

Azure SQL Database introduced a native JSON data type that stores JSON documents more efficiently than VARCHAR(MAX) and enables native CHECK constraints for JSON validation. Alongside the new data type, Azure SQL added JSON_ARRAYAGG (aggregate JSON values into an array), JSON_OBJECTAGG (aggregate key-value pairs into an object), and JSON_OBJECT (construct JSON objects from arguments) – all ANSI SQL-standard functions.
These features are confirmed for SQL Server 2025, making the techniques in this article directly applicable to on-premises SQL Server in the near future. This guide covers creating JSON columns, adding validation constraints, and using the new aggregation functions for practical JSON construction scenarios.
The new JSON field type and new functions in Azure SQL brings a new world of possibilities for JSON manipulation in SQL Databases. These features are slated to be a part of SQL Server 2025 as well.
Let’s analyze some practical uses of these features.
Read also: Storing and parsing JSON in SQL Server with VARCHAR/NVARCHAR
Creating and using a JSON column
Before this new field type, JSON data was typically stored in varchar(max) columns. There are many features to use with JSON values stored in varchar(max) columns and variables, but storing JSON as regular strings is still limited.
The built-in JSON type expands the possibilities. Using an actual JSON column, it becomes easier to build constraints related to JSON columns, for example.
Let’s see how to create a table and insert records using this new type.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
DROP TABLE IF EXISTS dbo.testOrders; CREATE TABLE dbo.testOrders ( order_id int NOT NULL IDENTITY, order_info JSON NOT NULL ); INSERT INTO dbo.testOrders (order_info) VALUES (' { "OrderNumber": "S043659", "Date":"2022-05-24T08:01:00", "AccountNumber":"AW29825", "Price":59.99, "Quantity":1 }'), (' { "OrderNumber": "S043661", "Date":"2022-05-20T12:20:00", "AccountNumber":"AW73565", "Price":24.99, "Quantity":3 }'); select * from testOrders; |
The output from the SELECT statement will look like this. If you grab the value from the JSON columns, you will see it looks just like the input.
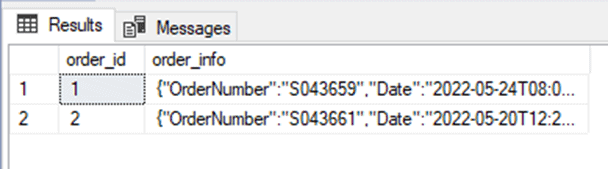
The format does not make a difference when you insert the data, if you change the first of the inputs to one long string, like the following:
|
1 2 |
VALUES ('{"OrderNumber": "S043659", "Date":"2022-05-24T08:01:00", "AccountNumber":"AW29825","Price":59.99,"Quantity":1}') |
There will be no difference between the values you see in the structures and output.
Creating a CHECK Constraint for a JSON type
One of many advantages of having a native JSON type is that you can use it to validate the structure (or values) in the JSON data. Consider the table in the example above: How could we prevent inserted records with bad JSON values based on our requirements?
For example, how can we prevent a JSON order without the attribute Price to be inserted? The creation of a constraint is much easier than it was before. :
|
1 2 3 |
alter table testOrders add constraint chkPrice CHECK (JSON_PATH_EXISTS(order_info, '$.Price') = 1) |
As a result, we have an actual JSON validation when data is inserted or modified. Any attempt to insert poorly formed order structures will be blocked, as illustrated in the image below:
Try to execute this code:
|
1 2 3 4 5 6 7 8 |
INSERT INTO dbo.testOrders (order_info) VALUES (' { "OrderNumber": "S0436663", "Date":"2022-05-24T08:01:00", "AccountNumber":"AW29827", "Quantity":1 }') |
And it will not create the data, but will fail with an error similar to the following:
Msg 547, Level 16, State 0, Line 1
The INSERT statement conflicted with the CHECK constraint "chkPrice". The conflict occurred in database "Testing", table "dbo.testOrders", column 'order_info'.
In this way, we can ensure our data will be way more consistent by using JSON fields and constraints.
Methods to Query the Data
There are at least two different methods to query the data: using the FOR JSON or using the JSON_ARRAYAGG aggregation function. FOR JSON is not new, it was introduced in SQL Server 2016.
JSON_ARRAYAGG, on the other hand, is one of the new JSON functions released in Azure SQL. It is an aggregation function, such as SUM, MAX or MIN. This means this function can aggregate the content of a field among many records and generate a JSON array as a result. As with every aggregation function, this can also be done according to the use of a GROUP BY.
It’s important to compare the new function with previously existing features to generate JSON data and in this way discover the new possibilities this function brings to us. Let’s analyze how both work and understand what was already available and what are the new features.
Let’s create a table for a customers and orders type scenario:
|
1 2 3 4 5 |
DROP TABLE IF EXISTS dbo.testJSON; CREATE TABLE testJSON (Id int identity(1,1) not null, CustomerName varchar(50), Orders JSON) |
The example is based on the AdventureworksLT database. This database can be provisioned as a sample database when provisioning an Azure SQL Database on Azure.
Editor note: it is a relatively painless operation if you have any experience with Azure SQL Databases. You can find more details here about restoring the database to your environment: AdventureWorks Sample Databases
This database has customers, order headers and order details. We can join these records and transform them into a JSON document for each customer.
We can use FOR JSON to create a JSON result and CROSS APPLY to get the orders for each customer. We need to use INSERT/SELECT to insert the records in the test table.
This is the code to fill the test table, it will create data with arrays in the Orders column:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
insert into testJSON(Id, CustomerName, Orders) select FirstName + ' ' + LastName as CustomerName, t.* from SalesLT.Customer c cross apply (select (select ProductID, UnitPrice, OrderQty, so.SalesOrderID from SalesLT.SalesOrderDetail so inner join SalesLT.SalesOrderHeader SOH on so.SalesOrderID=SOH.SalesOrderID where SOH.CustomerID = c.CustomerID for JSON auto) as product) t where t.product is not null |
Take a look at the data:
|
1 2 |
select * from testJson; |
And what you will see is that there is a square bracket that denotes an array of values:
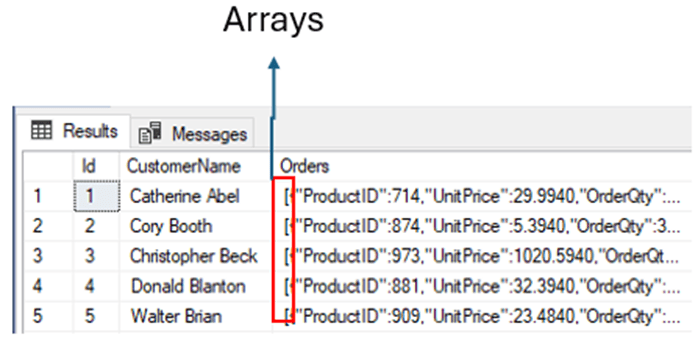
After creating the test table, it’s time to query it with our new functions. Let’s suppose we want to retrieve all the orders, together. The two methods, FOR JSON and JSON_ARRAYAGG allow this. What we need to discover is if there is any difference in the result.
Using the FOR JSON and Analyzing the Result
Let’s analyze the FOR JSON method. This query below is an example of this method:
|
1 2 3 |
select ( select Orders from testJSON for JSON auto) as Orders |
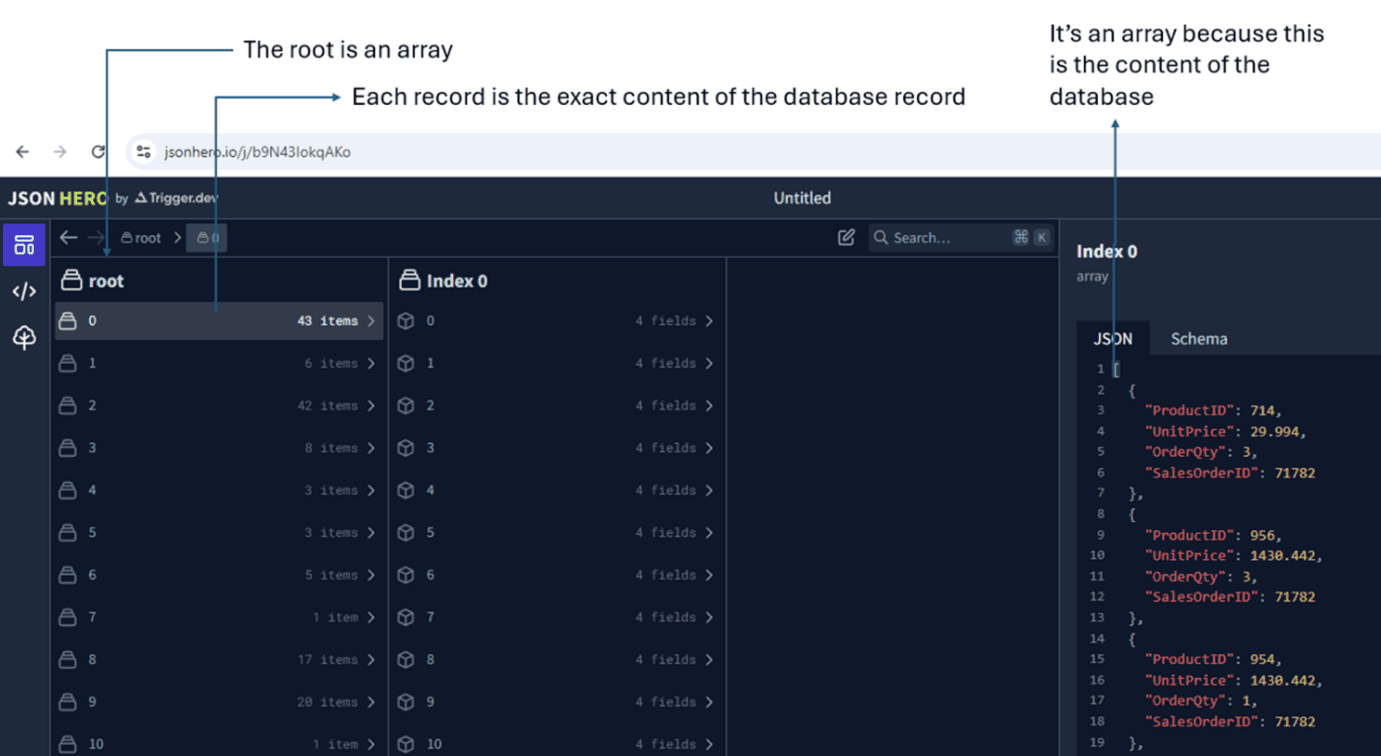
This query has two SELECT statements, one inside another. If we don’t build in this way, the JSON can be truncated. We can use JSON Hero website to analyze the result of the query. Just save the results to a file and import it into the tool to analyze it. FOR JSON joins the content from all the records in an array.
Each record has an array, because this is the original content inside the field Orders, resulting in an array of arrays, or close to this.
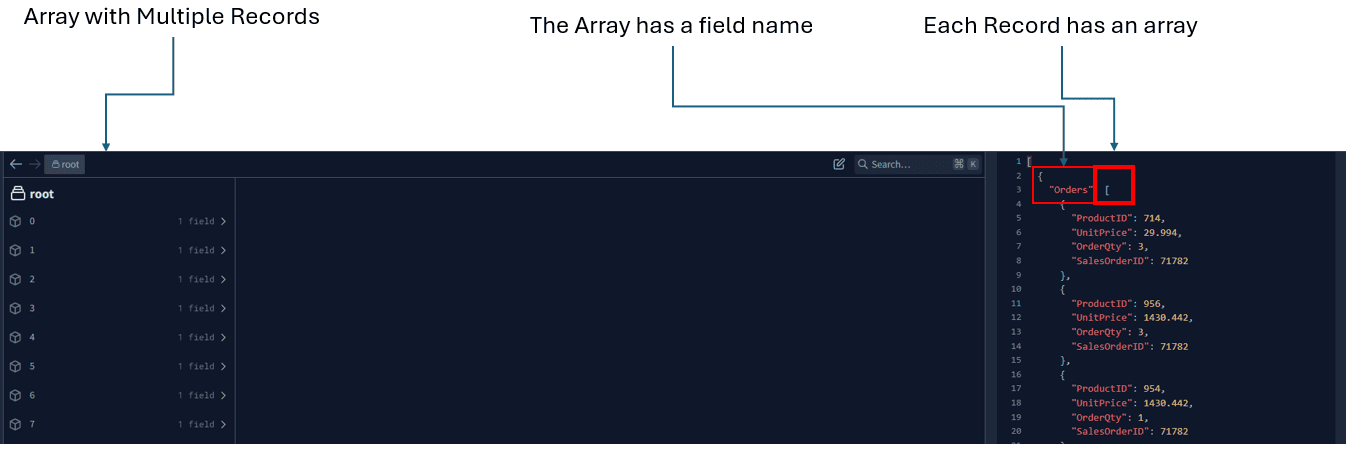
As you may notice in the image above, what we have is not exactly an array of array. The FOR JSON creates an additional element in the result: It creates an object wrapping each record in the structure.
In this way, the result becomes like this:
- Each record becomes an object with the fields we are recovering as properties
- We are recovering one single field,
Orders. The object has only this property - The content of the field
Ordersis an array - In each object/record, the property orders contain an array, the actual content of the field
- All the objects/records become one element inside a bigger array
In short: We have an array of objects containing one single property which contains an array.
Using the JSON_ARRAYAGG and Analyzing the Result
Let’s analyze how to reach the same result or similar using JSON_ARRAYAGG. The query will be like this:
|
1 2 |
select JSON_ARRAYAGG(Orders) from testJSON; |
Once again, we can use the JSON Hero website to analyze the result of the query.
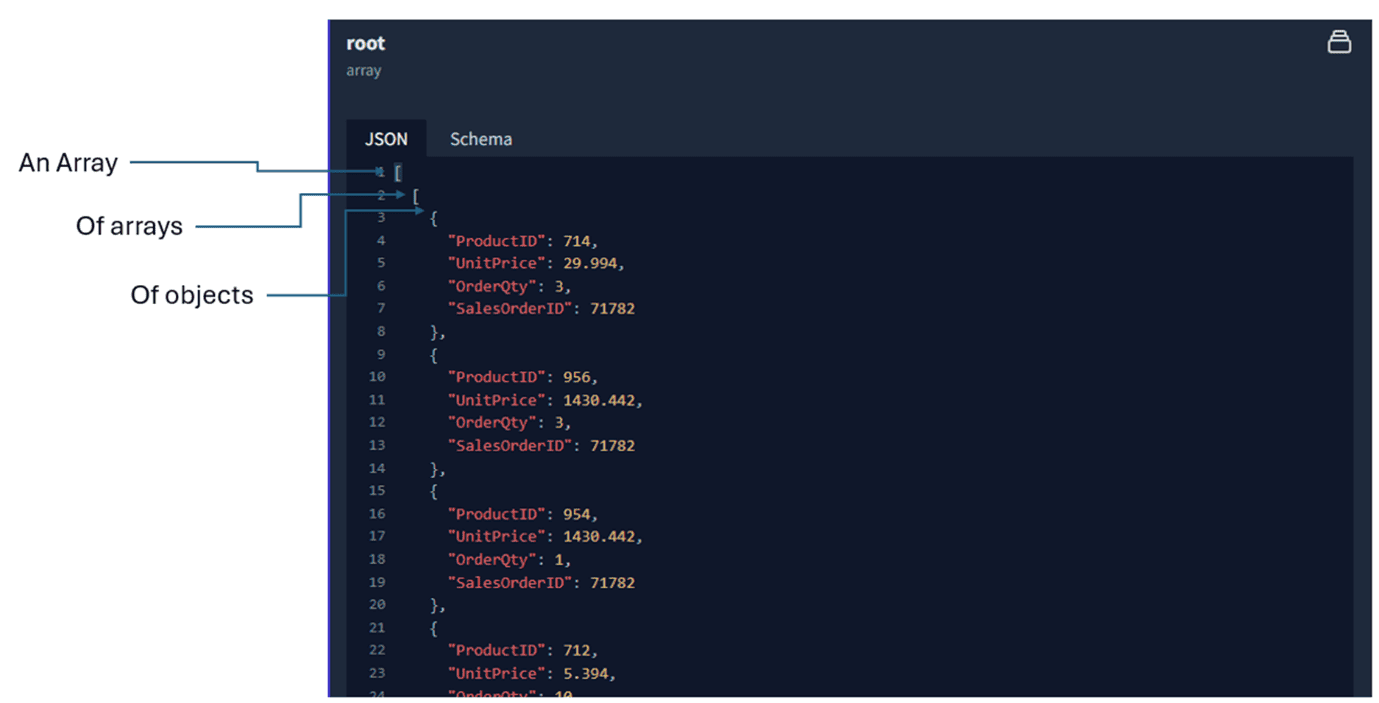
The result is an array of arrays of objects. The content of the records was used “as is” to build the JSON. The record already contains an array of objects, they are joined in a bigger array. In this situation, there is no wrapper object.
The difference between both methods
FOR JSON: Includes a wrapper object and add each field as one property of the wrapper object. The result is an array of the wrapper objects.
JSON_ARRAYAGG: The output includes the result from the database “as is”, without any wrapper object.
We can make the JSON_ARRAYAGG generate the same result as the FOR JSON, but we can’t make the FOR JSON generate the same result as the JSON_ARRAYAGG.
However, we can achieve the same result as the FOR JSON using the function JSON_OBJECT() together with JSON_ARRAYAGG. The function JSON_OBJECT can create the wrapper object which is automatically created by the FOR JSON. This is the query which will make the JSON_ARRAYAGG result the same as the FOR JSON result:
|
1 2 |
select JSON_ARRAYAGG(JSON_Object('Orders':Orders)) from testJSON; |
Looking at the output, you can see now it is an array of Orders objects as it starts like this:
[{"Orders":[{"ProductID":714,"UnitPrice":29.9940,"OrderQty":3,"SalesOrderID":71782},
Just like the FOR JSON output did.
JSON_ARRAYAGG is an aggregate function
Another important difference between the FOR JSON and JSON_ARRAYAGG is that while the first is applied over the entire result of a select, the last one is an aggregation function, it can be used together with a GROUP BY.
Let’s consider an example. The AdventureworksLT sample table has a table Customer. This table has a column named SalesPerson. Each sales person has multiple customers, and each customer has multiple orders.
This is an example of the total sales for each customer:
|
1 2 3 4 5 |
select c.SalesPerson,Count(*) as OrderCount from SalesLT.Customer AS C join SalesLT.SalesOrderHeader as SOH on C.CustomerId = SOH.CustomerId group by c.SalesPerson; |
Which will show you that there are a limited number of orders in this database
|
1 2 3 4 5 |
SalesPerson OrderCount -------------------------- ----------- adventure-works\jae0 14 adventure-works\linda3 9 adventure-works\shu0 9 |
We can group the records by SalesPerson and generate the JSON of the orders for each SalesPerson. JSON_ARRAYAGG is better for this because it’s an aggregation function. If we try to do the same with FOR JSON, we will need at least some subqueries, making it more difficult.
This is an example of JSON_ARRAYAGG used together a GROUP BY:
|
1 2 3 4 5 6 7 8 9 10 11 |
select SalesPerson, JSON_ARRAYAGG( JSON_OBJECT('CompanyName':c.CompanyName, 'ProductId':od.ProductID, 'UnitPrice':od.UnitPrice, 'OrderQty':od.OrderQty) ) from SalesLT.Customer c inner join SalesLT.SalesOrderHeader oh on oh.CustomerID=c.CustomerID inner join SalesLT.SalesOrderDetail od on od.SalesOrderID=oh.SalesOrderID group by SalesPerson; |
In this example we are using the function JSON_OBJECT to create an object for each order, joining fields from three tables, Customer, SalesOrderHeader and SalesOrderDetail.
The JSON_ARRAYAGG joins the individual JSON objects into an array, according to the GROUP BY. In other words, this function creates an array of orders for each sales person, like the image below:
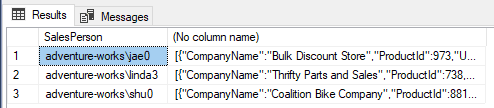
In the last column, if you execute the query, you can see all the sales for each salesperson
Summarizing the differences between the methods
We can notice in this comparison the differences between the new function JSON_ARRAYAGG and the FOR JSON.
There are small differences, and the same result could be achieved using previous methods.
When we need to make a GROUP BY, the JSON_ARRAYAGG is way easier than the FOR JSON.
Another benefit of the new function is the fact it’s part of ANSI SQL:2016. I would like to hear from you how important this is for you or how important the new features are for you. In my opinion, it’s more of a matter of a “kind-of” competition, because MySQL, PostgreSQL and Oracle already support this function.
JSON_OBJECTAGG
JSON_OBJECTAGG is one more function recently added to Azure SQL. It’s also an aggregation function, but this one creates a JSON object and not a JSON array. What’s the purpose?
It’s more difficult to identify the purpose of JSON_OBJECTAGG. The documentation explains it has two parameters: Two columns, one will be used as the JSON property name and the other will be used as the value of the property. Why would we like to transform only two columns into a JSON where the name of the properties are the values of one of the columns?
The question is in fact the answer: When would we like to use the content of a column as the name of JSON properties?
If we remember that JSON properties can be compared to columns in a table, using the content of a column as the name of columns is in fact a pivot table. In this way, using JSON_OBJECTAGG can achieve a similar result as creating a PIVOT table, but the function generates a JSON.
As an example, I will use AdventureWorksLT data. We will start with a query which could be transformed into a pivot table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
with qry as ( select pc.Name as Category, c.CompanyName, OrderQty * UnitPrice as TotalPrice from SalesLT.SalesOrderDetail sod inner join SalesLT.SalesOrderHeader SOH on sod.SalesOrderID= soh.SalesOrderID inner join SalesLT.Product p on sod.ProductID=p.ProductID inner join SalesLT.ProductCategory pc on p.ProductCategoryID=pc.ProductCategoryID inner join SalesLT.Customer c on c.CustomerID=SOH.CustomerID) select Category,CompanyName, sum(TotalPrice) as TotalSales from qry group by Category, CompanyName; |
This query creates a list of orders grouped by the product category and the company name and with the orders totaled.
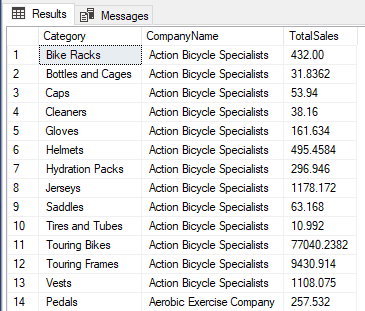
We can transform this into a pivot table where each company is a row, each category is a column with the total of the category for that company.
The JSON_OBJECTAGG can do this, transforming the result in JSON format.
Read also: Consuming JSON strings with custom T-SQL parsing
Pivot vs JSON_OBJECTAGG
If we apply a PIVOT operator to this result set, we could transform the category into columns and leave the company name as rows.
However, the SQL syntax to make a pivot has one limitation: The column names are fixed, we need to specify them one by one. The image below shows an example of how the column names are explicitly defined in the query:
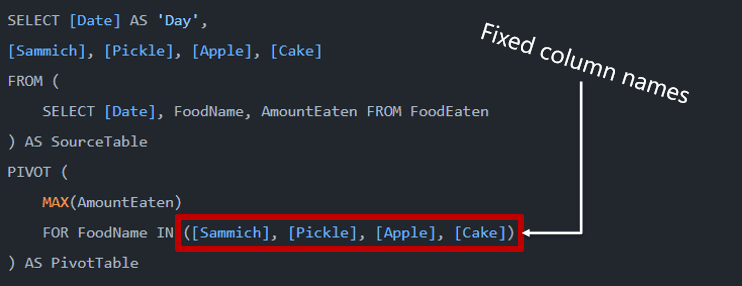
This syntax can pose a limit: If the number of columns is too high and dynamic, it will be very difficult to make a query using the PIVOT method. Considering the example above if there are too many different foods, it would be difficult to make the query.
In this way, if we compare a pivot table with the JSON_OBJECTAGG, the difference is exactly this: The pivot table is limited to creating fixed columns, but the JSON_OBJECTAGG uses the field content to create columns dynamically, it’s not fixed. The fact the result is in JSON format also makes the result more flexible: too many columns may not be so good in a query.
The example below transforms the CompanyName and TotalSales into properties of a JSON object for each one of the categories, grouping the different company names to build a single JSON Object. Compared with the PIVOT version, it’s like if the company name were transformed into a column.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
with qry as ( select pc.Name as Category, c.CompanyName, OrderQty * UnitPrice as TotalPrice from SalesLT.SalesOrderDetail sod inner join SalesLT.SalesOrderHeader SOH on sod.SalesOrderID= soh.SalesOrderID inner join SalesLT.Product p on sod.ProductID=p.ProductID inner join SalesLT.ProductCategory pc on p.ProductCategoryID=pc.ProductCategoryID inner join SalesLT.Customer c on c.CustomerID=SOH.CustomerID), dinPivot as ( select Category,CompanyName, sum(TotalPrice) as TotalSales from qry group by Category, CompanyName) select Category, JSON_OBJECTAGG(CompanyName:TotalSales) as SalesByCustomer from dinPivot group by Category |
This is how the results look:
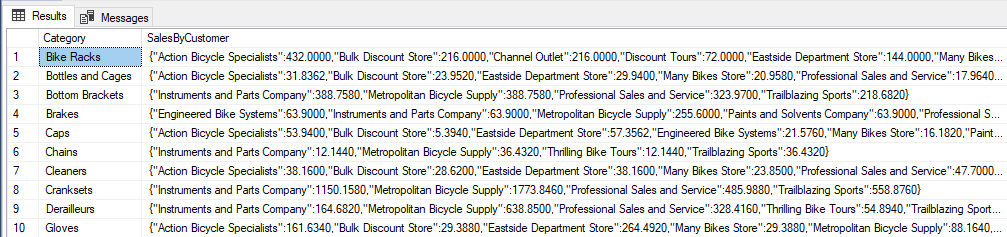
You will notice that in this snippet of the output:
"Action Bicycle Specialists":432.0000,"Bulk Discount Store":216.0000
The company names are now attributes, and the total sales are the property values.
Next step: Creating a new Object with this data
The previous result has two columns, Category and SalesByCustomer.
We can transform these two columns into an object. This transformation is row-by-row, and each row will generate an object. In this way, we can use the function JSON_OBJECT, because no row aggregation is needed.
The query will become like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
with qry as ( select pc.Name as Category, c.CompanyName, OrderQty * UnitPrice as TotalPrice from SalesLT.SalesOrderDetail sod inner join SalesLT.SalesOrderHeader SOH on sod.SalesOrderID= soh.SalesOrderID inner join SalesLT.Product p on sod.ProductID=p.ProductID inner join SalesLT.ProductCategory pc on p.ProductCategoryID=pc.ProductCategoryID inner join SalesLT.Customer c on c.CustomerID=SOH.CustomerID), dinPivot as ( select Category,CompanyName, sum(TotalPrice) as TotalSales from qry group by Category, CompanyName), firstLevel as (select Category, JSON_OBJECTAGG(CompanyName:TotalSales) as SalesByCustomer from dinPivot group by Category) select JSON_OBJECT(Category:SalesByCustomer) as Categories from firstLevel; |
This is the result:
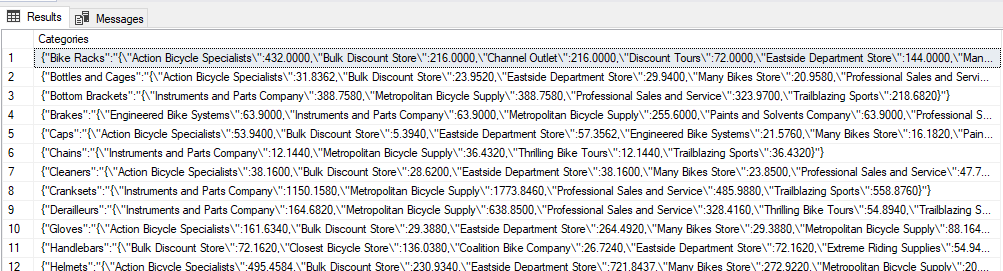
With this now as a snippet of the output:
{"Bike Racks":"{\"Action Bicycle Specialists\":432.0000,\"Bulk Discount Store\":216.0000
Each row is now an object, with the name of the product, with the company name and total sales for each in the output. The \ are to escape the double quotes, since each of the company names is inside of another set of double quotes.
Aggregating the rows
At this stage we can use what we learned before to aggregate all the rows in a single JSON array using JSON_ARRAYAGG
This is the final query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
with qry as ( select pc.Name as Category, c.CompanyName, OrderQty * UnitPrice as TotalPrice from SalesLT.SalesOrderDetail sod inner join SalesLT.SalesOrderHeader SOH on sod.SalesOrderID= soh.SalesOrderID inner join SalesLT.Product p on sod.ProductID=p.ProductID inner join SalesLT.ProductCategory pc on p.ProductCategoryID=pc.ProductCategoryID inner join SalesLT.Customer c on c.CustomerID=SOH.CustomerID), dinPivot as ( select Category,CompanyName, sum(TotalPrice) as TotalSales from qry group by Category, CompanyName), firstLevel as (select Category, JSON_OBJECTAGG(CompanyName:TotalSales) as SalesByCustomer from dinPivot group by Category) select JSON_ARRAYAGG(JSON_OBJECT(Category:SalesByCustomer)) as Categories from firstLevel; |
This is the result:

Now the output is an array of objects, each representing a product type.
Summary
The new JSON field and the creation of constraints over it are a powerful feature. The new functions provide additional capabilities for very specific scenarios and add the ANSI features to Azure SQL.
Simple Talk is brought to you by Redgate Software
FAQs: The JSON data type in Azure SQL Database
1. What is the JSON data type in Azure SQL Database?
The JSON data type is a native column type in Azure SQL Database (available since 2024) that stores JSON documents in an optimized binary format rather than as plain text in VARCHAR columns. It provides automatic validation (only valid JSON is accepted), more efficient storage, and serves as the foundation for JSON-specific CHECK constraints. Declare it with: CREATE TABLE t (data JSON NOT NULL).
2. Will the JSON data type be available in SQL Server 2025?
Yes. The native JSON data type and the new JSON aggregation functions (JSON_ARRAYAGG, JSON_OBJECTAGG, JSON_OBJECT) are confirmed for SQL Server 2025. The techniques demonstrated with Azure SQL Database will apply directly to on-premises SQL Server once 2025 reaches general availability.
3. What does JSON_ARRAYAGG do in Azure SQL?
JSON_ARRAYAGG is an aggregate function that collects values from multiple rows into a single JSON array. For example, SELECT JSON_ARRAYAGG(ProductName) FROM Products WHERE Category = ‘Electronics’ returns a JSON array like [“Laptop”, “Phone”, “Tablet”]. It works with GROUP BY for grouped arrays and can be combined with JSON_OBJECT for nested structures.





Load comments