




Purging data from a table is a common database maintenance task to prevent it from growing too large or to stay in compliance with data retention. When dealing with small amounts of data, this can be accomplished by a simple delete with no issues; however, with larger tables, this task can be problematic. Deleting records requires a lock that can block other processes from writing or even reading the data (depending on your isolation level). In this article I will share a technique I have used to work with some very large tables.
Suppose you have a requirement to remove all of the data from a table that is older than a certain date, and of course, you need to do this without incurring downtime. To illustrate this example, I will use the Stack Overflow 2013 database provided by Brent Ozar. The Posts table has over 17 million rows, 3.7 million of which are from earlier than 2011.
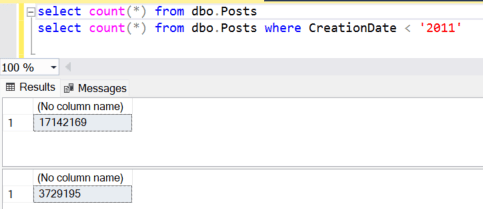
Using a simple DELETE statement will work but will lock the table for longer than acceptable. On my laptop this took over three minutes, far longer than we can afford due to the exclusive table lock that will block other processes (you can see these locks by running this in a transaction and querying sys.dm_tran_locks. Note that the DELETE statement will incur a table lock when you delete a lot of data because it becomes too costly to record individual locks for every row that is a part of the DELETE operation’s transaction).
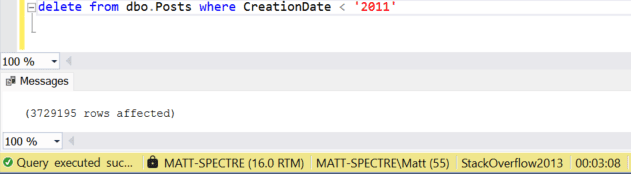
The execution plan shows that this delete will use a clustered index scan (a type of table scan used when a table has a clustered index).

Why Not Use an Index on the Searched Column?
Looking at the execution plan above, we might be tempted to add the missing index on CreationDate like so:
|
1 |
CREATE INDEX CreationDate ON dbo.Posts (CreationDate); |
This might solve the issue when processing a small number of rows, but for larger numbers or rows like we are looking at in this article, it probably will not help us, at least not enough. After creating this index our execution plan looks improved, as it does make use of the index, but still far from ideal.

Sorts, Parallelism, and those fat bars between operators are signs that this will not be a fast query. Indeed, it takes just as long to execute as it did without the index. Not to mention, adding indexes requires an extra write operation with every data modification. Indexes are often extremely useful tools to increase query performance, but not in this case due to the amount of data being processed.
Enter Batching to the Rescue
You may have learned at some point that “loops are bad” when working with SQL. Time to add some nuance to that idea. We won’t be going “row-by-agonizing-row,” but we will be using loops to break up the sets into smaller chunks.
Note: you can use partitioning to remove large chunks of rows very quickly if your cleanup is based on a specific factor that works well for partitioning. For more on partitioning, see the Microsoft docs.
In the following code sample, we will gather the Id values from the Clustered Index of all the records we want to delete and store them into a temp table. While this query might take some time to execute, it will not block any traffic to the target table, provided you are using theREAD COMMITTED isolation level with the READ_COMMITTED_SNAPSHOT database option turned on. READ COMMITTED without READ_COMMITTED_SNAPSHOT has a minimal likelihood of blocking.
Once we have the data fetched into a temp table, we will use our loop to portion off a small chunk of these Ids to a second temp table- let’s call it #Batch. This small table will result in a NESTED LOOPS join to the Clustered Index of our target table and the corresponding DELETE will be quick with minimal blocking.
Let’s see an example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
SET NOCOUNT ON; --control the number of rows deleted per iteration DECLARE @BatchSize INT = 5000; --variable used to tell the process to stop DECLARE @Stop INT = 0; IF (OBJECT_ID ('tempdb..#ToProcess') IS NULL) CREATE TABLE #ToProcess (Id INT NOT NULL PRIMARY KEY CLUSTERED); IF (OBJECT_ID ('tempdb..#Batch') IS NULL) CREATE TABLE #Batch (Id INT NOT NULL PRIMARY KEY CLUSTERED); -----------------Gather Ids------------------------------------ INSERT INTO #ToProcess (Id) SELECT Id FROM dbo.Posts WHERE CreationDate < '2011'; -----------------Main Loop------------------------------------ WHILE (@Stop = 0) BEGIN --Load up our batch table while deleting from the main set DELETE TOP (@BatchSize) #ToProcess OUTPUT DELETED.Id INTO #Batch (Id); --Once the rowcount is less than the batchsize, -- we can stop (after this loop iteration) IF @@ROWCOUNT < @BatchSize SELECT @Stop = 1; --Perform the DELETE DELETE FROM p FROM dbo.Posts p JOIN #Batch b ON p.Id = b.Id; --Clear out Batch table TRUNCATE TABLE #Batch END; |
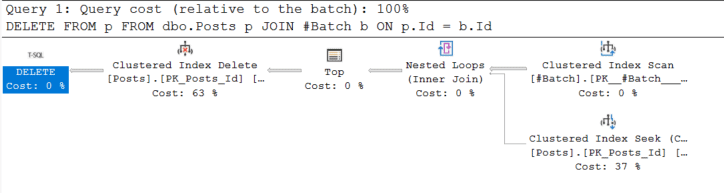
The core DELETE statement uses a Clustered Index Seek on the Posts table instead of a Scan (since it is using a join on the clustered index), which is a clue that this will give us better performance.
Running this operation took over two minutes on my laptop but each individual delete statement only took 100-150 milliseconds to execute, which is the length of time that any process would need to wait to perform a write to the table. We can see this by using a Profiler trace on the SQL_StmtCompleted event.
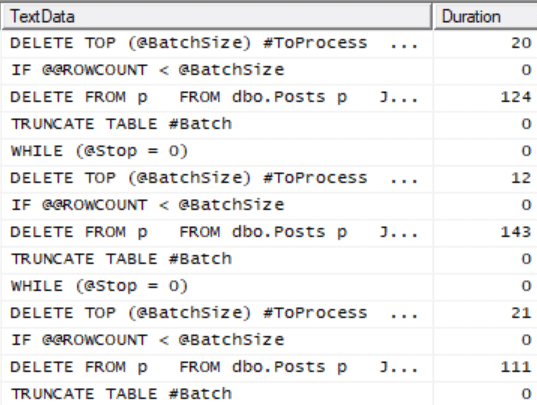
Note that the goal of this technique is not necessarily to speed up the overall operation. It may actually make it take longer. However, it gives you two values that make it important.
- It will have less effect on other users because you will most likely not be locking any rows used by other users for a significant length of time.
- If the
DELETEoperation is going to fail for some reason that you don’t expect, the error will have occurred in the chunk you are working in. This will be far fewer rows than if you tried to delete hundreds of thousands of rows, resulting in a quicker rollback and easier debugging.
Expanding on this Technique
Let’s say the requirements for your purge are more complicated than simply pruning off old data. Sometimes, a data cleanup might require joining another large table or even multiple large tables, for example, removing Post records created by users who had not logged on recently or with a low number of Votes. The beauty of this technique is that you can SELECT whatever rows you require into the initial temp table. No matter how complex and ugly this query is it won’t impact the performance of the DELETE statements.
As a quick example, say you want to delete all sales data from before 3 years ago. That would seem simple enough. But the users have more requirements. For our best customers, we keep 20 years of data, and for customers who have purchased a certain product, we keep 5-20 years, depending on how many versions of that product they have purchased. That is not quite simple to do (and certainly would not fit the partitioning model that was briefly mentioned earlier!).
This technique will also work for target tables that don’t have integer clustered indexes. The rule is to match the datatype(s) of your target clustered index with the temp tables, and this technique will still function. The main requirement for this technique to work well is that we can gather up values (ideally from the clustered index) and join back to the table in a well-performing manner.
Further Considerations
Ideally, we can test this process on an offline copy of our database to decide on the best size for these chunks- we want them to be small enough that the delete processes quickly so we minimize any blocking, but the smaller the batch, the longer this entire process will take. For the example in this article, I have used a batch size of 5K records, but this could easily be 1K, 50K, or even 500K, depending on the resources and utilization of your environment.
When deleting large amounts of data, be aware that your transaction log will see heavy writes and may grow. You may want to add more frequent transaction log backups during the time you are performing this maintenance, and you certainly want to make sure you have monitoring in place to alert you if your log is growing and/or you are running out of disk space.
Conclusion
While a single delete statement is easy to write and simple to understand, the locking it produces is often unacceptable for a production environment. This technique has been invaluable in my career, performing maintenance without taking downtime. It can be used as described to purge old data from large tables, but it is also very useful for data cleanup when the set of records to be deleted requires several joins to other large tables.


Load comments