
SQL Server 2022 introduced the ORDER clause for clustered columnstore indexes, allowing you to specify a sort column when creating or rebuilding the index: CREATE CLUSTERED COLUMNSTORE INDEX CCI ON Table ORDER (DateColumn). When data is ordered, rowgroup min/max ranges become tight and non-overlapping, enabling effective rowgroup elimination during queries.
Before SQL Server 2022, achieving this required manually ordering data through a clustered B-tree index before converting to columnstore. The ORDER clause automates this, but with limitations: it only applies during CREATE INDEX and ALTER INDEX REBUILD operations, not during ongoing INSERT operations. New data inserted after the index is built may not maintain order. This article demonstrates the feature, measures its performance impact, and evaluates its real-world limitations.
Introduction
One of the more challenging technical details of columnstore indexes that regularly gets attention is the need for data to be ordered to allow for segment elimination. In a non-clustered columnstore index, data order is automatically applied based on the order of the underlying rowstore data. In a clustered columnstore index, though, data order is not enforced by any SQL Server process. This leaves managing data order to us, which may or may not be an easy task.
To assist with this challenge, SQL Server 2022 has added the ability to specify an ORDER clause when creating or rebuilding an index. This feature allows data to be automatically sorted by SQL Server as part of those insert or rebuild processes. This article dives into this feature, exploring both its usage and its limitations.
Speedy Review of Data Order
To fully appreciate the impact of data order on a columnstore index, a quick demo will be presented to show its impact on segment elimination and the resulting effect on performance.
The following T-SQL creates a table with a columnstore index and inserts ~7.1 million rows into it (this script uses the WideWorldImportersDW database. You can download this database here):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
CREATE TABLE dbo.fact_order_BIG_CCI ( [Order Key] [bigint] NOT NULL, [City Key] [int] NOT NULL, [Customer Key] [int] NOT NULL, [Stock Item Key] [int] NOT NULL, [Order Date Key] [date] NOT NULL, [Picked Date Key] [date] NULL, [Salesperson Key] [int] NOT NULL, [Picker Key] [int] NULL, [WWI Order ID] [int] NOT NULL, [WWI Backorder ID] [int] NULL, [Description] [nvarchar](100) NOT NULL, [Package] [nvarchar](50) NOT NULL, [Quantity] [int] NOT NULL, [Unit Price] [decimal](18, 2) NOT NULL, [Tax Rate] [decimal](18, 3) NOT NULL, [Total Excluding Tax] [decimal](18, 2) NOT NULL, [Tax Amount] [decimal](18, 2) NOT NULL, [Total Including Tax] [decimal](18, 2) NOT NULL, [Lineage Key] [int] NOT NULL); -- Generate 7,173,772 rows in a heap INSERT INTO dbo.fact_order_BIG_CCI SELECT [Order Key] + (250000 * ([Day Number] + ([Calendar Month Number] * 31))) AS [Order Key] ,[City Key] ,[Customer Key] ,[Stock Item Key] ,[Order Date Key] ,[Picked Date Key] ,[Salesperson Key] ,[Picker Key] ,[WWI Order ID] ,[WWI Backorder ID] ,[Description] ,[Package] ,[Quantity] ,[Unit Price] ,[Tax Rate] ,[Total Excluding Tax] ,[Tax Amount] ,[Total Including Tax] ,[Lineage Key] FROM Fact.[Order] CROSS JOIN Dimension.Date WHERE Date.Date <= '2013-01-31'; -- Create a columnstore index on the table. CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI; |
No optimizations are made or consideration taken regarding data order. It’s a columnstore index sitting on top of a pile of data as-is. An assumption will be made here that this data will be searched most frequently based on date. If so, the ideal data order would be by the Order Date Key column. To verify the order of rows with respect to Order Date Key, the following query can be used to show the minimum and maximum values for that column within each rowgroup:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
SELECT tables.name AS table_name, indexes.name AS index_name, columns.name AS column_name, partitions.partition_number, column_store_segments.segment_id, column_store_segments.min_data_id, column_store_segments.max_data_id, column_store_segments.row_count FROM sys.column_store_segments INNER JOIN sys.partitions ON column_store_segments.hobt_id = partitions.hobt_id INNER JOIN sys.indexes ON indexes.index_id = partitions.index_id AND indexes.object_id = partitions.object_id INNER JOIN sys.tables ON tables.object_id = indexes.object_id INNER JOIN sys.columns ON tables.object_id = columns.object_id AND column_store_segments.column_id = columns.column_id WHERE tables.name = 'fact_order_BIG_CCI' AND columns.name = 'Order Date Key' ORDER BY tables.name, columns.name, column_store_segments.segment_id; |
The results are as follows (Your results should be similar, but likely differ a little bit, this is normal. In some executions I had an additional partition created):
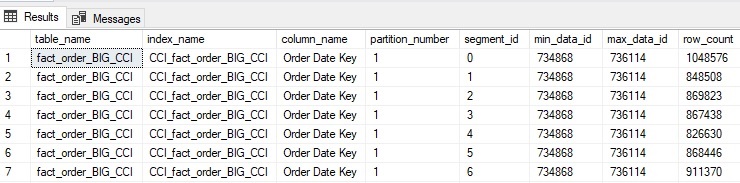
Each row is a single rowgroup within the columnstore index. Note that for each rowgroup, the min_data_id and max_data_id are the same. This indicates that the data is unordered, and the same set of disparate values is scattered across all rowgroups. The effect of this can be illustrated by running a simple analytic query.:
|
1 2 3 4 5 |
SET STATISTICS IO ON; --Output the IO that was needed to execute the query SELECT SUM([Total Excluding Tax]) AS [Total Excluding Tax] FROM dbo.fact_order_BIG_CCI WHERE [Order Date Key] = '2014-12-04'; |
This query returns a sum for only a single date value. When executed, the output of statistics IO shows the following:
Table 'fact_order_BIG_CCI'. Scan count 1, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 1540, lob physical reads 0, lob page server reads 0, lob read-ahead reads 0, lob page server read-ahead reads 0.
Table 'fact_order_BIG_CCI'. Segment reads 8, segment skipped 0.
Note that 8 segments were read and 0 were skipped. This indicates that data had to be read from all rowgroups in order to return information for a single date. The reads (1547) are suspiciously high for such a simple query as well.
Read also: Columnstore best practices: data ordering (Part 2)
The next step for this demonstration is to order this data and rerun the above queries again.
To do this, the columnstore index will be swapped out for a clustered rowstore index that is ordered by Order Date Key. The clustered rowstore index will then be swapped for a clustered columnstore index. MAXDOP of 1 ensures that parallelism does not inadvertently result in unordered data via multiple streams of ordered data being shuffled together into new rowgroups: (The clustered index I create first orders the data in the object before we create the clustered columnstore index.)
|
1 2 3 4 5 |
CREATE CLUSTERED INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI ([Order Date Key]) WITH (DROP_EXISTING = ON); CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI WITH (DROP_EXISTING = ON, MAXDOP = 1); |
Rerunning the rowgroup metadata query from earlier returns the following:
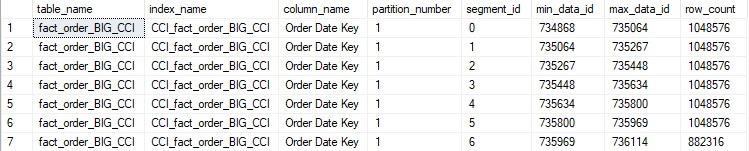
The minimum and maximum values for Order Date key are now nicely ordered from smallest to largest values. Running the simple analytic query from earlier produces the following statistics IO output:
Table 'fact_order_BIG_CCI'. Scan count 1, logical reads 0, physical reads 0, page server reads 0, read-ahead reads 0, page server read-ahead reads 0, lob logical reads 388, lob physical reads 0, lob page server reads 0, lob read-ahead reads 836, lob page server read-ahead reads 0.
Table 'fact_order_BIG_CCI'. Segment reads 1, segment skipped 6.
Only 1 segment was read whereas 6 were skipped. Note that the logical IO is significantly less than before, by about a factor of 10!
Filtering a large OLAP data set on ordered columnstore data will be significantly faster and more efficient than unordered data. But how is data ordered normally over the life span of a table? The most common solution is to:
- Structure an analytic table to only accept insert and delete operations
- Avoid updates at all costs.
- Insert new data at the end of the table for the most recent date dimension.
Alternatively, if a large table needs to be converted to a columnstore index, then trickery as demonstrated above is necessary, ordering with a rowstore index and then swapping in a columnstore index on top of the newly ordered table.
Introducing: Ordered Columnstore Indexes!
SQL Server 2022 adds the ORDER clause to the clustered columnstore index creation syntax. This column list specifies which columns to sort columnstore data by as part of the rebuild operation or as part of an INSERT operation.
To alter our existing columnstore index to use this feature, the following syntax can be used:
|
1 2 3 |
CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI ORDER ([Order Date Key]) WITH (DROP_EXISTING = ON, MAXDOP = 1); |
The result of this change formalizes the order of the columnstore index to default to using Order Date Key. When the ORDER keyword is included in a columnstore index create statement, SQL Server will sort the data in TempDB based on the column(s) specified. In addition, when new data is inserted into the columnstore index, it will be pre-sorted as well. When an ordered clustered columnstore index is the target of an index rebuild operation, the column order specified earlier will be honored.
This feature sounds like the perfect solution to enable segment elimination, but it is in no way free. As implied by the use of the word SORT, SQL Server needs to expend resources to sort the data. This not only requires TempDB resources, but it is an OFFLINE operation. Therefore, swapping a clustered columnstore index for one that is sorted will result in rebuild operations going from being online to offline operations. Note that in a partitioned table, then operation will only be offline for partitions affected by the rebuild operation. Typically, this will be a single current-data partition. Therefore, partitioning can help in improving availability for much of the data in ordered clustered columnstore indexes.
The sort operation can be visualized by checking the execution plan for both a standard and ordered columnstore index.
If you look at the query plan for creating thee indexes, you will see some interesting differences. The following plan is for creating the non-ordered columnstore index built earlier in this article:
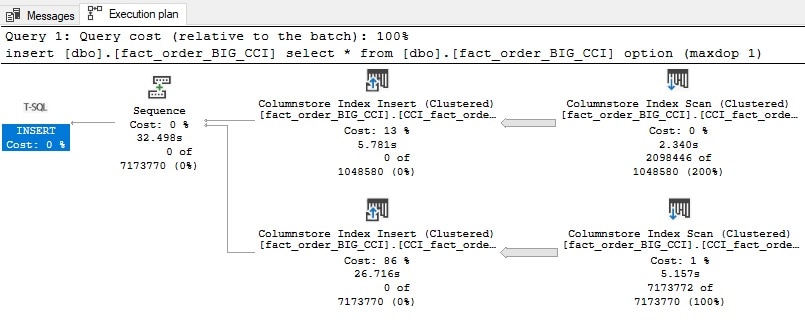
No surprises here. I wait 30 seconds and a columnstore index is ready for use on the table. Using the new syntax above that includes the ORDER clause will produce the following execution plan:
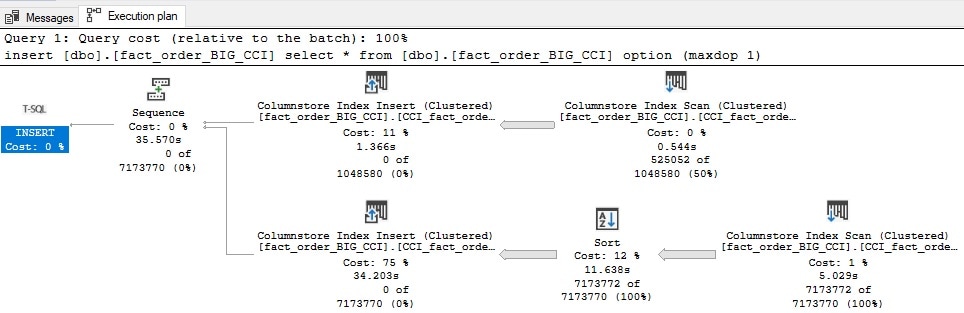
A SORT operation appears in the plan. Without partitioning or any other aids available, SQL Server needs to sort the entire data set in order to create an index that is ordered on the column of my choosing.
The column(s) used in the ORDER clause can be validated anytime in the system view sys.index_columns, using a query similar to this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT tables.name AS table_name, indexes.name AS index_name, columns.name AS column_name, index_columns.column_store_order_ordinal FROM sys.index_columns INNER JOIN sys.indexes ON indexes.index_id = index_columns.index_id AND indexes.object_id = index_columns.object_id INNER JOIN sys.columns ON index_columns.object_id = columns.object_id AND columns.column_id = index_columns.column_id INNER JOIN sys.tables ON tables.object_id = indexes.object_id WHERE tables.name = 'fact_order_BIG_CCI'; |
The results list all of the columns in the table, along with their column store order, if applicable. A value of zero indicates that the column is not a part of the columnstore order:
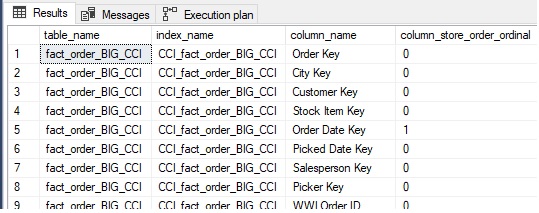
The metadata shows that Order Date Key is the sole ORDER column for this columnstore index. Consider a new index ordered by Order Date Key and then by Order Key:
|
1 2 3 |
CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI ORDER ([Order Date Key], [Order Key]) WITH (DROP_EXISTING = ON, MAXDOP = 1); |
For this index, the metadata results from above show the additional column as part of the columnstore order:
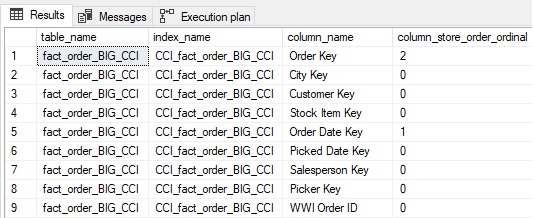
Note that Order Key is now shows as the second column in the columnstore order, after Order Date Key. For a large columnstore indexed table, ordering by an additional column may further assist queries that rely on multi-column filters.
Read also:
What Are Columnstore Indexes?
Columnstore index architecture (Part 1)
Ordered Columnstore Index Notes and Considerations
It is worth repeating that only clustered columnstore indexes can be use the ORDER clause. Non-clustered columnstore indexes inherit data order from the underlying rowstore index structure during creation and will provide segment elimination as effectively as the underlying data allows.
Ordered columnstore indexes are a heavy-handed and somewhat imperfect way of improving data order and segment elimination for three reasons:
- Rebuilding an ordered columnstore index is an
OFFLINEoperation. - Any data that is sorted must be sorted in
TempDB. - If a sort operation is so large that it would spill to disk, then the sort is aborted and data order may not be perfect.
There is value in exploring each of these issues to ensure that decisions made regarding ordered columnstore indexes are as optimal as possible:
Rebuilds on an Ordered Columnstore Index = OFFLINE Operation (Per Partition)
This is an availability concern that will not impact all users of columnstore indexes. If dedicated maintenance windows exist for index maintenance and OFFLINE is acceptable for rebuild operations, then there is no issue to be had here. Index reorganization is still an ONLINE operation and can be used as part of regular maintenance to reduce the need for rebuilds.
The amount of time that a given partition is unavailable will be equal to the amount of time needed to sort and rebuild the data in that partition. Therefore, if rebuilding a partition with 20 million rows in a clustered columnstore index typically takes 30 seconds, then the same operation would result in at least 30 seconds of offline/downtime for the same index if it were ordered. Presumably the sort operation will require some additional time, increasing the overall time needed to some number greater than 30 seconds.
It is possible to use partition switching to increase availability, though whether that level of added complexity is desired or not is wholly up to you to decide.
Ordered Columnstore Indexes Sort in TempDB
Data needs to be sorted, and in SQL Server, TempDB is where this happens. As a result, to ensure that data is properly sorted, it is important that TempDB has enough space allocated for it. If 500MB of data is to be inserted into an ordered columnstore index, then there needs to be an additional 500MB of TempDB space available.
Similarly, if a 500GB columnstore index is being rebuilt into an ordered columnstore index, then 500GB+ of TempDB space will be required. Depending on the organization and its hardware,
If there is insufficient TempDB space available to store the incoming columnstore data, then don’t use this feature. Ensuring there is enough space, though, becomes more important due to the next challenge:
Sort Operations Do Not Complete in Their Entirety
What happens when an ordered columnstore index is rebuilt or inserted into and not enough space is available in TempDB? Not what is expected! Typically, if a sort operator in an execution plan requires more TempDB space than is allocated or available, it spills to disk to allocate enough space to complete the operation.
That is NOT what happens with ordered columnstore indexes. If the data to be sorted into an ordered columnstore index exceeds the space allocated by the memory grant, then the sort operation simply completes and is flagged internally as a soft sort. A soft sort will sort as many rows as it can, but when space runs out, it will stop. While this behavior ensures that write operations are fast and do not spill to disk, they also pose a hazard as it is not immediately clear that this behavior occurred without further research.
To illustrate a soft sort, the test table earlier will be dropped, recreated, and populated with ~27.8 million rows. TempDB will also be reduced to a relatively small size to ensure that there is not enough space available to fully sort this data. The following code handles the table drop, creation, and population:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
DROP TABLE dbo.fact_order_BIG_CCI; CREATE TABLE dbo.fact_order_BIG_CCI ( [Order Key] [bigint] NOT NULL, [City Key] [int] NOT NULL, [Customer Key] [int] NOT NULL, [Stock Item Key] [int] NOT NULL, [Order Date Key] [date] NOT NULL, [Picked Date Key] [date] NULL, [Salesperson Key] [int] NOT NULL, [Picker Key] [int] NULL, [WWI Order ID] [int] NOT NULL, [WWI Backorder ID] [int] NULL, [Description] [nvarchar](100) NOT NULL, [Package] [nvarchar](50) NOT NULL, [Quantity] [int] NOT NULL, [Unit Price] [decimal](18, 2) NOT NULL, [Tax Rate] [decimal](18, 3) NOT NULL, [Total Excluding Tax] [decimal](18, 2) NOT NULL, [Tax Amount] [decimal](18, 2) NOT NULL, [Total Including Tax] [decimal](18, 2) NOT NULL, [Lineage Key] [int] NOT NULL); -- Generate 27769440 rows in a heap: INSERT INTO dbo.fact_order_BIG_CCI SELECT [Order Key] + (250000 * ([Day Number] + ([Calendar Month Number] * 31))) AS [Order Key] ,[City Key] ,[Customer Key] ,[Stock Item Key] ,[Order Date Key] ,[Picked Date Key] ,[Salesperson Key] ,[Picker Key] ,[WWI Order ID] ,[WWI Backorder ID] ,[Description] ,[Package] ,[Quantity] ,[Unit Price] ,[Tax Rate] ,[Total Excluding Tax] ,[Tax Amount] ,[Total Including Tax] ,[Lineage Key] FROM Fact.[Order] CROSS JOIN Dimension.Date WHERE Date.Date <= '2013-04-30'; |
With a heap of data waiting to be sorted, trace flag 8666 will be enabled:
|
1 |
DBCC TRACEON (8666); |
This undocumented trace flag will provide additional query optimizer details that otherwise are not provided in execution plans (graphical or XML). If you experiment with this trace flag, be sure to do so in a test environment and disable it when your testing is complete!
With added optimizer detail available, let’s turn on the actual execution plan, so we can quickly visualize what is going on here:
Finally, it is time to build an ordered columnstore index on the larger table created above:
|
1 2 3 |
CREATE CLUSTERED COLUMNSTORE INDEX CCI_fact_order_BIG_CCI ON dbo.fact_order_BIG_CCI ORDER ([Order Date Key], [Order Key]) WITH (MAXDOP = 1) |
This takes a few minutes to complete on my local server. The execution plan now contains some added information that can be used to understand what happened when SQL Server sorted the incoming data:
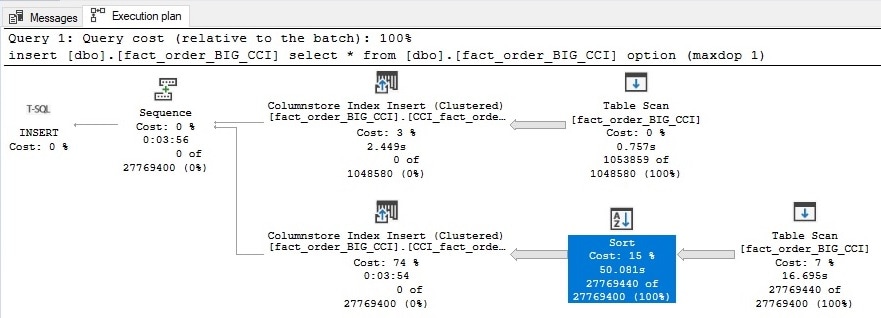
Opening the properties for the Sort operator allows us to get some additional detail:
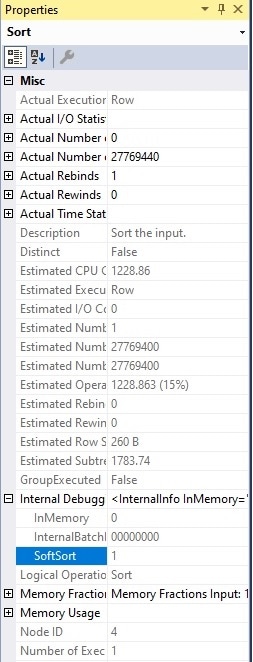
Within the internal debugger info is a flag that indicates if this was a soft sort or not. In this case, the answer is yes!
With that validated, the metadata query from earlier in this article will be run to show how well-ordered the rowgroups in the columnstore index are:
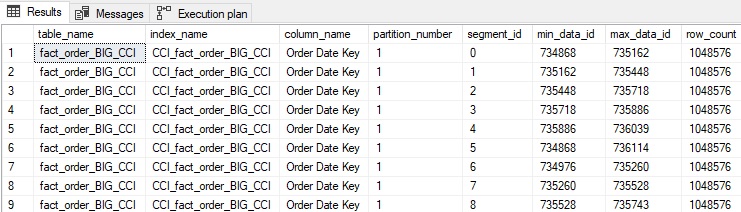
There are 27 rowgroups in total, but it is clear from the first 9 that this data is not actually ordered on Order Date Key effectively. While examining the values for min_data_id and max_data_id shows SOME ordering, it is clear that a query that should read 1-2 rowgroups will instead read many more as so many value ranges overlap.
To summarize: soft sorting is a hazard for building and maintaining ordered columnstore indexes and may be a reason to hold off on using them until the feature is further refined.
Conclusion
Prior to this feature, order was maintained manually. This sounds painful, but in reality, analytic data is often created based on date/time and naturally orders itself based on some key dimension(s), often date/time. For example, a table that loads new sales data daily will add a new day’s worth of data to the end of the columnstore index each day. So if updates are not performed on this table, then the data will naturally remain ordered as new data will also be the most recent. Even if 5% of the incoming data were old and out-of-order, overall segment elimination would still be relatively good.
Ordered columnstore indexes are an attempt to bring more focus on rowgroup elimination and its importance in speeding up analytic queries. If a columnstore index has 1 billion rows, then it will contain approximately 1,000 rowgroups. Reading 1000 segments to get data on a single column is far more expensive than reading 3 segments. Despite its promises, ordered columnstore indexes are not perfect and have limitations that make them a less-than-ideal solution, especially for tables where large amounts of data are inserted or rebuilt regularly.
This feature may work for you but be sure to test and ensure that insert operations and rebuilds do indeed sort the data correctly. If not, it may be worth reverting to the old-fashioned way of managing this data using natural ordering via manual processes.
Let’s hope for feature improvements! Columnstore indexes are a prime example of a feature that has improved steadily with every version of SQL Server since its inception. In the same way that columnstore indexes have matured to allow a wider variety of write operations, rowgroup elimination for more data types and predicates, and improved rowgroup consolidation/maintenance, it is likely that this feature will also get a much-needed upgrade soon.
Read also: AI embeddings in SQL Server 2025
Fast, reliable and consistent SQL Server development…
FAQs: Ordered columnstore indexes in SQL Server 2022
1. How do you create an ordered columnstore index in SQL Server 2022?
Use the ORDER clause: CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.YourTable ORDER ([DateColumn]). You can also specify ORDER during a rebuild: ALTER INDEX CCI ON dbo.YourTable REBUILD WITH (ORDER ([DateColumn])). The ORDER clause sorts data within each partition, creating tight min/max ranges in rowgroup metadata that enable efficient rowgroup elimination during queries.
2. What are the limitations of ordered columnstore indexes?
The ORDER clause only applies during index creation and rebuilds, not during ongoing INSERT operations. New rows inserted after the index is built land in delta rowgroups and may not maintain the specified order when compressed. Large bulk inserts may also not sort correctly. This means periodic rebuilds may still be needed to maintain optimal ordering. Additionally, the feature is limited to clustered columnstore indexes – nonclustered columnstore indexes inherit order from the underlying rowstore.
3. Do you still need to manually order data before creating a columnstore index?
In SQL Server 2022+, the ORDER clause handles sorting during creation and rebuilds. However, for ongoing data loads, you may still need to ensure data arrives in order, or schedule periodic rebuilds with ORDER to maintain rowgroup elimination effectiveness. In earlier SQL Server versions, the manual approach (create B-tree clustered index on the order column, then convert to columnstore with DROP_EXISTING) remains the only option.





Load comments