applications are written. To illustrate what is meant by a layered architecture, here is an example of a website I develop, which is an example book shop.
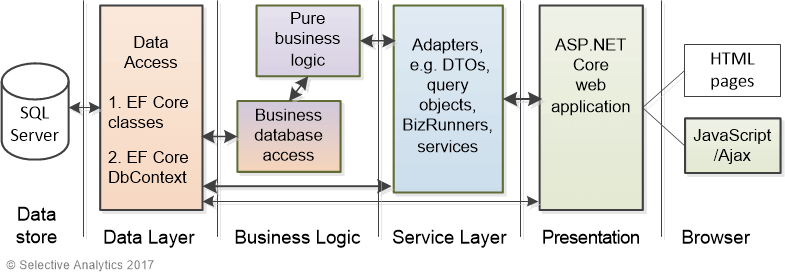
I could have used a number of different architectures, see this link for a good list, but the layered approach provides good SoC, and works well for small to medium web applications. Nowadays creating one executable program that containing the whole web application works well with for cloud hosting, where cloud providers can spin up more instances of the web application if it is under a heavy load. This involves running multiple copies of a web application, distributing the load between all the copies via a load-balancer. This known as scale out on Microsoft’s Azure and auto scaling on Amazon’s AWS.
The figure below shows how I apply SoC to my database access code within this layered architecture. It shows the same software structure, but I have highlighted all my EF database-access code in bubbles. The size of the bubbles relates to the amount of EF code you will find in each layer. Notice that the ASP.NET Core project and the pure business logic (BizLogic) project have no EF Core query/update code in them at all.
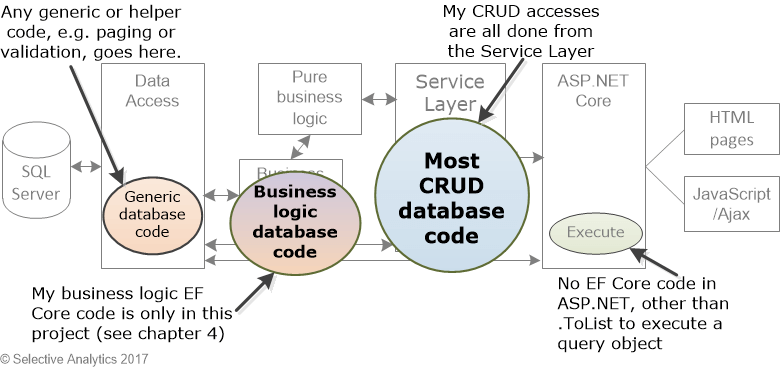
As I go through this article I will refer back to SoC, as it is an integral part of how I approach database applications.
Pattern: The Service Layer – separating data actions from presentation actions
For me the Service Layer, shown in the architecture diagram, is a really important layer. Dino Esposito says in his book Microsoft .NET: Architecting Applications for the Enterprise, published in 2009, that the Service Layer “sets a boundary between two interfacing layers” and Martin Fowler’s site link says the Service Layer “Defines an application’s boundary with a layer of services that establishes a set of available operations and coordinates the application’s response in each operation”. For me the Service Layer acts as both an adapter pattern and a command pattern in my applications.
In this section I’m going to concentrate on using the Service Layer acts as an adapter pattern and cover the command pattern later, in the section of business logic.
The Service Layer as an adapter
In an application there is often a data mismatch between the database/business logic and the presentation layer. The Domain-Driven Design (DDD) approach, which I describe in the next section, says that the database and the business logic should be focused on the business rules, while the Presentation Layer is about providing the user with an intuitive means to use the system, or in the case of a web service, providing a standard and simple API.
I use the Service Layer as the layer that understands both sides and can transform the data between the two worlds. This keeps the business logic and the database uncluttered by the presentation needs, such as drop-down lists and json AJAX calls. Similarly, the presentation layer can render the data more efficiently if the Service Layer delivers that data in exactly the format the presentation layer needs.
When dealing with database accesses via EF, the Service Layers use the adapter pattern to transform from the data layer/business logic layers to/from the presentation layer. Databases tend to minimise duplication of data and maximises the relational links between data, while the presentation layer is about showing the data in a form that the user finds useful.
The figure below shows an example of this difference in approach. Our example site needs to display a list of books with a number of details and even discounts and promotions. You can see how I have to pick data from lots of different tables in the database, and do some calculations, to form a summary of a book in my book list display.

Note: You can see this book list in action on the live site that hosts the example book selling site, at http://efcoreinaction.com/
EF provides a way of building queries, called select loading, that can ‘pick out’ the relevant columns from each table and combine them into a DTO/ViewModel class that exactly fits the user view. I apply this transform in the Service Layer, along with other sorting, filtering and paging features. The listing below is the SELECT query using EF Core to build the book summary you just saw in the figure above.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
public static IQueryable<BookListDto> MapBookToDto(this IQueryable<Book> books) { return books.Select(p => new BookListDto { BookId = p.BookId, Title = p.Title, Price = p.Price, PublishedOn = p.PublishedOn, ActualPrice = p.Promotion == null ? p.Price : p.Promotion.NewPrice, PromotionPromotionalText = p.Promotion == null ? null : p.Promotion.PromotionalText, AuthorsOrdered = string.Join(", ", p.AuthorsLink .OrderBy(q => q.Order) .Select(q => q.Author.Name)), ReviewsCount = p.Reviews.Count, ReviewsAverageVotes = p.Reviews.Count == 0 ? null : (decimal?)p.Reviews .Select(q => q.NumStars).Average() }); } |
Note: The code above wouldn’t work with EF6.x because it includes the command string.Join that cannot be converted into SQL but EF6.x. EF Core has a called Client vs. Server Evaluation, which allows methods that cannot be translated to SQL to be included. They are run after the data has been returned from the database.
Yes, this code is complex but, in order to build the summary, we need to pull data from lots of different places and do some calculations at the same time, so that’s what you get. I have built a library called GenericServices (currently only available for EF6.x) with automates the building of EF select loading commands like this by using a LINQ Mapper called AutoMapper. This significantly improves the speed of development of these complex queries.
Pattern: Building business logic – using Domain-Driven Design
Real-world applications are built to supply some sort of service, ranging from holding a simple list of things on your computer through to managing a nuclear reactor. Every different real-world problem has a set of rules, often referred to as business rules, or by the more generic name, domain rules.
Another book that I read some time ago that had a big impact on me was “Domain-Driven Design” by Eric Evans. The Domain-Driven Design (DDD) approach says that the business problem you are trying to solve must drive the whole of the development. Eric then goes on to explain how the business logic should be isolated from everything else other that the database classes so that you can give all your attention to what Eric Evans calls the “difficult task” of writing business logic.
There are lots of debates about whether EF Core is suitable for a DDD approach, because the business logic code is normally separate from the EF entity classes which it maps to the database. However, Eric Evans is pragmatic on this point and says in the section entitled “Working within your (database access) Frameworks” that, and I quote:
“In general, don’t fight your framework. Seek ways to keep the fundamentals of domain-driven design and let go of the specifics when your framework is antagonistic”
Page 157, Domain-Driven Design, by Eric Evans, 2004.
Note: I had to look up the word antagonistic: it means “showing or feeling active opposition or hostility towards someone or something”.
Here is a summary of a DDD approach that works with EF:
- The business logic has first call on how the database structure is defined
Because the problem I am trying to solve, called the “Domain Model” by Eric Evans, is the heart of the problem then it should define the way that the whole application is designed. Therefore, I try to make the database structure, and the entity classes, match my business logic data needs as much as I can.
- The business logic should have no distractions
Writing the business logic is difficult enough in itself, so I isolate it from all the other application layers, other than the entity classes. That means that when I write the business logic I only have to think about the business problem I am trying to fix. I leave the task of adapting the data for presentation to the Service Layer in my application.
- Business logic should think it is working on in-memory data
This is something Eric Evans taught me – write your business logic as if the data was in-memory. Of course there needs to be some a ‘load’ and ‘save’ parts, but for the core of my business logic I treat, as much as is practical, the data as if it is a normal, in-memory class or collection.
- Isolate the database access code into a separate project
This fairly new rule came out of writing an e-commerce application with some complex pricing and deliver rules. Before this I used EF directly in my business logic, but I found that it was hard to maintain, and difficult to performance tune. Now I have another project, which is a companion to the business logic, and holds all the database access code.
- The business logic should not call EF Core’s SaveChanges directly
The business logic does not call EF Core’s SaveChanges method directly. I have a class in the Service Layer whose job it is to run the business logic – this is a case of the Service Layer implementing the command pattern. and, if there are no errors, it calls SaveChanges. The main reason is to have control of whether to write the data out, but there are other benefits that I describe in the book.
The figure below shows the original software architecture, but with the focus on how the business logic is handled. The five numbers, with comments, match the numbered guidelines above.
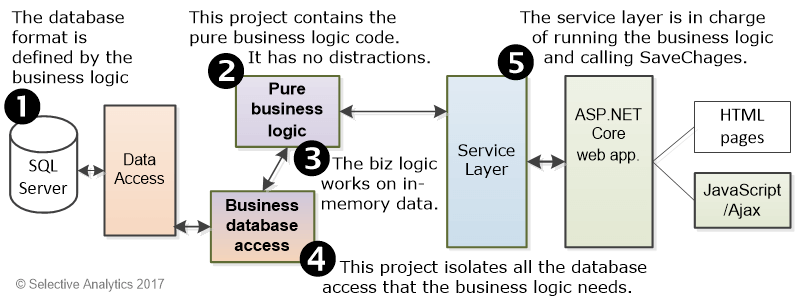
In my book I use the processing of an order for books as an example of a piece of business logic. You can see this business logic in action by going to the companion live site, http://efcoreinaction.com/, where you can ‘buy’ a book. The site uses an HTTP cookie to hold your basket and your identity (saves you having to log in). No money needed – as the terms and conditions says, you aren’t actually going to buy a book.
The code is too long to add to this article, but I have written another article called Architecture of Business Layer working with Entity Framework (Core and v6) which covers the same area in more detail and contains plenty of code examples.
Pattern: Picking the right sort of database access pattern
There are a number of different possible ways in which we can build EF database accesses inside an application, with different extents by which we can hide the EF access code from the rest of the code. In the figure below I show four different data access patterns.
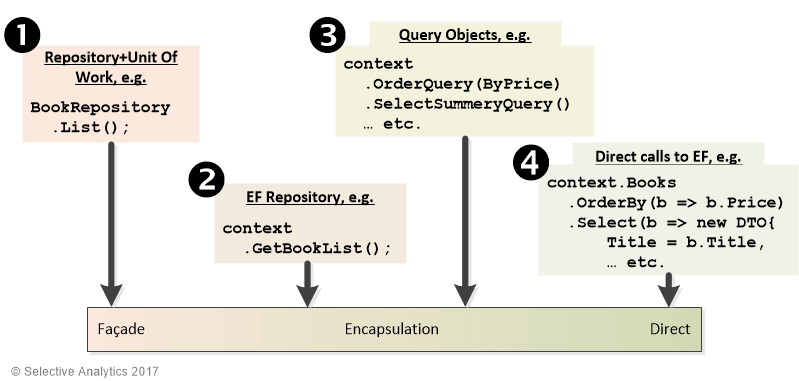
The four types of database access patterns are:
- Repository + Unit of Work (Repo+UOW): This hides all the EF Core behind code that provides a different interface to EF. This would allow you to replace EF with another database access framework with no change to the methods that call the Repo+UOW.
- EF repository: This is a repository patterns that, unlike the first pattern, ‘Repo+UOW’, doesn’t try and hide the EF code. EF repositories assume that you as developer know the rules of EF, such as using tracked entities and calling SaveChanges for updates, and you will abide by them.
- Query Object: Query objects encapsulate the code for a database query, that is a database read. They can hold the entire code for a query, or for complex queries it might hold just part of a query. Query objects are normally built as extension methods with IQueryable<T> inputs and outputs, so that they can be chained together to build more complex queries.
- Direct calls to EF: With this pattern, you simply place the EF code you need in the method that needs it. For instance, all the EF code to build a list of books would be in the ASP.NET action method that shows that list.
Note: I have left out a Domain-Driven Design (DDD) EF database pattern from my diagram for now. A DDD EF database pattern has classes that control access to parts of the database, especially on what DDD calls ‘aggregates’. I have found doing this in EF6.x difficult to achieve, but the new EF Core framework makes this more possible. I haven’t had time to look at this yet, so I left it out, but is definitely a possible option.
I used the Repo+UOW pattern, which was the recommended approach at the time, in a big project in 2014 – and I found it was really hard work. I, and many others, realised that Repo+UOW wasn’t the way to go – see my article ‘Is the Repository pattern useful with Entity Framework?’. The Repo+UOW can be a valid pattern in some cases where hiding of the certain part of the data is needed, but I think there are better ways to do this with some of the new EF Core features, such as backing fields.
At the other end of the spectrum is the pattern of having direct calls to EF in the method that needs it. This fails the separation of concerns principal because the database code is mixed in with other code not directly involved in database issues.
So, having ruled out the two extremes I would recommend:
- Query Objects for building queries, often breaking down large queries into a series of query objects. The previous listing in this article of the method called
MapBookToDto, which is a query object. - For Create, Update and Delete (and business logic which I cover later) I use a EF repository pattern, that is, I create a method that encapsulates the EF database access. This isolates the EF code and makes it easier to refactor or performance tune that code. The listing below shows a class with two EF repository methods for changing the publication date of a book in my example book selling site.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
public class ChangePubDateService : IChangePubDateService { private readonly EfCoreContext _context; public ChangePubDateService(EfCoreContext context) { _context = context; } public ChangePubDateDto GetOriginal(int id) { return _context.Books .Select(p => new ChangePubDateDto { BookId = p.BookId, Title = p.Title, PublishedOn = p.PublishedOn }) .Single(k => k.BookId == id); } public Book UpdateBook(ChangePubDateDto dto) { var book = _context.Books.Find(dto.BookId); book.PublishedOn = dto.PublishedOn; _context.SaveChanges(); return book; } } |
Pattern: Turning your database code into services
I have used dependency injection (DI) for years and I think it’s really useful approach. I want to show you a way you can inject your database access code into an ASP.NET Core application.
Note: If you haven’t used DI before have a look at this article for an introduction, or this longer article from another by Martin Fowler.
The benefits of doing this are twofold. Firstly, DI will dynamically link together your database access to the parts of the presentation/web API code that need it. Secondly, because I am using interfaces, it is very easy to replace the calls to the database access code with mocks for unit testing.
Here are the main steps, with links to online documentation if you want to follow it up.
You need to make each of your database access code into thin repositories. That is a class containing a method, or methods, that the front-end code needs to call. See the ChangePubDateService class listed above.
- You need to add an interface to each EF repository class. You can see the
IChangePubDateServiceinterface applied to theChangePubDateServiceclass listed above. - You need to register your EF repository class against its interface in the DI provider. This will depend on your application. For ASP.NET Core see this article.
- Then you need to inject it into the front-end method that needs it. In ASP.NET Core you can inject into an action method using the [FromServices] attribute. Note: I use this DI parameter injection rather than the more normal constructor injection because it means I only create the class when I really need it, i.e. it is more efficient this way.
Note: I realise that is a lot to take in. If you need more information can look at the GitHub repo associated with my book. Here are some useful links:
- Steps 1 and 2: The
ChangePubDateServiceclass. - Steps 3:
- The normal way using ASP.NET DI
- The more elegant way using AutoFac.
- Step 4: The AdminController action method.
At the end of this you have a method you can call to access the database. The listing below shows an ASP.NET Core action method that calls the UpdateBook method of the ChangePubDateService class that I listed previously. Line 4 has the [FromServices] attribute that tells the DI provider to inject the ChangePubDateService class into the parameter called service.
|
1 2 3 4 5 6 7 8 |
[HttpPost] [ValidateAntiForgeryToken] public IActionResult ChangePubDate(ChangePubDateDto dto, [FromServices]IChangePubDateService service) { service.UpdateBook(dto); return View("BookUpdated", "Successfully changed publication date"); } |
Note: There is a way to do parameter injecting into an ASP.NET MVC action method, but it involves you having to override the default Binder. See the section “How DI is used in SampleMvcWebApp” at the bottom of this page, and my DiModelBinder in the associated GitHub repo.
The result of all this is that database code is nicely separated into its own class/method and your front-end code just has to call the method, not knowing what it contains. And unit testing is easy, as you can check the database access code on its own, and replace the same code in your front-end call with a mocking class that implements the interface.
Principle: Get your EF code working, but be ready make it faster if you need to.
It is a known good approach when developing software to get it to work first, and then worry about making it faster. A more nuanced version of this, attributed to Kent Beck, is Make it Work. Make it Right. Make it Fast. Either way, these principle says we should leave performance tuning to the end. I would add a second part: you should only performance tune if you need to.
In this article I am talking about database accesses via EF. The main benefit of using EF is that I develop pretty complex database accesses in EF really quickly – at least five times faster than using ADO.NET or Dapper. That covers the “get it working part”. The down side is that EF doesn’t always produce the best performing SQL commands: sometimes it’s because EF didn’t come up with a good SQL translation, and sometimes it’s because the LINQ code I wrote isn’t as efficient as I thought it was. The first question is: does it matter?
For example, I developed a small e-commerce site (the code took me 10 months) which had a little over a hundred different database accesses and about twenty tables. More than 60% of the database accesses were on the admin side, with maybe 10% of accesses that really mattered to the paying user.
To show this graphically I have picked out three features from my example book selling site and then graded them by two scales:
- Vertically, what the user expects in terms of performance.
- Horizontally, how difficult is the database access.
This gives you the figure below, with top right highlighted as area where we really need to think about performance tuning.
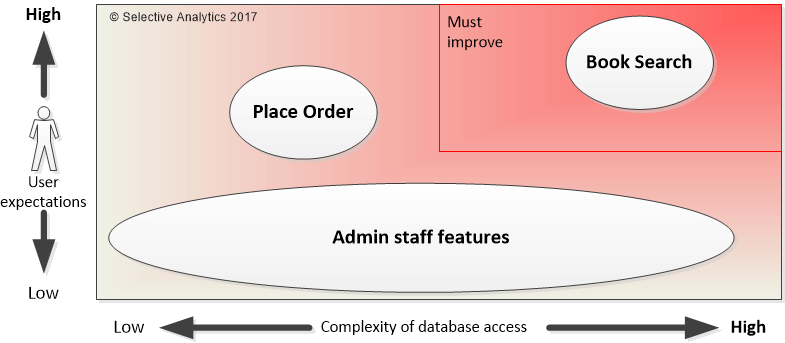
My analysis says that only the book search query needs work to improve it. The user is used to fast searches thanks to Google etc. and will get frustrated if our application is too slow. Looking at the complexity of the book search, which includes filtering on things like average user votes, I can see that it produces some rather complex database access commands.
Planning for possible performance tuning
I totally agree with the idea that you shouldn’t try to tune for performance too early, but it is still sensible to make provision for the possibility that you might have to performance tune. All six approaches I have described, especially that of encapsulating the databases accesses, means that my database code is clearly isolated, and open for performance tuning.
It turns out that the EF Core code for my book search performs badly, but there is plenty I can do about that. In fact, I have mapped out a whole section towards the end of my book where I show how I can improve the book search in a series stages, each getting more complex and taking more development time. They are:
- Can I improve the basic EF commands by rearranging or refining my EF code?
- Can I convert some or all of the EF code into direct SQL commands, calculated columns, store procedures etc.?
- Can I change the database structure, such as de-normalising the database, to improve the search performance?
Improving the book search will take quite a bit of time, but it’s worth it in this application. Quite honestly, the other features aren’t worth the effort because they are fast enough using standard EF Core commands.
So, my practice is to develop database accesses quickly with EF, but organise the code so that I encapsulate the database code cleanly. Then, if I have a performance problem, I can tune the database access code with minimal impact on other parts of your application.
Conclusion
Like many others, I started as programmer by writing long methods which were intertwined with each other – they worked, but the code was hard to understand, debug and maintain. However, by taking the principles and practices from the software giants and worked out how to apply them real applications then my code has become more robust, easy to test and easy to improve – and I write code much faster too.
For me, there is a big difference between being able to recognise a great idea and working out how it could help me. I instantly loved some books, such as Eric Evans “Domain-Driven Design” but it has still taken two or three projects before I had an implementation that works really well for me. I don’t think I’m unusual in this, as learning any new technique takes some time for it to become smooth and natural.
There are many great software thinkers out there and some great principles and practices. So the next time you think “there must be a better way of doing this” then go and have a look for other people’s thoughts. It’s a journey, but the reward is becoming a better developer.
Further Reading
I have written some articles over the years Manning Publication approached me to write a book about Entity Framework Core (EF Core). The book is called Entity Framework Core in Action and is now on early-access release i.e. if you buy now you will get the chapters as I write them, and the full book when it’s finished. Readers of Simple-Talk are entitled to 40% off the price of the book, Entity Framework Core in Action, with code entityfcore
This article uses code and figures from my book, which is based on the new .NET Core frameworks: EF Core and ASP.NET Core.
You might find these other articles of interest too:
- Architecture of Business Layer working with Entity Framework (Core and v6)
- Is the Repository pattern useful with Entity Framework?
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved
Load comments